



 本文介绍了数据库系统的基础概念,包括数据库的四个基本概念、数据管理技术的发展、数据模型的构成要素(如概念模型、逻辑模型和物理模型),重点阐述了关系模型、层次模型和网状模型的区别,以及SQL语言的特性与基本操作,如关系操作的选择、投影、连接等。此外,还讨论了数据库系统的三级模式结构和两层映像,以及数据库系统的组成和SQL的DDL和DML语句。
本文介绍了数据库系统的基础概念,包括数据库的四个基本概念、数据管理技术的发展、数据模型的构成要素(如概念模型、逻辑模型和物理模型),重点阐述了关系模型、层次模型和网状模型的区别,以及SQL语言的特性与基本操作,如关系操作的选择、投影、连接等。此外,还讨论了数据库系统的三级模式结构和两层映像,以及数据库系统的组成和SQL的DDL和DML语句。
第一章 绪论
重难点:
- 数据模型的三个组成要素
- 数据库系统的三级模式结构以及二级映像
1.1 数据库系统概述
1.1.1 数据库的 4 个基本概念
(1)数据(data):数据是数据库中存储的基本对象
(2)数据库(DataBase, DB):数据库是长期存储在计算机内、有组织的、可大量共享的数据的集合
- 数据按一定的数据模型组织、描述和储存
- 可为各种用户共享
- 冗余度小
- 数据独立性较高
- 易扩展
(3)数据库管理系统(DataBase Management System, DBMS):数据库管理系统是位于用户与操作系统之间的一层数据管理软件
- 用途:科学地组织和存储数据、高效的获取和维护数据
- 举例:Oracle、MySQL
- 主要功能:
- 数据定义
- 数据组织、存储、管理
- 数据操纵(增删改查)
- 数据库的事务管理和运行管理(安全性、完整性)
- 数据库的建立和维护
(4)数据库系统(DataBase System):数据库系统是由数据库、数据库管理系统、应用程序和数据库管理员组成的存储、管理、处理、维护数据的系统
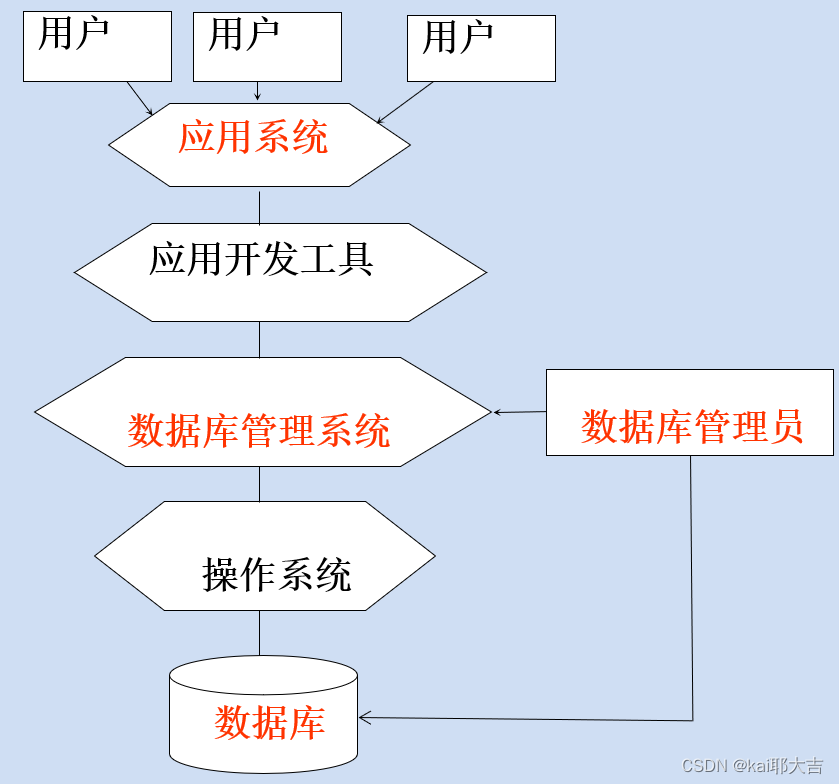
1.1.2 数据管理技术的产生和发展
(1)人工管理阶段(20世纪50年代中之前)
应用程序与数据之间的对应关系:
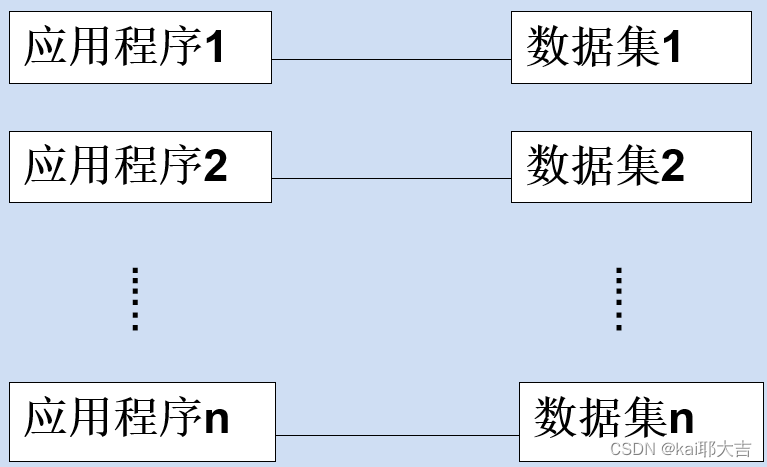
(2)文件系统阶段(20世纪50年代末-60年代中)
应用程序与数据之间的对应关系:
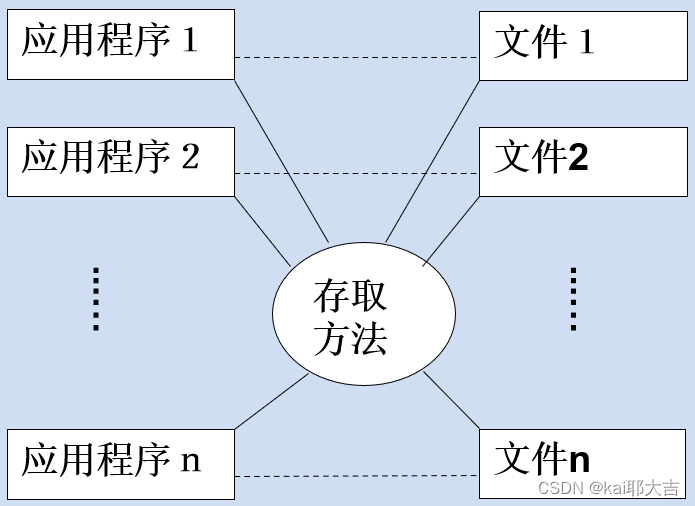
(3)数据库系统阶段(20世纪60年代末以来)
数据库系统
应用程序与数据之间的对应关系:
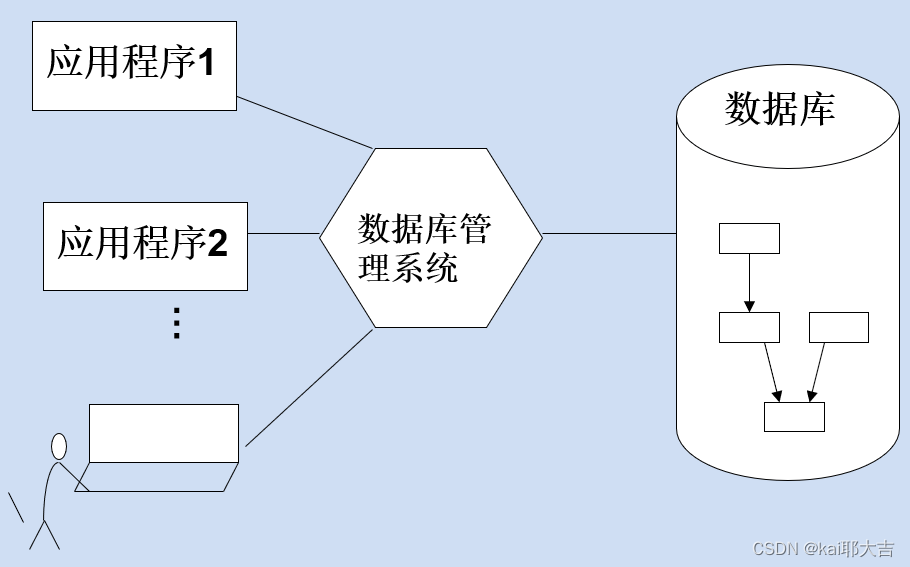
数据管理三个阶段的对比
