






 本文介绍了使用scrapy框架爬取糗事百科的过程,包括创建scrapy项目、设置User-Agent、爬取网页内容以及将数据保存到json文件。通过修改setting.py和pipelines.py文件,实现了数据的持久化存储。
本文介绍了使用scrapy框架爬取糗事百科的过程,包括创建scrapy项目、设置User-Agent、爬取网页内容以及将数据保存到json文件。通过修改setting.py和pipelines.py文件,实现了数据的持久化存储。
scrapy练习_爬“糗事百科”
scrapy是一个爬虫用的脚手架,和用于搭建网站的vue差不多。具体我也不知道有什么用(~ _ ~ ")。
创建scrapy项目
首先创一个新建文件夹,之后打开jupyter notebook,虽然可以不打开,直接使用cmd,但是cmd的界面真是不太容易看,而且很乱。
- 在jupyter notebook界面中输入dir,确定我们进入了刚刚创建的文件夹中。
- 输入
! scrapy startproject qsbk
创建名为qsbk的scrapy项目
这样它就会为我们创建这样的脚手架(马赛克部分是后来的)

- 用“cd qsbk”进入自动创建的qsbk文件夹里
- 输入
! scrapy genspider qsbk_spider "qiushibaike.com"
创建名为"qsbk_spider"的py文件,后面是即将要爬的网站url,其实这个url后面也要改。
总的来说就是像这样

于是我们就创建了这些文件,爬虫脚手架就搭建完成了。

先做个准备运动,还有一个小实验
首先找到setting.py,里面有很多被注释掉的代码,都是给你备用的。
找到"ROBOTSTXT_OBEY",这是一个“君子协议”——网页会规定一些你不能爬的东西,但是我不听 。这个"ROBOTSTXT_OBEY"默认是True,所以要改成False,表示你不遵守这些协议。如果你遵守那就真的没什么好爬的了。

然后便是在下面找到"DEFAULT_REQUEST_HEADERS",加入User-Agent,要获得这个东西很简单。只要随便找一个网站,点击F12→Network→All→点击左边框框随便一个选项→然后拖到最下边,就能找到User-Agent。
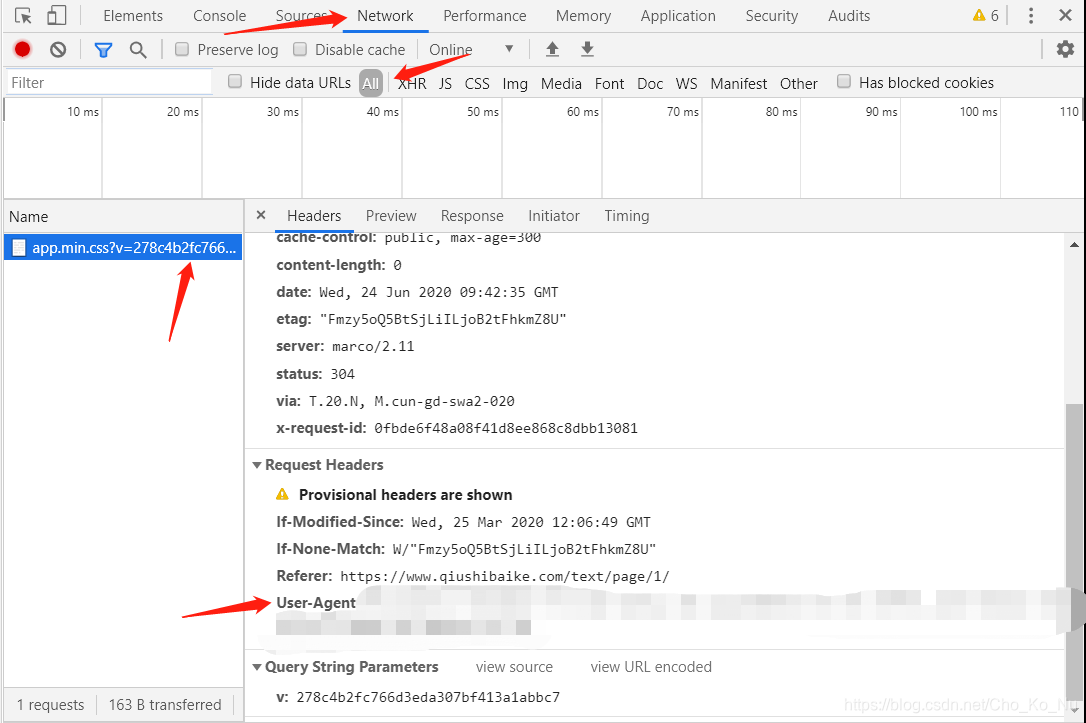
点击ctrl+s保存。
接着进入spiders文件夹里的qsbk_spider.py文件里。里面原本的内容是这样的。
# -*- coding: utf-8 -*-
import scrapy
class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
allowed_domains = ['qiushibaike.com']
start_urls = ['http://qiushibaike.com/']
def parse(self, response):
pass
于是我们要先做一个实验。这是糗事百科的url:https://www.qiushibaike.com/text/page/1/。我们先改一改start_url里的内容。
import scrapy
class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/page/1/']
def parse(self, response):
print('=' * 40)
print(response)
print('=' * 40)
这只是个实验,我们让它访问一下这个网页,看看它能返回什么。在jupyter notebook里输入
! scrapy crawl qsbk_spider
来运行这个代码,注意,此时你的位置必须在有"scrapy.cfg"这个文件的文件夹里才能运行,否则就会说“找不到crawl这个文件”,也可以输入
cd C:\Users\*****\Desktop\钉钉文件\scrapy\scrapy练习(糗事百科)\qsbk
来进入这个文件夹。多输入几次没关系的。

