




 本文详细介绍了使用Python库sklearn进行数据预处理,包括数据无量纲化的MinMaxScaler和StandardScaler,缺失值的SimpleImputer,分类型特征的LabelEncoder、OrdinalEncoder和OneHotEncoder,以及特征选择的Filter、Embedded和Wrapper方法。通过实例展示了如何使用这些工具进行数据预处理和特征选择,以提升模型性能和计算效率。
本文详细介绍了使用Python库sklearn进行数据预处理,包括数据无量纲化的MinMaxScaler和StandardScaler,缺失值的SimpleImputer,分类型特征的LabelEncoder、OrdinalEncoder和OneHotEncoder,以及特征选择的Filter、Embedded和Wrapper方法。通过实例展示了如何使用这些工具进行数据预处理和特征选择,以提升模型性能和计算效率。
目录
2 数据预处理 Preprocessing & Impute
preprocessing.MinMaxScaler数据归一化
preprocessing.StandardScaler数据标准化
StandardScaler和MinMaxScaler选哪个?
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
preprocessing.OneHotEncoder:独热编码,创建哑变量
sklearn.preprocessing.Binarizer
preprocessing.KBinsDiscretizer
feature_selection.SelectFromModel
1 概述
1.1 数据预处理与特征工程
数据挖掘的五大流程:
1.获取数据
1.2 sklearn中的数据预处理和特征工程

模块preprocessing:几乎包含数据预处理的所有内容
模块Impute:填补缺失值专用
模块feature_selection:包含特征选择的各种方法的实践
2 数据预处理 Preprocessing & Impute
2.1 数据无量纲化
preprocessing.MinMaxScaler数据归一化
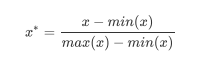
1.准备数据
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
import pandas as pd
pd.DataFrame(data)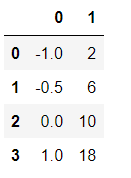
2.实现归一化
scaler=MinMaxScaler() #实例化
scaler=scaler.fit(data) #fit,在这里本质就是生成min(x)和max(x)
result=scaler.transform(data) #通过接口导出结果
result归一后的结果:
result_=scaler.fit_transform(data) #训练和导出结果一步达成
result_3.将归一化后的结果逆转
data1=scaler.inverse_transform(result)
pd.DataFrame(data1)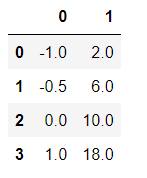 逆转回原来的结果。
逆转回原来的结果。
4.使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler=MinMaxScaler(feature_range=[5,10]) #依然实例化
result=scaler.fit_transform(data) #fit_transform一步导出结果
pd.DataFrame(result)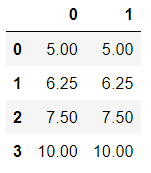 数据被压缩到【5,10】之间。
数据被压缩到【5,10】之间。
注意:当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了 ,此时使用partial_fit作为训练接口 ,scaler = scaler.partial_fit(data)
5.BONUS: 使用numpy来实现归一化
import numpy as np
X=np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
#归一化
X_nor=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
pd.DataFrame(X_nor) 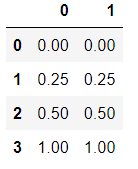 即用公式归一化。
即用公式归一化。
逆转归一化
#逆转归一化
X_returned=X_nor*(X.max(axis=0)-X.min(axis=0))+X.min(axis=0)
X_returned 又逆转回原来的了。
又逆转回原来的了。
preprocessing.StandardScaler数据标准化
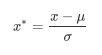
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler=StandardScaler() #实例化
scaler.fit(data) #fit,本质是生成均值和方差
scaler.mean_ #查看均值的属性mean_ array([-0.125, 9. ])
scaler.var_ #查看方差的属性var array([ 0.546875, 35. ])x_std = scaler.transform(data) #通过接口导出结果
x_std.mean() #导出的结果是一个数组,用mean()查看均值0
x_std.std() #用std()查看方差,1scaler.fit_transform(data) #使用fit_transform(data)一步达成结果
'''
array([[-1.18321596, -1.18321596],
[-0.50709255, -0.50709255],
[ 0.16903085, 0.16903085],
[ 1.52127766, 1.52127766]])
'''
scaler.inverse_transform(x_std) #使用inverse_transform逆转标准化
'''
array([[-1. , 2. ],
[-0.5, 6. ],
[ 0. , 10. ],
[ 1. , 18. ]])
'''StandardScaler和MinMaxScaler选哪个?

2.2 缺失值
机器学习和数据挖掘中所使用的数据,永远不可能是完美的。很多特征,对于分析和建模来说意义非凡,但对于实 际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的情况。因 此,数据预处理中非常重要的一项就是处理缺失值。
import pandas as pd
data=pd.read_csv(r"E:\数据分析师学习\Narrativedata.csv",index_col=0,engine='python')
data.head()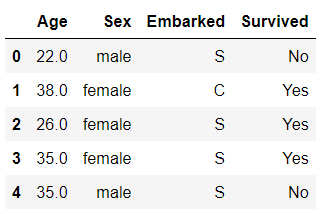 在这里,我们使用从泰坦尼克号提取出来的数据,这个数据有三个特征,一个数值型,两个字符型,标签也是字符 型。从这里开始,我们就使用这个数据给大家作为例子,让大家慢慢熟悉sklearn中数据预处理的各种方式。
在这里,我们使用从泰坦尼克号提取出来的数据,这个数据有三个特征,一个数值型,两个字符型,标签也是字符 型。从这里开始,我们就使用这个数据给大家作为例子,让大家慢慢熟悉sklearn中数据预处理的各种方式。
impute.SimpleImputer
| 参数 |
含义&输入 |
| missing_values |
告诉SimpleImputer,数据中的缺失值长什么样,默认空值np.nan |
| strategy |
我们填补缺失值的策略,默认均值。 输入“mean”使用均值填补(仅对数值型特征可用) 输入“median"用中值填补(仅对数值型特征可用) 输入"most_frequent”用众数填补(对数值型和字符型特征都可用) 输入“constant"表示请参考参数“fill_value"中的值(对数值型和字符型特征都可用) |
| fill_value |
当参数startegy为”constant"的时候可用,可输入字符串或数字表示要填充的值,常用0 |
| copy |
默认为True,将创建特征矩阵的副本,反之则会将缺失值填补到原本的特征矩阵中去。 |
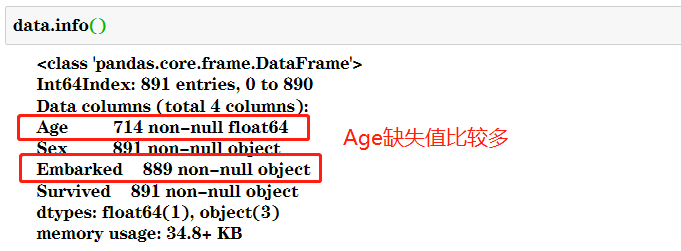
1.填补年龄
#填补年龄
Age = data.loc[:,"Age"].values.reshape(-1,1) #sklearn当中特征矩阵必须是二维2.实例化,查看均值、中值和0的填补方法
from sklearn.impute import SimpleImputer
#实例化
imp_mean = SimpleImputer() #默认均值填补
imp_median = SimpleImputer(strategy="median") #用中位数填补
imp_0 = Sim 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









