





本文字数:8227;估计阅读时间:21 分钟
作者:Kevin Biju Kizhake Kanichery
本文在公众号【ClickHouseInc】首发

在我看来,最糟糕的 bug,莫过于那些你决定不再深究的问题。
也许这个问题只在 2% 的场景中才会出现,或者只有在某些奇怪的环境下,比如特定品牌的硬件上,才会复现。也许客户一开始提供的信息就不足,难以定位原因。又或者你实在没有时间彻底调查。
最终,大家都会把这事抛在脑后。但当几个月后同样的 bug 再次出现时,你只能心里嘀咕一句,后悔当初没有坚持到底。今天要讲的,就是这样的一个故事。
ClickPipes 团队在 Postgres 只读副本上创建逻辑复制槽(logical replication slot)时遇到了一个问题。具体表现为,原本几秒钟就能执行完成的查询,这次却持续了几个小时,而且无论用 Postgres 提供的哪种方法,都无法终止它。这不仅让客户感到非常困扰,还威胁到了生产数据库的稳定性。在这篇博客文章中,我会分享我们是如何排查这个问题,并最终确认这是一个 Postgres 的 bug。同时也会介绍我们如何修复它,以及与 Postgres 社区的协作经历。
介绍
ClickPipes 的使命很简单:帮助客户轻松地将大量数据从 <X> 迁移至 ClickHouse Cloud,X 是一组不断扩展的对象存储、队列和数据库。我的团队专注于数据库数据管道的开发。在这之前,我们曾是初创公司 PeerDB,致力于从 Postgres 向 <X> 传输海量数据。得益于长期聚焦 Postgres,我们的团队在大规模变更数据捕获(CDC,Change Data Capture)方面积累了深厚的经验。
对于不熟悉的人来说,变更数据捕获(CDC)是持续跟踪数据库变更的过程,ClickPipes 借此可以将变更近乎实时地复制到 ClickHouse。Postgres 主要通过逻辑复制槽(logical replication slots)来实现 CDC[https://www.postgresql.org/docs/current/logical-replication.html]。逻辑复制槽从预写日志(WAL,Write-Ahead Log)中解码变更[https://www.postgresql.org/docs/current/wal-intro.html],并以流式传输的方式发送给消费端以供重放。它们就像是中间层,把原始的 WAL 数据转换为可消费的变更事件。我们的 Postgres ClickPipe 正是基于逻辑复制槽构建的,创建槽之后可以从数百个客户数据库中读取数据。
灾难的开始:距离“无法终止的查询”只差一步
一切始于我们的一个重要 PeerDB 客户联系了我们,说他们在新建的 Postgres 只读副本上设置数据管道时,整个过程似乎“卡住了”。我带着几种猜测登录到他们的实例,但表面上看一切正常——只有一个活跃的连接在执行某些操作。
SELECT pid,backend_start,xact_start,wait_event_type,wait_event,state,query
FROM pg_stat_activity
WHERE query LIKE '%pg_create_logical_replication_slot%'
AND pid!=pg_backend_pid();
-[ RECORD 1 ]---+--------------------------------------------------------------
pid | 5074
backend_start | 2025-06-27 14:57:01.458979+05:30
xact_start | 2025-06-27 14:57:47.819348+05:30
wait_event_type |
wait_event |
state | active
query | SELECT * FROM pg_create_logical_replication_slot('demo_slot', 'pgoutput');
创建新管道时,第一步之一是创建逻辑复制槽。这通常只需几秒钟,但这次却迟迟没有完成。我们没有看到任何 wait_event,这意味着 Postgres 认为该命令没有在等待任何资源。此外,pg_replication_slots 系统表里也出现了我们正在创建的槽,并且关联了一个活跃的 PID。
确认问题来源于 Postgres 后,我们尝试的第一种排查手段就是“重置管道”,让它重新运行。但这一操作带来了更令人担忧的情况:尽管 ClickPipe 已经断开连接,那个“顽固的查询”仍然没有消失。我们尝试通过 SQL 命令向相关后端进程发送 SIGINT 和 SIGTERM 信号,但都无济于事。尤其是 SIGTERM,作为最强制的终止信号,居然也没有生效,这令人十分警觉。
SELECT pg_cancel_backend(5074), pg_terminate_backend(5074);
