




【导读】
在当今的人工智能世界里,计算机视觉 (CV) 已变得触手可及。如今通过新一代AI开发平台已变得触手可及。然而,许多平台为了追求易用性,往往牺牲了开发者对模型架构的深度控制权——而这正是构建高性能CV模型的关键。本文将探讨为什么平台会限制微调?微调实际上意味着什么?为什么调整主干层对于构建强大的模型至关重要?>>更多资讯可加入CV技术群获取了解哦~
一、计算机视觉中的微调是什么?
当我们使用像 YOLOv5 或 YOLOv8 这样的预训练模型时,它们会预先从大型数据集(例如 COCO)中学习到一些通用知识。微调是指对这些知识进行微调,使模型在您自己的数据集上表现得更好。
微调的常用方法有两种:
-
仅训练头部(head):模型保留原始层,只需为自定义任务训练最后几层(称为“头部”)以适配你的任务。
-
训练整个模型(包括主干backbone):重新训练深层结构,增强模型对新数据的理解能力。
二、什么是主干层和头层?
在 CV 模型中,一般分为三个部分:
-
主干(Backbone):就像引擎,负责从图像中提取特征(颜色、纹理、形状等)。
-
颈部(Neck):中间处理层,整合和增强多尺度特征。
-
头部(Head):最终输出结果,如类别、位置、置信度等。
假设你正在训练一个模型来检测树上的芒果——主干网络学习颜色和形状,而头部则判断它是否是芒果。
三、为什么大多数平台会限制微调?
为了简化使用流程,许多平台(包括Ultralytics等)默认会限制模型微调。这意味着:
-
操作更简单
-
配置文件更轻量
-
训练更快,资源消耗更低
但为了这种简单性,他们做出了一些权衡:
-
灵活性较差:它们不容易暴露深层进行训练。
-
过度拟合的风险:如果用户进行过多微调,模型在未知数据上的表现可能会更差。
-
计算成本:训练完整模型(尤其是主干模型)对 GPU 的要求很高,而且耗时更长。
因此,为了保持简单和适合初学者,这些平台默认仅对头部进行微调。
-
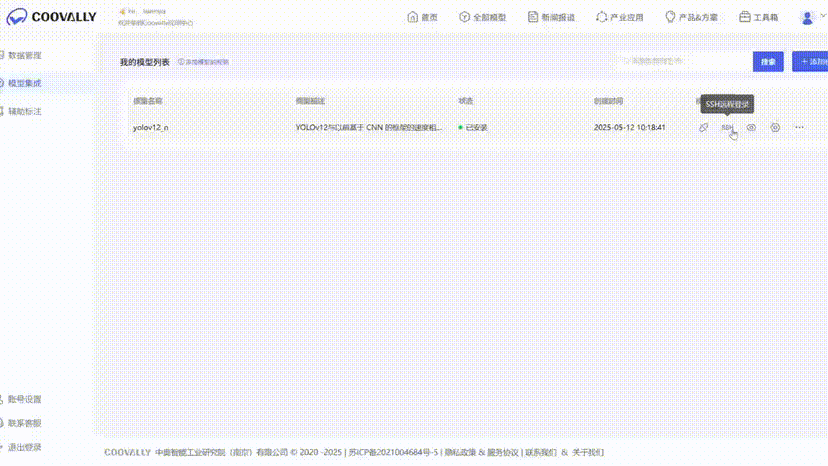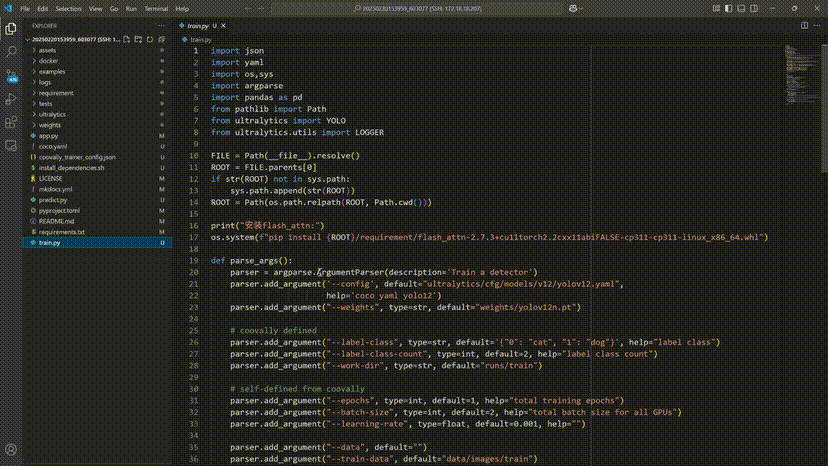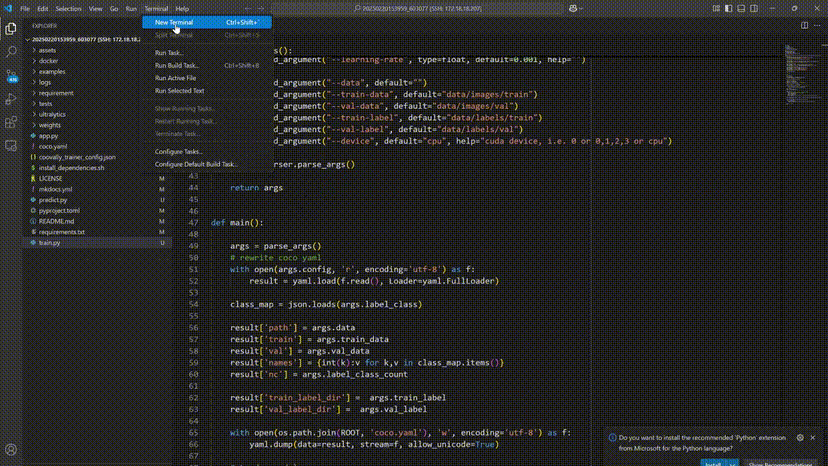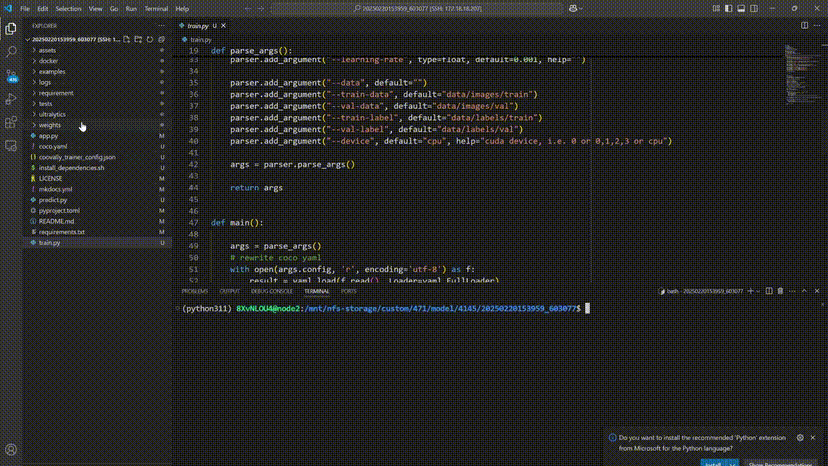
SSH直连云端算力,实时调试更自由!
为了开发者们更加自由调试模型,Coovally平台即将上线SSH远程连接,开发者们可以直接通过SSH连接Coovally的云端算力,基于VS Code、Cursor或Windsurf等开发工具,轻松进行模型算法的开发与改进。
-
从实验到落地,全程高速零代码!
无论是学术研究还是工业级应用,Coovally均提供云端一体化服务:
