




嘿,哥们!还在为服务的并发量上不去而头疼吗?用户量一上来,CPU、内存就告急,接口响应慢得像蜗牛?别慌,今天我们就来盘一盘,怎么用最新的Spring Boot 3,把服务性能调教到极致,让它从容应对C10K(即同时处理1万个并发连接)甚至更高的挑战。
目录
二、Spring Boot 3的王牌:虚拟线程 (Virtual Threads)
一、为啥你的“开箱即用”Spring Boot扛不住?
首先得明白,Spring Boot默认的配置,是为了“通用”和“易用”,而不是为了“高性能”。它默认内嵌的Tomcat采用的是**“一个请求一个线程(Thread-Per-Request)”**的模型。
这模型在并发量小的时候很美好,简单直接。但C10K一来,问题就暴露了:
-
线程是昂贵的:每个请求都得占用一个操作系统(OS)线程,而OS线程是很宝贵的资源,它需要消耗不少内存(通常是1MB左右),而且频繁创建和销毁的开销也很大。
-
I/O阻塞是性能杀手:大部分Web应用都是I/O密集型的,比如请求数据库、调用其他微服务。在传统模型下,一个请求在等待I/O时,对应的线程就被“阻塞”了,啥也干不了,只能干等着,白白占着茅坑。
当成千上万的请求涌入,你的服务器很快就会因为线程数量达到上限而无法响应新的请求。