pg_cancel_backend | pg_terminate_backend
-------------------+----------------------
t | t
(1 row)
SELECT pid,wait_event_type,wait_event,state,query
FROM pg_stat_activity
WHERE pid=5074;
pid | wait_event_type | wait_event | state | query
------+-----------------+------------+--------+----------------------------------------------------------------
5074 | | | active | SELECT pg_create_logical_replication_slot('demo_slot', 'pgoutput');
结果我们陷入了困境:复制槽被标记为“活跃”,但进程拒绝退出,导致无法删除这个槽。与此同时,该槽开始持续保留 WAL 日志用于解码。问题是,如果不能读取或删除这个槽,WAL 会一直被保留,存储空间会被不断占用,最终可能导致存储耗尽,影响数据库的正常运行。客户使用的是托管 Postgres 服务,唯一的解决方法就是彻底重启 Postgres 实例,以强制结束这个进程。但这样做会带来服务停机的风险,对生产环境极其不利。
如前所述,这并不是我们第一次见到这种现象。几个月前,另一位使用不同托管 Postgres 服务的客户,在只读副本上创建管道时也遇到了类似问题。虽然当时没能彻底解决,但调整了一些配置(比如启用 hot_standby_feedback)后,问题似乎就消失了,我们也就认为是托管服务的个别差异所致(而现在我们知道事实并非如此)。但当相同问题在不同的托管服务、最新的 Postgres 版本、并且启用了所有推荐配置的前提下再次出现时,我意识到是时候深入调查这个问题了。
等待那个永远不来的 COMMIT
我找到的第一个线索来自客户所用的 Postgres 服务商的支持团队,他们提供了一份针对出问题的后端进程的 strace 输出:
strace: Process 117778 attached
restart_syscall(<... resuming interrupted nanosleep ...>) = 0
nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0
...
从结果来看,只有大量的 nanosleep 系统调用,没有 IO 或其他系统调用,这表明后端进程正陷入一个持续 sleep 的循环,每次休眠固定 1 毫秒。这已经是一个重要线索,因为在 Postgres 代码里,只有极少数场景会出现这种持续 sleep 的循环。我顺着创建复制槽的控制流,找到了一个在特定条件下会这样休眠的函数,接着一路反推,弄清了它的作用以及会在什么情况下进入这种状态。虽然这个 bug 在生产环境中并不常见,但要“复现”其实非常简单:
-
要么自己搭建,要么请托管服务商为你准备一个 Postgres 集群(版本要在 16 及以上,因为从这个版本起只读副本才支持创建逻辑复制槽),包括主库和只读副本。
-
在主库上开启一个事务,并执行任意 DML 操作。Postgres 出于优化考虑,只有事务写入数据后,才会分配 transactionid(XID),所以这一步是为了让事务具备“真实的存在感”。此时先不要 COMMIT 或 ROLLBACK,保持会话处于活跃状态。
-
然后在只读副本上创建逻辑复制槽(最简单的方式是调用 SQL 函数 pg_create_logical_replication_slot)。一旦执行命令,Ctrl-C 便失效,尝试从其他会话取消或终止这个后端进程也无济于事。如果你通过 strace 监控这个进程,会看到反复出现 nanosleep 这样的系统调用。
-
当你在第 2 步的主库事务中执行 COMMIT 或 ROLLBACK 后,复制槽的创建最终就会返回成功。如果你之前尝试取消操作,这时也会被感知并正确地终止。
在复制槽创建的内部逻辑中,系统必须等待在创建槽命令之前已经开启的事务完成 COMMIT 或 ROLLBACK,才能达到“数据一致性点”,这样复制槽才能从这个点之后解码所有后续事务。虽然理论上在 Postgres 中不推荐出现长事务,但现实中诸如报表查询或大数据回填等业务场景确实会导致事务执行时间较长。如果此时创建复制槽,就不得不等待这些事务完成,因此耗时会比平常更久。
2025-05-22 10:44:53.868 UTC [1195] LOG: 00000: logical decoding found initial starting point at 0/356B148
2025-05-22 10:44:53.868 UTC [1195] DETAIL: Waiting for transactions (approximately 1) older than 6068 to end.
