






Java消息中间件篇
RabbitMQ消息队列模型
WorkQueues模型工作模式
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
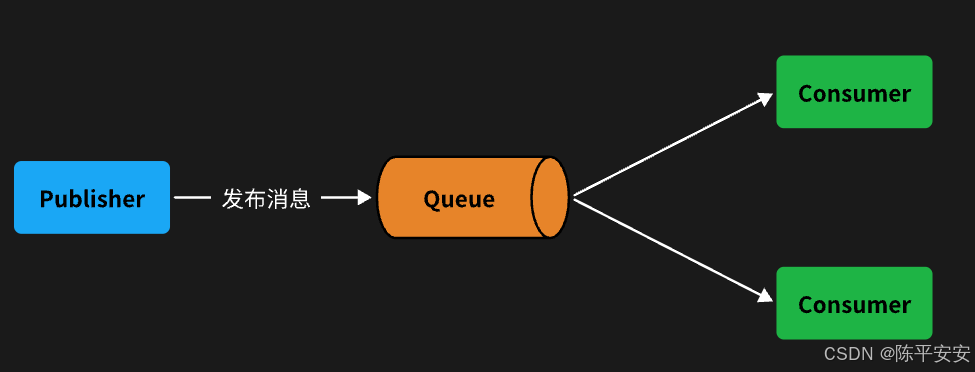
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
默认消息是平均分配给每个消费者,没有考虑到消费者的处理能力。导致1个消费者空闲,另一个消费者忙的不可开交。没有充分利用每一个消费者的能力,最终消息处理的耗时远远超过了1秒。这样显然是有问题的。
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息正所谓能者多劳,这样充分利用了每一个消费者的处理能力,可以有效避免消息积压问题。
总结
Work模型的使用:
-
多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
-
通过设置prefetch来控制消费者预取的消息数量
Fanout交换机
Fanout,英文翻译是扇出,我觉得在MQ中叫广播更合适。
在广播模式下,消息发送流程是这样的:
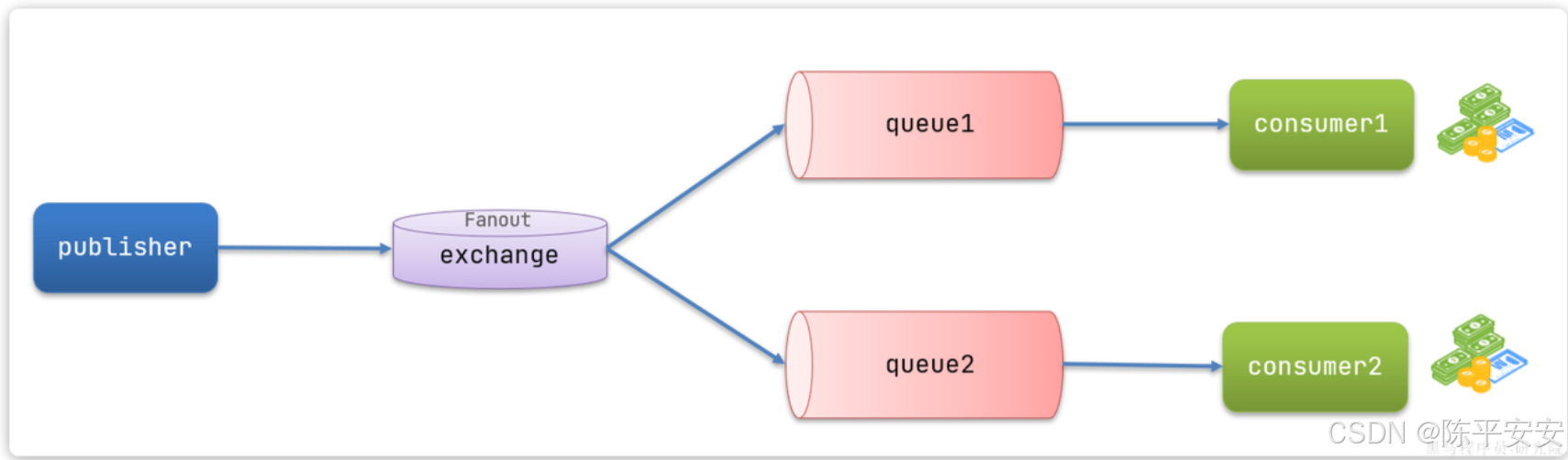
-
1) 可以有多个队列
-
2) 每个队列都要绑定到Exchange(交换机)
-
3) 生产者发送的消息,只能发送到交换机
-
4) 交换机把消息发送给绑定过的所有队列
-
5) 订阅队列的消费者都能拿到消息
订阅模型Direct交换机
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
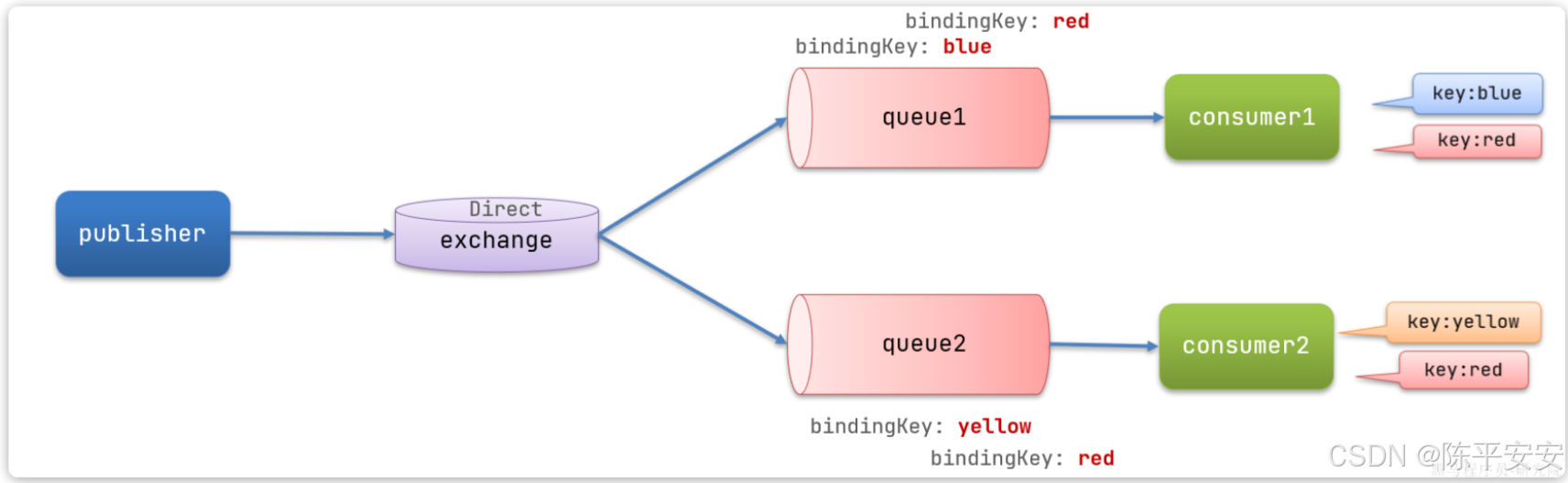
在Direct模型下:
-
队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) -
消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 -
Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
Topic交换机
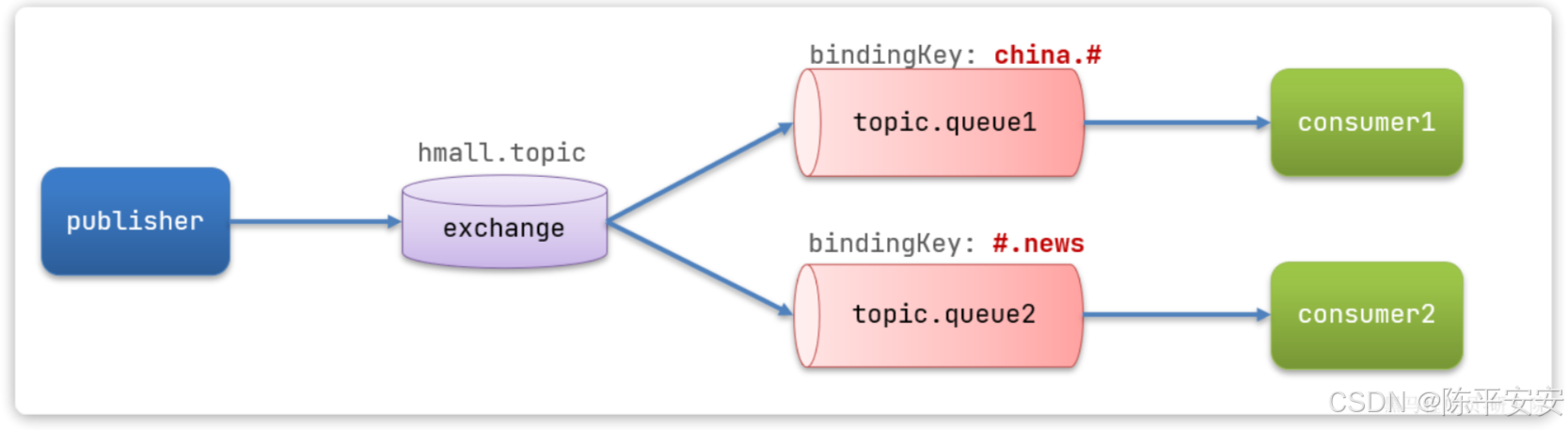
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。
只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候使用通配符!