返回状态码200,说明我们这个访问是成功的。
开始爬糗事百科
我们依旧是在qsbk_spider.py文件里进行工作,代码总的来说是这样的:
# -*- coding: utf-8 -*-
import scrapy
class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/page/1/']
def parse(self, response):
# SelevtorList
duanzidivs = response.xpath("//div[@id='content']/div/div[2]/div")
for duanzidiv in duanzidivs:
# Selevtor
author = duanzidiv.xpath(".//h2/text()").get().strip()
content = duanzidiv.xpath(".//div[@class='content']//text()").getall()
# getall 提取信息并返回列表
content = "".join(content).strip()
print(author)
print(content)
我使用xpath的方法来爬取数据,先把包住了所有故事和作者的版块爬下来,之后再一块一块爬。author是作者,content是内容。再用strip处理一下空格和回车。之后我们将它们输出。
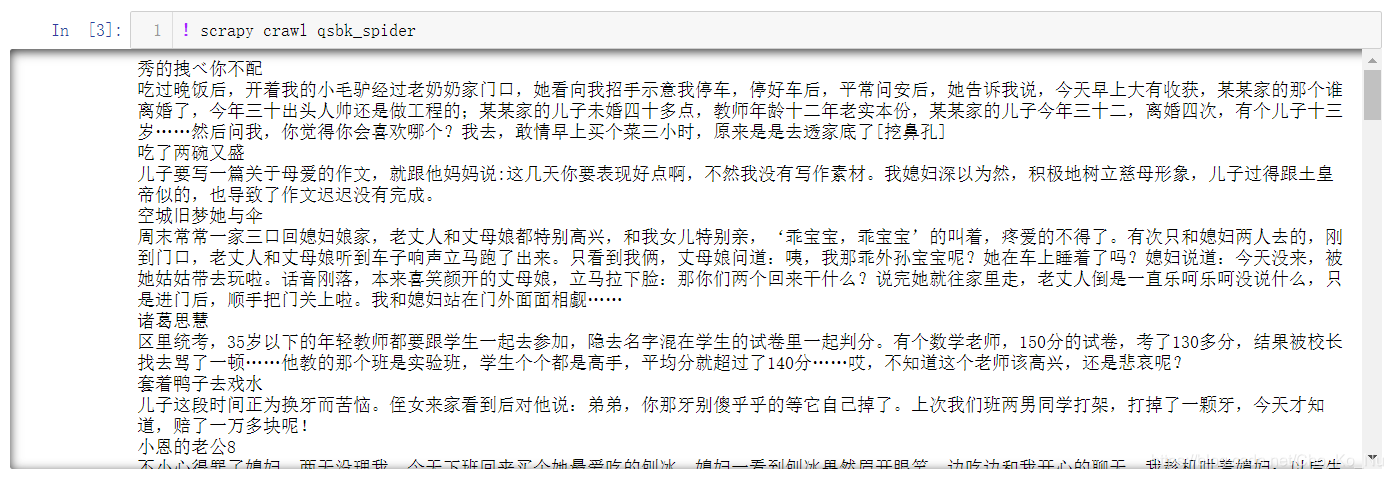
作者和内容都输出来了。那么接下来就是写入json文件。
写入json文件
piplines.py
打开pipelines.py文件,里面有一些代码。
class QsbkPipeline:
def process_item(self, item, spider):
return item
但是我们需要做一些修改:
总体来说就是这个样子。
import json
class QsbkPipeline:
def __init__(self):
self.fp = open("duanzi.json",'w',encoding='utf-8')
def open_spider(self,spider):
print('爬虫开始了···')
def process_item(self, item, spider):
item_json = json.dumps(item,ensure_ascii=False)
self.fp.write(item_json + '\n')
return item
def close_spider(self,spider):
self.fp.close()
print('爬虫结束了···')
首先导入json库。
import json
之后打开一个json文件(没有它会自动创建,无需手动创建),方法是’w’写入,编码是’utf-8’。
def __init__(self):
self.fp = open("duanzi.json",'w',encoding='utf-8')
爬虫打开来之后就会调用这个函数,我们输出一句“爬虫开始了”,表示自己正在爬。
def open_spider(self,spider):
print('爬虫开始了···')
我们将爬虫爬到的数据处理成名为duanzi的字典,之后这个字典会自动传入到’item’这个参数中,把字典转为json文件。'ensure_ascii = False’用于保存中文。
def process_item(self, item, spider):
item_json = json.dumps(item,ensure_ascii=False)
self.fp.write(item_json + '\n')
return item
如果直接将dict类型的数据写入json文件中会发生报错,因此在将数据写入时需要用到json.dump()。'ensure_ascii = False’用于保存中文,没有的话,中文会用ASCII码进行编译。
最后别忘了关闭文件,然后说结束语。
def close_spider(self,spider):
self.fp.close()
print('爬虫结束了···')
setting.py
找到setting.py文件,将这一段代码解封。这是一段确定优先级的代码。

