




“COUNT(*) 和 COUNT(1) 哪个快?” 这个问题,堪称是数据库领域的“月经贴”,每隔一段时间就会在技术社区引发热议。
有人说 COUNT(1) 更快,因为它不涉及列的解析;也有人说 COUNT(*) 是 SQL-92 标准,有神秘的官方优化。而 COUNT(column) 则在特定场景下默默地发挥着作用。
作为一名与数据打了多年交道的开发者或 DBA,你是否也曾被这个问题困扰?你是否也曾在代码审查时,为同事写的 COUNT(1) 而感到一丝不确定?
目录
为什么 InnoDB 不能像 MyISAM 那样存储总行数?
一. 正本清源:COUNT 函数的三种面孔
在深入底层之前,我们必须明确这三种写法的确切含义:
-
COUNT(*): 这是 SQL-92 标准定义的语法,用于计算结果集中的总行数。*在这里并不是指“所有列”,而是一个通配符,代表“一行数据”。MySQL 优化器会忽略*,它不关心你查的是哪些列,只关心有多少行。 -
COUNT(1): 这是一种常见的写法。1是一个常量。它的作用是计算结果集中,值为1的这个表达式不为NULL的行数。因为常量1永远不为NULL,所以其效果等同于计算总行数。 -
COUNT(column): 这种写法用于计算结果集中,指定column列值不为NULL的行数。
一句话总结: COUNT(*) 和 COUNT(1) 的目标是统计总行数,而 COUNT(column) 的目标是统计特定列非空值的行数。它们的意图有本质区别。
二. MyISAM 引擎:简单粗暴的 O(1) 速度神话
MyISAM 是 MySQL 早期的默认存储引擎,以其简单的结构和高速的读性能著称。它的 COUNT 机制也体现了这种“简单粗暴”的哲学。
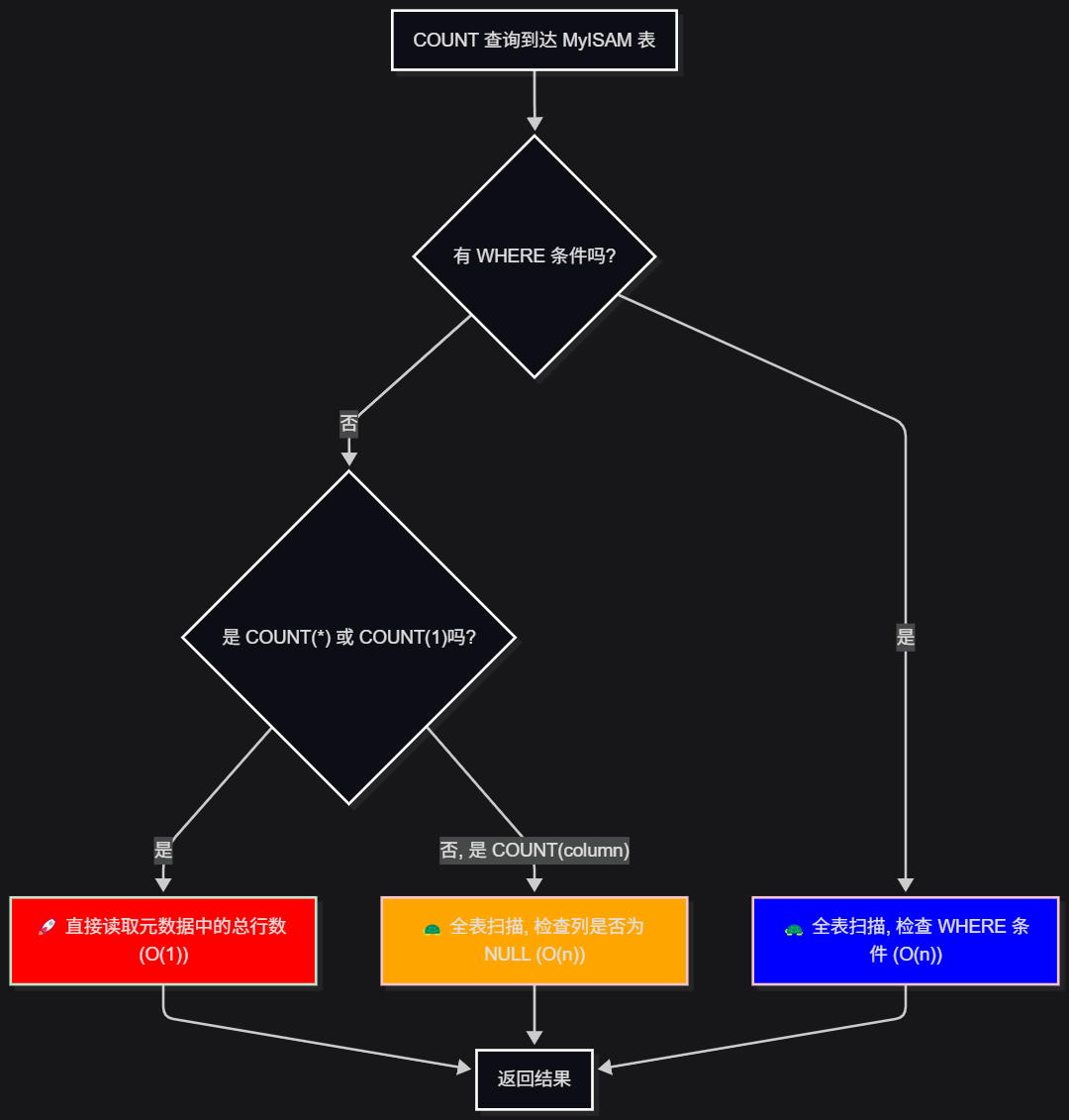
无 WHERE 条件下的 COUNT
当你执行 SELECT COUNT(*) FROM your_table; 且 your_table 的引擎是 MyISAM 时,这个查询的速度快到令人发指,几乎是瞬时完成,无论表有多大。