BindingKey 一般都是有一个或多个单词组成,多个单词之间以.分割,例如: item.insert
通配符规则:
-
#:匹配一个或多个词 -
*:匹配不多不少恰好1个词
举例:
-
item.#:能够匹配item.spu.insert或者item.spu -
item.*:只能匹配item.spu
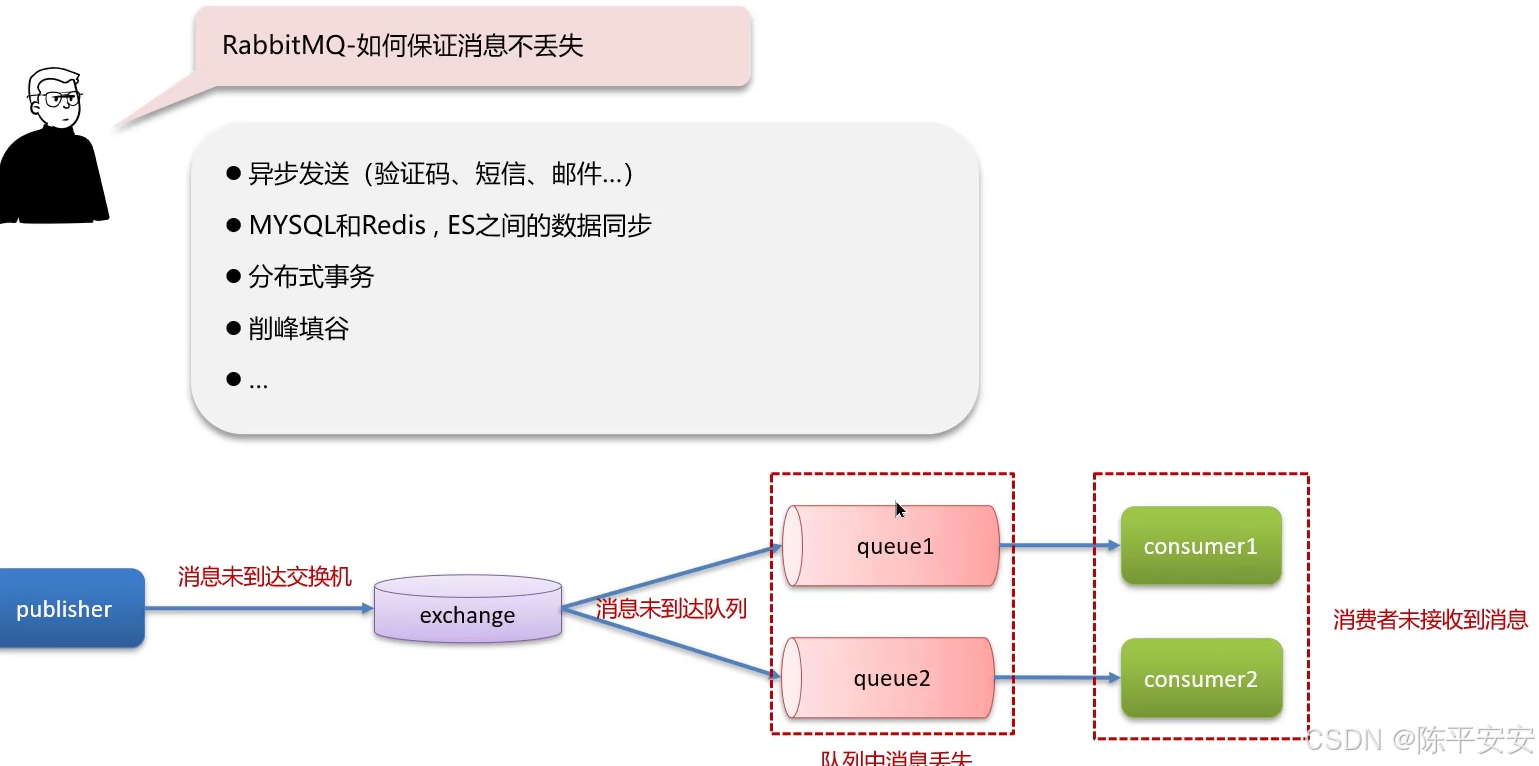
RabbitMQ如何保证消息不丢失


候选人:
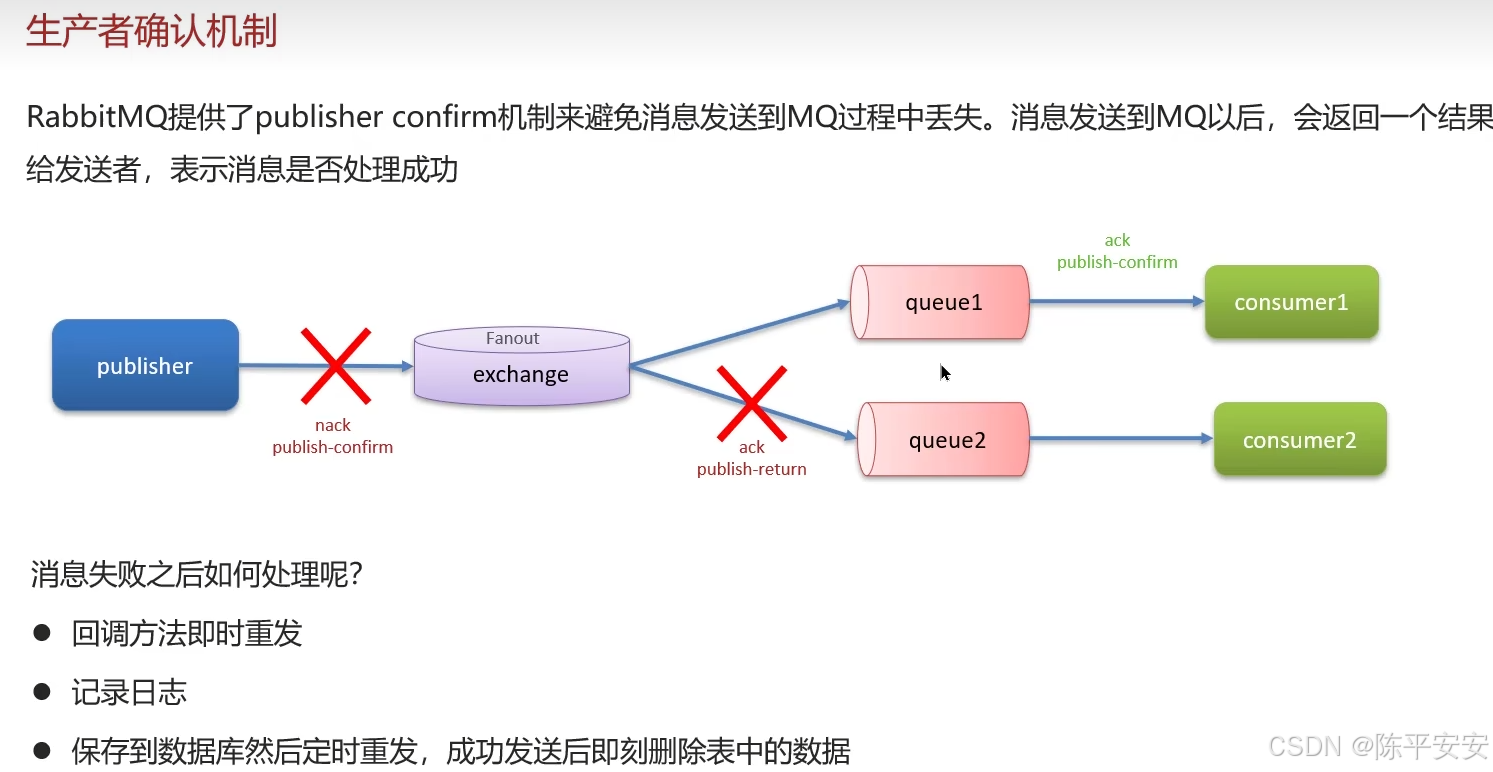
我们使用RabbitMQ来确保MySQL和Redis间数据双写的一致性,这要求我们实现消息的高可用性,具体措施包括:
-
开启生产者确认机制,确保消息能被送达队列,如有错误则记录日志并修复数据。
-
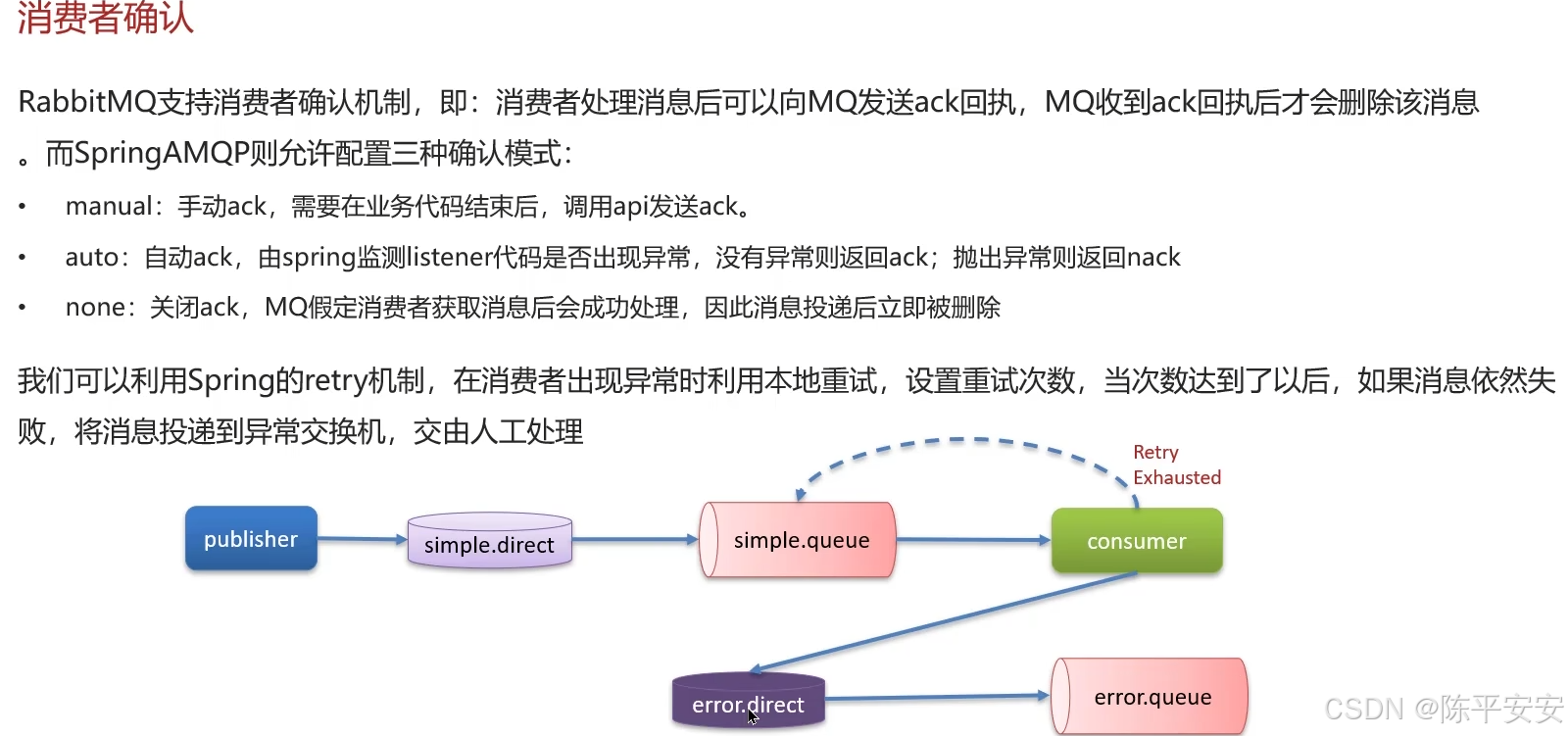