下面这张图来直观地理解这个窘境:
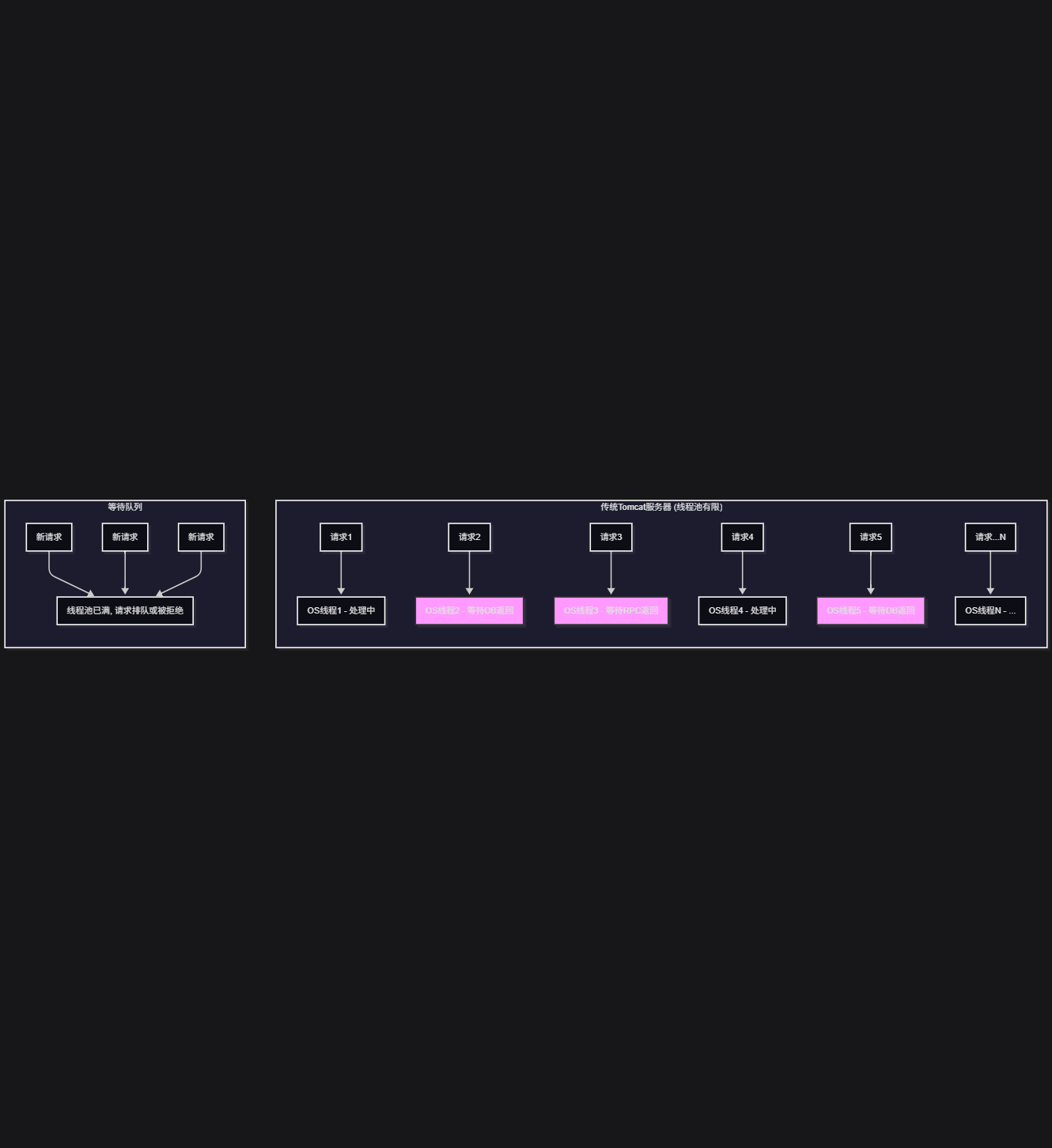
看到没?粉色的线程都在“摸鱼”,但资源却一点没少占。这就是瓶颈所在。
二、Spring Boot 3的王牌:虚拟线程 (Virtual Threads)
好消息是,Java 19带来的Project Loom(并在Java 21成为正式功能),给了我们一个大杀器——虚拟线程。Spring Boot 3第一时间就集成了它。
啥是虚拟线程?简单说:
它是一种由JVM自己管理的超轻量级线程。成千上万个虚拟线程可以被映射到一小组OS平台线程上运行。当虚拟线程遇到I/O阻塞时,它不会霸占平台线程,而是会被“卸载”,让平台线程去执行其他任务。
这简直就是为I/O密集型应用量身定做的!
在Spring Boot 3里启用虚拟线程,简单到令人发指,只需要在application.properties里加一行配置:
# 就这一行,你的Tomcat就开始用虚拟线程处理请求了
spring.threads.virtual.enabled=true
开启后,整个模型就变成了这样:
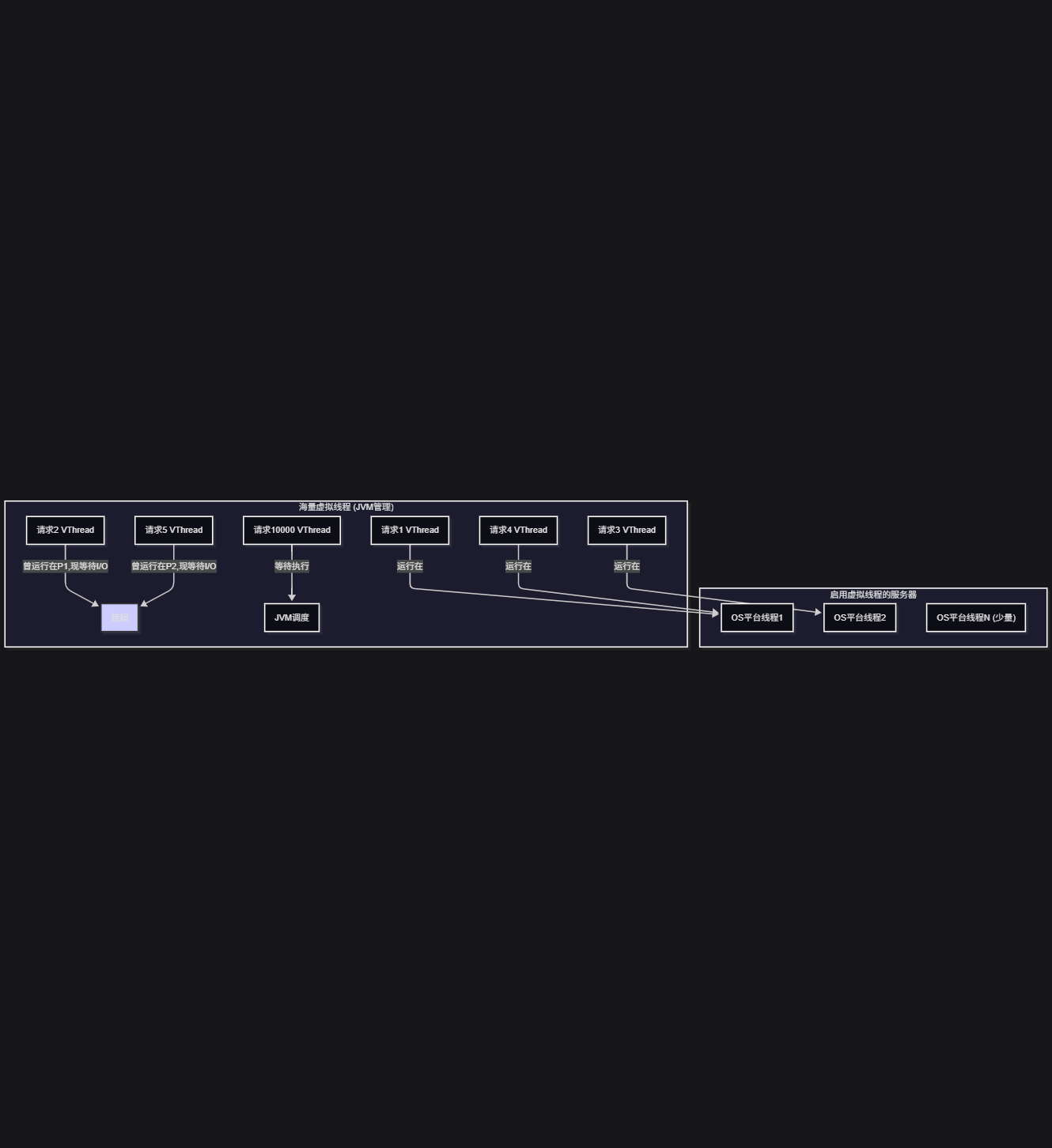