| 人工管理阶段 | 文件系统阶段 | 数据库系统阶段 | |
|---|---|---|---|
| 数据的管理者 | 用户(程序员) | 文件系统 | 数据库管理系统 |
| 数据面向的对象 | 某一应用程序 | 某一应用 | 现实世界(一个部门、企业、组织) |
| 数据的共享程度 | 无共享,冗余度极大 | 共享性差,冗余度大 | 共享性高,冗余度小 |
| 数据的独立性 | 不独立,完全依赖于程序 | 独立性差 | 具有高度的物理独立性和一定的逻辑独立性 |
| 数据的结构化 | 无结构 | 记录内有结构、整体无结构 | 整体结构化,用数据模型描述 |
| 数据控制能力 | 应用程序自己控制 | 应用程序自己控制 | 由数据库管理系统提供数据安全性、完整性、并发控制和恢复能力 |
1.2 数据模型
(1)两类数据模型:
- 概念模型:用于信息世界的建模,是现实世界到信息世界的第一层抽象
- 实体(entity)
- 属性(attribute)
- 码(key)
- 实体型(entity type)
- 实体集(entity set)
- 联系(relationship)
实体之间的联系有一对一、一对多和多对多等多种类型
实体-联系方法:用 E-R 图来描述现实世界的概念模型
- 逻辑模型和物理模型
(2)数据模型的组成要素
- 数据结构
- 数据操作
- 数据的完整性约束条件
(3)常用的数据模型
- 层次模型
- 网状模型
- 关系模型
- 面向对象数据模型
- 对象关系数据模型
- 半结构化数据模型
基本层次联系: 是指两个记录以及他们之间的一对多(包括一对一)的联系。
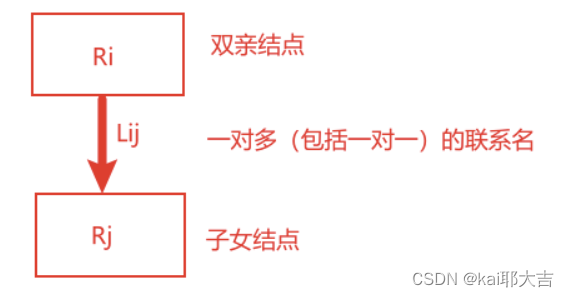
(4)层次模型
定义:
①有且只有一个结点没有双亲结点,这个结点称为根节点
②根以外的其他结点有且只有一个双亲结点
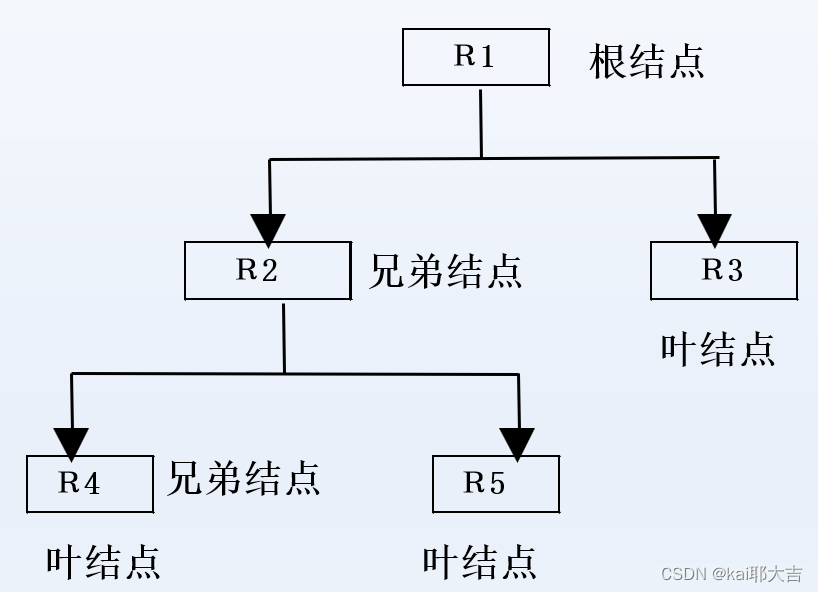
层次模型的数据操纵主要有增删改查,进行增删改的时候,要满足层次模型的完整性约束
- 进行插入操作时,如果没有对应的双亲结点值就i不能插入它的子女结点值
- 进行删除操作时,如果删除双亲结点值,则相应的子女结点值也将被同时删除
优点:
- 层次模型的数据结构比较简单清晰
- 查询效率高,性能优于关系模型,不低于网状模型
- 层次数据模型提供了良好的完整性支持
缺点:
- 结点之间的多对多表示不自然
- 对插入和删除操作的限制多,应用程序的编写比较复杂
- 查询子女结点必须通过和双亲结点
- 层次命令趋于程序化
(5)网状模型
定义:
①允许一个以上的结点无双亲
②一个结点可以有多于一个的双亲