启用持久化功能,保证消息在未消费前不会在队列中丢失,需要对交换机、队列和消息本身都进行持久化。
-
对消费者开启自动确认机制,并设置重试次数。例如,我们设置了3次重试,若失败则将消息发送至异常交换机,由人工处理。
-
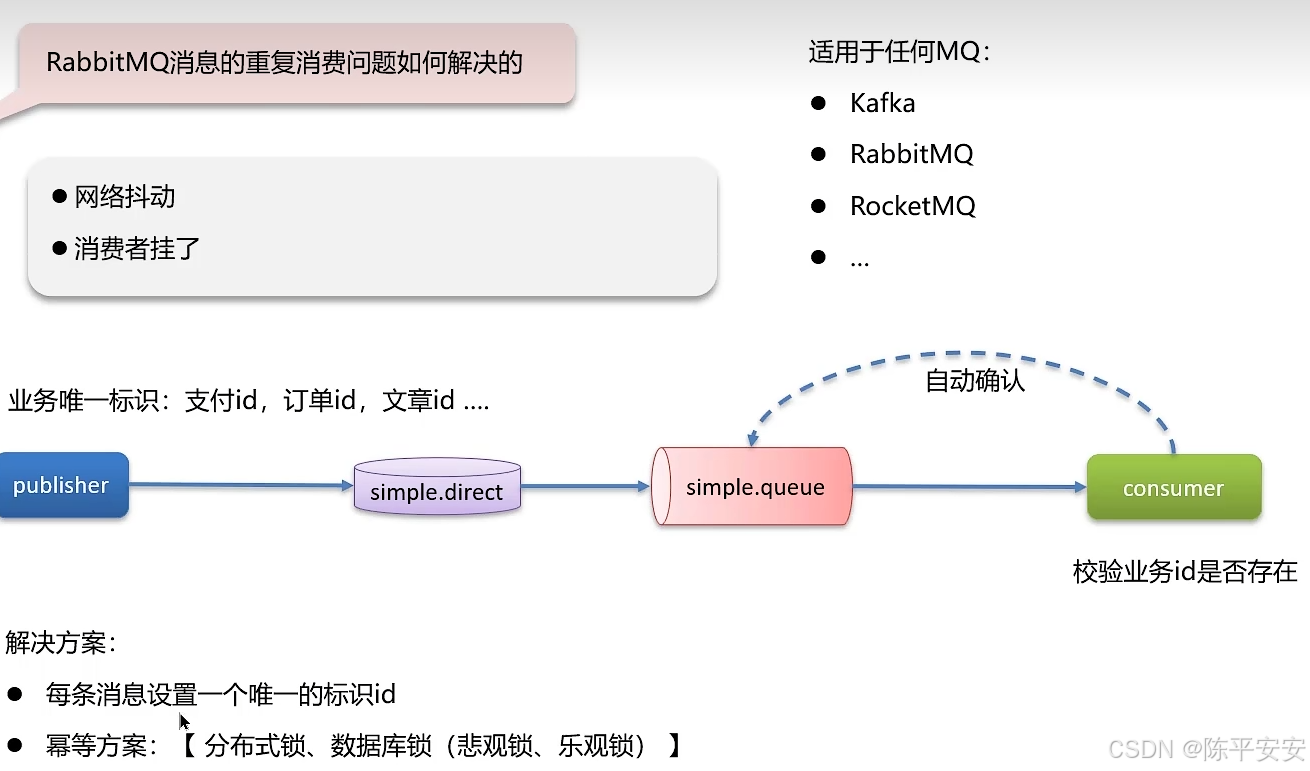
RabbitMQ消息的重复消费问题如何解决?
候选人:
我们遇到过消息重复消费的问题,处理方法是:
-
设置消费者为自动确认模式,如果服务在确认前宕机,重启后可能会再次消费同一消息。
-
通过业务唯一标识检查数据库中数据是否存在,若不存在则处理消息,若存在则忽略,避免重复消费。
-
保证MQ幂等性通常是指保证消费者消费消息的幂等性。
1、使用数据库的唯一约束去控制。
比如:添加唯一索引保证添加数据的幂等性
2、使用token机制
发送消息时给消息指定一个唯一的ID
发送消息时将消息ID写入Redis
