



嘿,兄弟,是不是最近感觉应用越来越慢,一个查询转半天,数据库CPU时不时就飙红?老板在身后关切地问你:“小王啊,咱们的用户体验是不是得优化一下?” 你一查数据库,好家伙,核心业务表不知不觉已经突破500万行了。
先别急着跑路,也别想着连夜升级服务器。500万数据,说多不多,说少不少,它正好是一个绝佳的“临界点”,逼着我们从“小子,我会写CRUD”的阶段,迈向“架构师,我懂海量数据”的阶段。今天,咱们就来聊聊这个让你升职加薪的必备技能 —— 分库分表。
为啥一张表扛不住了?从根儿上理解瓶颈
想象一下,你的数据库表是一本巨大的电话簿。
-
刚开始:只有几百页,找人(查询)很快,加个新人(插入)也很方便。
-
500万数据后:这本电话簿变得比牛津词典还厚。
-
查询慢:就算有索引(目录),目录本身也变得巨大无比。MySQL的索引(通常是B+树)层级会变深,每次查询需要更多的磁盘I/O。
-
写入慢:每次插入或更新,数据库都要维护这个巨大的索引,如果并发高,各种锁(行锁、表锁)的竞争会急剧增加,大家都在排队,系统自然就慢了。
-
运维难:想给这张几千万行的大表加个字段?
ALTER TABLE能锁死你几个小时。备份和恢复也成了噩梦。
-
当单表成为瓶颈时,我们就得想办法给它“减负”。怎么减?答案就是“分而治之”。
一、分库分表的两大流派:垂直拆分 vs 水平拆分
“分库分表”听起来高大上,其实核心思想就两种拆分方式。
1. 垂直拆分(Vertical Sharding)
这比较好理解,就是“按列拆分”。好比你的用户信息表里,既有id, username, password这些基本信息,又有profile_details, bio, last_login_ip这种不常用或者比较大的字段。
怎么拆? 把一张宽表,拆成多张窄表。
-
核心表:存放
id,username等高频访问的核心字段。 -
扩展表:存放
bio等低频访问或大文本字段。
优点:
-
减少单表的宽度,提高单行数据的读取效率。
-
可以把冷热数据分离,核心业务只访问核心表,速度更快。
何时用? 当你的表字段特别多(比如超过50-100个),或者有几个TEXT、BLOB大字段拖慢了整个表的查询速度时,垂直拆分是个不错的选择。
2. 水平拆分(Horizontal Sharding)
这是我们应对“海量数据”的主力武器,就是“按行拆分”。500万的数据量,主要矛盾在于“行太多”,而不是“列太多”。
怎么拆? 把一张大表的数据,按照某种规则,分散到多个结构完全相同的小表中。比如,user表有600万数据,我们可以把它拆成3个表:user_0, user_1, user_2,每个表存200万数据。
这些小表可以放在同一个数据库里(分表),也可以放在不同的数据库实例上(分库)。
-
只分表:解决了单表数据量过大的问题,但所有表还在一个数据库里,共享同一个CPU、内存和I/O。适合数据量大但并发压力不那么集中的场景。
-
分库又分表:这是终极形态。把数据分散到不同的物理服务器上,不仅解决了数据量问题,还分摊了查询压力,实现了真正的分布式。
二、设计篇:如何优雅地进行水平拆分?