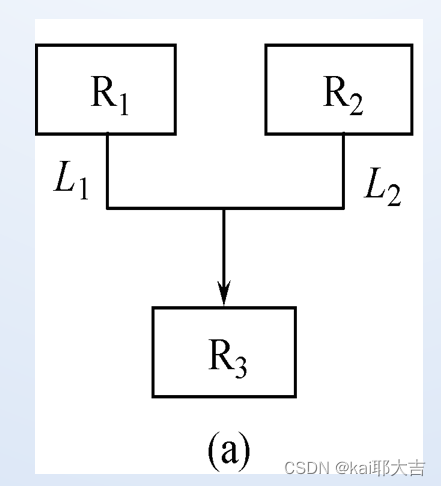
优点:
- 能够更为直接的描述现实世界,如一个结点可以有多个双亲
- 具有良好的性能,存取效率较高
缺点:
- 网状结构的复杂度(N平方),且随着应用环境扩大,数据库的结构就变得越来越复杂,不利于最终用户掌握
- DDL、DML语言复杂,用户不容易使用
- 记录之间联系是通过存取路径实现的,用户必须了解系统结构的细节,对应用程序不透明
(6)关系模型
①关系模型的数据结构:
- 关系(Relationship):一个关系对应一张表
- 元组(Tuple):表中的一行即为一个元组
- 属性(Attribute):表中的一列即为一个属性
- 主码(Key):表中的某个属性组,可以唯一确定一个元组
- 域(Domain):域是一组具有相同数据类型的值的集合
- 分量:元组中的一个属性值
- 关系模式:对关系的描述,例如 学生(学号,姓名,年龄,性别,年级),不允许表中还有表
关系的完整性约束条件:实体完整性,参照完整性,用户定义的完整性
优点:
- 建立在严格的数学概念的基础上
- 概念单一
- 实体和各类的联系都用关系来表示
- 对数据的检索也是关系
- 关系模型的存取路径对用户透明
- 具有更高的数据独立性,更好的安全保密性
- 简化了程序员的工作和数据库开发建立的工作
缺点:
- 存取路径对用户透明,查询效率往往不如格式化数据模型
- 为提高性能,必须对用户的查询请求进行优化,增加了开发数据库管理系统的难度
1.3 数据库系统模式的概念
(1)“型”和“值”的概念
- 型(type):对某一类数据的结构和属性的说明
- 值(value):是型的一个具体赋值
(2)数据库系统的三级模式结构
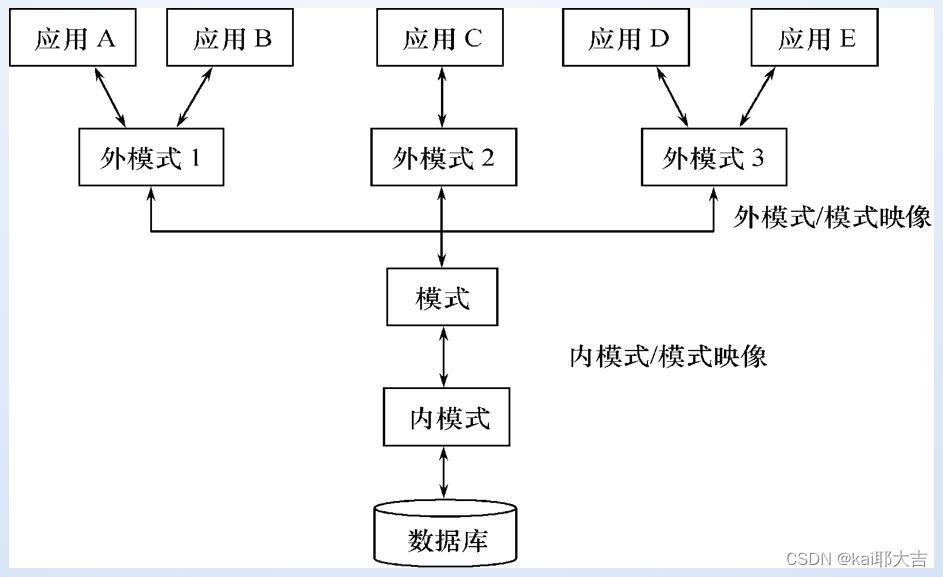
- 模式(schema):也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图,是数据库系统模式结构的中间层,一个数据库只有一个模式
- 外模式(external schema):也称子模式或用户模式,是数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述,外模式通常是模式的子集
- 内模式(internal schema):一个数据库只有一个内模式,是数据在数据库内部的组织方式
1.4 数据库系统两层映像系统结构
- 外模式/模式映像:描述的是数据的全局逻辑结构,外模式描述的是数据的局部逻辑结构。应用程序是依据数据的外模式编写的,从而应用程序不必修改,保证了数据与程序的逻辑独立性,简称数据的逻辑独立性。