消费时根据消息ID查询Redis判断是否已经消费,如果已经消费则不再消费。
-
确保消息幂等性
消费者幂等设计:设计消费者时,应确保其具有幂等性,即多次处理同一条消息所产生的结果与只处理一次时的结果相同。这可以通过一些技术手段来实现,比如使用唯一标识符对已处理的消息进行记录,或者利用数据库的主键约束、唯一索引等机制来确保重复消息不会对数据产生影响。
唯一消息标识符:在消息的属性中添加一个唯一的标识符,如消息ID或其他业务相关的唯一键。消费者在处理消息时,先检查该标识符是否已经处理过该消息,如果已经处理,则忽略该消息,避免重复消费。
那你还知道其他的解决方案吗?
候选人:
是的,这属于幂等性问题,可以通过以下方法解决:
-
使用Redis分布式锁或数据库锁来确保操作的幂等性。

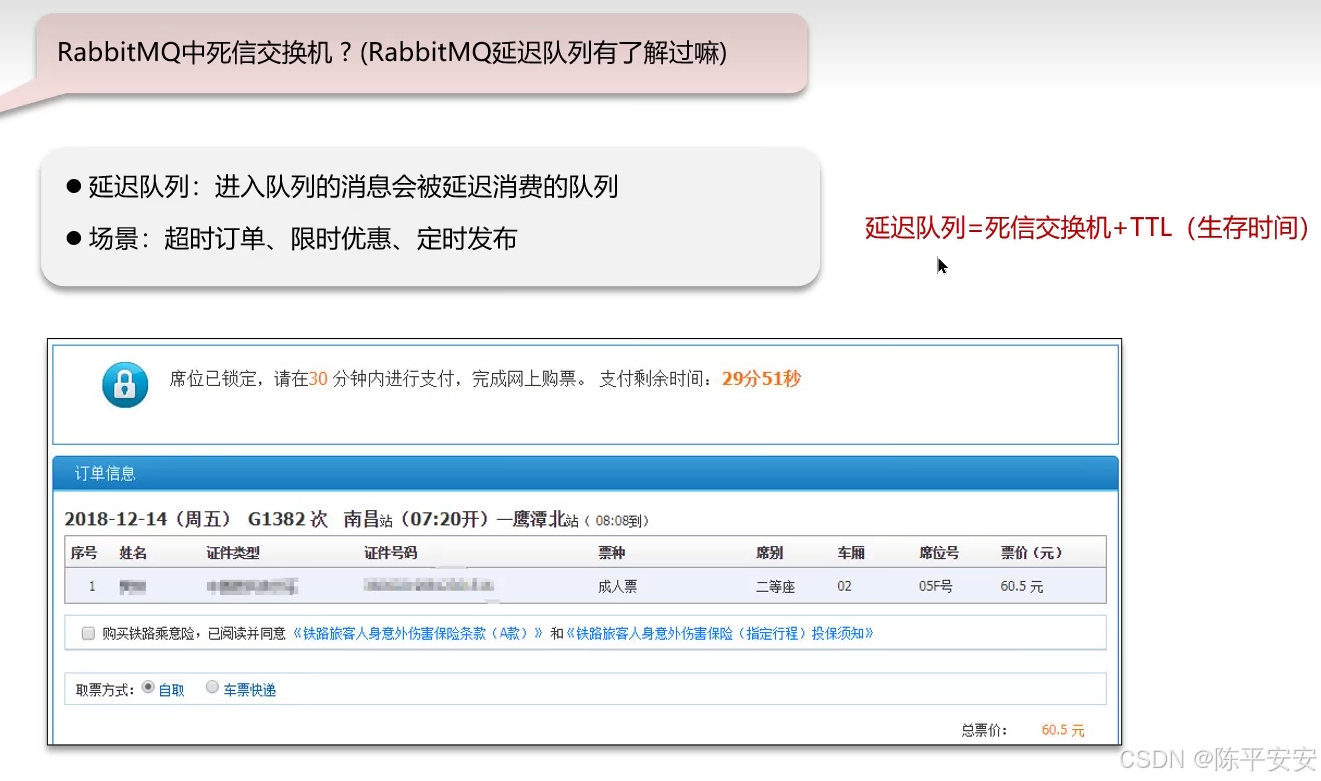
RabbitMQ中死信交换机了解吗?(RabbitMQ延迟队列有了解过吗?)