底层原理: MyISAM 引擎在物理上为每张表存储了一个元数据信息,其中就包含了该表的总行数 (total rows)。这个值被精确地维护在 .MYD 文件中。当收到一个没有 WHERE 条件的 COUNT(*) 或 COUNT(1) 请求时,MySQL 服务器根本不需要去扫描任何数据行,而是直接从存储引擎读取这个预先计算好的计数值。这个操作的时间复杂度是 O(1),即常数时间,与表的大小无关。
有 WHERE 条件下的 COUNT
一旦你的查询带上了 WHERE 子句,比如 SELECT COUNT(*) FROM your_table WHERE status = 1;,MyISAM 的 O(1) 神话就破灭了。
底层原理: 因为 WHERE 条件需要筛选特定的行,预存的总行数就派不上用场了。此时,MyISAM 别无选择,只能进行全表扫描 (Full Table Scan),逐行检查是否满足 WHERE 条件,然后累加计数。这个过程的时间复杂度是 O(n),与表的大小成正比。
对于 COUNT(column),即使没有 WHERE 条件,MyISAM 也必须进行全表扫描,因为它需要逐行判断该列的值是否为 NULL。
MyISAM 工作机制图解
三. InnoDB 引擎:MVCC 下的复杂与权衡
InnoDB 作为现在 MySQL 的默认存储引擎,支持事务、行级锁和外键,其设计比 MyISAM 复杂得多。这种复杂性也直接影响了 COUNT 的实现。
为什么 InnoDB 不能像 MyISAM 那样存储总行数?
核心原因在于 MVCC (Multi-Version Concurrency Control, 多版本并发控制)。
InnoDB 是一个支持事务的引擎。在同一时刻,不同的事务“看到”的表的状态可能是不同的。例如:
-
事务 A 启动,看到表中有 1000 万行。
-
同时,事务 B 插入了 10 行新数据并提交。
-
此时,事务 A 由于其事务隔离级别(如可重复读),依然“看”不到这 10 行新数据,对它来说,总行数还是 1000 万。
-
而一个新的事务 C 启动,它能“看”到事务 B 提交的数据,对它来说,总行数是 1000 万 + 10 行。
