





本文字数:17443;估计阅读时间:44 分钟
作者:Dale McDiarmid
本文在公众号【ClickHouseInc】首发

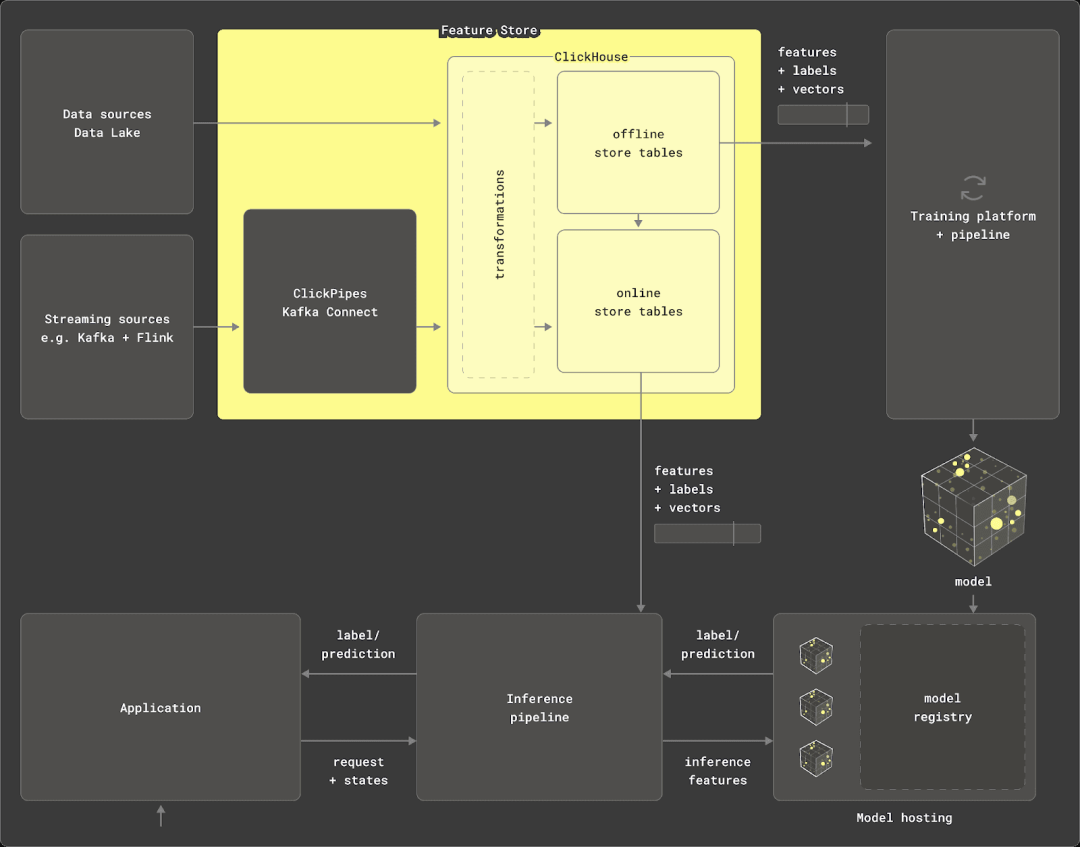
本文将探索 MLOps 的世界,探讨如何在 ClickHouse 中对数据进行建模和转换,使其成为高效的特征存储,用于训练机器学习模型。本文讨论的方法已被现有的 ClickHouse 用户采用,感谢他们分享这些技术,同时我们也会探讨开箱即用的特征存储解决方案。
我们将重点关注 ClickHouse 作为数据源、离线存储和转换引擎的角色。这些特征存储组件对于高效、准确地传递数据至关重要。尽管大多数开箱即用的特征存储提供了抽象层,我们将深入探讨如何高效建模数据,以构建和提供特征。无论您是希望构建自己的特征存储,还是只是对现有存储使用的技术感到好奇,请继续阅读。
为什么选择 ClickHouse?
