







前面我们了解了数据清洗的整个过程(详情可参考《数据清洗全流程详细解析与实践指南》文章),接下来我们就要讲一讲什么是数据质量评估。
目录
一、什么是数据质量评估?
数据质量评估是通过一系列标准化的指标,对数据集进行系统化的检查和分析,确保数据的准确性、完整性和适用性。数据质量的好坏决定了模型训练的效果,甚至可能影响最终的决策质量。

数据质量评估通常与数据预处理和数据清洗紧密相关。数据清洗是消除数据问题的过程,而数据质量评估则是验证清洗效果、发现潜在问题的关键步骤。两者是一个循环往复、反复迭代的过程。
二、数据评估的标准
数据评估的核心在于回答三个关键问题:
-
数据是否完整:是否存在缺失值?缺失比例如何?
-
数据是否准确:是否存在异常值或错误记录?
-
数据是否可用:数据分布是否符合业务逻辑?是否满足建模需求?
通过评估,可以明确数据中隐藏的"暗礁",避免因数据质量问题导致模型偏差或决策失误。
三、图像数据评估方法
对图像数据进行评估时,通常需要考虑多个方面,从数据质量到模型评估都有不同的评估指标。以下是一些常见的图像数据评估方法:
-
数据质量评估
-
分辨率与尺寸:检查图像的分辨率和尺寸是否符合要求。低分辨率图像可能会影响后续分析的精度。
-
图像清晰度:评估图像是否清晰,是否存在模糊或噪声。模糊图像可能影响特征提取和分类的准确性。
-
图像的色彩通道:确保图像的颜色通道(如RGB)是否完整,并且没有缺失或错误。
-
数据标注质量:如果数据集涉及标注(如物体检测中的框标注),需要检查标注的准确性和一致性。
-
数据分布分析
-
数据集类别分布:检查不同类别图像的分布,是否存在类别不均衡的问题,类别不均衡可能会导致模型偏向某些类别。
-
图像内容多样性:确保数据集中包含多样化的图像,例如不同角度、光照、背景、大小等,避免数据集过于单一。
-
图像预处理:确保图像是否进行了适当的预处理(如裁剪、缩放、归一化等),预处理步骤能大大提高模型的性能。
-
图像质量评估指标
-
PSNR(Peak Signal-to-Noise Ratio):衡量图像质量的一种常见指标,通常用于图像压缩或恢复任务中。PSNR值越高,图像质量越好。
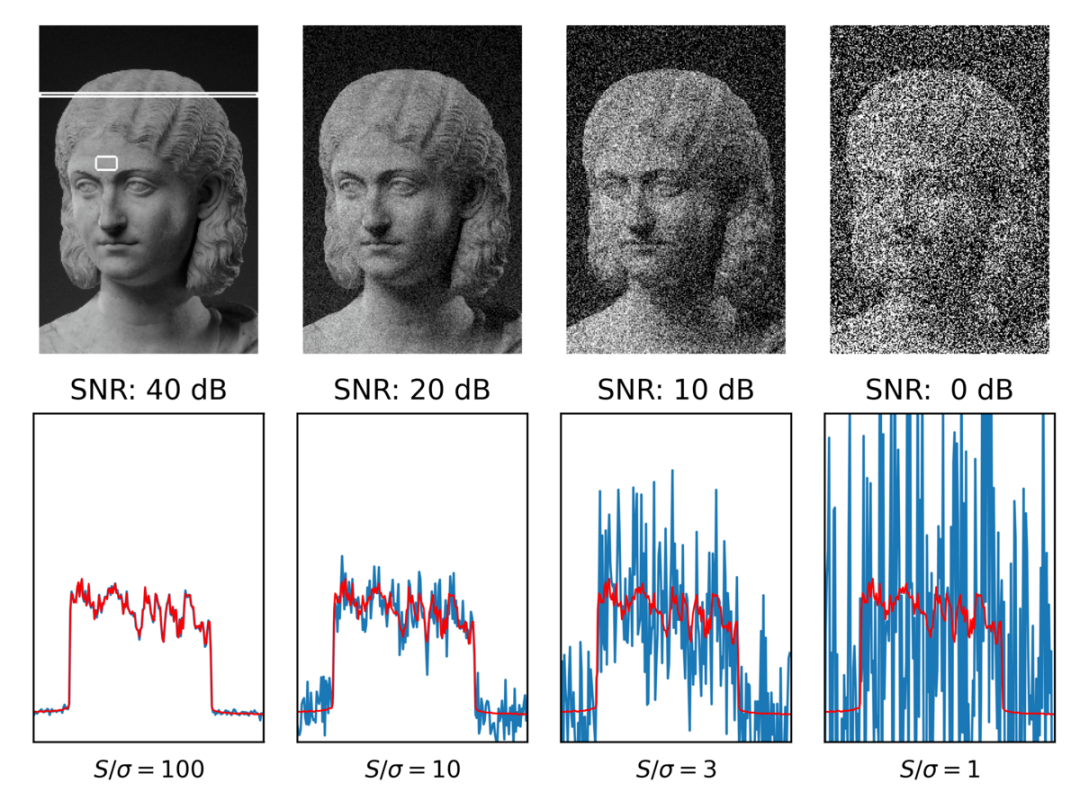