在这种情况下,如果 InnoDB 像 MyISAM 一样只维护一个单一的、全局的总行数,这个数字对哪个事务来说才是准确的呢?答案是:对谁都不准确。因此,InnoDB 没有预存一个全局的总行数。它必须在每次收到 COUNT 请求时,实时地去计算行数。
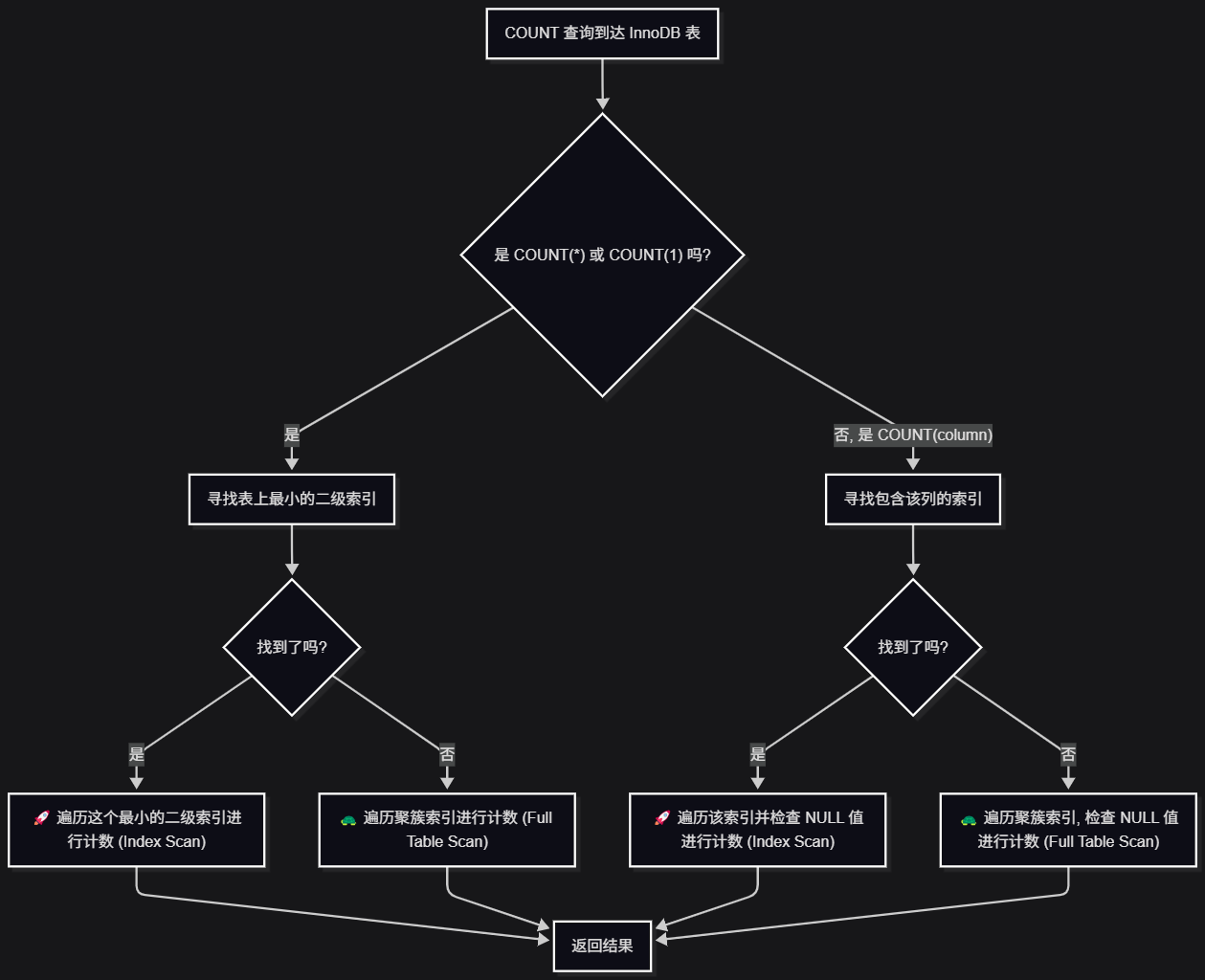
COUNT(*) 与 COUNT(1) 的“双胞胎”之谜
在 InnoDB 中,COUNT(*) 和 COUNT(1) 的性能完全没有区别。
底层原理: MySQL 优化器在解析这两种语法时,会把它们都识别为“计算总行数”。它知道常量 1 永远非空,所以 COUNT(1) 的逻辑等同于 COUNT(*)。优化器会将它们转换为完全相同的执行计划。
那么,这个执行计划是什么呢?InnoDB 的目标是以最小的代价扫描并计数。它会遵循以下策略:
-
寻找最小的二级索引 (Secondary Index):InnoDB 的数据存储在聚簇索引(Clustered Index,通常是主键)中,它包含了所有列的数据,非常庞大。而二级索引只包含索引列和主键值,体积小得多。
-
遍历索引:优化器会选择一个最小的可用二级索引进行遍历。因为它只需要计数,不需要读取数据行,扫描更小的索引意味着更少的 I/O 操作和更快的速度。
-
全表扫描:如果表上没有任何二级索引,InnoDB 将被迫扫描聚簇索引,这等同于全表扫描,性能最差。
所以,COUNT(*) 和 COUNT(1) 的性能,取决于是否存在一个合适的、小巧的二级索引。
COUNT(column) 的角色
COUNT(column) 的逻辑就有所不同了。优化器必须选择一个包含 column 列的索引进行扫描。
-
如果
column本身就是索引,或者是一个联合索引的前缀,优化器会直接扫描这个索引。由于需要判断值是否为NULL,其效率通常不会比COUNT(*)更高。 -
如果
column没有被索引,InnoDB 别无选择,只能扫描聚簇索引(全表扫描),逐行读取数据,然后判断column是否为NULL。这将非常慢。
InnoDB 如何选择最优 COUNT 路径?
