





本文字数:5448;估计阅读时间:14 分钟
作者:Mike Shi
本文在公众号【ClickHouseInc】首发

可观测性(Observability)原本是团队在系统故障时的一种底气——帮助快速定位问题、恢复服务。然而随着系统规模扩大,这一初衷常常被逐渐扭曲:它不再只是保障,而成为基础设施预算中最大的黑洞之一。这项本意为“防止宕机”的举措,反而演变成导致财务“出血”的源头。
团队的选择空间也随之收紧:每天都在讨论还能保留多少数据,更多精力花在“控制支出”而不是“解决问题”上。而要迁移平台?看似不可能。沉没成本、专有协议、厂商绑定,让切换之路难如登天。
有的组织甚至为此支付了惊人代价。2022 年,据报道某大型加密货币交易所一年花费高达 6500 万美元用于 Datadog 可观测性平台。
其实我们不必忍受这一现状。我们是如何走到这一步的?更重要的是,我们该如何走出去?
可观测性的演进史:我们是怎么入坑的?

第一阶段:从 grep 到 syslog
最初,可观测性只是“看得见”。1970 年代,工程师靠 grep 手动翻日志。1980 年代,syslog 出现,实现跨主机集中收集日志。这些工具简单、稳定,而且几乎没有成本压力。
第二阶段:Splunk 开创了初代可观测性
Splunk 的出现让日志查询进入了一个全新时代。它支持海量查询、实时可视化,并带来了 SPL(查询语言)和 读时建模(schema-on-read) 概念,让用户无需预定义表结构即可分析数据。这种灵活性极具变革意义。
但 Splunk 开创了一条新的行业道路:按数据摄取量计费。
一旦走上了这条道路,整个行业随之进入“数据越多、成本越高”的死循环。
第三阶段:开源替代品的崛起
2010 年后,Elasticsearch 和 ELK 技术栈作为开源选项而异军突起并迅速流行。它比 Splunk 便宜,但也存在明显问题:
-
用户体验笨重