-
SSIM(Structural Similarity Index):评估图像的结构相似性。它通过比较亮度、对比度和结构信息来评估两张图像的相似性。
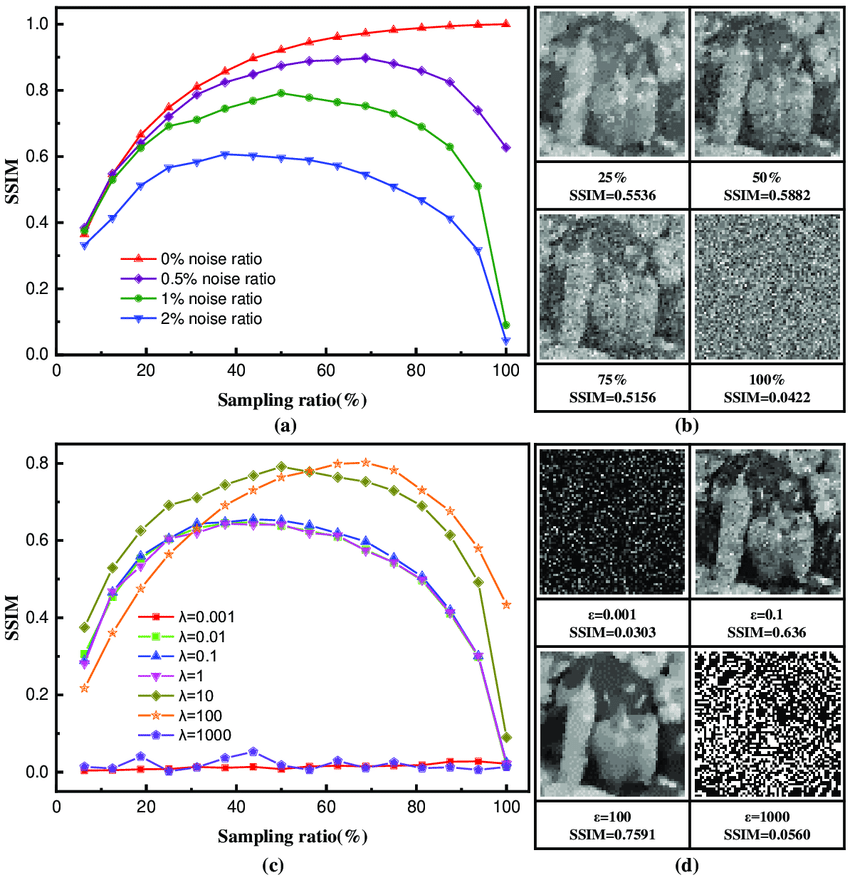
-
MSE(Mean Squared Error):计算图像之间的平均误差,值越小,图像越相似。

-
模型评估指标
对于图像分类、物体检测、分割等任务,常用的模型评估指标有:
-
图像分类
1). 准确率(Accuracy):预测正确的比例。
2). 精确率(Precision)、召回率(Recall)、F1-score:衡量模型在各类分类上的表现。
3). 混淆矩阵:可以看到模型在每个类别上的预测情况,帮助分析模型的误差分布。
-
物体检测
1). mAP(mean Average Precision):在物体检测中,mAP用于衡量检测器在不同IoU阈值下的表现。常用的mAP@0.5就是将IoU设为0.5,计算模型的平均精度。
2). IoU(Intersection over Union):评估预测框和真实框的重叠度,IoU越高,模型预测的框越准确。
3). Precision-Recall曲线:绘制不同阈值下的精确率与召回率的变化情况。
-
图像分割
1). IoU(Intersection over Union):对于图像分割任务,IoU是衡量分割区域与真实区域重叠程度的常用指标。
2). Dice系数(Dice Coefficient):衡量两个集合相似度的指标,常用于评估二值分割任务。
3). 平均像素精度(Mean Pixel Accuracy):计算每个像素的预测是否正确,最终的平均值。
-
异常值和噪声检查
-
噪声与伪影:检查图像中的噪声或伪影(如压缩损失、扫描误差),这些可能会干扰模型的学习过程。
-
异常数据检测:通过视觉检查或统计方法,识别图像数据中的异常,如过度曝光、低光、过度对比等。
-
数据增强效果评估
-
增强方法的多样性:评估数据增强方法(如旋转、翻转、裁剪、颜色扰动等)是否足够丰富,帮助模型学习更多的图像变换。
-
增强后数据的分布:检查增强后的数据是否依然符合原始数据的分布,避免数据增强后图像特征发生偏移。