- 模式/内模式映像:当数据库的存储结构改变时,由数据库管理员对模式/内模式的映像作相应改变,可以是模式保持不变,从而应用程序也不必改变。保证了数据与程序的物理独立性,简称数据的物理独立性
1.5 数据库系统的组成
- 硬件平台及数据库
- 足够大的内存
- 足够大的磁盘或磁盘阵列等设备
- 较高的通道能力,提高数据传送率
- 软件
- 数据库管理系统
- 支持数据库路管理系统运行的的操作系统
- 与数据库结构的高级语言及其编译系统
- 一数据库管理系统为核心的应用开发工具
- 为特定应用环境开发的数据库应用系统
- 人员
- 数据库管理人员
- 系统分析员和数据库设计人员
- 应用程序员
- 最终用户
第二章 关系数据库
重难点:
- 关系、关系模式和关系数据库的概念,选择、投影、来凝结等关系运算
- 关系模型中的三个组成要素
2.1 关系
关系模型中的逻辑结构就是一张二维表
(1)域(domain):一组具有相同数据类型的值的集合,即某一“列”的取值范围
(2)笛卡尔积(cartesian product):给定一组域D1, D2, …, Dn,允许其中某些域是相同的,即所有域的所有取值的一个组合
例如: 给出3个域:
D1=导师集合SUPERVISOR={张清玫,刘逸}
D2=专业集合SPECIALITY={计算机专业,信息专业}
D3=研究生集合POSTGRADUATE={李勇,刘晨,王敏}则 D1,D2,D3的笛卡尔积 D1 x D2 x D3 = {
(张清玫,计算机专业,李勇),(张清玫,计算机专业,刘晨),
(张清玫,计算机专业,王敏),(张清玫,信息专业,李勇),
(张清玫,信息专业,刘晨),(张清玫,信息专业,王敏),
(刘逸,计算机专业,李勇),(刘逸,计算机专业,刘晨),
(刘逸,计算机专业,王敏),(刘逸,信息专业,李勇),
(刘逸,信息专业,刘晨),(刘逸,信息专业,王敏) }
基数为 2 * 2 * 3 = 12
- 元组:笛卡尔积中的每一个元素(d1,d2,…,dn)叫做一个n元组
- 分量:笛卡尔积元素中的每一个值di叫做一个分量
笛卡尔积没有实际意义
- 候选码:若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码。(最简情况:候选码只包含一个属性)
- 全码:关系模式的所有属性组是这个关系模式的候选码
- 主码:若一个关系有多个候选码,则选定其中一个为主码
- 主属性:候选码的多个属性称为主属性,不包含在任何候选码中的属性称为非主属性
(3)三类关系
- 基本关系(基本表):实际存在的表,是实际存储数据的逻辑表示(分量必须是原子式,满足第一范式)
- 查询表:查询结果对应的表
- 视图表:由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据