-
架构只适合中小规模、低基数数据
-
随着数据量增长,暴露出一系列结构性瓶颈
例如:JVM 的内存管理限制了扩展,倒排索引 + 单线程分片执行效率低,面对高基数字段(如标签数非常多的 metrics)时性能迅速崩溃。
Elastic 曾尝试用资源型计费替代摄取计费,理论上允许用户“优化成本”,但现实中却让系统变得更难用。要用好它,你得理解内部结构(如分片分配、查询路径等),对“只想把数据发进来然后查一查”的用户不友好。
第四阶段:云端全家桶服务统治市场
Elastic 不够“云化”,Splunk 也不是为云设计,于是 Datadog 等云原生平台迅速占据主导地位。
Datadog 的用户体验极佳,它抽象掉了很多底层细节,让团队专注于使用。但它也带来了新的问题:成本爆炸式增长。
数据狗它不单纯按摄取量计费,它还引入了按主机数量计费的模式,尤其在 APM 和追踪(tracing)场景中。换句话说:你部署的实例越多,哪怕业务没变,观察成本也水涨船高。
有些公司甚至发现:可观测性成本高于基础设施本身运行费用。
以“三大支柱”为轴心的架构,已穷途末路

为了控制日益上涨的成本,行业选择将可观测性的数据类型进行了拆解,构建针对单一数据类型(日志、指标或追踪)的专用存储引擎。
Prometheus 成为专用的指标数据库,聚合性能优异,但在数据基数暴涨后捉襟见肘。它的架构启发了 Loki(专注日志)和 Tempo(专注追踪)。这些系统本身确实更易于运行、成本更低,但也做出许多妥协 —— 比如,牺牲了对高基数字段(如用户 ID)的快速搜索能力。
于是,我们得到的是一种“看似节省”的结果:数据被分散存放,每种类型一个孤立的存储数据系统,只能靠预设的标签进行数据关联查询。团队被迫维护多个仪表盘、手动做数据关联。而原本在 Splunk 或 Datadog 中流畅的探索式排查流程,如今因为底层多数据源多地性能瓶颈而变得遥不可及。