好了,理论讲完,上干货。设计一个水平拆分方案,你必须想清楚三个核心问题。
第一步:选择“分片键”(Shard Key)
这是最最最重要的一步,没有之一。分片键就是你用来决定“这条数据该去哪个表”的依据。
好的分片键特征:
-
业务核心:必须是查询中
WHERE子句里最常用的那个字段,比如订单表的order_id,用户表的user_id。 -
均匀分布:键值必须能让数据均匀地散落在各个表中,避免“数据倾斜”(某个表数据特别多,成为新瓶颈)。
-
相对稳定:分片键的值最好是创建后就不会改变的。
错误示范:用create_time做分片键。会导致新数据全部涌入最新的那个表,造成“热点”问题。用gender做分片键,数据会严重不均。
第二步:选择“路由算法”(Sharding Algorithm)
选好了分片键,怎么根据它来计算具体去哪个表呢?主流算法有两种。
-
范围分片 (Range Sharding)
-
玩法:按ID范围或时间范围来分。比如
user_id1-100万在user_0,101-200万在user_1。 -
优点:实现简单,扩容容易(加个新表就行)。对于范围查询非常友好(比如查询最近一个月注册的用户)。
-
缺点:容易数据倾斜。如果
user_id是自增的,那么新数据永远只写一个表。
-
-
哈希取模分片 (Hash/Modulo Sharding)
-
玩法:对分片键进行哈希计算,然后对分表总数取模。公式:
table_index = hash(shard_key) % N(N是分表的数量)。 -
优点:数据分布非常均匀,能有效避免热点问题。
-
缺点:扩容极其困难。比如你从3个表扩到4个表,
% 3变成了% 4,几乎所有的数据都要重新计算位置并进行迁移(数据迁移工程量巨大)。范围查询是灾难,需要查所有表。
-
业界优化方案:为了解决哈希取模扩容难的问题,业界发明了一致性哈希算法,它在增减节点时,只会影响到少量的数据,这里不展开,可以作为进阶课题研究。
新手建议:对于大多数场景,哈希取模是最常见的选择。在项目初期就预估好未来几年的数据量,设定一个相对充足的分表数量(比如16或32),短期内就不用考虑扩容问题了。
三、查询篇:分库分表后,数据要怎么查?
拆分一时爽,查询火葬场。这可能是很多人的担忧。别怕,我们分场景来看。
场景一:带分片键的查询(最理想)
这是最简单、最高效的查询。比如,我们要查询user_id = 123的用户信息。
-
路由计算:你的应用层(或中间件)拿到
user_id = 123。 -
执行算法:
123 % 3 = 0。 -
精确定位:应用知道要去
user_0表里查。 -
直接查询:
SELECT * FROM user_0 WHERE id = 123;
整个过程干净利落,和查单表几乎一样快。这就是为什么我们强调分片键一定要是常用查询条件的原因。
场景二:不带分片键的查询(最头疼)
现在来了个需求:根据用户名username = 'Gemini'来查询用户信息。username不是分片键,我们根本不知道这个用户在哪张表里。
怎么办?硬着头皮上:聚合查询(Scatter-Gather)
-
广播查询:将
SELECT * FROM ... WHERE username = 'Gemini'这个查询,同时发送给user_0,user_1,user_2所有三个表。 -
各自执行:每个分表在自己的地盘上执行查询。
-
结果聚合:应用层或中间件收集所有分表的返回结果。
-
数据归并:将结果合并,如果需要排序或分页,就在内存中对聚合后的结果进行处理。
显而易见的缺点:非常低效!分表越多,性能越差。要尽量避免这种查询。
如何优化这种查询?
