





本文字数:5888;估计阅读时间:15 分钟
作者:Al Brown and Tom Schreiber
本文在公众号【ClickHouseInc】首发

摘要(TL;DR)
在 ClickHouse Cloud 中,用内存字典替代 join,让我们的查询提速最高可达 6.6 倍,并降低 60% 的成本,而且只需要对 SQL 做极少量修改。
这篇文章会介绍这种调优方案(字典),讲讲如何用它们进行维度表查找,以及基于 14 亿行数据的真实基准结果。
其他数据规模的图表可以在 GitHub 中查看。
何必仅满足于快?
如果你是第一次看到这系列文章,没关系。ClickHouse 的 join 在零调优下已经表现出色。在第 1 部分,我们用 17 条高并发 join 查询做测试,没做任何优化,ClickHouse 依旧比 Databricks 和 Snowflake 又快又便宜。
但这篇文章会更进一步。如果你想要更极致的速度,ClickHouse 原生的字典就能帮你做到,快、省、而且基本不用大改。
或许你会想:那我需要迁移吗?
好消息是:非常简单。在第 1 部分中,我们只是做了一个匹配的表结构,然后直接从外部的 Iceberg 表加载数据(也可以是 Delta Lake 或者 S3 上的 Parquet),join 查询保持不变,就已经跑得又快又省。
但为什么要停在这里?让我们看看通过一点 ClickHouse 原生调优,能把性能推到多高的水准。
本文会讲清楚如何把维度表转换成内存字典,从而极大地提升查询效率。这是最轻松可行的 join 加速方式之一,几乎是无缝接入,就能带来可观的性能收益。
字典,让 join 飞起来
首先介绍这套调优方案的主角:字典[https://clickhouse.com/blog/faster-queries-dictionaries-clickhouse]。
如果你的查询中涉及 join,特别是星型或雪花型模型中对小型维度表的外键 join,字典会带来非常显著的提升。
为什么选择字典?
字典允许你把表加载到内存中,以高效的键值结构形式保存,并针对超低延迟的查找做优化。当 join 的一侧(比如维度表)可以完全驻留在内存中时,就能把传统的 join 替换为字典查找,从而获得巨大的性能提升。
回顾一下基准测试
这个数据集模拟的是一个全国范围的咖啡连锁订单,包括:
-
Sales:订单事实表
-
Products:产品维度表
-
Locations:门店/位置维度表
这些表和第 1 部分完全一样,大部分查询都依赖大事实表与小维度表的外键 join,非常适合用内存字典来替换。
所以我们将不再基于磁盘表进行 join,而是把 Products 和 Locations 表加载到字典中,通过这样一个简单的调优,就能把性能再次大幅提升。
从表到字典:迁移维度表
接下来一起看看,如何把已有的维度表迁移成字典结构。
ClickHouse 的字典非常灵活,你几乎可以基于任何 ClickHouse 能查询的数据源来构建它们。无论是 Parquet、Arrow、JSON 这样的文件格式,还是 S3、HDFS、Kafka,或 Iceberg、Delta Lake 这样的开放表,只要 ClickHouse 能读,就能转成字典。
迁移 Locations 维度表:使用哈希键字典做查找
我们将把 S3 上存储的一个 Iceberg 表中的 Locations 维度表迁移成字典结构:
CREATE DICTIONARY dicts.dict_locations
(
location_id String,
record_id String,
city String,
state String,
country String,
region String
)
PRIMARY KEY location_id
SOURCE(CLICKHOUSE(
QUERY "
SELECT
COALESCE(location_id, '') AS location_id,
COALESCE(record_id, '') AS record_id,
COALESCE(city, '') AS city,
COALESCE(state, '') AS state,
COALESCE(country, '') AS country,
COALESCE(region, '') AS region
FROM icebergS3('s3://clickhouse-datasets/coffeeshop/dim_locations/')"))
LIFETIME(0)
LAYOUT(complex_key_hashed());这个 dict_locations 字典从外部 Iceberg 表加载,并会在所有 ClickHouse Cloud 计算节点中自动可用。我们将其 LIFETIME(生命周期)参数设置为 0,表示这是静态内容,不会自动刷新。