候选人:
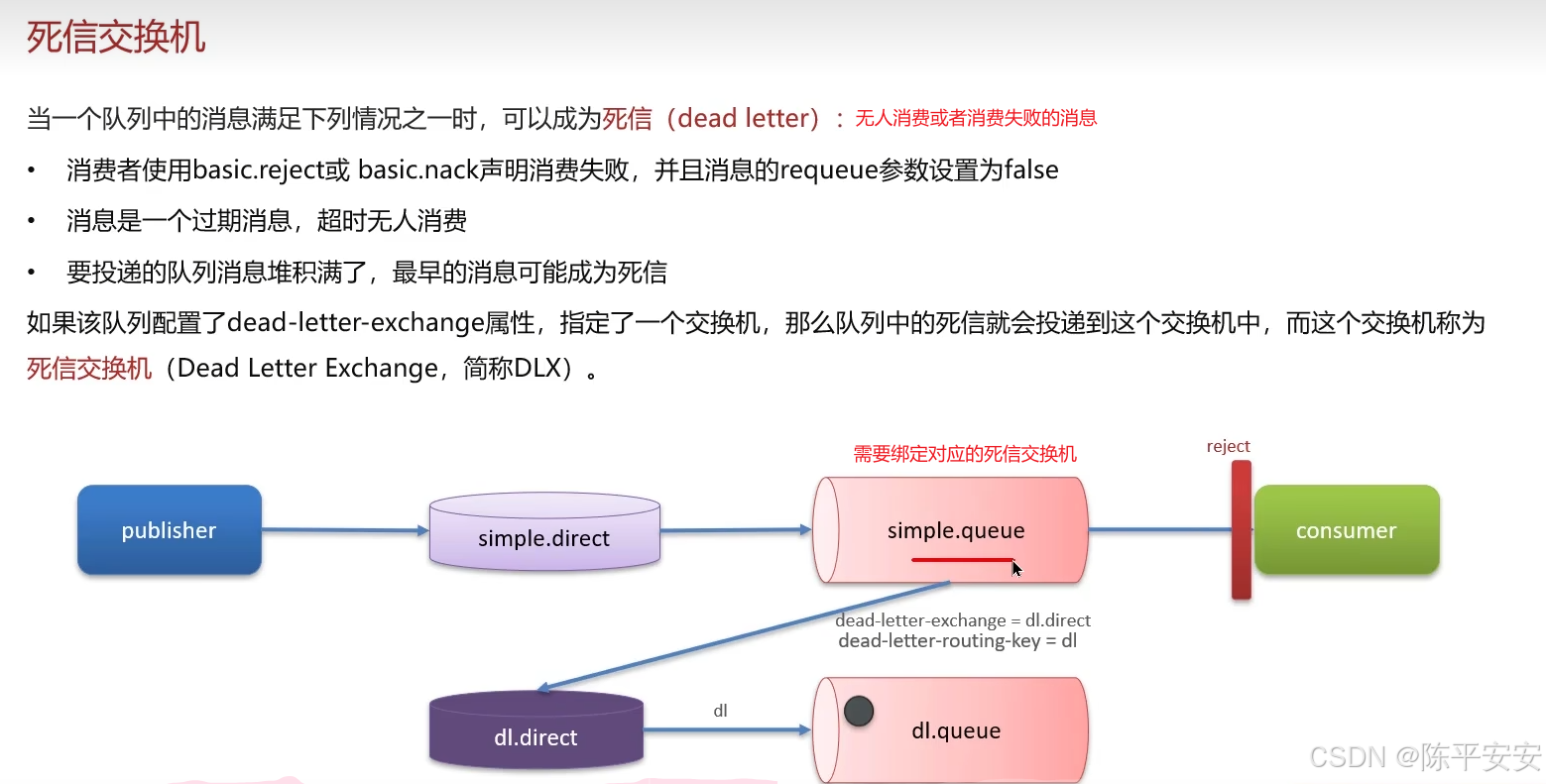
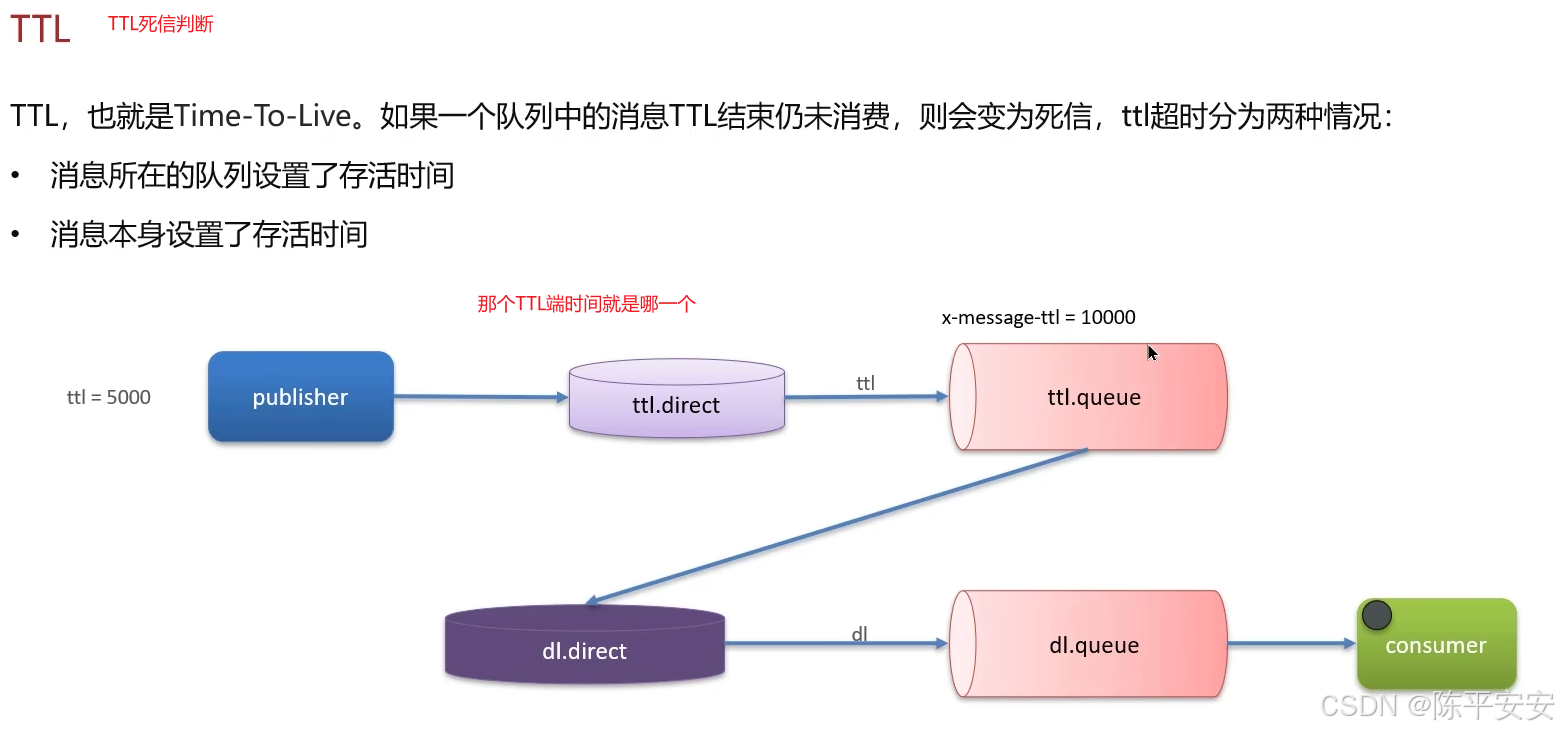
了解。我们项目中使用RabbitMQ实现延迟队列,主要通过死信交换机和TTL(消息存活时间)来实现。
-