-
建立“索引表”:创建一个新的映射表,比如
user_mapping,里面只有两列:username和user_id。这个表可以不分片,或者用username的哈希做分片。查询时,先查这个映射表,拿到user_id,再回到场景一的高效查询。 -
引入搜索引擎:将需要被非分片键查询的数据,同步一份到Elasticsearch或Solr中。利用搜索引擎强大的反向索引能力,实现各种复杂条件的组合查询,然后根据搜到的结果ID,再回数据库查询详情。这是业界最成熟、最主流的方案。
别重复造轮子:善用中间件
看到这里,你可能觉得头都大了。别担心,这些复杂的路由、查询、聚合逻辑,我们不需要从零开始写。业界已经有很多成熟的开源中间件了。
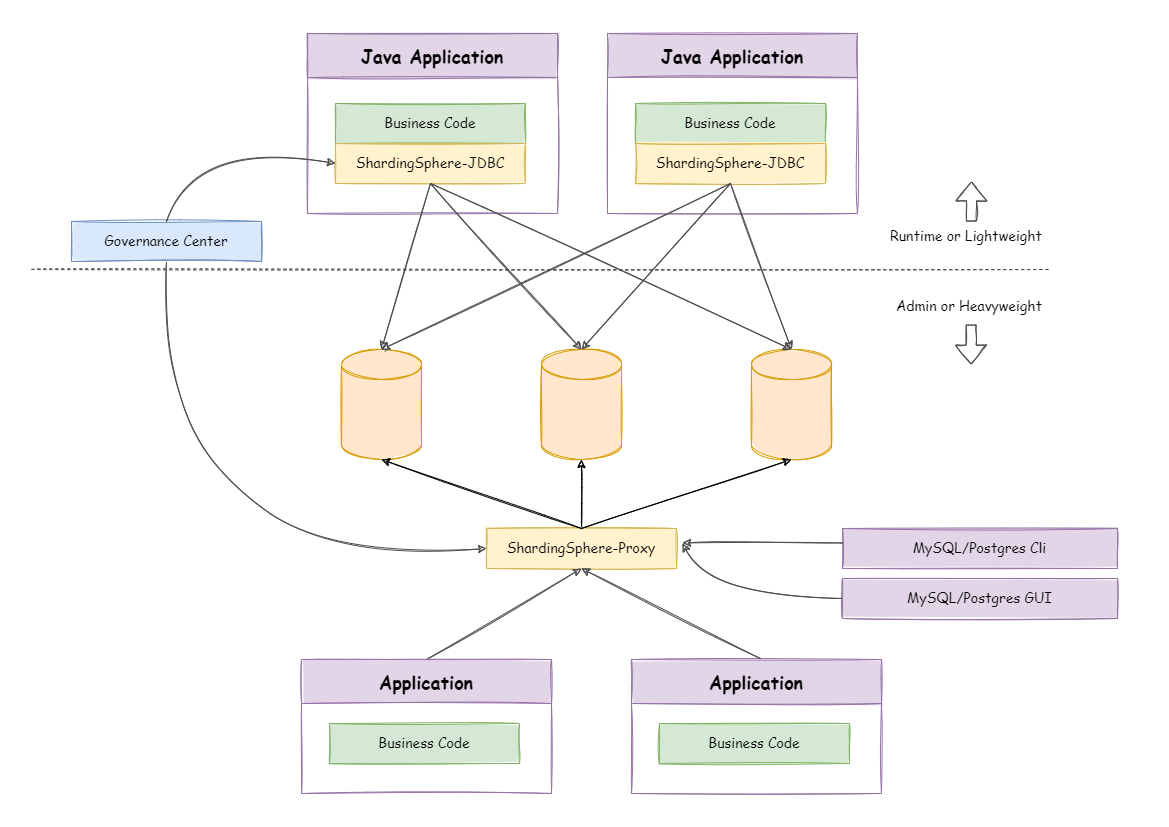
-
Sharding-JDBC (现在是 ShardingSphere 的一部分): 一个基于Java的JDBC驱动层增强。对应用代码的侵入性小,你只需要配置好规则,写SQL时就像在操作一张逻辑表,它会自动帮你路由和聚合。
-
MyCAT / ShardingSphere-Proxy: 数据库代理层。你把它部署成一个独立的中间件服务,你的应用连接的是MyCAT/Proxy,而不是直接连MySQL。它伪装成一个MySQL服务器,在后端帮你完成所有分库分表的操作。对应用完全透明。
对于大部分团队来说,选择一个合适的中间件,远比自己实现一套分库分表逻辑要靠谱得多。
四、总结
回到最初的问题:500万数据,如何设计和查询?