这些评估方法有助于确保图像数据的质量和准确性,同时也是验证图像模型表现的重要步骤。
四、数据集健康度评估
-
统计特性评估
-
基础统计指标
对于图像数据集,需要评估以下基本统计特征:
1). 像素值分布:计算均值、标准差、偏度和峰度是评估数据集像素分布的重要指标。它们有助于了解数据的集中程度和分布形态。
# 计算图像数据集的均值和标准差
μ = (1/N) * Σ(xi)
σ = sqrt((1/N) * Σ(xi - μ)²)
# 偏度系数(衡量分布的对称性)
skewness = (1/N) * Σ((xi - μ)/σ)³
# 峰度系数(衡量分布的尖峭程度)
kurtosis = (1/N) * Σ((xi - μ)/σ)⁴ - 32). 图像熵(衡量信息量):用于衡量图像的信息量,反映图像的复杂度和细节。
H = -Σ(pi * log2(pi))其中pi是像素值i出现的概率
-
类别分布评估
对于分类或检测任务,需要评估类别分布的平衡性:
1). 基尼系数(衡量类别不平衡程度):
Gini = 1 - Σ(pi²)其中pi是第i类样本的比例
2). 香农熵(衡量类别分布的不确定性):
H = -Σ(pi * log2(pi))3). 类别不平衡率:
Imbalance_ratio = max_class_count / min_class_count-
质量一致性评估
-
图像质量指标
1). 平均图像质量得分:使用SSIM、PSNR来衡量图像质量,帮助评估数据集的质量一致性。
# 结构相似性指数(SSIM)
SSIM = (2μxμy + C1)(2σxy + C2) /
((μx² + μy² + C1)(σx² + σy² + C2))
# 峰值信噪⽐(PSNR)
PSNR = 20 * log10(MAX_I) - 10 * log10(MSE)2). 质量一致性系数:
CV = σ_quality / μ_quality其中CV是变异系数,用于衡量质量的离散程度
-
噪声水平评估
局部噪声估计和全局噪声分布的评估通过比较图像和去噪图像,以及使用主成分分析(PCA)来捕捉噪声特征。
1). 局部噪声估计:
noise_level = sqrt((1/W*H) * Σ(I - I_denoised)²)2). 全局噪声分布:
使用主成分分析(PCA)评估噪声特征:
# 特征值分解
λ1, λ2, ..., λn = eigenvalues(Cov(X))
# 噪声能量⽐
noise_ratio = Σ(λi, i>k) / Σ(λi)-
语义完整性评估
-
特征空间分析
特征聚类度量(如轮廓系数)和特征判别性(如Fisher判别比)有助于评估数据集的语义完整性。
1). 特征聚类度量:
# 轮廓系数(Silhouette Coefficient)
s(i) = (b(i) - a(i)) / max(a(i), b(i))其中:
a(i)是样本i与同类其他样本的平均距离
b(i)是样本i与最近的其他类别样本的平均距离
2). 特征判别性:
# Fisher判别⽐
J = tr(Sb) / tr(Sw)其中:
Sb是类间散度矩阵
Sw是类内散度矩阵
-
标注质量评估
Cohen's Kappa系数和标注不确定性是评估标注质量的重要指标,标注的一致性和不确定性直接影响模型性能。
1). 标注一致性得分:
# Cohen's Kappa系数
κ = (po - pe) / (1 - pe)其中:
po是观察到的一致性
pe是随机一致性的期望值
2). 标注不确定性:
uncertainty = -Σ(p(yi|x) * log(p(yi|x)))其中p(yilx)是模型对样本x预测类别yi的概率
-
数据健康度评分系统
基于上述指标,我们可以构建一个综合评分系统:
Health_Score = w1 * Statistical_Score +
w2 * Quality_Score +
w3 * Semantic_Score
其中:
Statistical_Score = f1(Gini, Entropy, Balance_Ratio)
Quality_Score = f2(SSIM, PSNR, Noise_Ratio)
Semantic_Score = f3(Silhouette, Fisher_Score, Kappa)评分标准:
90-100分:极其健康,可直接用于训练
80-90分:健康,小幅优化后可用
70-80分:亚健康,需要重点优化