消息若超时未消费则变为死信,队列可绑定死信交换机,实现延迟功能。
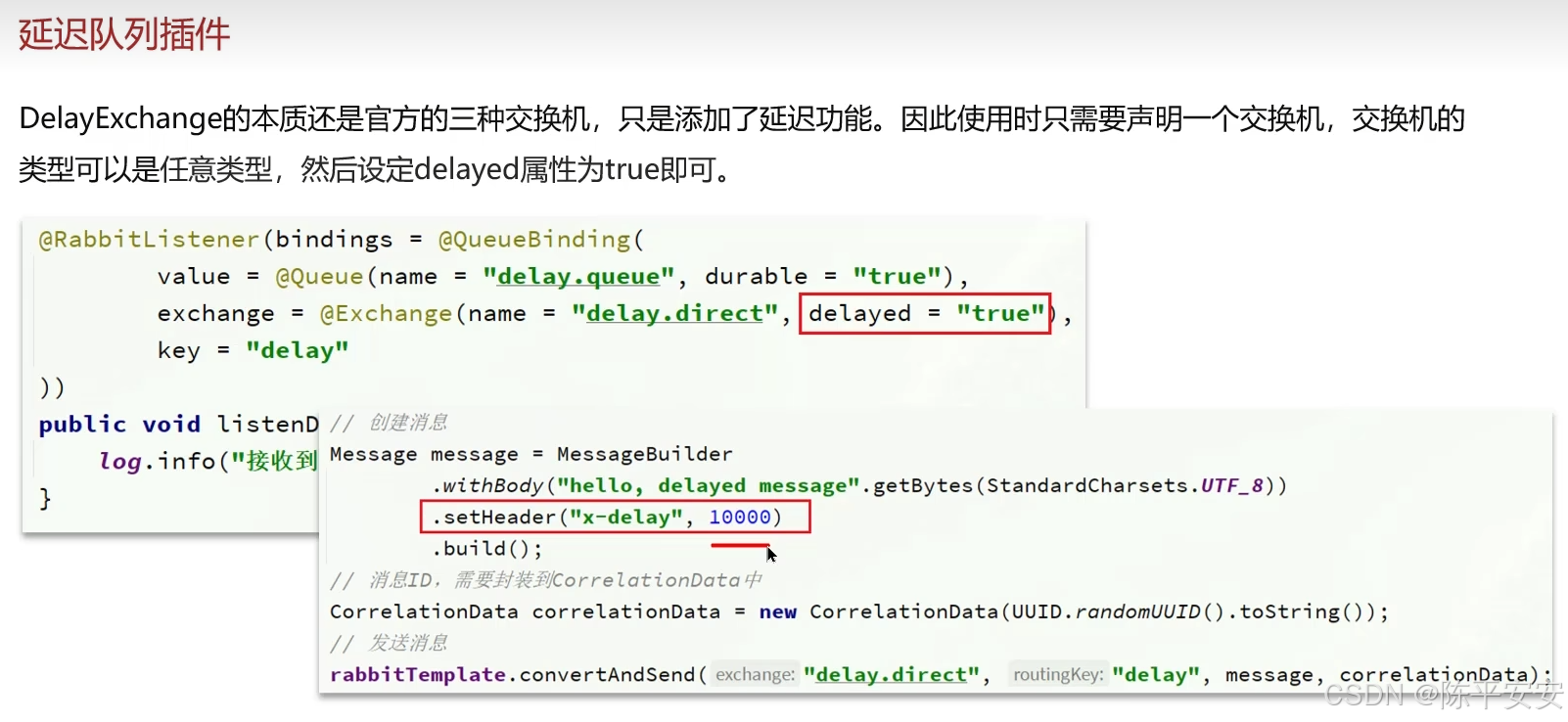
-
另一种方法是安装RabbitMQ的死信插件,简化配置,在声明交换机时指定为死信交换机,并设置消息超时时间。
如果有100万消息堆积在MQ,如何解决?
