




 本文是关于使用Hadoop MapReduce进行平均值计算的学习笔记,详细介绍了环境配置,包括Linux Ubuntu 16.04上的Hadoop 3.0.0启动,Eclipse的Hadoop集成设置。通过编写Score.java程序,实现了读取数据文件,计算并输出平均值的结果。
本文是关于使用Hadoop MapReduce进行平均值计算的学习笔记,详细介绍了环境配置,包括Linux Ubuntu 16.04上的Hadoop 3.0.0启动,Eclipse的Hadoop集成设置。通过编写Score.java程序,实现了读取数据文件,计算并输出平均值的结果。
前言
本文主要是学习MapReduce的学习笔记,对所学内容进行记录。
实验环境:
1.Linux Ubuntu 16.04
2.hadoop3.0.0
3.eclipse4.5.1
一、启动Hadoop
- 进入Hadoop启动目录
cd /apps/hadoop/sbin - 启动Hadoop
./start-all.sh - 输入‘jps’,启动后显示如下信息

二、环境搭配
-
打开eclipse->Window->Preferences;
-
选择Hadoop Map/Reduce,选择Hadoop包根目录,
/apps/hadoop,点击Apply,点击OK; -
点击window–>show view–>other–>mapreduce tools–>map/reduce locations,之后页面会出现对应的标签页;

-
点击3中图标1,在Local name输入myhadoop,在DFS Master 框下Port输入8020,点击Finish,出现3中右侧页面;

-
点击3中
-
图标2,选择下图内容,出现第3步图中左侧内容

完成环境配置环境。
三、求平均值
- 新建test项目,新建average包,图片步骤可见“排序”;
- 新建Score类,即Score.java,编写并保存如下代码:
package average;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Score {
public static class Map extends Mapper<Object,Text,Text,IntWritable>{
public void map(Object key,Text value,Context context){
String line=value.toString();
StringTokenizer tokenizer=new StringTokenizer(line,"\n");
while(tokenizer.hasMoreElements()){
StringTokenizer tokenizerLine=new StringTokenizer(tokenizer.nextToken());
String nameString=tokenizerLine.nextToken();
String scoreString=tokenizerLine.nextToken();
int scoreInt=Integer.parseInt(scoreString);
try {
context.write(new Text(nameString),new IntWritable(scoreInt));
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
public void reduce(Text key,Iterable<IntWritable> values,Context context){
int sum=0;
int count=0;
Iterator<IntWritable> iterable=values.iterator();
while(iterable.hasNext()){
sum+=iterable.next().get();
count++;
}
int avg=(int)sum/count;
try {
context.write(key,new IntWritable(avg));
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(Score.class);
job.setJobName("average score");
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/average/input"));
FileOutputFormat.setOutputPath(job, new Path("/average/output"));
job.waitForCompletion(true);
}
}
- 运行指令
cp /apps/hadoop/etc/hadoop/{core-site.xml,hdfs-site.xml,log4j.properties} /home/dolphin/workspace/test/src,将hadoop配置文件复制到src文件夹下;
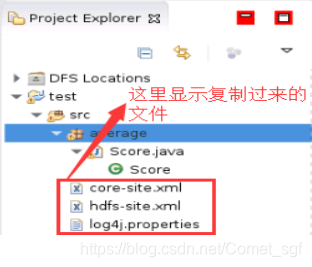
- 创建输入文件存放路径
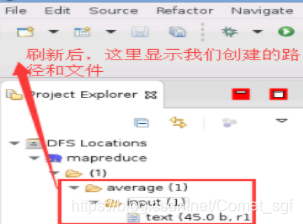
hadoop fs -mkdir /average
hadoop fs -mkdir /average/input
- 将数据文件放入hadoop目录下,
hadoop fs -put /home/dolphin/Desktop/text.txt /average/input,text.txt内容如下:
zhang 82
li 90
zhang 66
li 86
zhao 78
zhao 84
- 运行Score.java文件,得到分数平均值结果在output文件夹中如下所示
li 88
zhang 74
zhao 81
总结
本实验利用Hadoop进行求平均值操作,代码的理解也需要去看去练习才能适应各种环境。



















 2423
2423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









