




 本文介绍了如何在分布式环境下实现高性能的连接查询优化算法,包括数据导入Mysql数据库、测试数据处理、查重和数据结构设计,重点是针对特定规模的数据集进行功能性和非功能性要求的实现。
本文介绍了如何在分布式环境下实现高性能的连接查询优化算法,包括数据导入Mysql数据库、测试数据处理、查重和数据结构设计,重点是针对特定规模的数据集进行功能性和非功能性要求的实现。
一、实现要求
- 整体要求
基于指定的数据规模、数据集,实现一种分布式数据库领域的高性能连接查询优化算法,完成要求的性能测试,并进行效果演示。
- 功能性要求
1、在单台机器上启动参赛者程序,共启动4个实例。
2、4个实例各自加载50万零件数据和大约1500万行订单数据到内存中(每个实例加载不同的部分,记录加载时间)。
3、程序可以指定有效的零件品牌参数,非法的零件品牌报错。对于有效的零件品牌参数,完成如下要求的功能并计算时间:
(1)计算每个零件的销售总量、所有零件的销售总量并得出零件平均销售量;
(2)对于满足用户指定的零件品牌的零件,如果该零件销售总量小于(1)中的平均销售量的30%,则认定为非畅销零件。
注意:零件品牌的格式为Brand#MN,其中M、N都是在1-5中任意选择,如Brand#12。
(3)计算并输出该品牌的所有非畅销零件的销售总额。
- 非功能性要求
实例间通过IP+端口方式进行通信(模拟多个节点),不得采用共享内存方式进行通信。
- 演示要求
1、 启动4个实例后,在任意一个实例的控制台界面输入load表示开始加载数据,然后在各控制台界面显示各实例自己加载的2个表的各自的数据量和数据加载的时间;
2、 然后输入select,表示开始执行查询,Brand#MN总共有25种情况,程序自动依次从Brand#11开始到Brand#55结束,显示这25种情况下的查询结果和消耗的查询时间,最后显示出总的执行时间。
二、测试数据
测试数据生成下载地址
运行如下命令生成比例因子为10的part表和lineitem表的文本测试数据:
.\dbgen.exe -s 10 -T P
.\dbgen.exe -s 10 -T L
上述命令生成part.tbl和lineitem.tbl这两个文本文件,文本文件总大小约为8G左右,其中part.tbl包括200万行零件数据,lineitem.tbl包含接近6000万条订单数据。
注意:dists.dss需要和dbgen.exe在相同目录下
在linux操作系统中,dbgen.exe无法运行且没找到合适解决办法,因此在windows操作系统中生成测试数据,拷贝到linux系统中使用。
cd /dbgen
vim makefile.suite
