




 本文回顾了C语言中的数组和指针概念,并深入探讨了Java中的ArrayList和LinkedList两种容器。ArrayList作为动态数组,允许不同类型的元素存储,而LinkedList实现了双向链表,适合于中间元素的增删操作。文章通过代码示例展示了ArrayList的添加功能,并分析了其扩容机制。此外,还对比了数组与链表的优缺点,强调了它们在不同场景下的适用性。
本文回顾了C语言中的数组和指针概念,并深入探讨了Java中的ArrayList和LinkedList两种容器。ArrayList作为动态数组,允许不同类型的元素存储,而LinkedList实现了双向链表,适合于中间元素的增删操作。文章通过代码示例展示了ArrayList的添加功能,并分析了其扩容机制。此外,还对比了数组与链表的优缺点,强调了它们在不同场景下的适用性。
还记得我半年前第一次学习c中的数组,大概曾经我觉得非常难以理解的计算机数据存储在学习数组之后感觉也就这样,比我想象的容易,而且指针的概念在通过学习数组后也逐渐清晰明了。直到我学到了数据结构,害!不提了,那都是后话了。
在这里 我通过java知识来梳理和下我曾经学过的数组以及为了应付考试学的一点点数据结构。以此纪念曾经奋斗学习的岁月。
java 在其库中提供了多种的容器结构。想想我花了一天敲出来的单链表。这些库函数也大大提高了我们开发的效率。当然java中没有指针这个概念,因此容器的数据增删改查远远没有c来的直接。但是java提供了多种方法可以去操控对应的容器。毕竟面向对象的编程最基本的操作还是函数操作。
在此,我先提及三个容器,ArrayList、LinkedLIst,在java中,这两种结构都需要实现Collection接口。这两个分别代表动态数组,双向链表。接下来一一讲解这些容器。
ArrayList
这个容器即是动态数组,弥补了数组不能扩容的缺点(好像学了这么多编程语言,就没见过哪个数组天生就可以扩容的,这跟底层有关吗)当然扩容也是自动扩容,类似于StringBuffer。扩容的先决条件是你要添加的元素个数超过了总容器的大小,在这里首先讲解下添加函数的方法。
实例化的容器名.add(要添加的元素);
当然容器的底层存储的类型是object,也就是说你添加的也是object的子类,所以要添加的元素为基本类型的时候,会自动装箱(仅限于单个元素)。也就是说你最后添加的还是其包装类。并且这个容器不像数组只能存储一种类型的元素,比如矿泉水瓶只能装矿泉水,这个瓶子不仅能装矿泉水,还可以在里面混入可乐,柠檬茶,甚至还可以混沙子,也就是说数组元素可以混着装。
代码如下:
package collectionTest;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.List;
/**
* @author jreson
* @create 28 2:37 下午
*/
public class CollectionTest {
public static void main(String[] args) {
Collection coll=new ArrayList();
coll.add("abc");
coll.add("def");
coll.add(123);
coll.add(true);
System.out.println(coll.toString());//[abc, def, 123, true]
List arr1= Arrays.asList(new int[]{1,2,3,4,5,6,7});//这里存的是数组的地址
System.out.println(arr1.toString());//[[I@5acf9800]
List arr2=Arrays.asList(new Integer[]{1,2,3,4,5,6,7});//这里存的是数组的内容
System.out.println(arr2.toString());[1, 2, 3, 4, 5, 6, 7]
