




面向有效层共享的保证可交换性的Docker镜像重构
目录
ABSTRACT
docker images构成:应用程序 + 依赖文件,支持灵活部署和迁移(advantage)。
- 问题:
1.容器的快速发展导致上百万的容器镜像被生成及存储;
2.非本地的镜像需要从registry中拉取,导致大量网络流量。
- 解决:
CAS(Content Addressable Storage)内容可寻址存储。 通过允许不同的镜像之间共享相同的层来节省网络和存储开销。但CAS对于Docker镜像并不是百分百完美,因为在实践中,不同镜像之间很少存在完全相同的层。
- 提出
本文企图通过重构Docker镜像来增加完全相同层的数量从而节省存储和网络开销。
1.定义了“文件可交换性”来保证交换后的image仍然有效;
2.提出这个重构过程是一个整数非线性规划问题;
3.受到层相似性的启发,设计一个相似度感知的在线镜像重构算法.
1 INTRODUCTION
container与虚拟机相比:
1. 更加轻量级。通过共享操作系统内核来产生更小开销;
2. 使开发人员可以更多的关注应用逻辑,而无需担心底层基础设施。
- 问题:存储和网络开销
1.镜像数量飞速增长。如Docker Hub如今(截至2022年)存储了2百万共有镜像 + 400百万私有镜像,占据近1PB存储空间;
2.互联网移动设备的普遍使用加剧了服务的移动性和动态性。如Google平均每秒启动7000个容器来支持不断变化的请求,这种频繁的业务部署和迁移也会给存储和网络带来巨大压力。
- 应运而生:CAS
CAS(内容可寻址存储)通过在同一客户端上存储的不同镜像之间共享相同的层来缓解网络和存储开销。但据统计,CAS只节省了38%的存储开销,仍有35%是冗余的。主要原因:很少存在完全相同的层(1%)但存在很多相似的层。因此层共享技术仍然有待开发。
- 设想
在registry中,基于层共享在文件粒度上删除重复文件,只保留独有文件。存在问题:Docker镜像中的“recipe”文件记录了每一层的文件,在客户端请求时会根据recipe来构建镜像并传送给client,因此这种方式只节省了registry的空间,并不能节省网络开销和客户端的存储空间。
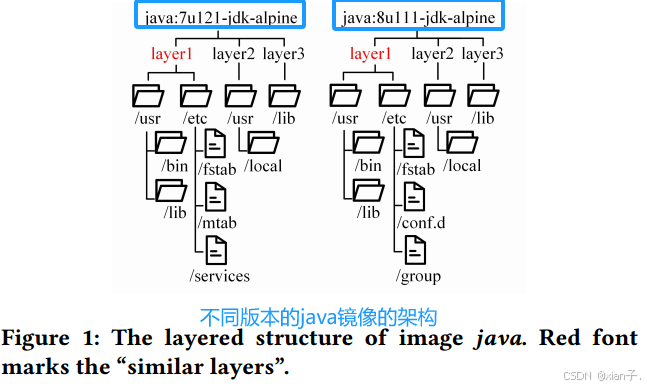
很少存在完全相同的层但存在很多相似的层:如上图所示,两个版本的镜像的layer1完全相同可以共享,实际上layer2和layer3仍然有很多文件是相同(复制)的,极少数是特殊独有的。统计了2200个镜像间的相似度发现:26042对层之间有近80%的相似度(80%的文件相同)!此外,同一repository中镜像相似度 > 不同repository。
registry与repository:
· registry就是像Docker Hub这样存放大量镜像的地方;
· repository就像是集装箱,将这些镜像进一步分类,拥有同一类型但tag版本不同的镜像就会被存放在同一repository中。
- 本文提出
企图通过重组各层文件来最大化相同层的数量,因此需要考虑如下问题:
(1) 重构后的镜像有多少层?
(2) 如何判断一个文件应该属于哪一层?
(3) 各层的顺序是什么?