考虑到这些旧事务可能需要不确定的时间完成,Postgres 采用了一种高效的等待机制。它通过已有的锁机制,对旧事务加锁。因为事务只有在完成后才会释放其对应的 transactionid 锁,成功拿到这个锁就意味着事务已经结束。更好的是,这种等待过程是可观测的,相关的系统表可以展示出当前活跃的等待情况,便于管理员监控进度。
SELECT pid,wait_event_type,wait_event,state,query
FROM pg_stat_activity
WHERE pid=804;
pid | wait_event_type | wait_event | state | query
-----+-----------------+---------------+--------+----------------------------------------------------------------
804 | Lock | transactionid | active | SELECT pg_create_logical_replication_slot('demo_slot', 'pgoutput');
(1 row)
SELECT locktype,transactionid,pid,mode
FROM pg_locks
WHERE pid=804 AND granted='f';
locktype | transactionid | pid | mode
---------------+---------------+-----+-----------
transactionid | 6077 | 804 | ShareLock
如果需要,管理员可以直接取消这些耗时事务,或者中断仍在等待的复制槽创建。但这种策略只适用于“普通”的 Postgres 实例。事实上,在 Postgres 的只读副本中,这些机制的某些前提条件被打破,导致相同的操作在只读副本上却表现出完全不同的行为。
只读副本并没有你想象的那么神奇
“只读副本”是 Postgres 中处理只读流量的实例的通俗叫法,听起来好像很简单。但实际上,Postgres 称它们为“热备用(hot standby)”。所谓热备用,是指 Postgres 处于“恢复模式”的实例,持续不断地从主库接收 WAL(预写日志)记录,并通过这些日志与主库保持数据的完全同步。这里有一个关键点:备用库只能通过 WAL 间接感知主库上正在运行的事务。具体来说,备用库会根据接收到的 WAL 记录,持续维护一份主库活跃事务的列表,称为 KnownAssignedXids。
前文提到的实现“等待事务完成”逻辑的函数叫做 XactLockTableWait。对我们来说最关键的,就是其中的一个循环(代码已简化):
void
XactLockTableWait(TransactionId xid, Relation rel, ItemPointer ctid,
XLTW_Oper oper)
<...>
for (;;)
{
Assert(TransactionIdIsValid(xid));
SET_LOCKTAG_TRANSACTION(tag, xid);
(void) LockAcquire(&tag, ShareLock, false, false);
LockRelease(&tag, ShareLock, false);
if (!TransactionIdIsInProgress(xid))
break;
pg_usleep(1000L);
}
<...>
Postgres 会通过 LockAcquire 去获取指定事务 ID 的锁,这个过程会阻塞,直到目标事务完成并释放锁。拿到锁后,系统会立刻释放它,然后通过 TransactionIdIsInProgress 检查该事务是否仍在执行。如果没有,则直接退出。但如果事务还在进行中,就会进入一次 1 毫秒的 sleep,再继续下一轮循环。既然是在加锁之后才检查事务状态,为什么还会遇到事务未完成的情况呢?这是因为,正如代码注释所描述的,存在一个“窗口期”:在这段时间内,事务虽然已经登记为“正在运行”,但尚未真正持有 transactionid 锁。尽管代码对这种情况已有处理,sleep 的引入是为了避免在事务尚未达到一致状态时反复尝试加锁。一般来说,这种窗口期出现的机会不多,持续时间也很短。
