







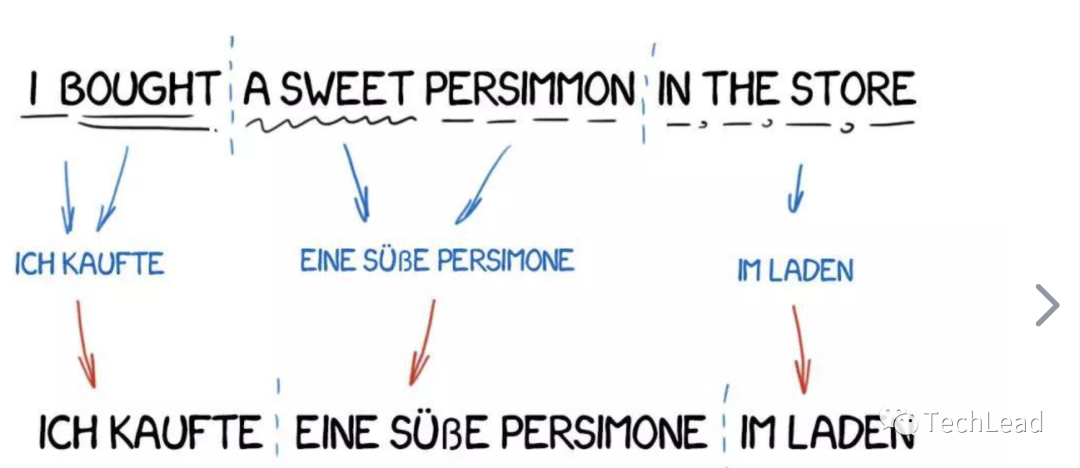
在当今信息全球化的背景下,语言障碍的克服变得尤为重要。机器翻译,它将一段文本从一种语言自动翻译到另一种语言。作为连接不同语言和文化的桥梁,其发展受到了前所未有的关注。在本次实验中,我们将重点探讨如何利用序列到序列(seq2seq)模型来实现机器翻译。并通过引入注意力机制,使模型能够更好地捕捉源语言和目标语言之间的复杂映射关系,从而提高翻译的准确性和流畅性。
一、实验原理
1.1、机器翻译
机器翻译,作为自然语言处理的一个核心领域,一直都是研究者们关注的焦点。其目标是实现计算机自动将一种语言翻译成另一种语言,而不需要人类的参与。它使用特定的算法和模型,尝试在不同语言之间实现最佳的语义映射。

机器翻译的核心是翻译模型,它可以基于规则、基于统计或基于神经网络。这些模型都试图找到最佳的翻译,但它们的工作原理和侧重点有所不同。
1.1.1基于规则的机器翻译 (RBMT)
基于规则的机器翻译(RBMT)是一种利用语言学规则将源语言文本转换为目标语言文本的技术。这些规则通常由语言学家手工编写,覆盖了语法、词汇和其他语言相关的特性。
1.1.2基于统计的机器翻译 (SMT)
基于统计的机器翻译 (SMT) 利用统计模型从大量双语文本数据中学习如何将源语言翻译为目标语言。与依赖语言学家手工编写规则的RBMT不同,SMT自动从数据中学习翻译规则和模式。
1.1.3基于神经网络的机器翻译
 基于神经网络的机器翻译(NMT)使用深度学习技术,特别是递归神经网络(RNN)、长短时记忆网络(LSTM)或Transformer结构,以端到端的方式进行翻译。它直接从源语言到目标语言的句子或序列进行映射,不需要复杂的特性工程或中间步骤。也是本文中重点讲解的技术。
基于神经网络的机器翻译(NMT)使用深度学习技术,特别是递归神经网络(RNN)、长短时记忆网络(LSTM)或Transformer结构,以端到端的方式进行翻译。它直接从源语言到目标语言的句子或序列进行映射,不需要复杂的特性工程或中间步骤。也是本文中重点讲解的技术。
1.2、编码器—解码器(seq2seq)
在自然语言处理的很多应用中,输入和输出都可以是不定长序列。以机器翻译为例,输入可以是一段不定长的英语文本序列,输出可以是一段不定长的法语文本序列。当输入和输出都是不定长序列时,我们可以使用编码器—解码器(encoder-decoder)。Encoder–Decoder是一种框架,许多算法中都有该种框架,在这个框架下可以使用不同的算法来解决不同的任务。