在 InnoDB 中,对于 COUNT(*) 和 COUNT(1),优化器会智能地选择成本最低的路径。对于 COUNT(column),它的选择范围被限定在包含该列的索引上。
InnoDB 工作机制图解
四. 实战 EXPLAIN:用证据说话
理论说再多,不如 EXPLAIN 一看。我们来创建两张结构相同但引擎不同的表。
环境准备
-- 创建一个拥有100万数据的用户表 (MyISAM)
CREATE TABLE `user_profiles_myisam` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL,
`email` varchar(100) DEFAULT NULL, -- email可以为NULL
`status` tinyint(4) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_status` (`status`) -- 在 status 列上创建一个二级索引
) ENGINE=MyISAM;
-- 创建一个拥有100万数据的用户表 (InnoDB)
CREATE TABLE `user_profiles_innodb` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL,
`email` varchar(100) DEFAULT NULL, -- email可以为NULL
`status` tinyint(4) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_status` (`status`) -- 在 status 列上创建一个二级索引
) ENGINE=InnoDB;
-- (此处省略插入100万条数据的存储过程)
-- 假设两张表都已填充了100万行数据,其中部分email为NULL
MyISAM 性能分析
-- 查询1: 无条件的 COUNT(*)
EXPLAIN SELECT COUNT(*) FROM user_profiles_myisam;
EXPLAIN 输出的关键信息: 在 Extra 列,你会看到 Select tables optimized away。这正是 MyISAM 读取元数据计数的证据,表示 MySQL 甚至不需要访问表就能得到结果。
InnoDB 性能分析
-- 查询2: COUNT(*)
EXPLAIN SELECT COUNT(*) FROM user_profiles_innodb;
EXPLAIN 输出的关键信息:
-
type:index -
key:idx_status -
Extra:Using index这说明优化器选择了更小的idx_status索引进行全索引扫描来计数,而不是扫描巨大的主键索引。
-- 查询3: COUNT(1)
EXPLAIN SELECT COUNT(1) FROM user_profiles_innodb;
EXPLAIN 输出的关键信息: 你会发现,其输出与 COUNT(*) 完全一致。这证明了在 InnoDB 中,COUNT(*) 和 COUNT(1) 被优化成了相同的执行计划。
-- 查询4: COUNT(status)
EXPLAIN SELECT COUNT(status) FROM user_profiles_innodb;
EXPLAIN 输出的关键信息: 输出同样与 COUNT(*) 几乎一样,因为它也利用了 idx_status 索引。
-- 查询5: COUNT(email)
