





本文字数:8563;估计阅读时间:22 分钟
作者:ClickHouse Team
本文在公众号【ClickHouseInc】首发

时间!又一个月过去了,这意味着又到了发布新版本的时间!
发布概要
本次ClickHouse 24.7 版本包含了18个新功能🎁、12项性能优化🛷、76个bug修复🐛
新贡献者
一如既往,我们特别欢迎所有在 24.7 版本中的新贡献者!ClickHouse 的广受欢迎,很大程度上归功于社区的积极贡献。看到社区不断壮大,总是让人感到谦虚。
以下是新贡献者的名单:
0x01f, AntiTopQuark, Daniel Anugerah, Elena Torró Martínez, Filipp Bakanov, Gosha Letov, Guspan Tanadi, Haydn, Kevin Song, Linh Giang, Maksim Galkin, Max K., Nathan Clevenger, Rodolphe Dugé de Bernonville, Tobias Florek, Yinzuo Jiang, Your Name, Zawa-II, cw5121, gabrielmcg44, gun9nir, jiaosenvip, jwoodhead, max-vostrikov, maxvostrikov, nauu, 忒休斯~Theseus
按顺序读取的优化
由 Anton Popov 贡献
在从表中读取数据时,ClickHouse 默认应用了一些优化。其中之一是 optimize_read_in_order:如果查询中的 ORDER BY 列是表主键的前缀,或者在完全排序的合并连接中,一个或两个连接表的物理行顺序与连接键的排序顺序一致,则数据可以按磁盘顺序读取,从而跳过排序操作。这通常也有利于内存使用。因为不需要进行完整的内存排序,所需内存更少。此外,当查询使用 LIMIT 子句时,还可以进行短路操作。
然而,optimize_read_in_order 优化虽然防止了数据重新排序,但也降低了读取表数据的并行性。通常,表数据会被划分为不重叠的范围,由 N 个线程并行读取(流式传输)到查询引擎中以进行进一步处理(N 由 max_threads 设置控制)。
下图展示了为何这种方法不适用于 optimize_read_in_order 优化:
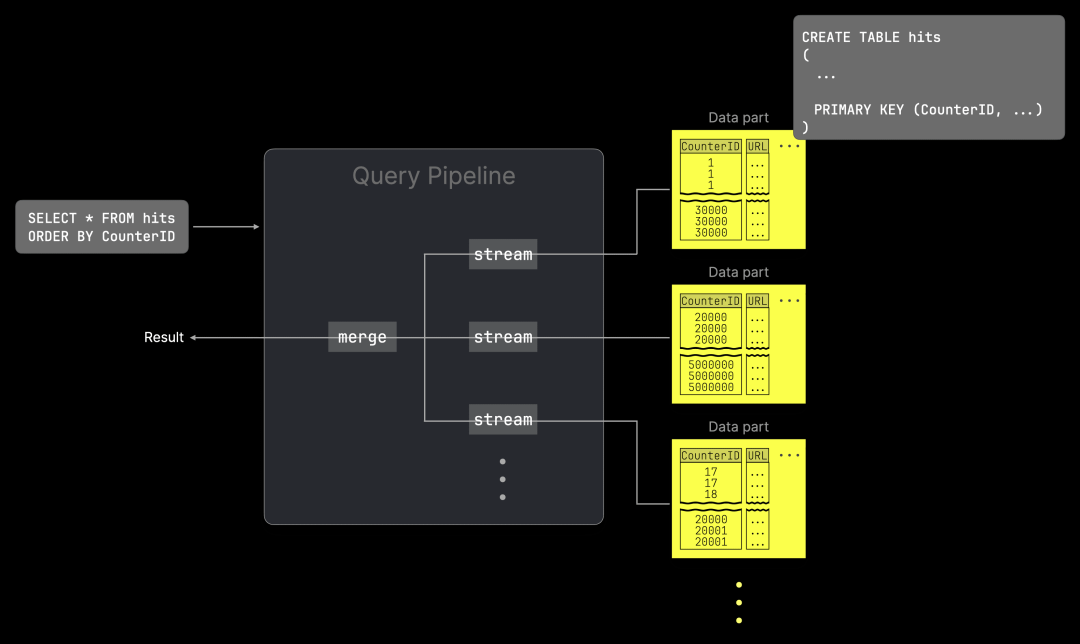
在上图中,我们勾画了属于表的部分数据,这些数据在磁盘上的行(每个数据部分)首先按 CounterID 列排序。我们展示了一个查询管道(物理执行计划),该查询包含一个 ORDER BY 子句,与表在磁盘上的物理行顺序一致。因此,无需重新排序数据。相反,表中已(局部)排序的行通过在各数据部分内以及跨数据部分的交错线性扫描进行合并。这意味着数据不是并发流式传输的,而是顺序处理的。
ClickHouse 24.7 版本现在引入了在合并步骤前对表数据部分进行缓冲的功能,该功能由设置 read_in_order_use_buffering 控制(默认启用)。尽管这增加了内存使用量,但也提升了查询执行的并行性,因为它允许在数据合并到最终结果之前将其并发地流式传输到缓冲区:
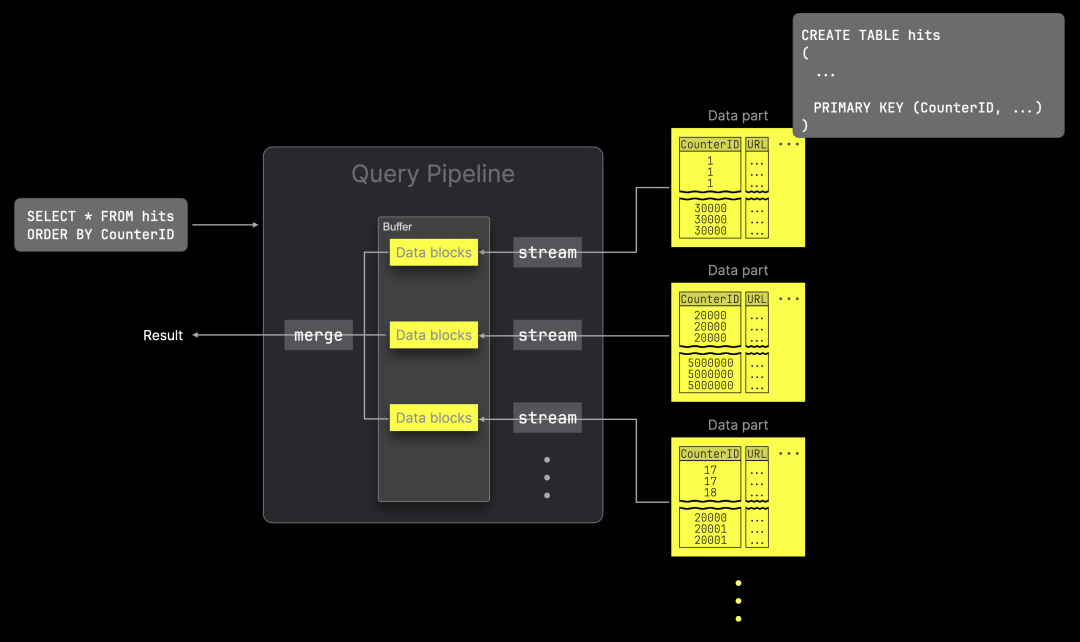
如果查询使用了高选择性过滤器(显著减少了流式传输和缓冲的数据量),应用 optimize_read_in_order 优化的查询性能最多可提升 10 倍。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