更糟的是,虽然每个系统单独运行效率不低,组合起来却带来了额外成本:你要运维三个系统,理解三个架构,为每一个点状工具付出学习与维护成本。
最后不但没有能决绝掉成本问题,还创造出了另一个新问题:观测数据孤岛。
“日志、指标、追踪”被称为“可观测性的三大支柱”——但这个比喻本身就是问题的一部分。它强化了工具进一步分裂的碎片化趋势,让我们误以为碎片化是自然规律,而非工程设计的选择。
当前困境:要么贵得离谱,要么功能残缺
今天的团队面临两难选择:
-
一方面:功能全但费用高昂的专有平台(如 Datadog),一旦规模扩大便难以承受;
-
另一面:价格便宜但碎片化的开源生态,每个工具只关注一种观测信号,从未呈现出完整画面。
这些点状工具确实便宜,但它们造成了严重的数据孤岛。在最理想情况下下,你还可以靠 trace ID 关联事件;而在最糟时,探索式排查或高基数分析都压根无法快速的进行。
我们现在被逼进了死胡同:在财务上不可持续的工具 vs 技术整个能力有限的工具,显然这两者都无法实现可观测性的初衷 —— 在关键时刻带给团队信心的助攻与清晰的判定。
敢问路在何方:以 OpenTelemetry 为基石
OpenTelemetry 是 CNCF(云原生基金会)中最活跃的项目之一,仅次于 Kubernetes。
它通过标准化采集方式和数据格式,让团队实现“采一次,送多处”,不再被某个厂商绑定。多数厂商现已支持 OTel,因此你可以逐步采用新 SDK,而无需大拆大改。
当然,并非每个团队都准备好立即迁移到 OTel,因此解决方案仍需具备兼容其他格式的能力。
如果 OTel 是可观测性的底座,下一步的问题是:我们理想中的“全景可观测性系统”应该是什么样子?
我们真正需要的可观测性系统,应当具备这些能力:
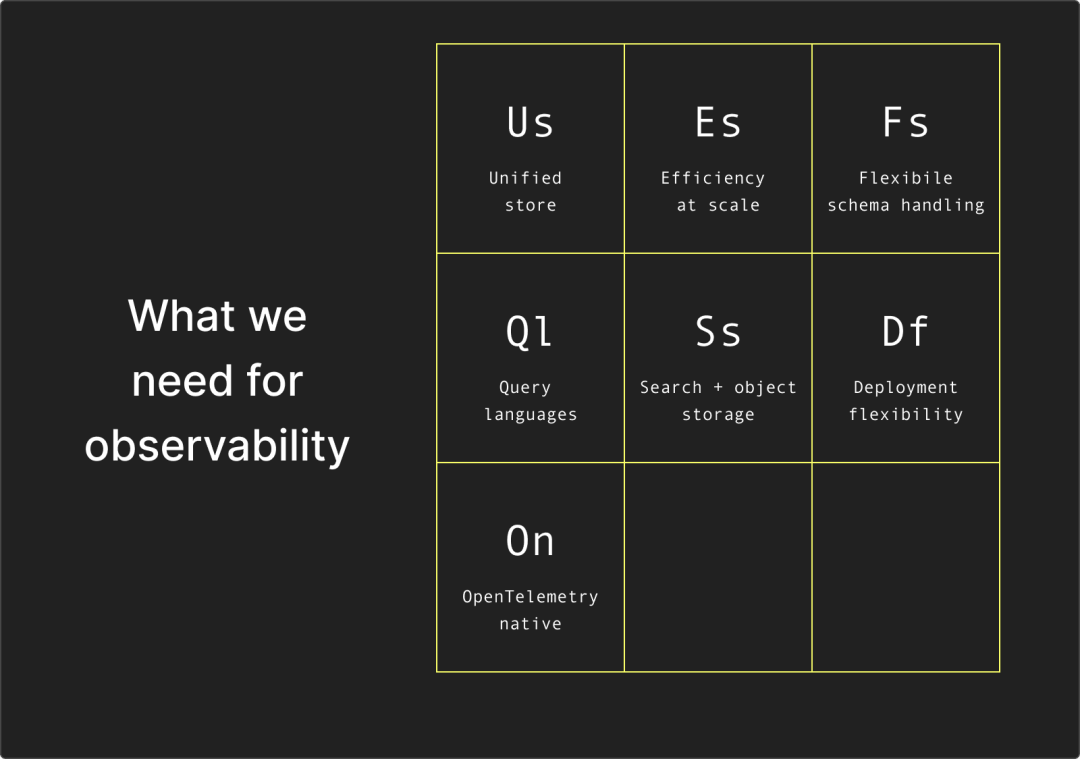
1. 统一的数据引擎: 日志、指标、追踪不再分离,而是:它甚至与业务数据归于一处:并列可查询、互相可联动。