-
免环境配置:直接调用预置框架(PyTorch、TensorFlow等);
-
免复杂参数调整:内置自动化训练流程,小白也能轻松上手;
-
高性能算力支持:分布式训练加速,快速产出可用模型;
-
无缝部署:训练完成的模型可直接导出,或通过API接入业务系统。
!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
无论你是算法新手还是资深工程师,Coovally以极简操作与强大生态,助你跳过技术鸿沟,专注创新与落地。访问官网,开启你的零代码AI开发之旅!
四、为什么必须微调主干以获得更强大的模型
如果您的数据集与原始数据集(如 COCO)有很大差异,那么仅训练头部是不够的。
-
预训练模型学的是街道车辆
-
你要检测的是水下鱼类
鱼类的颜色、形状、背景和纹理都与街景大不相同。此时,不解冻主干层、只是训练头部的话,模型很难学到真正有用的特征。
所以更强大的微调策略通常包括:
-
解冻主干层(允许它们训练)
-
调整降低学习率(慢慢训练更深的层)
-
可能会更改或添加新层
这使您的模型更强大、更准确,特别是对于小众或复杂的数据集。
五、如何在实践中真正微调骨干
在像 Coovally 这样允许 SSH 自由调试的平台上,你可以完全控制模型训练过程,比如在 PyTorch 中:
for param in model.backbone.parameters():
param.requires_grad = True设置优化器时:
optimizer = torch.optim.SGD([
{'params': model.backbone.parameters(), 'lr': 1e-4},
{'params': model.head.parameters(), 'lr': 1e-3}
])你可以自由地选择训练策略,尝试不同的超参数、结构调整等,真正发挥你对模型的理解和创造力。
-
大模型加持,智能辅助模型调优!
若对模型效果不满意?Coovally即将推出大模型智能调参能力,针对你的数据集与任务目标,自动推荐超参数优化方案,让模型迭代事半功倍!

六、结论
计算机视觉并不只是“即插即用”,真正的性能提升来自于对模型的深入理解和精细打磨。
借助 Coovally 平台即将上线的 SSH 功能,你可以摆脱传统平台的限制,深入模型内部,按需微调主干、解构架构、甚至自定义训练逻辑。
如果你真的想训练一个强大、专业且适配性强的视觉模型,别满足于默认设置,开始动手探索吧!




















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