同时,首先应该保证重构后的镜像是有效的(Docker的union mount机制将各层文件挂载到同一文件系统中,且只提供一个文件系统视图给容器,因此改变文件所属层的位置会影响最后的合并结果,这就容易导致重构后的镜像无效),因此,决定是否可以改变文件所属层的位置是至关重要的(这在之前的研究中未得到解决)。
其次,重构镜像应权衡存储开销和操作开销。一个直观的想法是一层一个文件,显然不切实际(一个image有成千上万个文件,20%的image有超过一万个文件),一层一文件会导致层深过深(本文研究表明,层深与操作延迟呈正相关,因此层深过深不利于容器操作)以及源数据过大。
- 解决方案
为了解决如上问题
(1) 首先弄清楚了image的层结构,提出了可交换性来保证文件的正确顺序以及镜像的有效性;
(2) 通过数据拟合方法提出了一个数学表达式揭示了层深与操作延时的关系;
(3) 将镜像重构操作建模为整数非线性规划(INLP)问题,旨在降低存储开销和操作开销;
(4) 为减小镜像庞大的元数据,提出一种相似性感知的在线镜像重构算法(SOIRA),来解决这个INLP问题。
SOIRA重新排列已提交的层来使其与目标层相同,前文提到同一repository中的镜像间相似度更高,因此SOIRA从repository中选取目标而非从整个registry,以此大大降低了算法执行时间。
本文选取了一系列Docker镜像进行测试,其中包含1413629个唯一文件,近60GB。与目前(2022年)最先进的技术相比,SOIRA只需要多几层就可以节省近10%的存储空间;另外,20个客户端每个拉取20个镜像,可以减少近9.3%的流量。综上表明,Docker镜像重构在存储空间和网络流量的节省上拥有巨大发展空间。
- 主要贡献
(1) 通过评估CAS有效性和文件冗余性,明确了镜像层共享的优化空间,是第一个量化层间相似性的;
(2) 首个定义可交换性来保证重构后镜像的有效性;
(3) 将重构过程建模为INLP(整数非线性规划问题)。通过研究层间相似性,提出了SOIRA算法降低镜像庞大的元数据;
(4) 对Docker Hub中的镜像进行了广泛评估,验证分析了具有1413629唯一文件以验证模型和算法的有效性。
2 BACKGROUND
2.1 Docker Overview
- Repository and registry
Repository被视为是同一类型镜像不同版本的集合。例如,“java:7u121jdk-alpine”和“java:8u111-jdk-alpine”都属于repository“java”。Registry 是一个用于存储和交付Docker镜像的系统,它存储了Repository中镜像的层以及元数据(eg. manifest.json)。
- Image delivery
镜像交付常用命令:pull和push。Docker在每个host上面运行了一个本地守护进程(local daemon),当遇到“pull”命令时,Docker local daemon就从registry中拉取镜像的manifest.json(记录了配置信息configuration和层信息list of layers),各层由digest(采用SHA-256算法对内容进行哈希结果命名给层名称)标识及引用,Docker daemon正是通过检查层的digest来判断本地是否有相同的层,然后只下载未存储在本地的层。同时,CAS允许在同一host上的不同images之间共享相同的层。
“push”触发daemon上传最新的镜像和manifest到registry中。
- Image building
有两种方式创建并发布image到registry中:(1) dockerfile;(2) Docker commit。
(1)dockerfile是通过文件命令(类似shell脚本)方式创建docker镜像,其中每个命令创建一层;
(2) Docker commit是将正在运行的容器连同其环境打包成镜像的命令。
相同的库和包可以被不同的镜像引用,但由于开发人员独立的创建和发布他们的镜像,这些镜像可能会调用具有不同方法和指令的库,这就会导致产生高度相似的层。
2.2 Docker Storage Driver
Docker image的层结构就是由Docker存储驱动创建,最常用的是overlay,基于了overlayFS联合文件系统(overlayFS在linux3.18之后也被写入了linux内核)。如下图所示overlayFS的挂载机制:
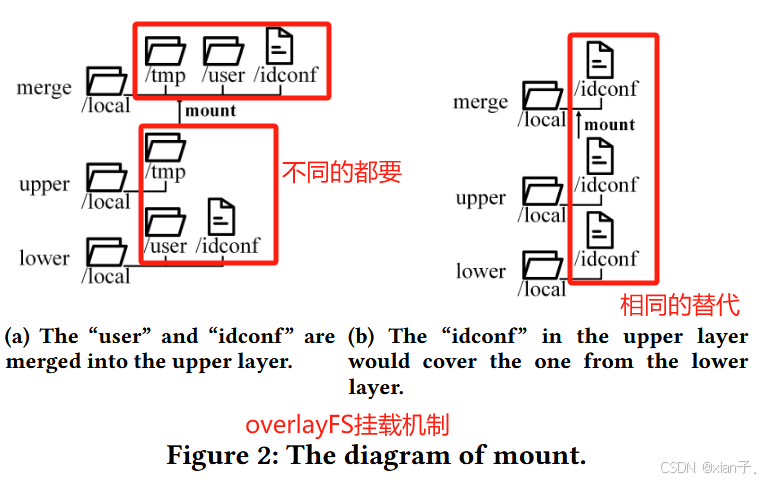
注意图2(b),不管这两个idconf文件中的内容是否相同,只要他们路径和文件名相同都会上层覆盖下层。
overlay还有另外一个技术:Copy on Write(COW,写时复制)。如下图所示:
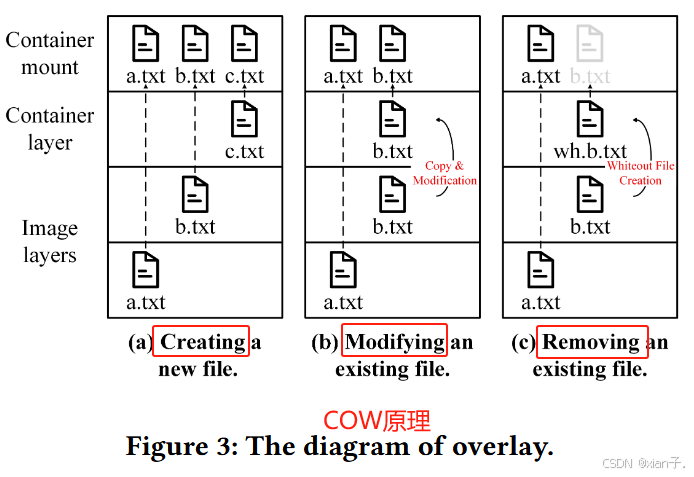
镜像层只读,容器层可读可写,所有的操作都发生在容器层而不会改变镜像层中文件的内容。
3 IMAGE ANALYSIS
settings:服务端配置:8核cpu,2.5GHz,11G主存RAM,从Docker Hub中拉取了130个常用reposi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