在基准查询中,对 Locations 维度表的所有查找都只是基于 location_id(比如 'AUSTX156' 或 'HOUTX133')的简单键查找。这里我们使用 complex_key_hashed 类型的字典布局,以支持基于字符串键的高速内存访问,因为像 flat 和 hashed 这样的布局只支持 UInt64 键。
字典的布局决定了在内存中以何种结构存储内容,以便对不同的查找模式做出最优响应。
迁移 Products 维度表:基于时间的范围查找
为了举一个第二个来源数据的案例,我们把 Products 维度表直接从第 1 部分用到的原生 MergeTree 表中迁移出来:
CREATE OR REPLACE DICTIONARY dicts.dict_products (
record_id String,
product_id String,
name String,
category String,
subcategory String,
standard_cost Float64,
standard_price Float64,
from_date Date,
to_date Date
)
PRIMARY KEY name
SOURCE(CLICKHOUSE(db 'coffeeshop' table 'dim_products'))
LIFETIME(0)
LAYOUT(COMPLEX_KEY_RANGE_HASHED())
RANGE(MIN from_date MAX to_date);在基准查询中,针对 Products 维度表的查找是基于时间范围的,通过 from_date 和 to_date 来定位某个时间点上生效的产品版本(比如在第四季度 Q4 看到的版本[https://github.com/ClickHouse/coffeeshop-benchmark/blob/dd63a6c60f61d5ff0b145d4ee2cb0ea3406d38c8/clickhouse-cloud/queries.sql#L83])。
为了解决这种需求,我们选择了 Range Dictionary。它就是专门针对“通过指定键+时间来匹配正确版本”这种场景做优化的。在内存中,ClickHouse 会先在主键上建立哈希索引,再在已排序的日期区间里做快速二分查找。
不过要注意一个细节:必须保证同一个键下没有重叠的时间范围,否则字典只会返回第一个匹配记录,而这往往不是你想要的结果。我们已经确认过,原始的 Products 维度表中不存在范围重叠。
ClickHouse 还支持更多适用于进阶场景的字典布局,例如正则表达式匹配、CIDR IP 段查找,或者点是否在多边形内(point-in-polygon)的地理空间查询。这些我们这次没用到,但如果你在做 user agent 分类、IP 定位、GPS 坐标映射之类的场景,非常值得研究一下。
更新查询以使用字典
字典配置完成后,更新 SQL 查询就很直接。原本的 join 都会变成闪电般快速的内存查找。我们的改造逻辑如下:
SELECT
f.order_date,
l.city,
p.subcategory
FROM fact_sales f
① JOIN dim_locations l
ON f.location_id = l.location_id
② JOIN dim_products p
ON f.product_name = p.name
AND f.order_date BETWEEN p.from_date AND p.to_date
WHERE …
GROUP BY …
ORDER BY …Sales 事实表需要与:
① 通过 location_id 与 Locations 维度表关联
② 通过 product_name 加上日期范围过滤(order_date BETWEEN from_date AND to_date)与 Products 维度表关联
这两个 JOIN 最终都会被替换成两个基于字典的查找:
SELECT
f.order_date,
① dictGet(
'dicts.dict_locations', 'city',
f.location_id) AS city,
② dictGet(
'dicts.dict_products','subcategory',
f.product_name, f.order_date) AS subcategory,
FROM fact_sales f
WHERE …
GROUP BY …
ORDER BY …① 在 dict_locations 字典中基于 location_id 进行一对一的直接查找
→ 相当于用内存字典查找替代了简单的等值 join。
② 在 dict_products 字典中使用 product_name 与 order_date 组成的复合键,进行基于范围的查找
→ 也就是用范围查找(order_date BETWEEN from_date AND to_date)替代传统 join,并且能确保按时间匹配到正确的产品版本。
这几个小的更改,就能把查询计划中原本的完整 join 移除,换成超快的内存查找。这种模式在 17 条基准查询里都可以套用,非常简单易行。
结果:究竟快了多少?