(4)关系模式
eg: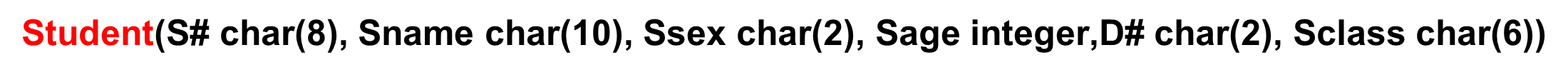
2.2 关系操作
(1)常用的关系操作
特点:集合操作方式,操作的对象和结果都是集合,一次一集合。
- 查询操作:选择、投影、连接、除、交、并、差、笛卡尔积
- 数据更新:插入、删除、修改
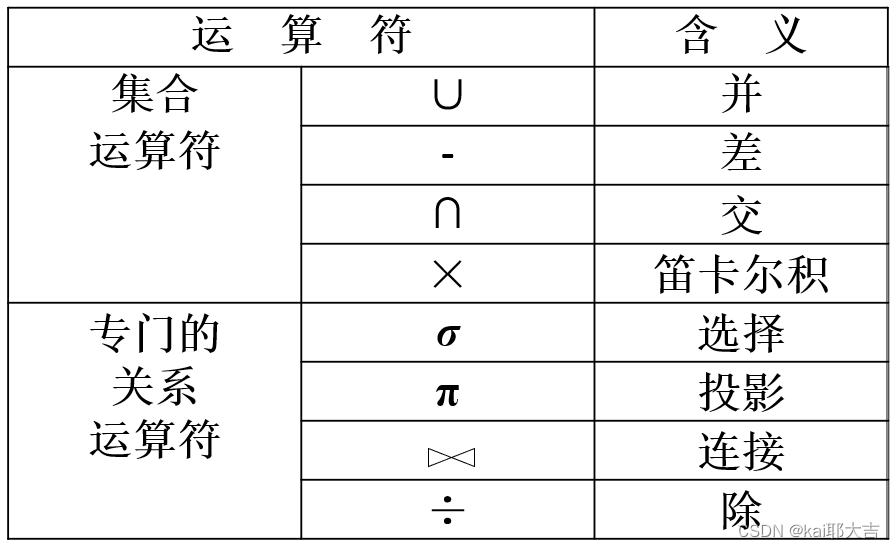
(2)关系代数
-
选择
eg:在Student表中查询信息系(IS)的全体学生
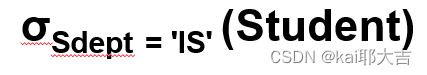
-
投影
eg:查询学生的姓名和所在系

-
连接
-
等值连接

-
自然连接 在结果中去除重复列

-
外连接:把悬浮元组也保存在关系结果中,在其他属性天上NULL,就叫外连接
-
左外连接:只保留左边关系R中的悬浮元组
-
右外连接:只保留右边关系S中的悬浮元组
-
-
除运算
第三章
重难点:
- SQL-DDL基本语句: CREATE DATABASE,CREATE TABLE
- SQL-DML基本语句:INSERT,DELETE,UPDATE,SELECT
(1)SQL的特点
- 综合统一
- 高度非过程化
- 面向集合的操作方式
- 使用一种语法结构提供多种使用方式(独立语言;嵌入式语言)
- 语言简洁,易学易用
| SQL功能 | 动词 |
|---|---|
| 数据定义DDL | CREATE(创建),DROP(撤销),ALTER(修改) |
| 数据操纵DML | INSERT(插入),UPDATE(更新),DELETE(删除),SELECT(选择) |
| 数据控制DCL | GRANT(授权),REVOKE(撤销) |
(2)数据定义
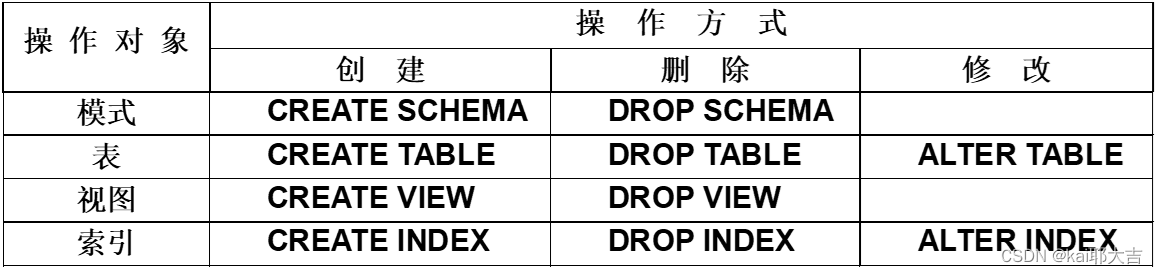
(3)索引的建立与删除
#为Student表按学号升序建立唯一索引
CREATE UNIQUE INDEX SCNO ON Student(Sno);
#修改索引名
ALTER INDEDX SCNO RENAME TO SCSNO;
#删除索引
DROP INDEX SCSNO;
3.1 数据查询
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
(1)单表查询
#查询全体学生的姓名、出生年份和所在院系
SELECT Sname,Birth,LOWER(Sdept);
#列别名
SELECT Sname,Birth,LOWER(Sdept) DEPARTMENT;
去除重复记录:DISTINCT 关键字