生成后如下:
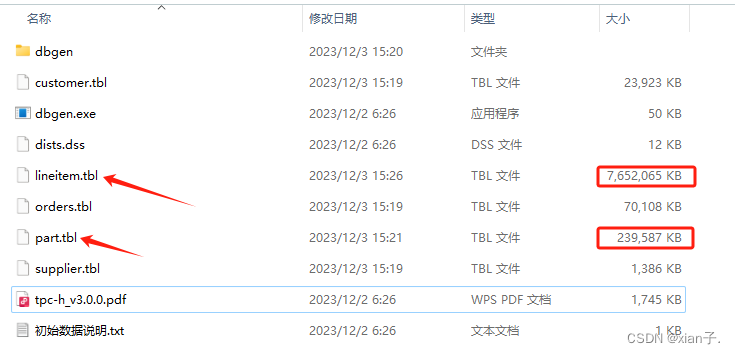
其中,只有箭头指向的两个文件才是我们所需要的。
- part表(零件数据):
P_PARTKEY:零件号,唯一,整数类型
P_NAME:零件名称,唯一,字符串长度不超过55字节
P_MFGR:制造商名称,字符串长度不超过25字节
P_BRAND:零件品牌,字符串长度不超过10字节
P_TYPE:零件类型, 字符串长度不超过25字节
P_SIZE:零件尺寸,整数
P_CONTAINER:容器名称,字符串长度不超过10字节
P_RETAILPRICE:零件价格,浮点数
P_COMMENT:备注,字符串长度不超过23字节
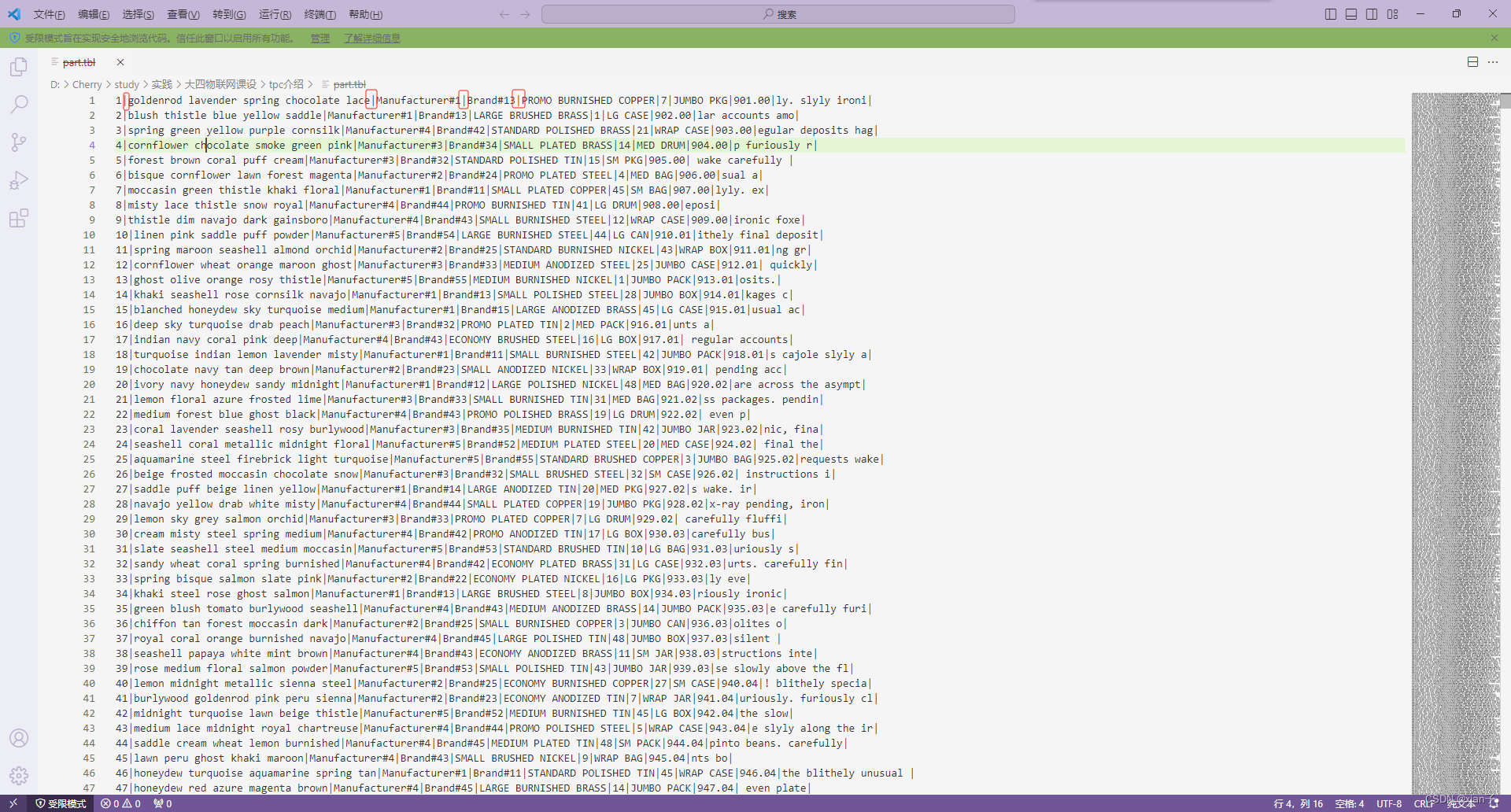
其中的每一列数据用 | 符号隔开
- lineitem表
L_ORDERKEY:订单号,整数
L_PARTKEY:零件号,整数,引用part表d的P_PARTKEY
L_SUPPKEY:供应商号,整数
L_LINENUMBER:订单细目号,整数
L_QUANTITY:零件数量,整数
L_EXTENDEDPRICE:零件价格,浮点数
L_DISCOUNT:零件折扣,浮点数,本课题不考虑折扣
L_TAX:税率,浮点数,本课题不考虑税
L_RETURNFLAG:订单退回标志,字符串,1字节
L_LINESTATUS:订单状态,字符串,1字节
L_SHIPDATE:发货日期,日期类型
L_COMMITDATE:提交日期,日期类型
L_RECEIPTDATE:接收日期,日期类型
L_SHIPINSTRUCT:发货指令,字符串不超过25字节
L_SHIPMODE:发货方式,字符串不超过10字节
L_COMMENT:备注,字符串不超过44字节
三、两个.tbl测试文件导入Mysql数据库
- 开启mysql服务:
sudo service mysql start
- 登陆mysql:
mysql -u root -p #然后根据提示输入用户密码
- 创建数据库
create database tpch; #tpch是数据库的名字
查看创建成功没(查看所有建立的数据库):
show databases;
进入创建的这个数据库:
use tpch;
- 创建表
part表的建表语句:
CREATE TABLE part ( P_PARTKEY INTEGER NOT NULL,
P_NAME VARCHAR(55) NOT NULL,
P_MFGR CHAR(25) NOT NULL,
P_BRAND CHAR(10) NOT NULL,
P_TYPE VARCHAR(25) NOT NULL,