现在,就算有1万个请求在等待数据库返回,也只会占用极少的平台线程,服务器的吞吐量瞬间就上去了。
三、光有虚拟线程还不够:深入配置调优
别高兴得太早,以为开了虚拟线程就万事大吉了。真实的系统是个木桶,性能取决于最短的那块板。下面我们就来一个个地加固这些木板。
3.1. Web服务器调优 (以Tomcat为例)
即便用了虚拟线程,Tomcat的一些核心参数还是需要我们去关注。
# application.yml
server:
tomcat:
# 最大连接数。这是服务器愿意接受的总连接数。对于C10K,这个值必须调大。
max-connections: 12000
# 等待队列长度。当所有线程都在忙时,新来的连接会在这里排队。
accept-count: 2000
threads:
# 虽然用了虚拟线程,但平台线程池还是存在的,用于处理一些内部任务。
# 这个值不需要很大,保持默认或根据CPU核心数设置即可。
max: 200 # 这个是平台线程数,不是虚拟线程数
3.2. 数据库连接池:最关键的瓶颈!
这是最最最重要的一环!你的应用能创建1万个虚拟线程,但你的数据库能同时处理1万个连接吗?显然不能。数据库连接是昂贵的物理资源。
所以,千万不要把连接池大小设置成10000!