| 查询条件 | 谓词 |
|---|---|
| 比较 | =,<=>(判断NULL=),>,<, >=,<=,!=,<>,!>,!<;NOT+上述比较运算符 |
| 确定范围 | BETWEEN AND, NOT BETWEEN AND |
| 确定集合 | IN NOT IN |
| 字符匹配 | LIKE, NOT LIKE |
| 空值 | IS NULL, IS NOT NULL |
| 多重条件(逻辑条件) | AND, &&, OR, ||, NOT, !, XOR |
#查询所有年龄在20岁以下的学生姓名及其年龄
SELECT Sname,Sage
FROM Student
WHERE Sage<20;
#查询年龄在20~30岁之间的学生姓名
SELECT Sname
FROM Student
WHERE Sage BETWEEN 20 AND 30;
#查询计算机科学系、数学系和信息系学生的姓名和性别
SELECT Sname,Ssex
FROM Student
WHRER Sdept IN('CS','MA','IS');
#检索所有姓张的学生学号及姓名
SELECT S#,Sname
FROM Student
WHERE Sname LIKE '张%';
#查询所有有成绩的学生的学号和课程号
SELECT Sno,Cno
FROM SC
WHERE Grade IS NOT NULL;
#查询计算机系年龄在20岁以下的学生姓名
SELECT Sname
FROM SC
WHERE Sdept='CS' AND Sage<20;
ORDER BY子句(ASC 升序, DESC 降序; 缺省值为升序)
#查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排列
SELECT Sno,Grade
FROM SC
WHERE Cno='3'
ORDER BY Grade DESC;
聚集函数
聚集函数只能出现在select子句和group by子句的having子句中,不能用在where子句中
- COUNT(*)
- SUM()
- AVG()
- MAX()
- MIN()
#查询学生总人数
SELECT COUNT(*)
FROM Student;
#查询选修了课程的学生人数
SELECT COUNT(DISTINCT Sno)
FROM SC;
#计算1好课程的学生平均成绩
SELECT AVG(Grade)
FROM SC
WHERE Cno='1';
SELECT * FROM SC LIMIT 5,10; #检索记录行6-15
GROUP BY子句
#求各个课程号及相应的选课人数