把所有维度查找切换成字典,并且稍作调整查询后,我们重新跑了完整基准测试,来看看带来了多大收益。
补充说明,我们依旧在 ClickHouse Cloud 上做测试,同时调节了计算节点数量(也借此验证了 ClickHouse Cloud 的 Parallel Replicas 并行副本特性)。所有服务规格都是每个节点 30 核心、120GB 内存。图表中标签采用以下格式:
CH 2n_30c_120g,其中:
-
2n = 计算节点数量
-
30c = 每节点 CPU 核心数
-
120g = 每节点内存(GB)
为方便聚焦,这里只展示 1b 规模(即 14 亿行事实表)的结果,500m 和 5b 的完整图表可以在 GitHub 查看[https://github.com/ClickHouse/coffeeshop-benchmark/tree/main/charts/tuned]。
总耗时
和第 1 部分一样,下面这张图展示了各系统顺序执行 17 条查询的总耗时(单位:秒),括号中还标注了运行全部查询的总成本。
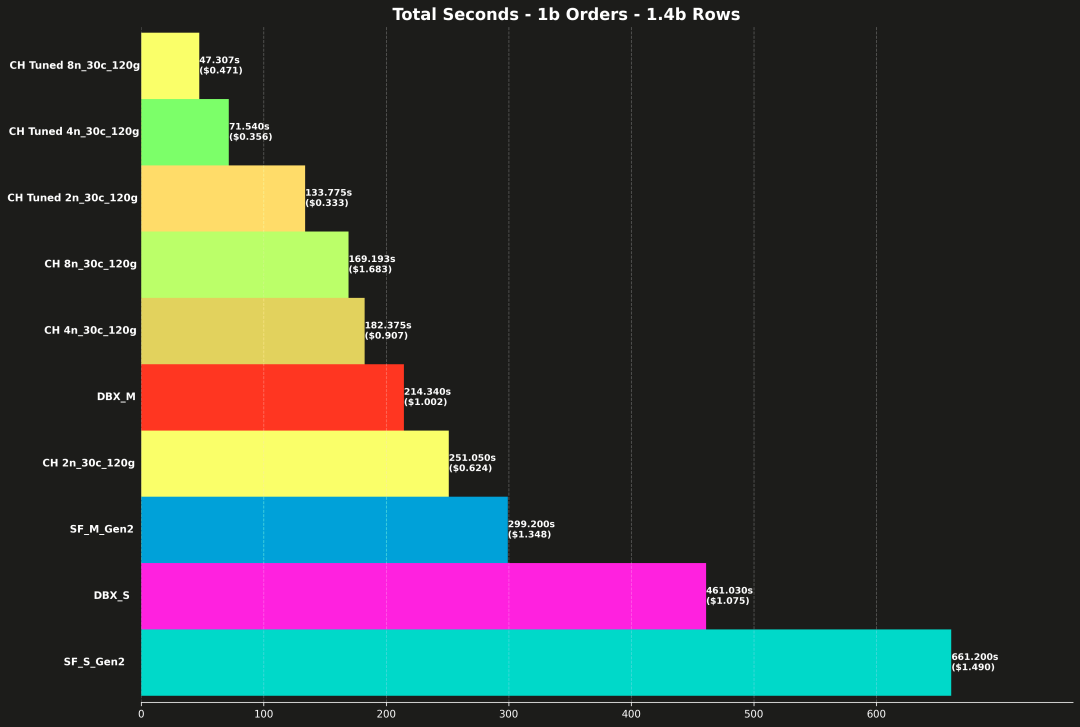
来看一下调优后的 ClickHouse 和未调优版本的对比:同样的算力配置、同样的数据,单纯只是查询方式优化,就有惊人的表现:
- 2 节点(2n_30c_120g)
-
未调优:251.05 秒
-
调优:133.78 秒
→ 相当于提速 1.9 倍,成本降低 47%。
-
- 4 节点(4n_30c_120g)
-
未调优:182.38 秒
-
调优:71.54 秒
→ 提速 2.5 倍,且成本降低超过 60%(0.907 美元 → 0.356 美元)。
