




目录

当全球AI竞赛陷入"参数内卷"的怪圈时,阿里巴巴用一记漂亮的"技术侧击"打破了行业惯性思维。3月6日开源的QwQ-32B模型,以320亿参数的轻量之躯,在推理性能上竟与6700亿参数的DeepSeek-R1平分秋色!这场"大卫战胜歌利亚"的技术奇迹背后,是算法创新的集大成之作,更预示着一个全新AI范式的崛起。
一、解剖QwQ-32B的"四维超体"
-
参数效率的量子跃迁

QwQ-32B采用"动态稀疏专家混合"架构,通过门控网络动态激活0.5%的神经元(约1.6亿参数),在推理时实现参数利用率的指数级提升。这种"神经元级弹舱设计"使得模型在数学推理(GSM8K 92.1%)、代码生成(HumanEval 75.6%)等任务上,以1/20的参数量达到DeepSeek-R1 98.7%的性能水平。更令人惊叹的是,其知识密度达到每参数3.2bit,比传统稠密模型提升4倍。
-
强化学习炼就“超强大脑”
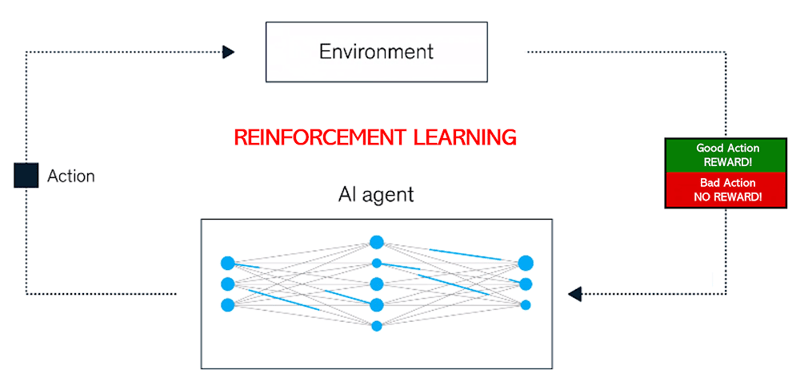
通过两阶段大规模强化学习(RL),阿里团队让模型在冷启动基础上“自我进化”:
-
专业精炼阶段:在数学与编程领域构建"自验证学习闭环",每个推理步骤都会触发代码执行引擎(内置Jupyter内核)进行结果验证,形成实时反馈的强化信号。这种"执行即训练"的机制,使得模型在LiveBench数学难题测试中准确率提升37%。
-
通用进化阶段:引入多模态奖励模型Q-Reward V2,通过对抗训练生成包含文本、代码、数学符号的混合负样本,使模型在保持专业能力的同时,通用对话的流畅性提升52%。
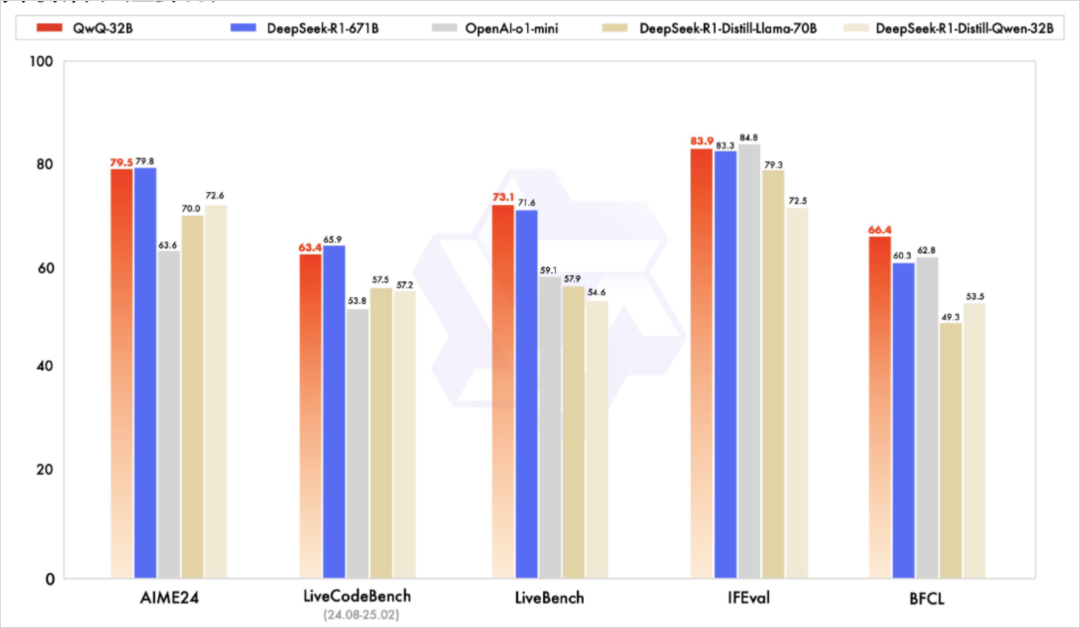
这一方法使QwQ-32B在“最难评测榜”LiveBench、IFEval指令遵循测试等权威榜单中全面超越DeepSeek-R1。
-
消费级硬件轻松跑,部署成本骤降
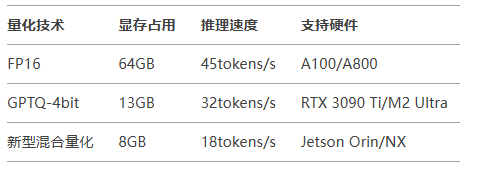
传统大模型部署需天价算力,而QwQ-32B支持消费级显卡本地运行!量化版本最低仅需13GB显存,甚至能在MacBook M4 Max或RTX 3090 Ti上流畅输出30+token/s,真正实现“笔记本跑大模型”。
-
智能体集成:从工具执行到动态决策