2. 大规模与强性能一体: 能同时支撑高摄取速率和高基数聚合分析。
3. 对象存储是一等公民: 可实现长期存储且成本可控。
4. 灵活的 schema 处理能力: 支持“读时建模(schema-on-read)”灵活分析,也支持“写时建模(schema-on-write)”,高效处理 JSON 与宽表事件。
5. 多层次的查询能力: SQL 是底层语言,热数据可全文搜索,也支持 SPL / PromQL / ES|QL 等 DSL, 降低数据使用门槛。
6. 原生兼容 OTel,且不限于 OTel: 同时支持传统格式和“宽事件(wide events)”。
7. 部署灵活:托管 or 自建,随你选择: 想要省事可选云服务,注重自我掌控可本地自建,无需被锁定。
实现可观测性的道路上,不该逼团队在“预算”与“能力”之间二选一。真正的解决方案应让成本可预测、可持续,同时满足开发体验与运维效率。
它不应是一个“特殊系统”,而应像数据栈那样,被现代工程团队掌控并进化。
它不是监控用的黑盒,而是一套现代数据系统,交到好处地解决可观测性问题。
列式存储的优势
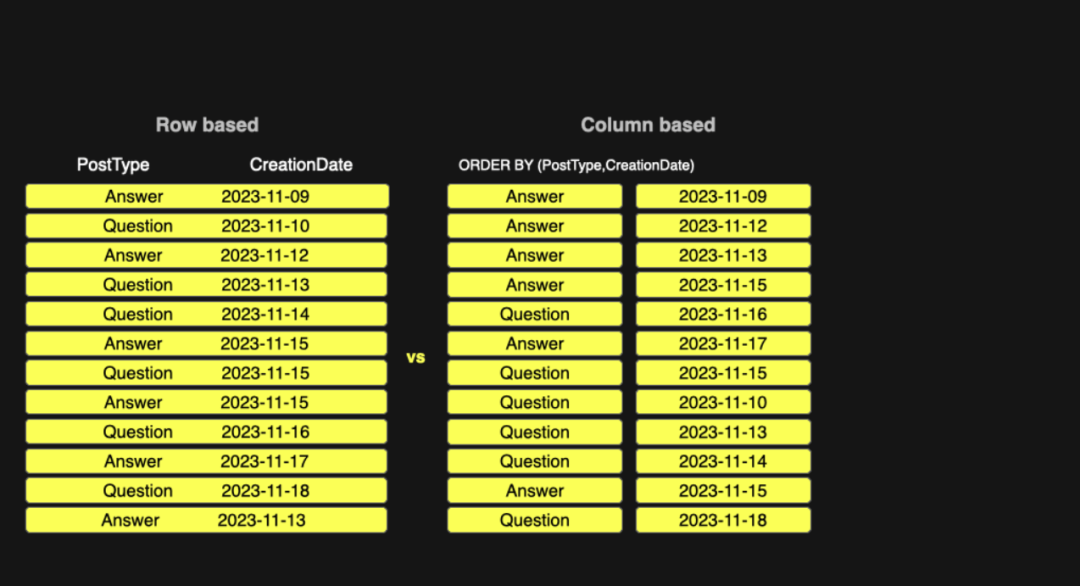
列式存储将每一列独立写入磁盘,按照顺序组织,并支持 Delta 等压缩编解码器,从而大幅降低 I/O 成本并实现高压缩率。
这与可观测性场景天然契合。列式数据库具备出色的数据压缩和存储效率,使得在海量数据下依然具备极高的性价比。它擅长对高基数数据进行快速聚合,按需只扫描必要列,从而高效支持仪表盘和探索式分析。它既支持高速写入,又能配合布隆过滤器等高效索引;现代引擎甚至支持列级别的可选全文检索,专为日志类负载设计。
如今的列式数据库不仅支持读时建模(schema-on-read),也支持写时建模(schema-on-write),可快速解析半结构化数据,原生支持 JSON 和宽事件(wide events)。而由于其内建完整 SQL 查询能力,团队无需学习新 DSL 即可构建复杂查询。