在之前的博客文章中,我们已经探讨过什么是特征存储,并建议用户在深入阅读本文之前先了解这一概念。简单来说,特征存储是一个集中式存储库,用于存储和管理用于训练机器学习模型的数据,旨在提高协作性和重用性,同时减少模型迭代时间。
作为一个实时数据仓库,ClickHouse 除了提供数据源之外,还能够满足特征存储的两个主要需求。
-
转换引擎:ClickHouse 利用 SQL 进行数据转换声明,并通过其强大的分析和统计功能进行优化。它支持从多种数据源(如 Parquet、Postgres 和 MySQL)中查询数据,并在 PB 级数据上执行聚合操作。物化视图允许在插入时进行数据转换。此外,ClickHouse 还可以通过 chDB 在 Python 中使用,以处理和转换大型数据帧。
-
离线存储:ClickHouse 可以通过 INSERT INTO SELECT 语句持久化查询结果,自动生成表架构。它支持高效的数据迭代和扩展,特征通常以时间戳为查询点的方式存储在表中。ClickHouse 的稀疏索引和 ASOF LEFT JOIN 子句加速了过滤和特征选择过程,优化了训练管道中的数据准备工作。这些操作在集群中并行执行,使得离线存储可以扩展到 PB 级别,同时保持特征存储的轻量化。
在本文中,我们将展示如何在 ClickHouse 中对数据进行建模和管理,以实现这些功能。
总体步骤
当使用 ClickHouse 作为离线特征存储的基础时,我们将训练模型的步骤概括为以下几个部分:
-
探索 - 通过 SQL 查询熟悉 ClickHouse 中的源数据。
-
识别数据子集和特征 - 确定可能的特征、它们各自的实体,以及生成这些特征所需的数据子集。我们称这些子集为“特征子集”。
-
创建特征 - 编写 SQL 查询以生成所需特征。
-
生成模型数据 - 适当地组合这些特征,生成一组特征向量,通常通过在公共键和时间戳邻近性上使用 ASOF JOIN 来实现。
-
生成测试集和训练集 - 将“特征子集”拆分为测试集和训练集(可能还有验证集)。
-
训练模型 - 使用训练数据进行模型训练,可能尝试不同的算法。
-
模型选择与调优 - 使用验证集评估模型,选择最佳模型,并微调超参数。
-
模型评估 - 使用测试集评估最终模型。如果性能足够好,则可以停止;否则,返回步骤 2。
我们主要关注步骤 (1) 到 (5),因为这些步骤是 ClickHouse 特有的。上述过程的一个关键特点是其高度迭代性。步骤 (3) 和 (4) 可以宽泛地归为“特征工程”,这一过程通常比选择模型和优化超参数更耗时。因此,优化这一过程,并确保 ClickHouse 的高效使用,可以带来显著的时间和成本节省。
接下来,我们将逐步探讨这些步骤,并提出一种灵活的方法,充分利用 ClickHouse 的特性,帮助用户高效地进行迭代。
数据集与示例
在本示例中,我们使用了以下网站分析数据集,详见此处【https://clickhouse.com/docs/en/getting-started/example-datasets/metrica】。该数据集包含 1 亿行数据,每行代表对特定 URL 的请求。使用 ClickHouse 处理网站分析数据并训练机器学习模型是常见的用例[1][2]。
由于数据量较大,以下表格仅包含我们将使用的列。完整的表结构请见此处【https://pastila.nl/?00acf5da/2295705307eb4090c33cb5f0f5b8d472#kSJRFJM6RcULiQUo90npfA==】。
CREATE TABLE default.web_events
(
`EventTime` DateTime,
`UserID` UInt64,
`URL` String,
`UserAgent` UInt8,
`RefererCategoryID` UInt16,
`URLCategoryID` UInt16,
`FetchTiming` UInt32,
`ClientIP` UInt32,
`IsNotBounce` UInt8,
-- many more columns...