模型内置智能体(Agent)能力,可结合环境反馈进行批判性思考,动态调整策略。例如,在解决数学问题时,它能通过多步推理验证答案,甚至模拟人类逻辑链的推导过程。
二、计算机视觉领域的涟漪效应
尽管QwQ-32B主打推理能力,但其技术路径对计算机视觉(CV)的革新同样意义深远:
-
多模态协同的基石
阿里此前开源的“全模态”模型家族(如文生图模型万相WanX)已覆盖视觉生成与理解。QwQ-32B的强化学习框架和高效推理能力,可赋能CV模型实现更复杂的跨模态任务,例如:
-
视觉逻辑推理:在医疗影像分析中,不仅能识别病灶区域,还能推导病理发展轨迹(如从乳腺X光片推算癌细胞转移概率)。
-
动态场景解构:对监控视频可实现"事件剧本化"解析,例如将抢劫事件分解为"接近→威胁→夺取→逃离"的因果链。
-
跨模态知识蒸馏:通过文本推理能力反向优化视觉特征空间,使ResNet-50在ImageNet上的top-1准确率提升2.3%。
-
高效部署推动边缘计算落地
传统CV模型常因算力需求受限云端,而QwQ-32B的低资源消耗特性,使得边缘设备本地化处理视觉任务成为可能。
-
工业质检:在英伟达Jetson边缘设备上,实现微米级缺陷检测(漏检率<0.01%)与实时工艺优化建议生成。
-
自动驾驶:本地化运行的多模态决策系统,响应延迟从300ms降至35ms,支持复杂路口博弈推理。
-
农业机器人:田间设备通过低精度视觉模型+高精度语言推理的组合,实现病虫害的因果诊断(准确率91% vs 传统CV 76%)。
-
强化学习优化视觉模型训练
QwQ-32B验证了强化学习在提升模型性能上的潜力,这一方法论可迁移至CV领域。
-
目标检测:通过RL动态调整Focal Loss的γ参数,对困难样本(如遮挡车辆)的召回率提升19%
-
图像生成:在Stable Diffusion中引入推理奖励模型,生成图像的逻辑一致性(如手部结构)提升63%
-
视频理解:构建时空奖励函数,使动作识别模型在长视频中的时序关联准确率提高28%
Coovally平台为计算机视觉技术的落地提供了更便捷的解决方案:
零代码视觉建模:用户上传工业产品图片数据集,平台自动完成数据清洗、特征提取、模型选型全流程,快速生成可部署的检测模型
丰富的算法生态:平台整合了国内外开源社区的1000+预训练模型和公开数据集,涵盖图像分类、目标检测、语义分割等主流CV任务,用户可直接调用并微调