简而言之,列式存储让我们可以把“可观测性”当作标准的数据问题处理 —— 在同一套架构中同时解决压缩、高基数、查询速度和 schema 灵活性,构建出传统工具难以实现的能力底座。
为什么 ClickHouse 是最优选
虽然市面上还有 Apache Pinot、Apache Druid 等多个列式数据库,在架构层面具备相似能力,并在大型分析场景中表现不俗,但在可观测性领域,ClickHouse 因其在实时性能方面的专注,从而脱颖而出。
其稀疏主索引能高效支持常见过滤操作,符合大多数可观测性数据访问模式;并行执行引擎可将查询任务分配至多核 CPU,有效处理海量数据;此外,通过跳跃式索引与内建的全文搜索支持,ClickHouse 进一步增强了探索式分析能力。
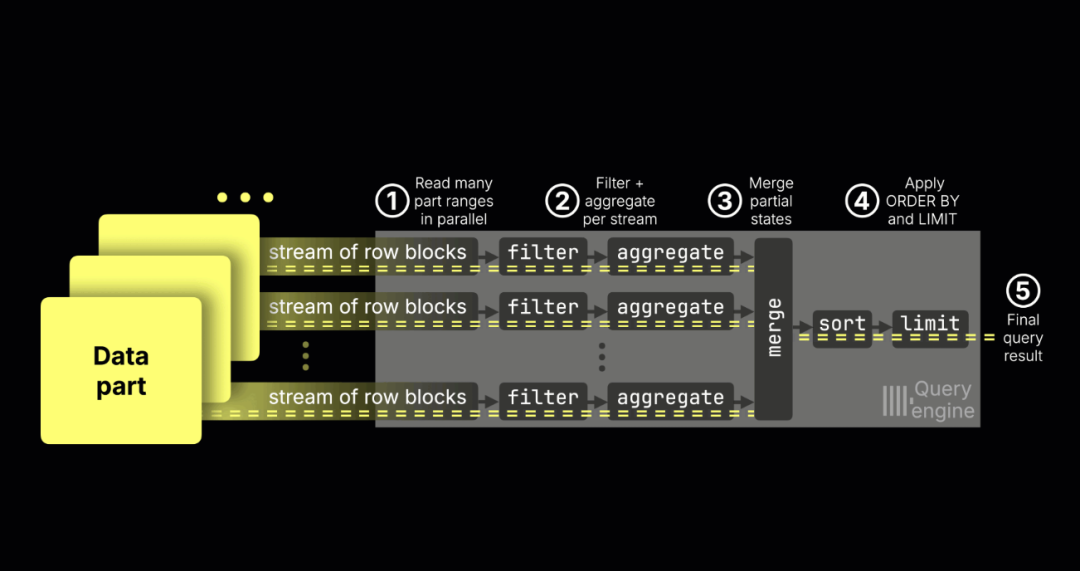
图示:ClickHouse 查询执行完全并行化,最大限度利用机器所有核心
ClickHouse 的存储架构原生支持对象存储与计算资源解耦。结合列式压缩,这使得海量数据可以低成本长期保留,且可根据需求弹性扩展计算资源。
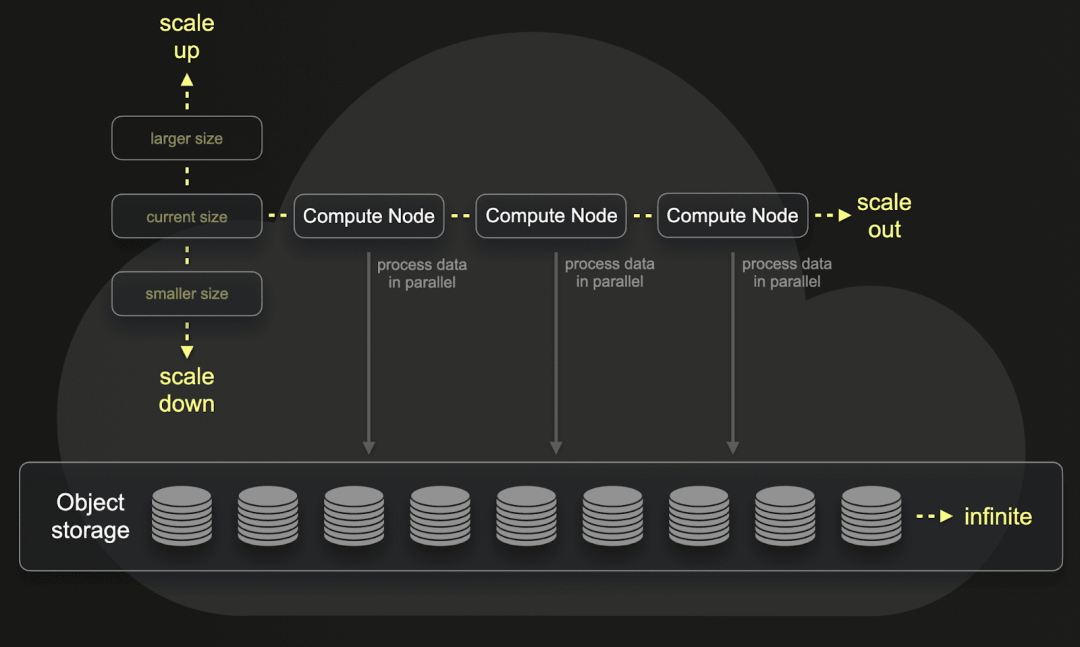
图示:计算与存储分离不仅让存储更经济,还实现了工作负载隔离与按需弹性计算能力
其独特的 JSON 类型也很重要:它保留字段结构和类型信息,避免了早期写时建模模型常见的问题(如首个写入值决定字段类型)。这意味着团队只需“直接传 JSON”即可上手,而在数据源未定义结构时,ClickHouse 仍可通过优化后的字符串解析实现高效查询。
这些特性早已在实际可观测性系统中得到验证。包括 Tesla、Anthropic、OpenAI 和 Character.AI 在内的多家公司,已经在 PB 级别数据量下使用 ClickHouse 进行可观测性分析,证明了其出色的扩展性与实战能力。