seq2seq模型属于encoder-decoder框架的范围,Seq2Seq 强调目的,不特指具体方法,满足输入序列,输出序列的目的,都可以统称为 Seq2Seq 模型。模型本质上用到了两个循环神经网络,分别叫做编码器和解码器。前者负责把序列编码成一个固定长度的向量,这个向量作为输入传给后者,输出可变长度的向量。
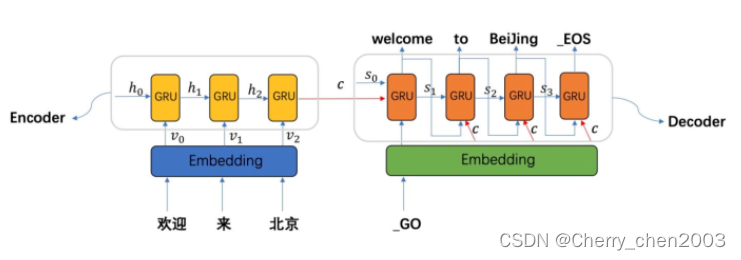
在Decoder中,每一时刻的输入为Encoder输出的c和Decoder前一时刻的输出,还有前一时刻预测的词向量
(如果是预测第一个词的话,此时输入的词向量为“_GO”的词向量,标志着解码的开始),用g函数表达解码器的隐藏层变换,即:
直到解码解出“_EOS”,标志着解码的结束。
1.2.1编码器
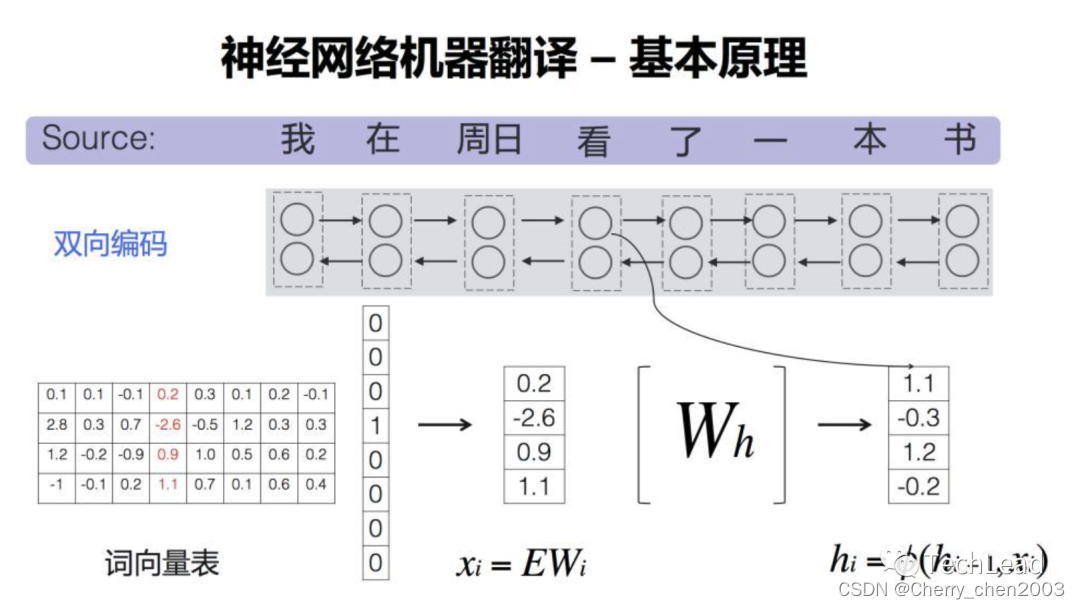
编码器的作用是把一个不定长的输入序列变换成一个定长的背景变量𝑐,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。
让我们考虑批量大小为1的时序数据样本。假设用表示转换成词向量的输入,例如
是输入句子中的第𝑖个词。在时间步𝑡,循环神经网络将输入
的特征向量
和上个时间步的隐藏状态
变换为当前时间步的隐藏状态
。我们可以用函数𝑓表达循环神经网络隐藏层的变换:
接下来,编码器通过自定义函数𝑞将各个时间步的隐藏状态变换为背景变量
例如,当选择时,背景变量是输入序列最终时间步的隐藏状态
。
就相当于从输入中提取出来大概意思,包含了输入的含义。
以上描述的编码器是一个单向的循环神经网络,每个时间步的隐藏状态只取决于该时间步及之前的输入子序列。我们也可以使用双向循环神经网络构造编码器。在这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的子序列(包括当前时间步的输入),并编码了整个序列的信息。
1.2.2解码器
刚刚已经介绍,编码器输出的背景变量𝑐编码了整个输入序列的信息。给定训练样本中的输出序列
,对每个时间步𝑡′(符号与输入序列或编码器的时间步𝑡有区别),解码器输出𝑦𝑡′的条件概率将基于之前的输出序列
和背景变量𝑐,即
。
为此,我们可以使用另一个循环神经网络作为解码器。在输出序列的时间步𝑡′,解码器将上一时间步的输出以及背景变量𝑐作为输入,并将它们与上一时间步的隐藏状态
变换为当前时间步的隐藏状态
。因此,我们可以用函数𝑔表达解码器隐藏层的变换:
有了解码器的隐藏状态后,我们可以使用自定义的输出层和softmax运算来计算,例如,基于当前时间步的解码器隐藏状态
、上一时间步的输出
以及背景变量𝑐来计算当前时间步输出
的概率分布。
直到解码解出“_EOS”,标志着解码的结束。
1.2.3训练模型