-
- 8 节点(8n_30c_120g)
-
未调优:169.19 秒
-
调优:47.31 秒
→ 提速 3.5 倍,成本也降低 44%,而且对比最快的其他非 ClickHouse 服务,不仅快得惊人,还便宜得多。
-
每条查询的运行时间(不含 Q10 和 Q16)
下一个图表把总运行时间拆分成了每条查询的运行时间。
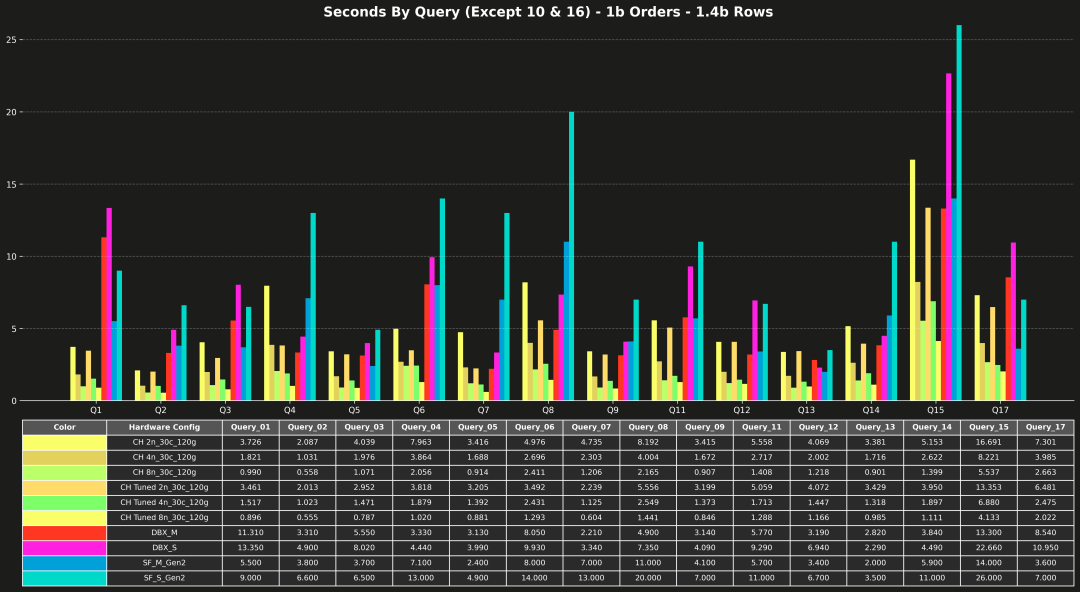
让我们分解几个字典影响最大的典型查询:
Q04
-
2n: 7.96s → 2.95s
-
4n: 3.86s → 1.47s
-
8n: 2.06s → 0.79s
→ 大约 2.5–3 倍提速,使用字典替代 join 带来巨大收益
Q08
-
2n: 8.19s → 3.55s
-
4n: 4.00s → 2.55s
-
8n: 2.17s → 1.29s
→ 显著提速:大约快 2–2.7 倍
Q15
-
2n: 16.69s → 6.48s
-
4n: 8.22s → 3.95s
-
8n: 5.54s → 2.02s
→ 大约 2–3 倍提速,尤其在 2 节点和 8 节点上非常亮眼
Q17
-
2n: 7.30s → 3.95s
-
4n: 3.99s → 2.48s
-
8n: 2.66s → 1.37s
→ 依旧稳定实现大约 2 倍提速
每条查询的运行时间(仅 Q10 和 Q16)
最后,这里是针对 Q10 和 Q16 的单独图表。正如第 1 部分所提到的,这两个查询是异常值,比其他查询要慢得多,会影响整体图表的比例,因此原文将它们单独分开。
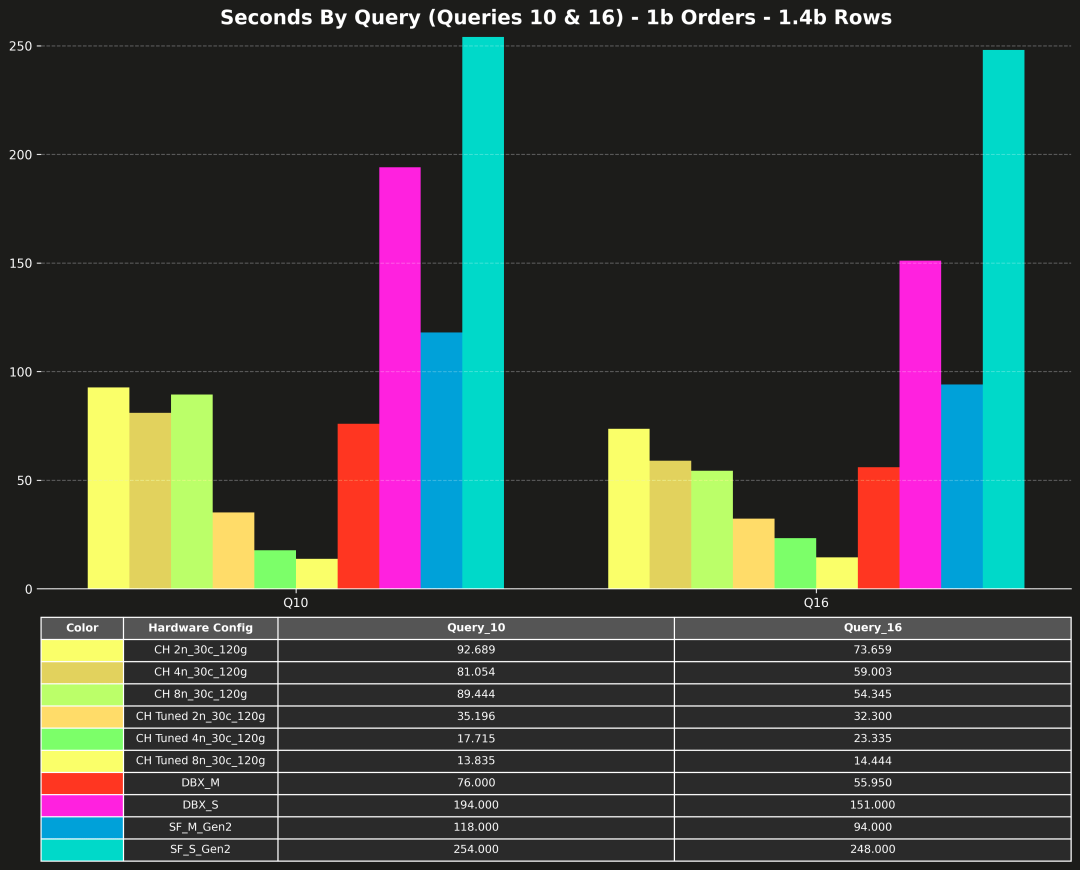
