




 本文介绍如何使用Python进行带参数的网络请求,以爬取QQ音乐平台上的用户歌曲信息并实现翻页功能。通过分析Network中的Headers参数,将查询字符串转化为字典形式,利用自动化处理简化代码。
本文介绍如何使用Python进行带参数的网络请求,以爬取QQ音乐平台上的用户歌曲信息并实现翻页功能。通过分析Network中的Headers参数,将查询字符串转化为字典形式,利用自动化处理简化代码。
在Network中的Headers中的Query String Parameters中找到下面的参数
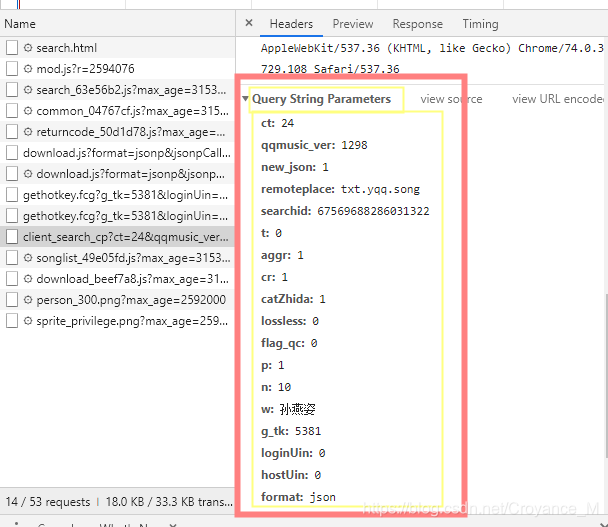
把上面的参数放在一个字典中,记得要加上引号''和逗号, 由于加这些比较麻烦,写了个小函数,自动加上引号和逗号
def add_yinhao(test):
#将复制来的param加上引号如下
#test="""'content'"""
test=test.replace(' ','')
test=test.replace("\n","',\n'") #换行
print(test.replace(":","':'"))
#但是字典首尾要自己加上单引号
- 简单的练习
爬取QQ音乐任何人的歌以及翻页
import requests
from bs4 import BeautifulSoup
import json
url='https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
for i in range(2): #只遍历前两页的歌曲
params={
'ct':'24',
'qqmusic_ver':'1298',
'new_json':'1',
'remoteplace':'txt.yqq.song',
'searchid':'64221885833364721',
't':'0',
'aggr':'1',
'cr':'1',
'catZhida':'1',
'lossless':'0',
'flag_qc':'0',
'p':str(i+1),
'n':'10',
'w':'孙燕姿', #可变
'g_tk':'5381',
'loginUin':'943413047',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0'
}
res=requests.get(url,params=params)
#上面get的网址是network中,client_search_cp...中Header中URL的网址,而且是?问号之前的内容,?问号之后是参数params里的内容
js=res.json() #使用json()方法将response对象转换为字典/列表
list_m=js['data']['song']['list']
for m in list_m:
print('歌名:《'+m['name']+'》')
print('专辑:《'+m['album']['title']+'》')
print('播放链接:https://y.qq.com/n/yqq/song/'+m['mid']+'.html\n')


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