P_SIZE INTEGER NOT NULL,
P_CONTAINER CHAR(10) NOT NULL,
P_RETAILPRICE DECIMAL(15,2) NOT NULL,
P_COMMENT VARCHAR(23) NOT NULL );
lineitem表的建表语句:
CREATE TABLE lineitem ( L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL);
检查一下创建成功没有:
show tables;
- 将本地文件导入mysql
查看文件路径(part.tbl和lineitem.tbl):
pwd
根据上述指令的结果,执行导入数据库命令,其中的文件路径就是刚刚的两个表的绝对路径:
load data local infile '/home/cherry/IOT-finall-work/part.tbl' into table part fields terminated by '|' lines terminated by '|\n';
会发现报错:

- 解决:
查看是否开启加载本地文件
show variables like 'local_infile';
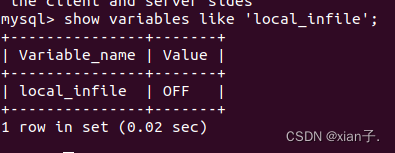
看到果然是off,再开启全局本地文件设置:
set global local_infile=on;
再查看已经打开了。
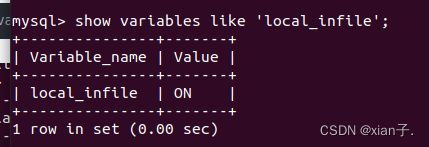
再执行一遍load指令,如果发现还是解决不了,出现新问题(在为on的前提下):
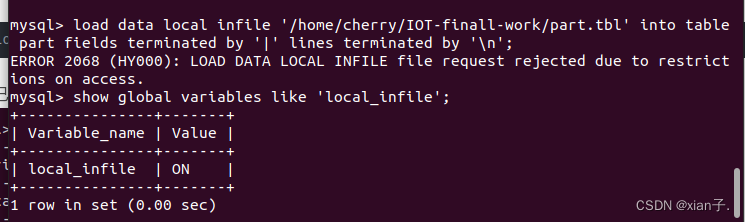
则exit退出mysql,通过如下命令重新登录:
mysql -u root -p --local-infile
然后选择tpch数据库,再执行一遍load指令,发现导入成功(200万行),花费时间是15.21秒:
同样方法导入lineitem表:
在执行过程中,出现了根目录已满的情况,于是百度扩展根目录,发现自己的磁盘空间未分配的与根目录空间不连续,因此无法扩展。没办法删除ubuntu废了九牛二胡之力重新下载,给根目录分配了70G的空间,在回来执行一遍以上命令。
并且回来执行的时候,发现改load part表时
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6297
6297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









