






写在前面的内容
服务器环境描述:
集成显卡、16G、linux-cent7.9
1、下载部署环境
https://ollama.com/download/linux
1.1选择系统版本,复制下载命令
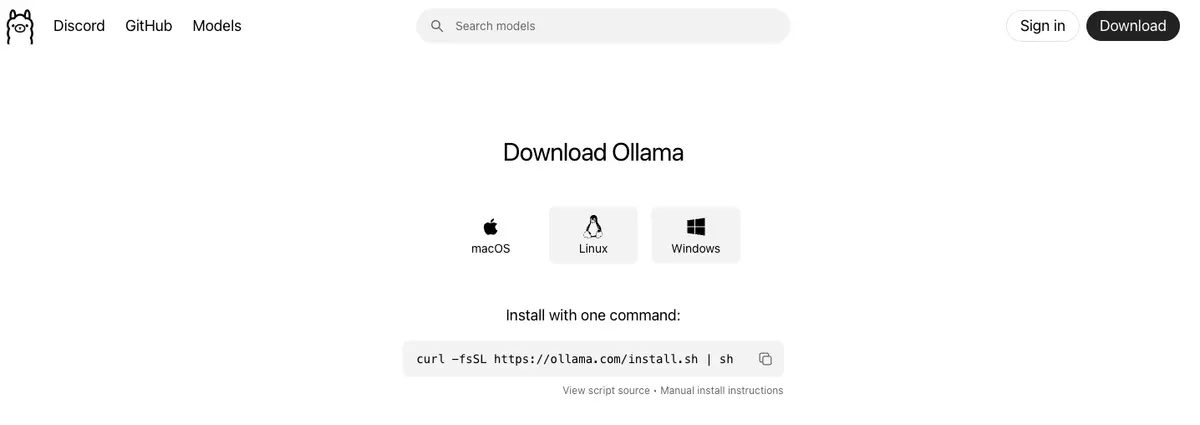
注意:如果失败,一般是网络影响,可配置梯子,或者建议从github 拉取安装包进行处理,github链接:https://github.com/ollama/ollama

选择需要的系统进行下载:

1.2 安转ollama
可查看 https://github.com/ollama/ollama/blob/main/docs/linux.md 文件说明
第一步解压安装包:
sudo tar -C /usr -xzf ollama-linux-arm64.tgz
或者直接解压,然后把 bin 和 lib文件考到 /usr 路径下

1.3 配置系统自启动服务
Create a service file in /etc/systemd/system/ollama.service:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=default.target
之后依次执行命令
# Then start the service:
sudo systemctl daemon-reload
sudo systemctl enable ollama
# Start Ollama and verify it is running:
sudo systemctl start ollama
sudo systemctl status ollama
启动成功截图

以上是运行模型的底座(ollama),安装并启动完成。
2、部署模型
模型链接:https://ollama.com/library/deepseek-r1:1.5b

复制模型下载命令:
ollama run deepseek-r1:1.5b
在linux执行

执行完成截图

2.2使用
部署成功后就可以进行交互问答了

3、交互窗口部署
3.1 下载安装Chatbox(Windows用户推荐)
进入官网下载安装Chatbox客户端

3.2、点击设置,选择Ollama API

3.3 选择安装好的deepseek r1模型,保存即可

3.4 部署完成,就可以正常使用了

4、安装 open-webui(开发者推荐)
4.1 采取docker安装,拉取镜像并运行
## 官网命令,但拉取速度太慢
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
## 加速通道,将ghcr.io换成 ghcr.nju.edu.cn,直接复制下面这行代码运行就能解决
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main
4.2 配置参数
报错处理

open-webui OpenBLAS blas_thread_init: pthread_create failed for thread : Operation not permitted
添加参数
# 在容器启动命令中加上
--privileged=true
4.1 访问 OpenWebUI 界面(因服务器性能,可能相应比较慢)
打开浏览器,在地址栏输入 http://主机IP地址:3000/ 并打开,进入 OpenWebUI 的聊天测试界面。首次进入需要注册账号

4.2 选择并连接 Ollama 模型
在聊天界面的左上角选择当前在 Ollama 中运行的大语言模型。如果无选择内容,则可能是因为无法连接到 Ollama,可以进行以下修改:
~]# systemctl edit ollama
添加
[Service]
Environment=“OLLAMA_HOST=0.0.0.0”
重启 Ollama 服务:
systemctl daemon-reload
systemctl restart ollama
此模型自动加载出来,无需配置。

4.3 选择对应模型并使用


















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