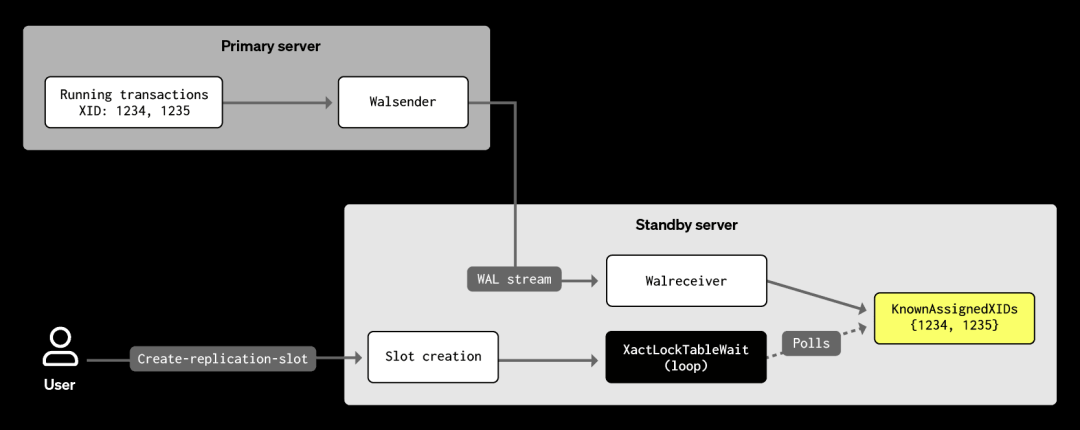
那么在热备用场景下,会发生什么呢?只读副本在创建逻辑复制槽时,也需要等到所有早于槽创建之前启动的事务完成,才能找到一致性点。但由于只读副本本身不会执行这些事务,所以 LockAcquire 在这里总是会立即返回。与此同时,TransactionIdIsInProgress 会参考 KnownAssignedXids,因此系统知道事务仍在进行中。于是,进程会进入 1 毫秒的 sleep,然后继续循环。但这一次,这不再是短暂的等待,而可能会一直卡在那里,甚至长达数小时。
-
在主库上,LockAcquire 的阻塞等待是高效的,而在只读副本上,这个等待却变成了固定 1 毫秒的轮询,长时间等待会浪费大量计算资源。
-
LockAcquire 在需要等待时会自动响应中断信号。但由于 XactLockTableWait 这个函数的设计是围绕 LockAcquire 来处理等待的,sleep 被当作是临时性补充,因此循环内没有中断处理的逻辑。这就导致了后端进程变成“不可杀死”的状态。
-
系统并不会报告自己正在等待外部操作,因为这一部分原本是 LockAcquire 来负责的。普通用户如果想要知道复制槽创建是否卡住了,只能通过日志判断,日志会提示需要等待旧事务完成。在主库上,这种等待还可以通过系统表直接观察。
这个问题是“好代码在意外场景下失效”的一个经典案例。代码本身设计严谨,但因为被应用在开发者当初没有预料的场景里,导致了新的问题。任何复杂的代码库里,这种事情都会不可避免地发生。
解决方案:为复制槽创建过程引入中断机制
我们当时最紧迫的问题是,备用库上在等待一致性点期间创建复制槽的过程无法被中断。为了解决这一点,我向 Postgres 官方邮件列表提交了一个补丁,主要是在每次 sleep 调用前加入了中断检查:
+ CHECK_FOR_INTERRUPTS();
pg_usleep(1000L);
Postgres 的维护者很快接受了这个补丁(特别感谢 Fujii Masao 的审阅),并将其回溯应用到所有受支持的主版本中。只要用户升级到最新的小版本,使用热备用的环境下,这个问题基本就能得到缓解。
此外,还有一位社区成员非常积极地解决了此处缺少 wait_event 标记和循环效率低的问题。相关补丁已经发布,增加了一个新的等待事件用于识别这种场景,同时也在讨论如何改进备用库在等待主库事务完成时的机制。这些更新仍在推进中,预计将在明年发布的 Postgres 19 中正式引入。
经验教训:回馈开源的价值
ClickPipes 团队意识到这不是孤立问题后,我花了大约一两天时间就找到了根本原因(RCA),并完成了解决方案的开发。得益于对 Postgres 代码库的熟悉,加上其良好的代码结构,我很快定位到 XactLockTableWait() 并逐步排查。虽然 Postgres 社区的贡献流程偏传统,需要通过邮件列表提交补丁,过程有些不够现代化,但社区成员的积极反馈和高效的补丁审阅、回溯工作,保障了最终用户的使用体验。
这次对一个看似普通的 bug 的调查,让我再次感受到现代数据库系统背后的深度与复杂性。即便像 Postgres 这样经历了数十年打磨的架构,依旧会在某些边缘场景中出现子系统交互的意外情况。类似地,ClickHouse 也以其列式存储引擎和丰富的特性,不断挑战分析性能的极限,这背后同样伴随着各种技术挑战。开源的特性,让我们能够及时发现、修复此类问题,并通过提交补丁的方式回馈社区,也算是对这些深受信赖的系统的一种致敬。
将数据从 PostgreSQL 复制到 ClickHouse,可以充分释放列式存储的性能、并行查询的能力以及对时序数据的高级分析支持,从而实现基于行存储的事务系统难以胜任的工作负载。我们推荐 ClickHouse Cloud 用户使用 ClickPipes for Postgres[https://clickhouse.com/docs/integrations/clickpipes/postgres],它提供托管的实时复制服务,无需额外的基础设施投入。对于自托管的 ClickHouse 用户,可以选择 PeerDB,提供高性能的自托管 CDC 能力。这两种方案都能很好地配合 Postgres 的只读副本进行 CDC 操作,有效减轻主库的复制压力。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