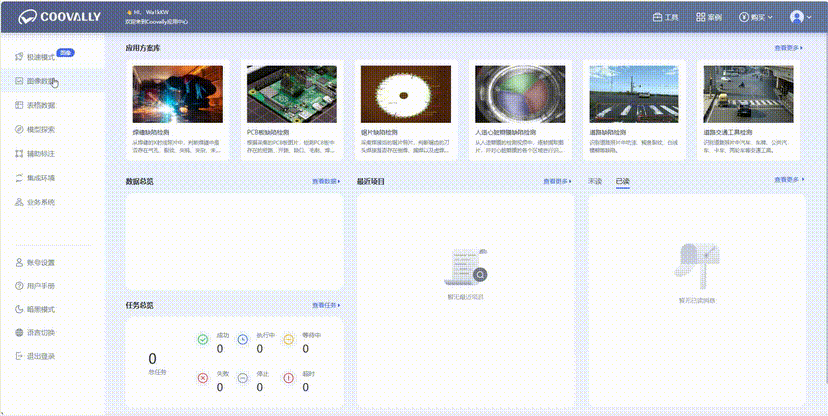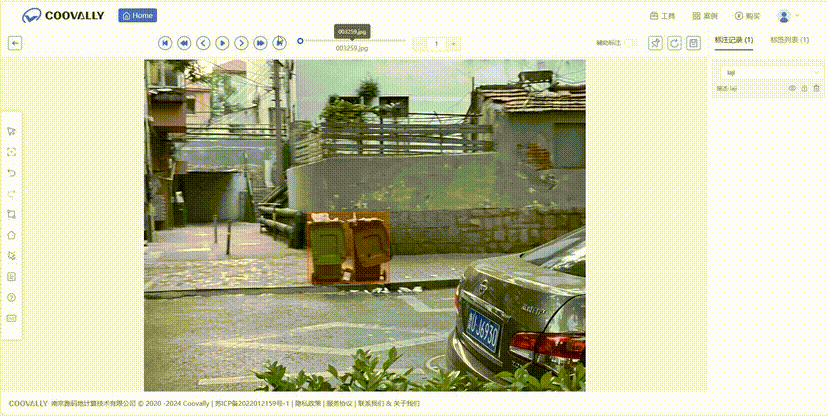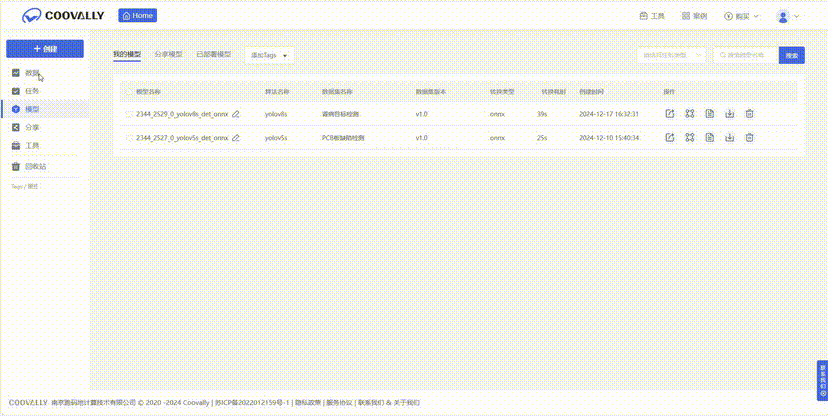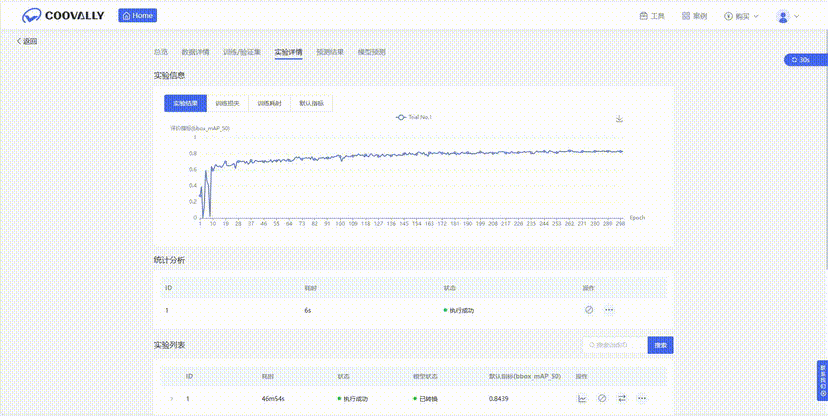
云端模型优化:训练完成的YOLO检测模型可一键转换为ONNX格式,便于后续部署到推理引擎
三、开源生态:普惠AI的未来已来
阿里构建的"三位一体"开源体系正在改写AI产业规则:
-
模型即服务(MaaS):通过ModelScope平台提供"即插即用"的视觉-语言联合微调接口,企业可用自有数据在5分钟内构建定制模型
-
硬件民主化:联合英特尔推出OpenVINO优化套件,在至强CPU上实现70tokens/s的推理速度,让没有GPU的企业也能部署大模型
-
可信AI护城河:内置的"AI防火墙"支持动态内容过滤、版权溯源、幻觉检测,商业应用中合规风险降低80%
阿里以Apache 2.0协议全面开源QwQ-32B,开发者可通过Hugging Face、ModelScope等平台免费获取模型,并支持商用。结合阿里云PAI平台的微调工具,企业能快速定制行业专属AI解决方案。
魔搭开源链接:
https://modelscope.cn/models/Qwen/QwQ-32B
Hugging face开源链接:
https://huggingface.co/Qwen/QwQ-32B
官方在线体验地址:
https://chat.qwen.ai/?models=Qwen2.5-Plus
四、结语
当谷歌大脑研究员Yann Dubois评价"这是2024年最重要的AI突破"时,我们看到的不仅是技术的跃进,更是整个产业的价值重构。在计算机视觉领域,这种"小模型大智慧"的范式,正在催生新一代具身智能、工业元宇宙、生物计算等颠覆性应用。或许正如OpenAI首席科学家Ilya Sutskever所言:"未来属于那些能用最少参数表达最多智慧的模型。"而QwQ-32B,正是这个未来投下的第一道曙光。未来,随着智能体与长时推理技术的深化,我们或许将见证AI在视觉理解、动态决策等场景中创造更多奇迹!



















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









