



我们常常听到java中有红黑树算法,这个据我了解最难的数据结构知识点不知是在java中扮演了什么样的角色,但是知道我学习到TreeSet,他才揭开了他的面纱。当然这里不是讲红黑树的,我对数据结构所知甚浅,甚至二叉树都没有学到。当然也不配在这里讲述红黑树。但是,不讨论底层并不代表不能讨论他的应用,这次就来讲讲红黑树在java中的应用——TreeSet。
众所周知,TreeSet是属于Set这一类型的集合,他们的最大的特点就是无序,并且没有重复的数据。每个Set集合的判断是否为重复的方法都不一样,比如HashSet的方法就是运用Hash表来算所有数据的Hash值,并配合equals方法来判断是否为重复数据,当然LinkedhashSet只是其一个链式存储,其于HashSet的最大的区别在于LinkedhashSet可以根据输入的顺序进行遍历,但是其在底层的存储还是处于无序状态。只是通过链式结构去获取数据的顺序而已。
而TreeSet和这些Set的最大的区别在于底层的储存数据结构为树形结构,因此在其存储的时候就可以对其进行自动排序,以下是TreeSet的实例化方法:
TreeSet setone=new Treeset();
括号里可以放入自己写入的compare方法,当然也可以不放,不放的话就用其默认的判断方法,默认方法只能排序基本数据类型,如果让其排序类就会出现问题。
这里抛出了ClassCastException异常。需要我们放入比较器(comparator)

当然使用比较器(comparator)在之前的类中也有接触,这里重新写一个匿名comparator方法。
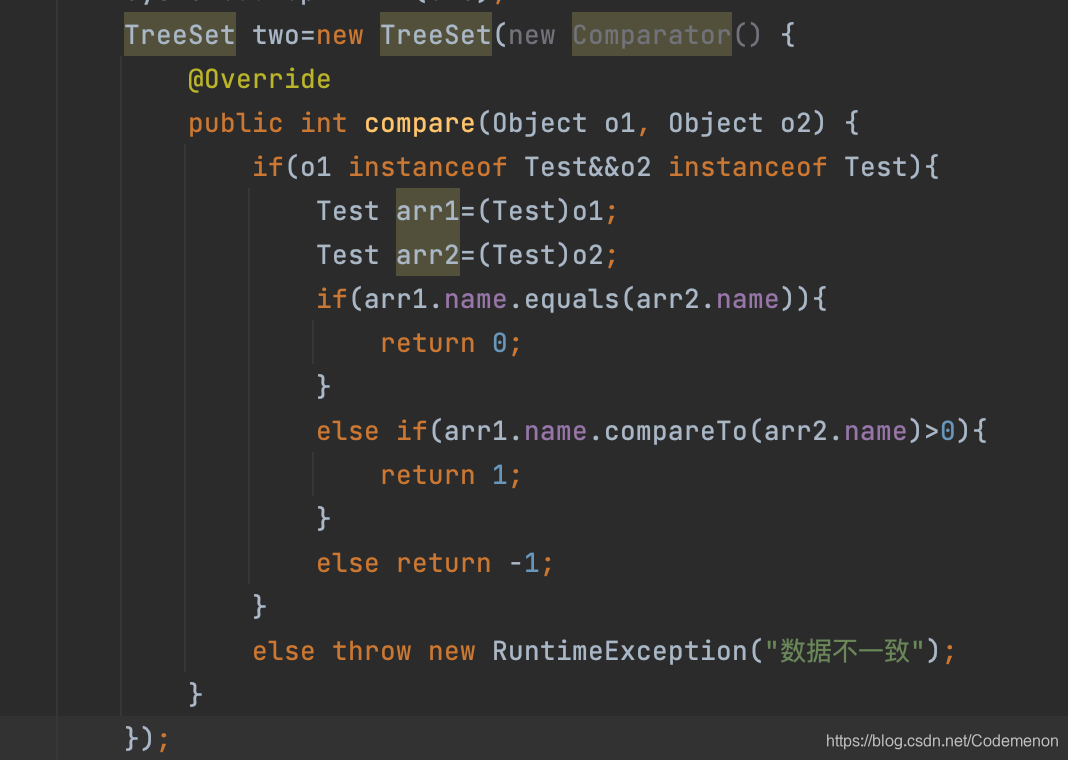
可以看出是在括号中重写的,当然重写的步骤在这里要重新讲解下
1.实例化一个comparator对象。
2.在对象中重写compare方法,会自动创建一个带有两个object参数的方法
重写compare方法步骤
2.1用instanceOf判断两个compare方法是否为需要判断的对象的子类,如果不是抛出异常。
2.2向下转型,将object对象强制转换为自己需要比较的对象类型。
2.3调用自己需要比较的数据类型,然后进行比较,比较大的用1,比较小的用-1,相等就用0。
可以看出我在这里写的对象是比较两个对象的name,而name又是用String类型,所以直接用了equals方法进行比较。
3.添加数据,添加的数据要与比较器比较的数据一致。

这里我添加的是比较器中的数据类型,也就是具有name类型的Test类,这个类中有两个元素,一个是name,另一个是age(年龄)。所以存储的时候底层是通过比较name字符类型来进行存储。

4.输出
当然这里要重写Test类的toString方法,否则输出的结果是其对象的地址。
我们比较字符串的顺序的根据26个字母的先后顺序来进行排序,比如说J在T的前面。那么输出顺序是先输出Jeck后输出name。
我们根据结果来看,是先输出Jeck后输出Tom。跟输入的顺序不一样。因此也可以说明是否底层的存储数据也是根据Comparator比较器来进行排序。

















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