ClickHouse 在我们开发和发布 Claude 4 的过程中发挥了至关重要的作用。借助 ClickHouse,数据库保持稳定,查询速度极快,且成本得到有效控制。ClickHouse 已经为我们在打造最先进的语言模型方面提供了巨大的价值。
ANTHROPIC
过去,查询最近 10 分钟的数据需要 1-2 分钟。借助 ClickStack,这几乎快到和眨眼一样。性能确实可靠。当你在故障排查中分析日志时,每一秒都至关重要。
character.ai
成功案例:
Anthropic 如何利用 ClickHouse 提升 AI 时代的可观测性
特斯拉如何基于 ClickHouse 构建千万亿级别的可观测性平台
专属 UI 不是摆设,而是刚需
列式数据库非常适合可观测性,越来越多公司已认识到这一点。Anthropic、OpenAI 和 Netflix 等公司已经在 ClickHouse 之上构建了强大的系统,充分验证了该架构的可行性。但它们真正的优势不仅在于选对了数据库,更在于拥有专属工程团队构建了高度定制的可观测性界面。这种路径对大多数公司而言门槛太高,需要大量人力与资金投入,仅适合超大规模场景。
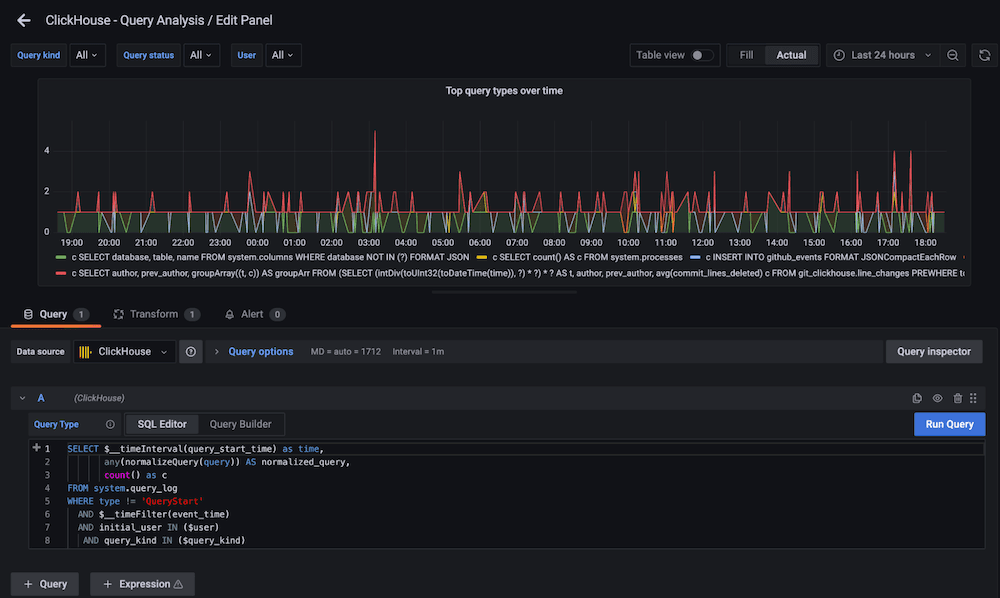
对于更多团队而言,Grafana 仍是不二之选。它是一款优秀的多源数据可视化工具,也能支持 ClickHouse,但使用过程中用户必须熟悉 SQL,还得自己负责查询优化。对于只是想快速排查问题的开发者来说,这样的门槛往往过高。
开发者日常更需要的是——一个简单易用、即开即用的分析工具。SQL 永远是深入分析的利器,但对于临时搜索与即时响应,它并不是最适合的方式。
我们真正需要的是一款专为 ClickHouse 打造的可观测性界面:对开发者友好,支持快速上手,保留对底层数据库的控制能力,并且最重要的一点——开源、无锁定。