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))为了说明建模步骤,假设我们希望使用此数据集构建一个模型,以预测用户在请求到达时是否会跳出。如果考虑上述源数据,这由 IsNotBounce 列表示。此列代表我们的目标类别或标签。
我们不会实际构建这个模型或提供 Python 代码,而是专注于数据建模过程。因此,所选择的特征仅作示例用途。
步骤 1 - 探索
要探索和理解源数据,用户需要先熟悉 ClickHouse SQL。我们建议用户在此过程中熟悉 ClickHouse 提供的各种分析功能。一旦掌握了数据,我们就可以开始识别模型所需的特征及相应的数据子集。
步骤 2 - 特征和子集
为了预测一次访问是否会跳出,我们的模型需要一个训练集,其中每个数据点都包含组装成特征向量的适当特征。这些特征通常基于数据的一个子集。
我们在其他博客中探讨过特征和特征向量的概念,以及它们分别如何与结果集的列和行对应。关键是,这些特征在训练和请求时都必须可用。
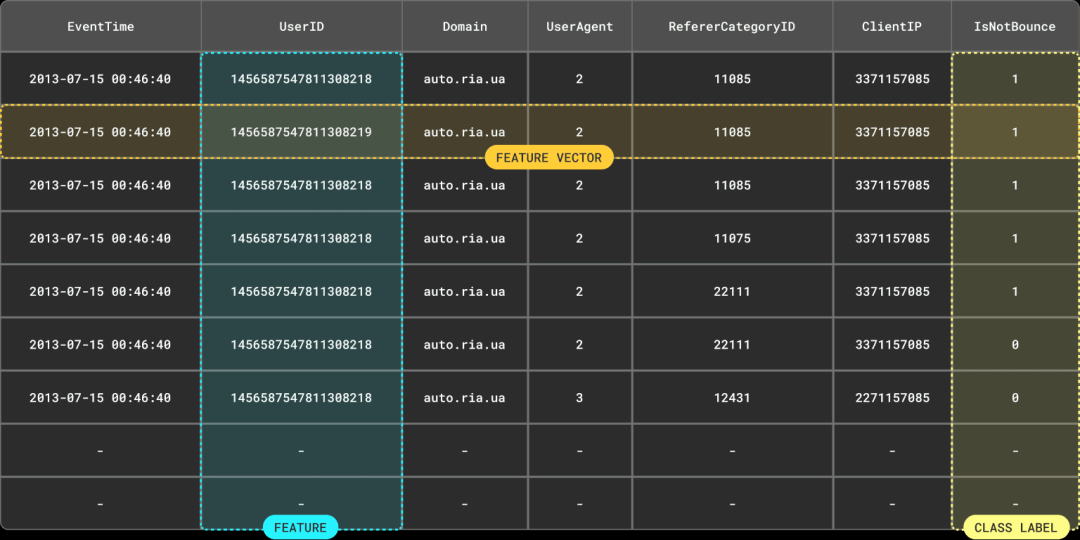
请注意,我们在上文中强调了“结果集”。特征向量往往不仅仅是表中某一行包含的列特征。通常情况下,需要通过复杂的查询来计算特征,这些查询可能涉及聚合或转换操作。
识别特征
在识别特征之前,我们需要了解两个关键属性,它们会影响我们的建模过程:
-
与实体的关联 - 特征通常与一个实体相关联或“键入”到该实体。对于我们的任务,可能有助于预测的特征可能是基于用户或域的组合。基于用户的特征通常与特定请求相关,例如用户的年龄、客户端 IP 或用户代理。基于域的特征则与访问的页面相关,例如每年的访问次数。
要将特征与某个实体实例关联,需要该实体有一个键或标识符。在我们的例子中,我们需要一个用户标识符和一个域名值。这些分别可以从 UserID 和 URL 列中获得。我们可以使用 ClickHouse 的 domain 函数从 URL 中提取域名,即 domain(URL)。
-
动态与复杂 - 虽然有些特征是相对静态的,例如用户的年龄,但其他特征如客户端 IP 会随着时间的推移而变化。在这种情况下,我们需要获取特定时间戳下的特征值,这是创建时点正确训练集的关键。
某些特征可能相对简单,例如设备是否为移动设备或客户端 IP,而其他更复杂的特征则需要聚合统计数据,并且这些数据会随时间变化——这是 ClickHouse 的强项所在!
示例特征
例如,假设我们认为以下特征有助于预测用户访问网站时是否会跳出。由于这些特征都是动态的,并且会随时间变化,因此它们都与时间戳关联
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