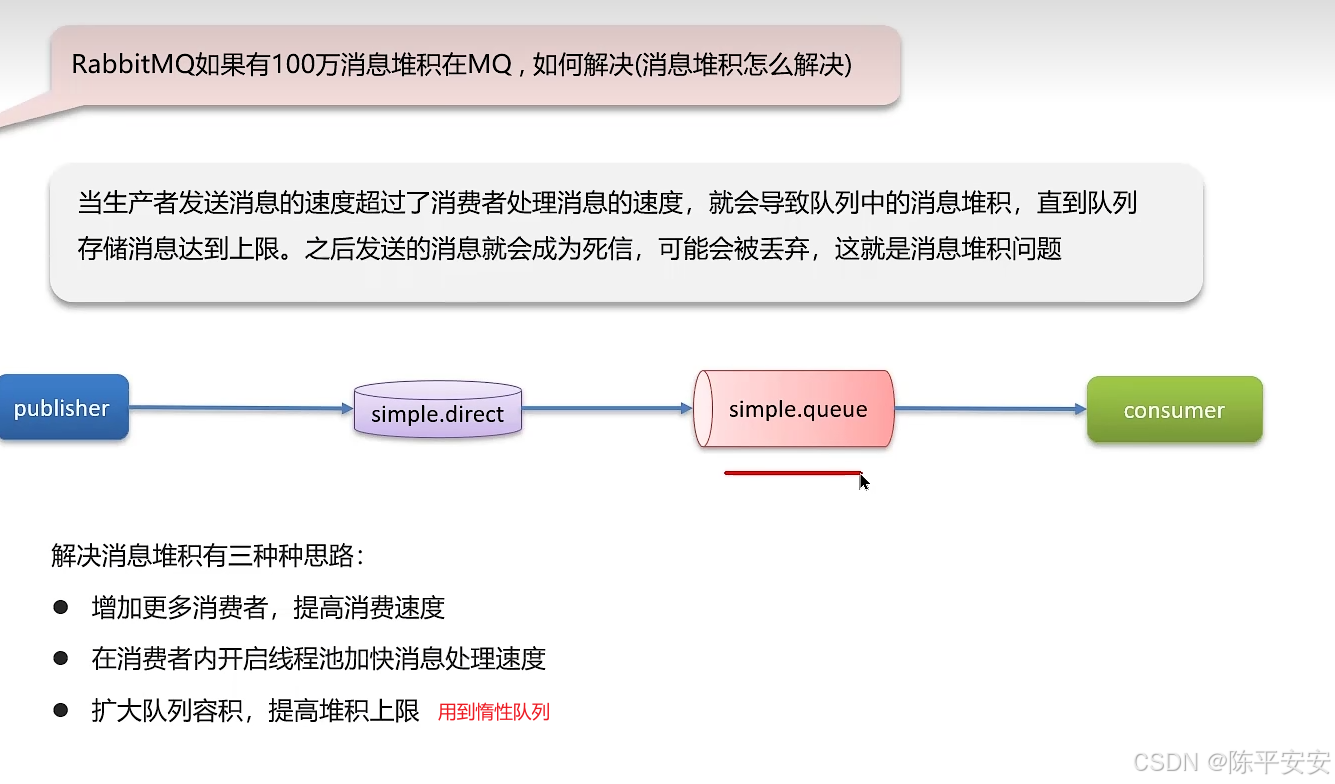

候选人:
若出现消息堆积,可采取以下措施:
-
提高消费者消费能力,如使用多线程。
-
增加消费者数量,采用工作队列模式,让多个消费者并行消费同一队列。
-
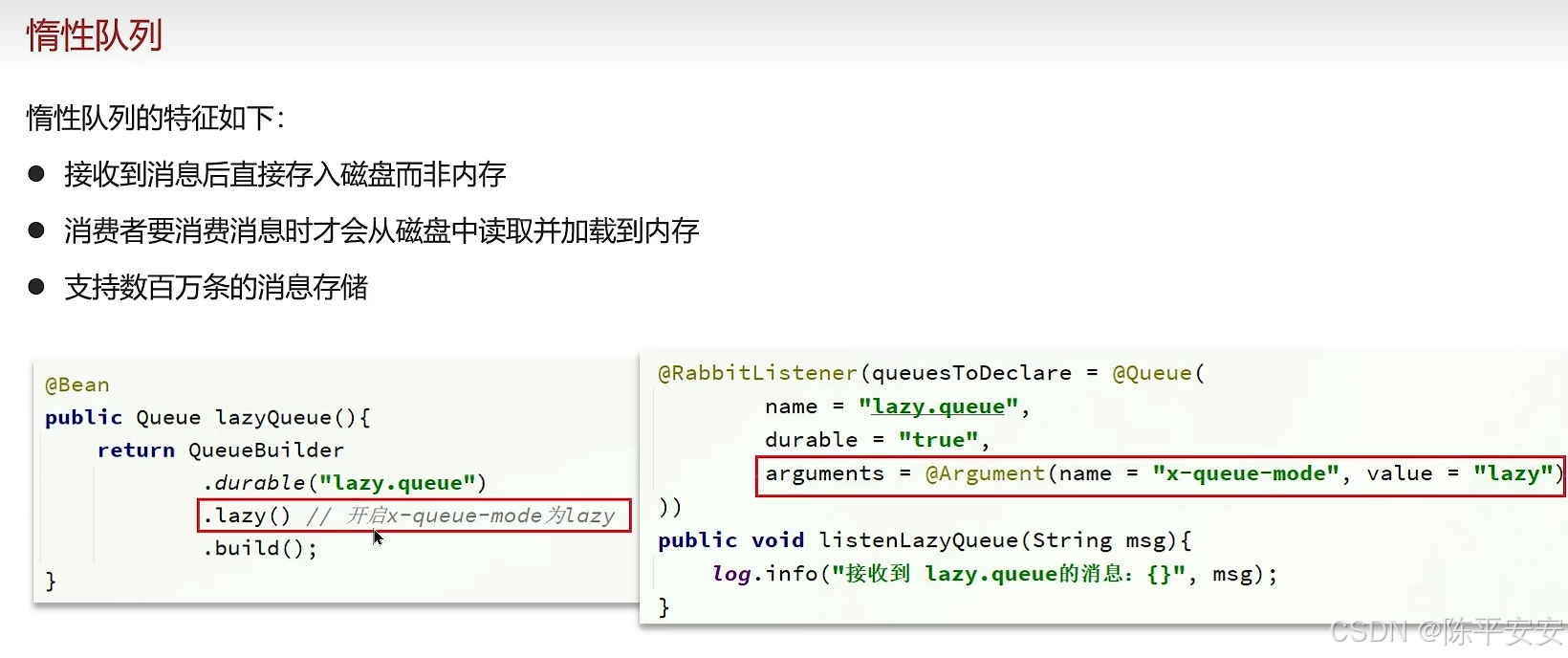
扩大队列容量,使用RabbitMQ的惰性队列,支持数百万条消息存储,直接存盘而非内存。
RabbitMQ的高可用机制了解吗?(集群)
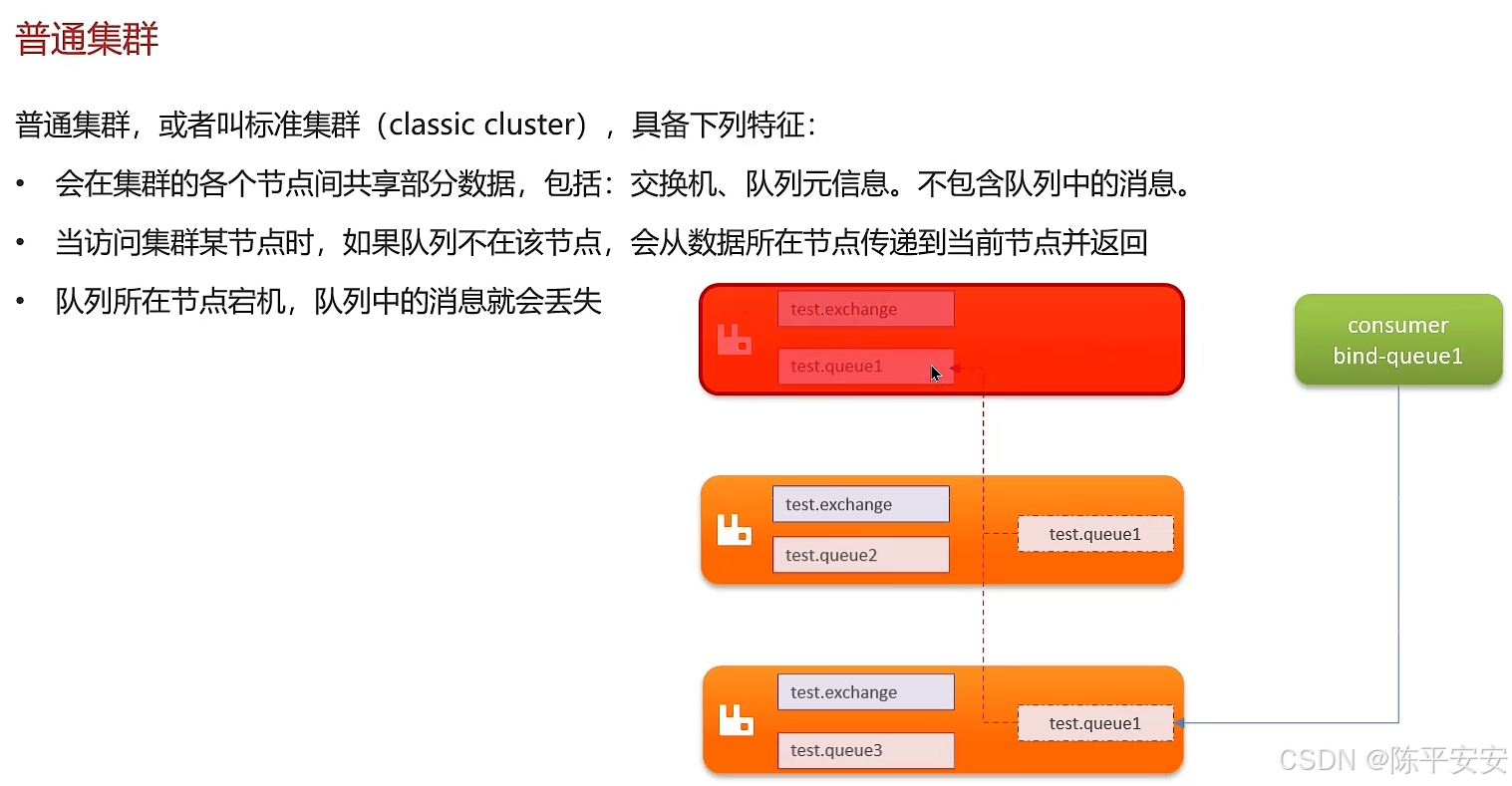
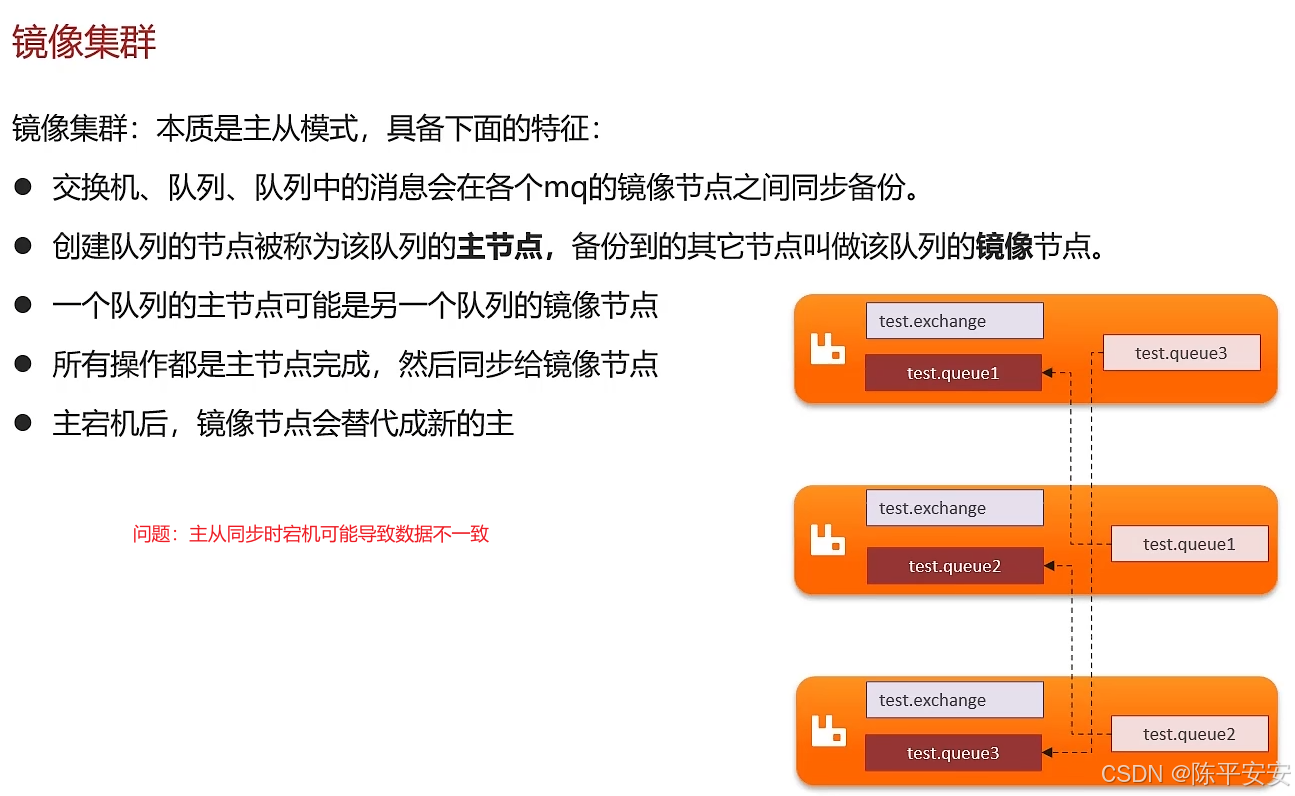


候选人:
我们项目在生产环境使用RabbitMQ集群,采用镜像队列模式,一主多从结构。
-
主节点处理所有操作并同步给从节点,若主节点宕机,从节点可接替为主节点,但需注意数据同步的完整性。
那出现丢数据怎么解决呢?
候选人:
使用仲裁队列,主从模式,基于Raft协议实现强一致性数据同步,简化配置,提高数据安全性。
Kafka是如何保证消息不丢失?
候选人:
Kafka保证消息不丢失的措施包括:
-
生产者使用异步回调发送消息,设置重试机制应对网络问题。
-
在Broker中通过复制机制,设置
acks参数为all,确保消息在所有副本中都得到确认。 -
消费者手动提交消费成功的offset,避免自动提交可能导致的数据丢失或重复消费。
-
Kafka中消息的重复消费问题如何解决?
候选人:
通过以下方法解决Kafka中的重复消费问题:
-
