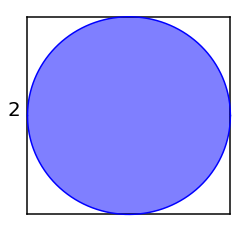
数据点(x,y)的横坐标从[-1,1]中均匀抽样得到,纵坐标从[-1,1]中均匀抽样得到,则数据点落在圆内的概率为: p = A 2 A 1 = π 4 p=\frac{A_2}{A_1}=\frac{\pi}{4} p=A1A2=4π
计算误差为: o ( 1 n ) o(\frac{1}{\sqrt{n}}) o(n1) 则计算圆周率的流程为:
设定一个大数n,计数器m。
for i = 1 to n: x ← [ − 1 , 1 ] y ← [ − 1 , 1 ] m ← m + 1 ( 当 x 2 + y 2 ≤ 1 时 ) x\gets[-1,1]\\y\gets[-1,1]\\ \\m\gets m+1(当x^2+y^2≤1时) x←[−1,1]y←[−1,1]m←m+1(当x2+y2≤1时)
π ← 4 m n \pi \gets \frac{4m}{n} π←n4m
1.2 代码实现
import random
n =10000000
m =0for i inrange(n):
x = random.uniform(-1,1)
y = random.uniform(-1,1





 本文通过数学理论,详细讲解了如何利用蒙特卡洛方法估算圆周率、一元和多元积分,并演示了期望估计的实际应用。通过代码实例展示了如何用随机抽样计算这些复杂数学问题的近似解。
本文通过数学理论,详细讲解了如何利用蒙特卡洛方法估算圆周率、一元和多元积分,并演示了期望估计的实际应用。通过代码实例展示了如何用随机抽样计算这些复杂数学问题的近似解。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