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;
(2)连接查询
- 等值连接
#按“001”号课成绩由高到低顺序显示所有学生姓名(二表连接)
SELECT Sname FROM Student,SC
WHERE Student.SCourse=SC.SCourse AND SC.SCourse='001'
ORDER BY Sgrade DESC;
- 自然连接
自然连接会去除重复列
#查询每个学生及其选修课程的情况
SELECT Student.*,SC.*
FROM Student,SC
WHERE Student.Sno=SC.Sno;
#用自然连接替代
SELECT * FROM Student NATURAL JOIN SC
WHERE Student.Sno=SC.Sno;
- 自身连接:一个表与其自己连接,表中两个属性重名,需要使用别名区分
#求年龄有差异的任意两位同学的姓名
SELECT S1.Sname AS STU1,S2.Sname AS STU2
FROM Student1 S1,Student S2
WHERE S1.Sage > S2.Sahe;
#求既学过“001”号课程又学过“002”号课程的所有学生的学号
SELECT S1.Sno
FROM SC S1,SC S2
WHERE S1.Sno=S2.Sno AND S1.Cno="001" AND S2.Cno="002";
- 外连接
- 连接中使用
natural- 出现在结果关系中的两个连接关系的元组在公共属性上取值相等,且公共属性只出现一次
- 连接中使用
on连接条件- 出现在结果关系中的两个连接关系的元组取值满足连接条件,且公共属性出现两次
- 左外连接(left outer join 表名 on)
- 右外连接(right outer join 表名 on)
#查询每个学生及其选修课程的情况(左外连接)
SELECT *
FROM Student LEFT OUTER JOIN SC
ON Student.Sno=SC.Sno;
- 多表连接
必须有等值连接条件,否则结果为笛卡尔积
#查询每个学生的学号、姓名、选修的课程名及成绩
SELECT Student.Sno,Sname,Cname,Grade
FROM Student,SC,Course
WHERE Student.Sno=SC.Sno AND SC.Cno=Course.Cno;
(3)嵌套查询
- 不相关子查询:子查询的查询条件不依赖于父查询
- 相关子查询:子查询的查询条件依赖于父查询
- max聚集函数查的是最大值,并不是最大值对应的记录(因为符合max的可能有多行,也并不是其中一行)