-
评估瓶颈:首先确认是“行太多”导致的性能问题,确定需要水平拆分。
-
设计方案:
-
选好分片键:这是重中之重,选你最核心、最常用的查询ID,比如
user_id。 -
定好路由算法:对于大多数场景,
hash(id) % N是个不错的开始。预估未来数据量,把N定得大一些(如16, 32, 64)。 -
决定分库还是分表:初期可以只分表,当数据库实例本身成为瓶颈时,再上分库。
-
-
改造查询:
-
带分片键的查询:由中间件或代码逻辑自动路由到正确的表。
-
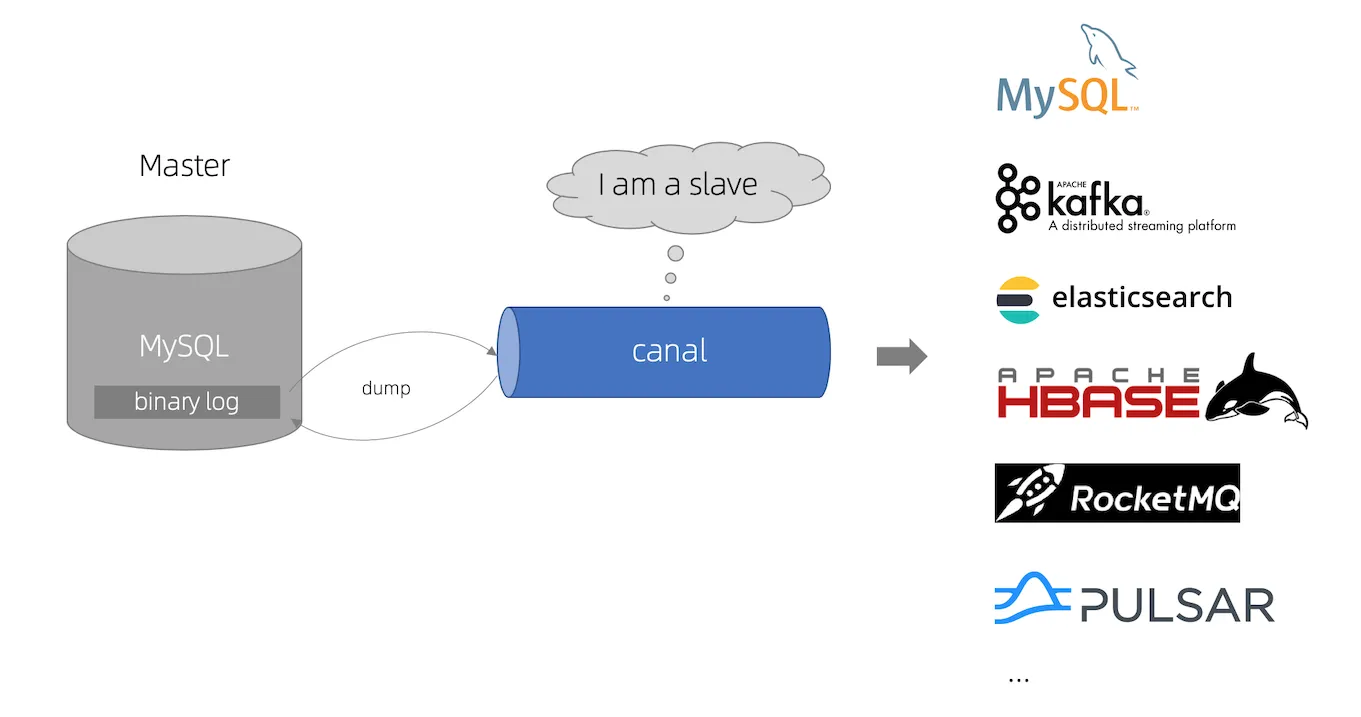
不带分片键的查询:坚决避免全量扫描!通过建立“索引表”或引入“Elasticsearch、HBase、Canal、MQ”来解决。
-
-
引入工具:不要自己造轮子,熟练掌握一种分库分表中间件(如ShardingSphere)的配置和使用。
500万数据不是技术的终点,而是一个架构升级的起点。它标志着你的产品正在成功,用户量正在增长。
坦然面对它,解决它,你收获的将不仅仅是一个更快的系统,更是一个更牛的自己。


















 8901
8901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