禁用自动提交offset,手动控制offset提交时机。
-
确保消息消费的幂等性,例如通过唯一主键或分布式锁。
-
Kafka是如何保证消费的顺序性?
候选人:
Kafka默认不保证消息顺序性,但可以通过以下方法实现:
-
将消息存储在同一个分区,通过指定分区号或相同的业务key来实现。
-
Kafka的高可用机制了解吗?
候选人:
Kafka的高可用性主要通过以下机制实现:
-
集群部署,多broker实例,单点故障不影响整体服务。
-
复制机制,每个分区有多个副本,leader和follower,leader故障时从follower中选举新leader。
-
解释一下复制机制中的ISR?
候选人:
ISR(In-Sync Replicas)指与leader保持同步的follower副本。
-
当leader故障时,优先从ISR中选举新leader,因为它们数据一致性更高。
-
Kafka数据清理机制了解吗?
候选人:
Kafka的数据清理包括:
-
基于消息保留时间的清理。
-
基于topic数据大小的清理,可配置删除最旧消息。
-
Kafka中实现高性能的设计有了解过吗?
候选人:
Kafka高性能设计包括:
-
消息分区,提升数据处理能力。
-
顺序读写,提高磁盘操作效率。
-
页缓存,减少磁盘访问。
-
零拷贝,减少数据拷贝和上下文切换。
-
消息压缩,减少IO负载。
-
分批发送,降低网络开销。


















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