- 聚集函数仅用于 select 和 having,不用于 where子句
- 带有
IN的子查询
##########非相关子查询##############
#列出张三、王三同学的所有信息
SELECT * FROM Student
WHERE Sname IN ('张三','王三');
#列出选修了“001”号课程的学生的学号和姓名
SELECT Sno,Sname
FROM Student
WHERE Sno IN (
SELECT Sno
FROM SC
WHERE Cno='001'
);
#查询与“刘晨”在同一个系学习的学生
①确定“刘晨”所在系名
SELECT Sdept
FROM Student
WHERE Sname='刘晨';
(查询结果为 CS)
②查找所有在CS系的学生
SELECT *
FROM Student
WHERE Sdept='CS';
③讲第一步查询嵌入到第二步查询的条件中
SELECT *
FROM Student
WHERE Sdept IN (
SELECT Sdept
FROM Student
WHERE Sname='刘晨'
);
############相关子查询###############
#求学过001号课程的同学的姓名
SELECT Sname
FROM Student Stud
WHERE Sno IN(
SELECT Sno
FROM SC
WHERE Sno=Stud.Sno AND Cno='001'
);
- 带有比较运算符的子查询
当能确切知道内层查询返回单值时,可用比较运算符
#由于一个学生只可能在一个系学习,则可以用 = 代替 IN
SELECT *
FROM Student
WHERE Sdept = (
SELECT Sdept
FROM Student
WHERE Sname='刘晨'
);
#找出每个学生超过他选修课程平均成绩的课程号
SELECT Sno,Cno
FROM SC x
WHERE Grade>=(
SELECT AVG(Grade)
FROM SC y
WHERE y.Sno=x.Sno
);
----------------------------------------------------------------------------------持续更新-----------------------------------------------------------------------------------

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