来看看针对 Query 10 和 16,调优后带来的性能改进:
Query 10:大 join + 过滤
-
2n 配置:从 92.69s → 35.20s
→ 大约 2.6 倍提速 -
4n 配置:从 81.05s → 17.72s
→ 大约 4.6 倍提速 -
8n 配置:从 89.44s → 13.84s
→ 大约 6.6 倍提速,比图表上任何其他结果都快
Query 16:复杂且开销大的 join
-
2n 配置:从 73.66s → 32.30s
→ 大约 2.3 倍提速 -
4n 配置:从 59.00s → 23.34s
→ 大约 2.5 倍提速 -
8n 配置:从 54.35s → 14.44s
→ 大约 3.7 倍提速,再次成为最快
快,还能更快
ClickHouse 本身就非常快,但在做了有针对性的小优化,用内存字典替代传统 join 后,我们又把它的速度和成本优势进一步放大。
-
在这些以 join 为主的查询中,最高实现了 6.6 倍的提速,并且节省超过 60% 的费用。
-
即便是最庞大、最复杂的查询(像 Q10 和 Q16),只用简单的字典查找,就能快上几分钟完成。
-
而且这些优化不需要重新加载任何数据,不需要修改 schema,并且可以从 2 节点平滑扩展到 8 节点。
如果你在做维度表的 join,字典绝对是毫无疑问的选择。它快速、灵活、上手成本低。如果你正在考虑使用 ClickHouse,那就是最好的证明:这个引擎不仅快,而且用得越多,它就越快。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