ClickStack 是明智之选
已有不少团队在 ClickHouse 基础上构建了可观测性平台,但也伴随一些问题。部分系统只支持 OpenTelemetry,无法支持宽事件等更灵活的数据模型;也有一些走向封闭专有化,又重新引入了我们希望避免的数据孤岛,无法关联业务数据,限制了 ClickHouse 本身的潜能。
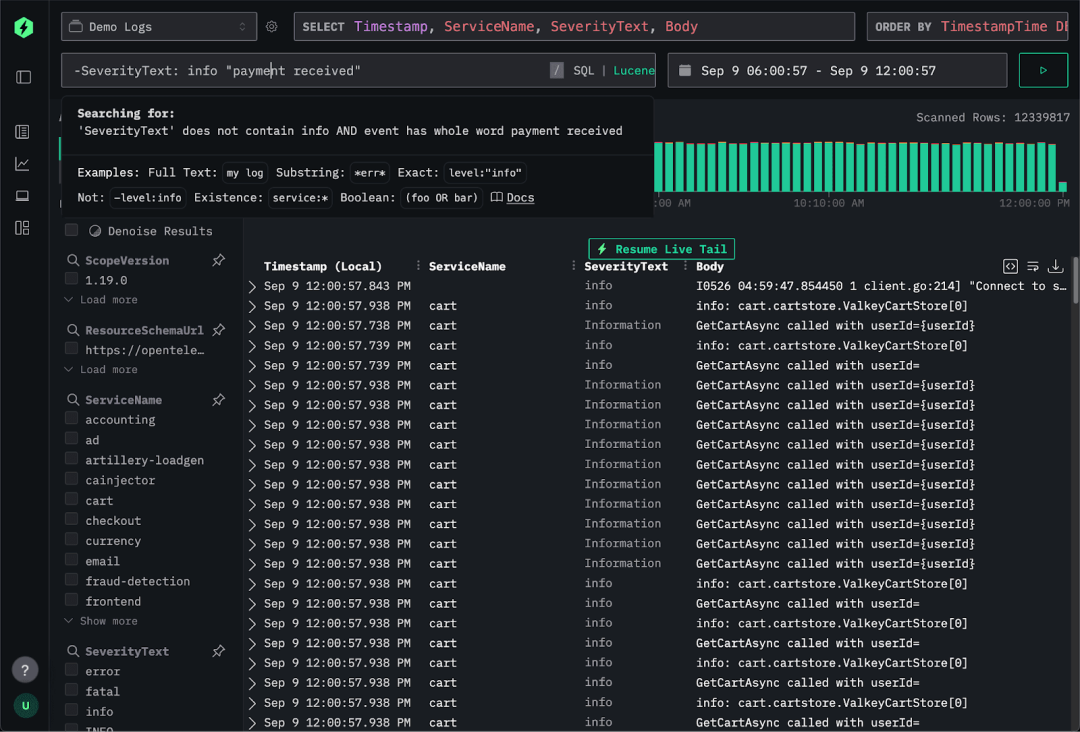
ClickStack 则选择了不同路径。它在最大限度释放 ClickHouse 能力的同时,避免了专属工具的锁定陷阱。ClickStack 原生支持 OTel 但并不局限于 OTel 格式,宽事件也是核心支持类型。它完全开源,用户既可以在本地轻量运行,也可以在业务扩展时平滑迁移至云端。
在 ClickHouse Cloud 中,ClickStack 延续了 ClickHouse 的诸多优势:存储与计算解耦、极高压缩率与极低成本。同时,它还将各类数据(可观测性指标、业务数据、用户行为)聚合在一个平台中,真正实现跨系统分析,摆脱信息孤岛。
结语
回顾整个发展过程,我们最终来到了这样一个结论:列式数据库天然就是构建可观测性平台的最佳基础。它既具备现代负载所需的高压缩与高性能,也拥有灵活的 schema 设计能力。宽事件更进一步,让我们超越“日志 / 指标 / 追踪”这三大传统支柱,能在单条记录中表达完整上下文。ClickHouse 已在海量实战中证明这些理念是可行的。
而 ClickStack 的使命则是:让这种能力为所有人所用。几条命令即可启动,无需专属维护团队、无需牺牲性能与开放性,就能构建强大可观测性系统。这是新的可观测性范式:无孤岛、无锁定、无高价。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