HikariCP是Spring Boot默认的连接池,性能极佳。对于虚拟线程,它的配置哲学需要改变:
# application.yml
spring:
datasource:
hikari:
# 这是关键!连接池大小不需要很大。一个经验法则是 (CPU核心数 * 2) + 1。
# 为什么?因为虚拟线程的哲学是“快速借用,快速归还”。
# 只要你的SQL执行够快,小连接池也能服务大量请求。
maximum-pool-size: 20
# 最小空闲连接数,可以和最大值设成一样,避免高峰期动态创建连接的开销。
minimum-idle: 20
# 连接超时时间。如果连接池满了,一个请求最多等多久。可以设短一点,快速失败。
connection-timeout: 2000 # 2秒
# 最大生命周期。一个连接在池里活多久,避免因网络问题产生死连接。
max-lifetime: 600000 # 10分钟
核心思想:用一个小的、高效的连接池,配合执行飞快的SQL,让每个虚拟线程拿到连接后,迅速完成数据库操作并释放连接,从而实现高周转率。你的优化重点应该放在减少SQL执行时间上。
3.3. JVM调优
对于C10K,JVM参数也得跟上。
# 启动脚本里的JAVA_OPTS
-Xms4g -Xmx4g # 堆内存初始值和最大值设成一样,避免GC时动态调整大小带来性能抖动
-XX:+UseG1GC # 使用G1垃圾收集器,在响应时间和吞吐量之间有很好的平衡
-XX:MaxGCPauseMillis=200 # 期望的最大GC停顿时间
-Djava.security.egd=file:/dev/./urandom # 解决Tomcat启动慢的问题
四、架构与代码层面的神操作
配置拉满了,代码层面也不能拖后腿。
4.1. 异步化你的CPU密集型任务
虚拟线程能解决I/O阻塞,但如果你的代码里有某个计算任务需要消耗大量CPU(比如复杂的加密、图像处理),它还是会霸占着平台线程不放,影响其他虚拟线程。
怎么办?把这种CPU密集型任务扔到专门的线程池里去异步执行。
@Service
public class MyService {
// 创建一个专门用于CPU密集型任务的线程池
private final ExecutorService cpuBoundExecutor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public String handleRequest(String data) {
// ... 一些I/O操作,可以充分享受虚拟线程的好处
// someIoOperation();
// 现在,遇到一个CPU密集型任务
CompletableFuture<String> cpuTask = CompletableFuture.supplyAsync(() -> {
// 在专门的线程池里执行这个耗时计算
return performComplexCalculation(data);
}, cpuBoundExecutor);
// 主虚拟线程可以继续做别的事,或者等待结果
try {
return cpuTask.get(); // 等待异步任务完成
} catch (InterruptedException | ExecutionException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}