根据最大似然估计,我们可以最大化输出序列基于输入序列的条件概率
并得到该输出序列的损失
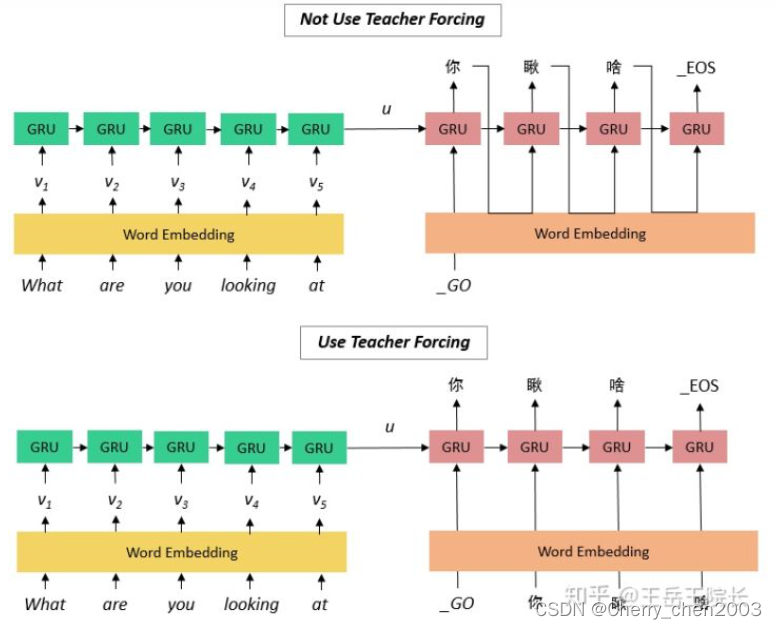
在模型训练中,所有输出序列损失的均值通常作为需要最小化的损失函数。在图10.8所描述的模型预测中,我们需要将解码器在上一个时间步的输出作为当前时间步的输入。与此不同,在训练中我们也可以将标签序列(训练集的真实输出序列)在上一个时间步的标签作为解码器在当前时间步的输入。这叫作强制教学(teacher forcing)。
1.3、注意力机制
深度学习中的注意力机制正是借鉴了人类视觉的注意力思维方式。一般来说,人类在观察外界环境时会迅速的扫描全景,然后根据大脑信号的处理快速的锁定重点关注的目标区域,最终形成注意力焦点。该机制可以帮助人类在有限的资源下,从大量无关背景区域中筛选出具有重要价值信息的目标区域,帮助人类更加高效的处理视觉信息。
在机器翻译中,注意力机制允许模型在解码时“关注”源句子中的不同部分。这使得翻译更加准确,尤其是对于长句子。下面将着重介绍基于Encoder-Decoder的注意力机制。
1.3.1基于Encoder-Decoder的注意力机制
人类视觉注意力机制,在处理信息时注意力的分布是不一样的。而 Encoder-Decoder 框架将输入X都编码转化为语义表示C,这样会导致所有输入的处理权重都一样,没有体现出注意力集中。因此,也可看成是“分心模型”。
为了能体现注意力机制,将语义表示C进行扩展,用不同的C来表示不同注意力的集中程度,每个C的权重不一样。扩展后的 Encoder-Decoder 框架变为:
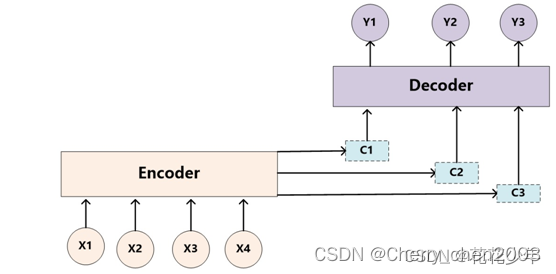
下面通过一个英文翻译成中文的例子说明“注意力机制”:
例如,输入的英文句子是:Tom chase Jerry,目标的翻译结果是:”汤姆追逐杰瑞”。那么在语言翻译中,Tom,chase,Jerry这三个词对翻译结果的影响程度是不同的。其中,Tom是主语,Jerry是宾语,是两个人名,chase是谓语,是动词,这三个词的影响程度大小顺序分别是Jerry>Tom>chase,例如(Tom,0.3),(chase,0.2),(Jerry,0.5)。不同的影响程度代表模型在翻译时分配给不同单词的注意力大小,即分配的概率大小。
生成目标句子单词的过程,计算形式如下:
其中,f1是 Decoder 的非线性变换函数。每个 C i C_iCi 对应不同单词的注意力分配概率分布,计算形式如:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