//aslist后面要用类
}
}
可以看出我们向coll对象(也就是ArrayList对象)中放入了字符串,数字,bool值(true)。在toString中都打印出来了。同样的,asList方法是将数组转换成list集合,由于集合是object 的子类,因此只能储存对象,将基本类型的数组存入该集合,存入的仅仅是该数组的元素,因此要将Integer包装类数组转化成集合,得到的才是该包装集合的数值。asList使用方法:
返回的类型用List集合来存储=array.asList(这里放的是包装类数组);
我们对ArrayList源码进行分析,发现该集合跟懒汉式极其相似,也就是说初始化默认的是一个空集合,等到第一次添加数据时才扩容集合,扩容的最少大小是10个大小,然后将扩容前的集合内容拷贝放入扩容后的集合,并将实例的引用类型指向扩容后的集合。在第一次添加数据时才扩容集合,也就是说该线程是不安全的。(详情看我之前写的<从懒汉式到线程安全>)。
还有其他的基本操作,由于没有太多需要注意的点,因此基本操作都放在这里以供参考
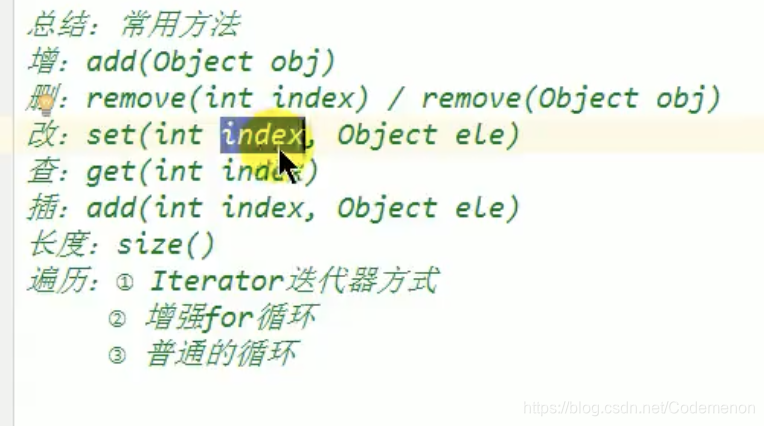
LinkedList
这个容器结构即为链表结构,在数据结构中我对链表有了较浅的理解,数组是在内存中连续存储的容器,那么链表就是非连续存储的容器,但是如果前面的数据和后面的数据在内存中不是连续存储,那么通过什么方法可以使得元素之间有一定的顺序,就跟数组的角标一样。那么就要引入指针这个概念了,前一个元素要放在节点中,然后该节点内有一个指针指向下一个元素所存放的节点,然后下一个节点再指向下下个节点....依次类推,每个节点都有一个地址去让上一个节点指向,以及每个节点都有一个指向下一个节点的指针。因此,一个节点就被拆分成三个部分,第一部分指向上一个节点,第二部分存放数据,第三部分指向下个节点。那么我们发现首元素没有上一个节点,那么它的第一部分怎么表达呢,于是我们就把它的第一部分指定为空。也就是链表的首节点的第一部分为null。然后我们还发现链表的最后一个节点没有下一个部分可以指向了。那么该怎么办。于是我们把最后一个元素的第三部分也设为null。就这样,一个双向链表就完成了。
写到这里,我算是对数据结构的链表有了一个复习了。在学c的时候,由于都是面向过程编程,对结构体的学习也算是蜻蜓点水。所以链表的源码我并未看懂,但是在学习了java面向对象之后。链表这种定义节点存放数据的方式算是能够深刻理解了。只可惜java并不能直接操作指针。因此在java源码中,该容器的底层操作还是依据无法看的底层c++代码实现的,但是链表的数据定义还是在java源码中有体现。通过源码,可以复习链表的设计思想。
那么链表我就介绍到这了,以上的实现方法就是基于双向链表来实现的,当然也有单向链表,单向链表就是没有上述的第一部分,也就是该元素不会指向上一个元素。不会知道上一个元素的位置。而双向链表上一个元素的位置,下一个元素的位置都知道。这就是单项链表和双向链表的区别。
因此我们发现链表调用元素数据需要将其遍历,而不像数组一样可以直接用其角标来调用其元素。因此我们发现如果需要在链表尾部进行扩容,需要将链表遍历一遍,才能知道其尾部的位置。效率相较于数组而言比较低下。而链表需要删除和增加其中间位置的元素时只需要修改其上一个元素和下一个元素的指针。而数组则在中间添加和删除元素的时候需要将其后面元素的位置都得改动(也就是后面元素的角标被改动了)。我们发现中间修改元素链表的效率较高,而末尾增添元素数组的效率更高。各有优缺点。因此链表和数组都是分别运用在不同运算的容器中。
链表(LinkedList)的操作这里就不赘述了,链表的作用跟数组一致。因此其增删改查的方法也与其一致,只不过底层实现的机制不同罢了。

















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