<70分:不健康,需要大规模清洗或重新采集
-
健康状态提升建议
根据评分结果,可采取以下措施:
-
统计特性改善:
1). 对类别不平衡使用SMOTE等算法进行过采样
2). 对分布异常的类别进行定向增强
-
质量一致性提升:
1).使用自适应直方图均衡化改善对比度
2). 应用降噪算法处理高噪声样本
-
语义完整性增强:
1). 使用主动学习选择待标注样本
2). 采用多专家交叉验证提高标注质量
这些评估指标提供了一种综合的方法来分析数据集的质量、平衡性和一致性。通过建立一个评分系统,用户可以更好地理解数据集的健康状态,并基于具体的评分采取相应的优化措施,从而提升数据集的质量,确保模型训练的效果。
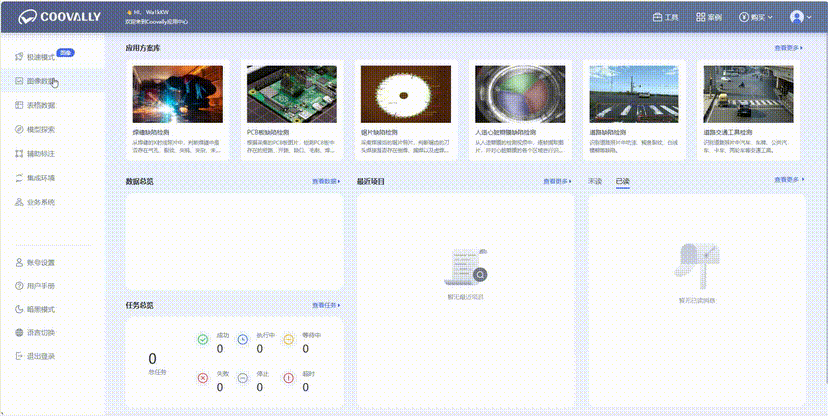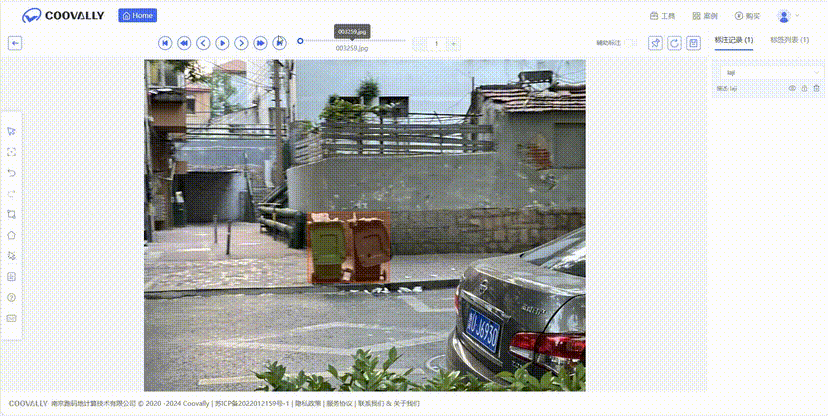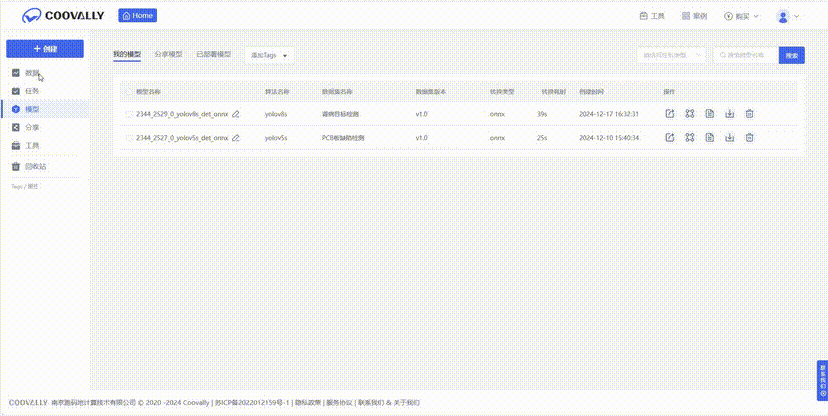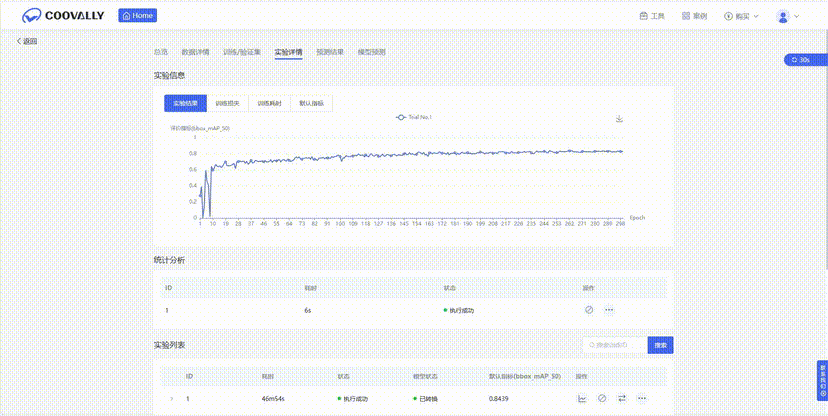
五、Coovally AI模型训练与应用平台
在Coovally平台上,提供了可视化的预处理流程配置界面,您可以:选择预处理方法(去噪、锐化、均衡化等),设置处理参数,预览处理效果,批量处理数据。
与此同时,Coovally还整合了各类公开可识别数据集,进一步节省了用户的时间和精力,让模型训练变得更加高效和便捷。
在Coovally平台上,无需配置环境、修改配置文件等繁琐操作,可一键另存为我的模型,上传数据集,即可使用YOLO、Faster RCNN等热门模型进行训练与结果预测,全程高速零代码!而且模型还可分享与下载,满足你的实验研究与产业应用。
总结
通过系统化的图像数据质量评估,我们可以更好地掌控数据集的质量,发现潜在问题,避免不必要的错误和偏差。数据质量直接影响模型的效果,只有确保数据的健康,才能让模型在实际应用中发挥出最大的潜力。希望这篇文章能帮助你更好地理解图像数据质量评估,并在实际工作中加以应用,提升模型的准确性和鲁棒性。



















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