EXPLAIN SELECT COUNT(email) FROM user_profiles_innodb;
EXPLAIN 输出的关键信息:
-
type:index -
key:PRIMARY(或者可能是idx_status,取决于优化器评估) -
Extra:Using index由于email列没有索引,优化器可能会选择扫描主键(全表扫描)或者扫描idx_status然后回表查询email值。无论哪种,成本都可能比直接扫描idx_status要高。如果它选择了扫描idx_status,那是因为优化器认为即使需要回表,也比全表扫描聚簇索引要快。
五. 结论与最佳实践
| 场景 |
|
|
| 性能王者 |
|---|---|---|---|---|
| MyISAM (无 WHERE) | O(1), 极快 | O(1), 极快 | O(n), 慢 |
|
| MyISAM (有 WHERE) | O(n), 全表扫描 | O(n), 全表扫描 | O(n), 全表扫描 | 无明显差异 |
| InnoDB (无 WHERE) | O(n), 扫描最小索引 | O(n), 扫描最小索引 | O(n), 扫描列索引或全表 |
|
| InnoDB (有 WHERE) | O(n), 索引扫描 | O(n), 索引扫描 | O(n), 索引扫描 | 无明显差异 |
最终结论:
-
COUNT(*)vsCOUNT(1): 在 InnoDB 中,它们没有任何性能差异。在 MyISAM 中也一样。COUNT(1)比COUNT(*)快的说法,是一个流传已久的都市传说。 -
引擎决定一切: 性能的核心差异在于存储引擎的实现。MyISAM 在无
WHERE时有 O(1) 的绝对优势,而 InnoDB 必须进行实时扫描。 -
索引是 InnoDB 的生命线: 在 InnoDB 中,
COUNT(*)的性能高度依赖于是否存在一个体积小巧的二级索引。如果没有,它将退化为全表扫描。
最佳实践建议:
-
无脑用
COUNT(*): 鉴于COUNT(*)是 SQL 标准语法,且意图最清晰(就是统计行数),同时 MySQL 优化器对它做了专门的优化,请始终使用COUNT(*)。这让你无需纠结,代码也更具可读性。 -
为 InnoDB 表创建小索引: 如果你的业务需要频繁地对一张大 InnoDB 表进行
COUNT操作,可以考虑添加一个体积很小的二级索引,例如在某个TINYINT类型的状态列上建索引。这将显著提升COUNT(*)的速度。 -
避免
COUNT(非索引列): 除非你的业务逻辑确实需要统计某非索引列的非空值数量,否则应极力避免这种写法,因为它很可能导致 InnoDB 进行全表扫描。 -
考虑缓存和汇总表: 对于上亿级别的超大表,任何
COUNT操作都是昂贵的。此时应考虑在应用层做缓存,或者创建汇总表 (Summary Table),通过触发器或定时任务来维护一个准确的计数值。这是解决超大表计数问题的根本之道。
希望这篇深度剖析能彻底解开你心中关于 COUNT 的疑惑,让你在未来的开发中,能够更加自信、从容地写出高效的 SQL。
六. 附录:图解
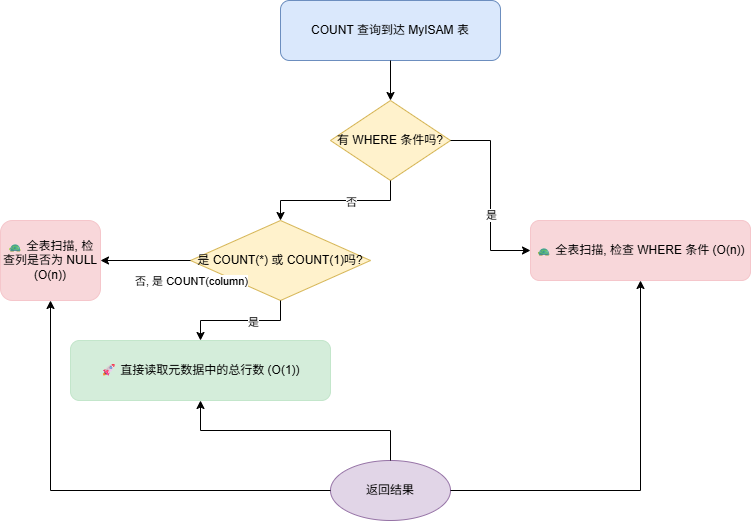
MyISAM 图解:
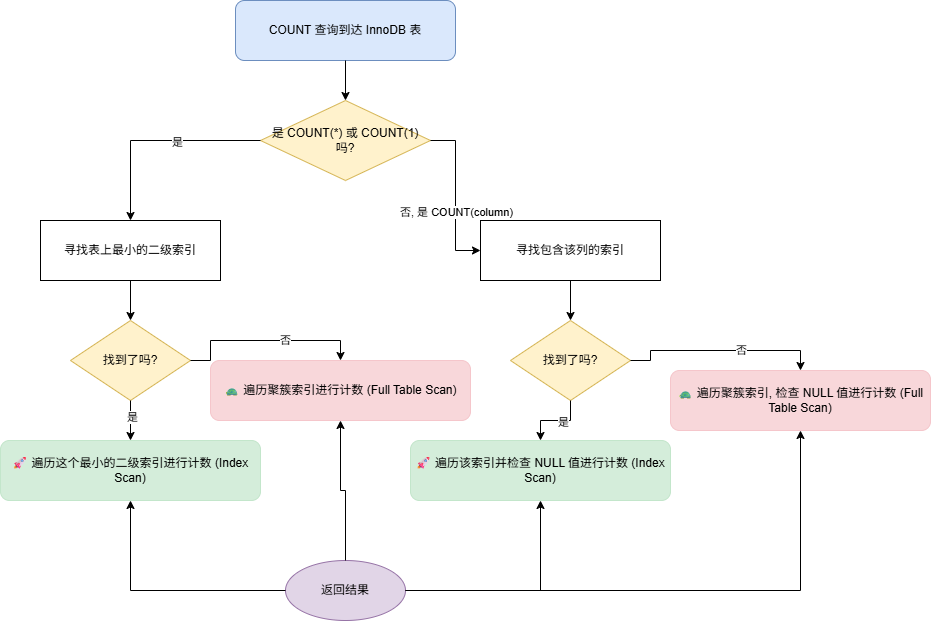
InnoDB 工作图接 :


















 2610
2610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