private String performComplexCalculation(String data) {
// 模拟一个非常耗CPU的操作
// ...
return "calculated_" + data;
}
}
4.2. 缓存,缓存,还是缓存!
应对高并发,最简单粗暴有效的方法就是减少对下游(尤其是数据库)的直接访问。
-
本地缓存(Caffeine):对于不常变化的数据,用本地缓存顶一下,连网络I/O都省了。
-
分布式缓存(Redis):多实例共享数据,减轻数据库压力。
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
@Service
public class ProductService {
// 加上这个注解,方法的结果就会被缓存。
// 下次用相同的参数调用,直接从缓存返回,根本不执行方法体。
@Cacheable(value = "products", key = "#id")
public Product getProductById(String id) {
// ... 这里是查询数据库的慢操作
System.out.println("正在从数据库查询产品: " + id);
return findProductInDB(id);
}
private Product findProductInDB(String id) {
// 模拟DB查询
try {
Thread.sleep(500); // 模拟慢查询
} catch (InterruptedException e) {}
return new Product(id, "My Awesome Product");
}
}
4.3. 终极奥义:WebFlux响应式编程
如果你的业务逻辑可以被描述为一系列事件流,并且你追求的是极致的资源利用率和最低的延迟,那么可以考虑Spring WebFlux。
WebFlux是完全基于事件驱动和非阻塞的,但学习曲线也更陡峭。它和虚拟线程是解决并发问题的两种不同思路。
-
虚拟线程:用大家熟悉的同步阻塞写法,达到异步非阻塞的效果,迁移成本低。
-
WebFlux:需要用响应式API(Mono/Flux)重构代码,心智负担重,但性能天花板更高。
对于大部分现有项目,优先选择虚拟线程进行优化,性价比最高。
总结
好了,哥们,一口气说了这么多,我们来捋一捋。要让你的Spring Boot 3应用在C10K下活下来并活得滋润,你需要一套组合拳:
-
开启虚拟线程:这是最核心的一步,解决了I/O阻塞的根本问题。(
spring.threads.virtual.enabled=true) -
压榨数据库连接池:用小而快的连接池,配合高效SQL,实现高周转。
-
调优Web服务器和JVM:把基础打牢,别让它们拖后腿。
-
代码层面优化:异步化CPU密集任务,善用缓存。
-
画个图总结一下:
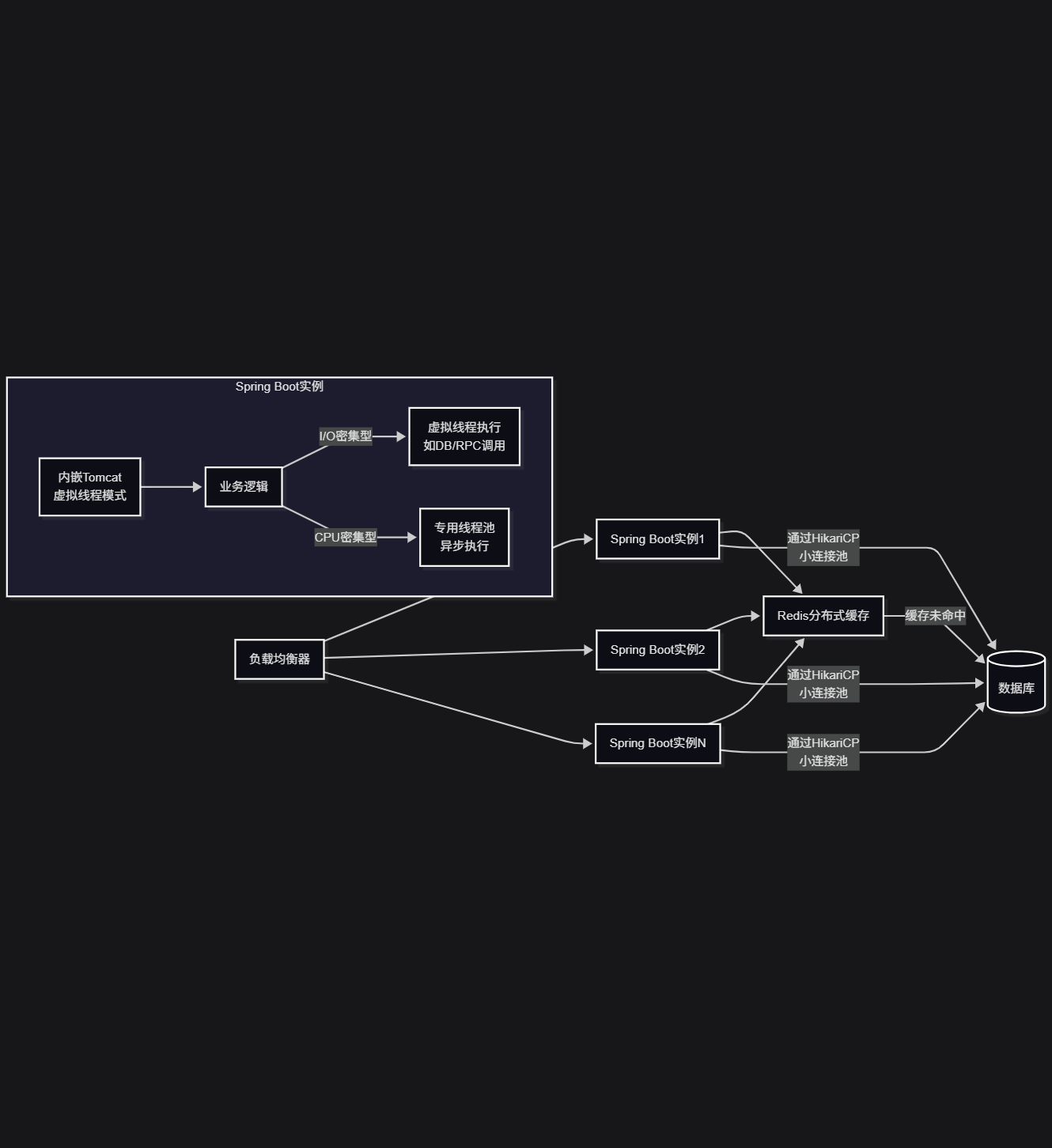
性能优化没有银弹。它是一个系统工程,需要你从上到下,从配置到代码,全面地进行分析和调整。
希望这篇能帮你在下一次性能挑战中,成为那个最靓的仔!开干吧!


















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











