




 本文介绍了几种先进的深度学习模型及优化技术,包括Recurrent Entity Networks(EntNet)、使用快速权重关注近期历史的方法、通过梯度下降学习优化算法、数值优化教程及神经网络架构的发展历程。这些方法和技术为解决复杂任务提供了有力支持。
本文介绍了几种先进的深度学习模型及优化技术,包括Recurrent Entity Networks(EntNet)、使用快速权重关注近期历史的方法、通过梯度下降学习优化算法、数值优化教程及神经网络架构的发展历程。这些方法和技术为解决复杂任务提供了有力支持。
- 【论文 & 代码】Tracking the World State with Recurrent Entity Networks
简介:
We introduce a new model, the Recurrent Entity Network (EntNet). It is equipped with a dynamic long-term memory which allows it to maintain and update a rep-resentation of the state of the world as it receives new data. For language under-standing tasks, it can reason on-the-fly as it reads text, not just when it is required to answer a question or respond as is the case for a Memory Network (Sukhbaatar et al., 2015). Like a Neural Turing Machine or Differentiable Neural Computer (Graves et al., 2014; 2016) it maintains a fixed size memory and can learn to perform location and content-based read and write operations. However, unlike those models it has a simple parallel architecture in which several memory loca-tions can be updated simultaneously. The EntNet sets a new state-of-the-art on the bAbI tasks, and is the first method to solve all the tasks in the 10k training examples setting. We also demonstrate that it can solve a reasoning task which requires a large number of supporting facts, which other methods are not able to solve, and can generalize past its training horizon. It can also be practically used on large scale datasets such as Children’s Book Test, where it obtains competitive performance, reading the story in a single pass.
原文链接:https://openreview.net/forum?id=rJTKKKqeg
2.【博客 & 论文 & 代码】Implementation of Using Fast Weights to Attend to the Recent Past
简介:
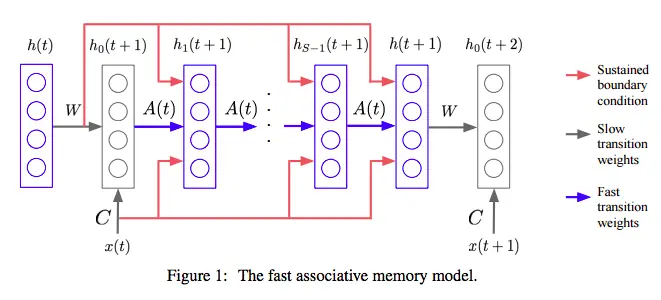
Until recently, research on artificial neural networks was largely restricted to systems with only two types of variable: Neural activities that represent the current or recent input and weights that learn to capture regularities among inputs, outputs and payoffs. There is no good reason for this restriction. Synapses have dynamics at many different time-scales and this suggests that artificial neural networks might benefit from variables that change slower than activities but much faster than the standard weights. These “fast weights” can be used to store temporary memories of the recent past and they provide a neurally plausible way of implementing the type of attention to the past that has recently proved very helpful in sequence-to-sequence models. By using fast weights we can avoid the need to store copies of neural activity patterns.
论文链接:https://arxiv.org/pdf/1610.06258v3.pdf
代码链接:https://github.com/ajarai/fast-weights
3.【论文 & 代码】Learning to learn by gradient descent by gradient descent
简介:
The move from hand-designed features to learned features in machine learning has been wildly successful. In spite of this, optimization algorithms are still designed by hand. In this paper we show how the design of an optimization algorithm can be cast as a learning problem, allowing the algorithm to learn to exploit structure in the problems of interest in an automatic way. Our learned algorithms, implemented by LSTMs, outperform generic, hand-designed competitors on the tasks for which they are trained, and also generalize well to new tasks with similar structure. We demonstrate this on a number of tasks, including simple convex problems, training neural networks, and styling images with neural art.
原文链接:https://arxiv.org/pdf/1606.04474v2.pdf
论文链接:https://github.com/deepmind/learning-to-learn
4.【博客】An Interactive Tutorial on Numerical Optimization
简介:
Numerical Optimization is one of the central techniques in Machine Learning. For many problems it is hard to figure out the best solution directly, but it is relatively easy to set up a loss function that measures how good a solution is - and then minimize the parameters of that function to find the solution.
I ended up writing a bunch of numerical optimization routines back when I was first trying to learn javascript. Since I had all this code lying around anyway, I thought that it might be fun to provide some interactive visualizations of how these algorithms work.
The cool thing about this post is that the code is all running in the browser, meaning you can interactively set hyper-parameters for each algorithm, change the initial location, and change what function is being called to get a better sense of how these algorithms work.
原文链接:http://www.benfrederickson.com/numerical-optimization/
5.【博客】Neural Network Architectures
简介:

Deep neural networks and Deep Learning are powerful and popular algorithms. And a lot of their success lays in the careful design of the neural network architecture.
I wanted to revisit the history of neural network design in the last few years and in the context of Deep Learning.
原文连接:https://culurciello.github.io/tech/2016/06/04/nets.html

















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