qsbk_spider.py
回到qsbk_spider.py文件,将代码修改成这样。
# -*- coding: utf-8 -*-
import scrapy
class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/page/1/']
def parse(self, response):
# SelevtorList
duanzidivs = response.xpath("//div[@id='content']/div/div[2]/div")
for duanzidiv in duanzidivs:
# Selevtor
author = duanzidiv.xpath(".//h2/text()").get().strip()
content = duanzidiv.xpath(".//div[@class='content']//text()").getall()
# getall 提取信息并返回列表
content = "".join(content).strip()
# 存入数据
duanzi = {"author":author,"content":content}
yield duanzi
把author和content做成一个字典。
yield是生成器,简单地说就是一个可以迭代的return。
点击运行
点击运行之后,就会像这样。json文件里全都是作者和内容。
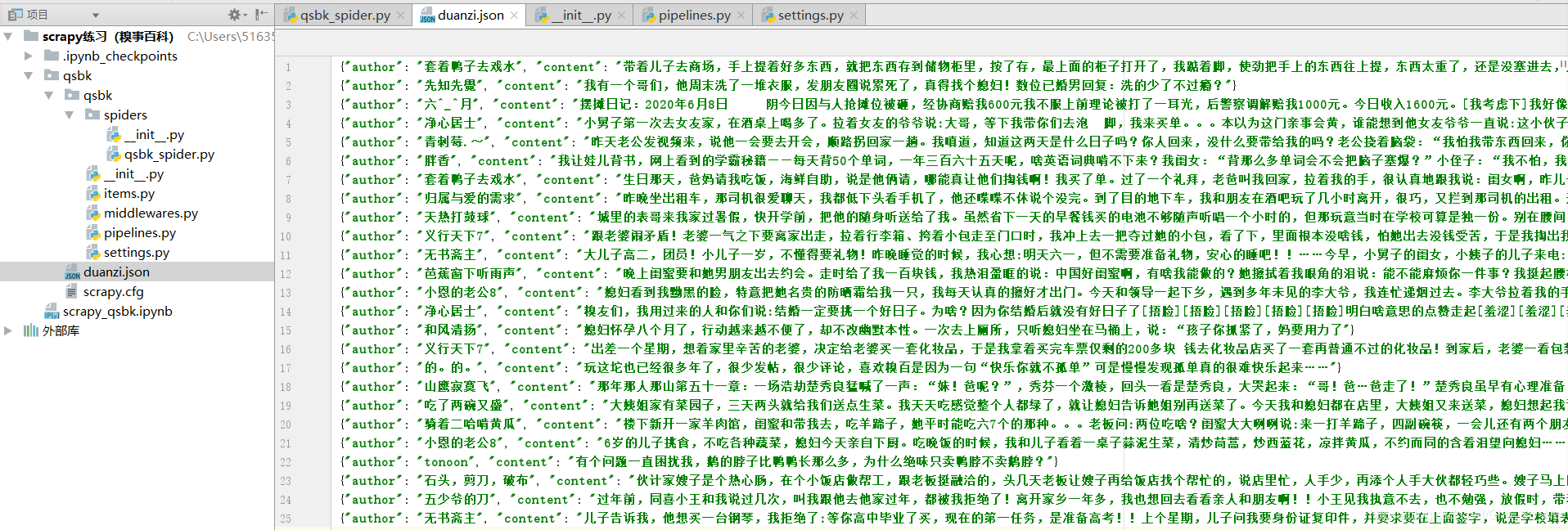


















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









