



 本文介绍了一个Python爬虫项目,旨在从豆瓣读书Top250页面抓取书籍名称和链接。通过定制请求头和利用requests库,实现了翻页功能并使用BeautifulSoup解析HTML,最终成功提取所有书籍信息。
本文介绍了一个Python爬虫项目,旨在从豆瓣读书Top250页面抓取书籍名称和链接。通过定制请求头和利用requests库,实现了翻页功能并使用BeautifulSoup解析HTML,最终成功提取所有书籍信息。
Requests爬虫实践:豆瓣读书Top250数据
本次的实践项目是爬取豆瓣读书Top250的书籍名称和网页地址
参考书籍:《Python网络爬虫从入门到实践》
书中爬的是电影数据,自己想爬个书籍数据看看,差别也不是很大了
首先找到了豆瓣读书Top250的网页地址:https://book.douban.com/top250
然后需要为其定制请求头Headers,如果请求头没有指定或者和实际网页不一致,就无法返回正确的结果。
定制请求头
使用Chrome浏览器的“检查”命令查看网页请求头,如下图所示
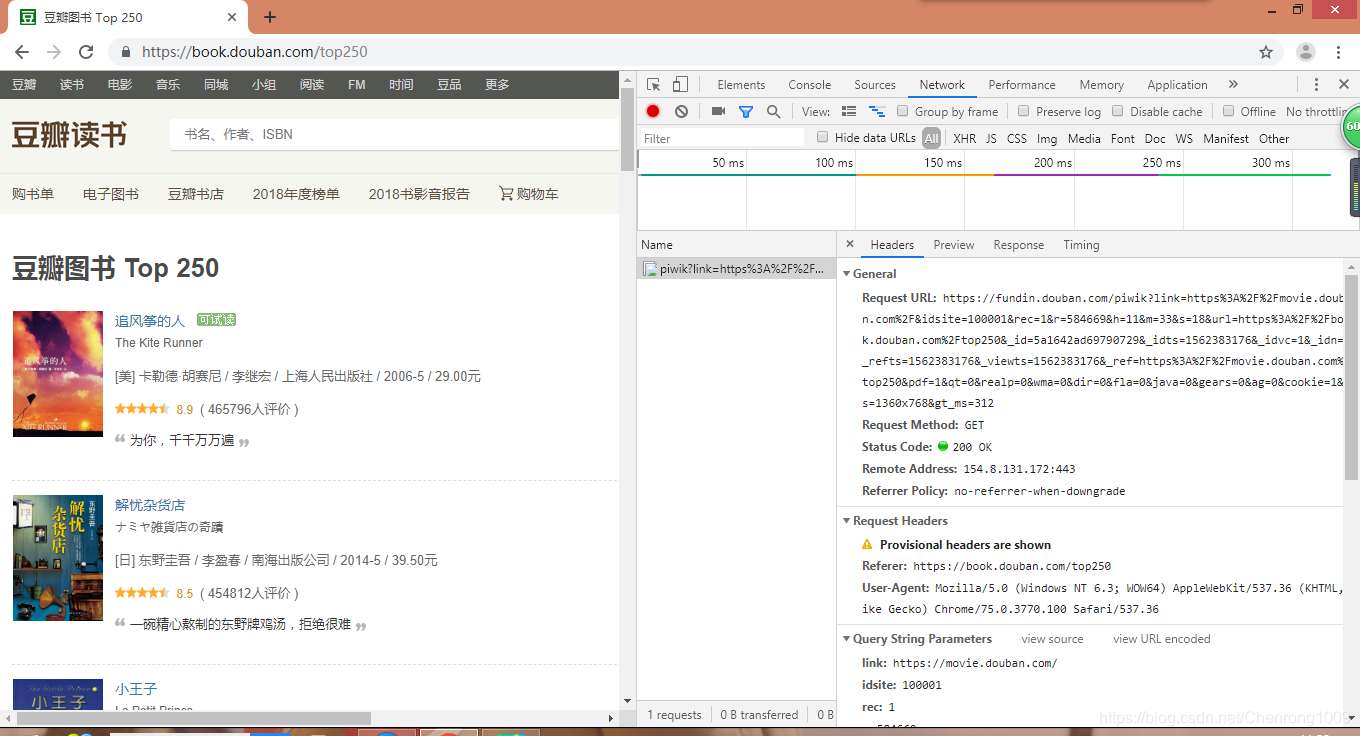
提取请求头代码如下:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Host': 'book.douban.com'
}
第一页只有25项内容,因此需要获取10页的书籍,点击第二页时,网页地址变成了:https://book.douban.com/top250?start=25
第三页的地址为:
https://book.douban.com/top250?start=50
因此需要设置相应的start参数来获取
提取内容
可以将提取操作封装到函数中,代码如下:
def get_TopBooks():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Host': 'book.douban.com'
}
for i in range(0,10):
link = 'https://book.douban.com/top250?start='+str(i*25)
r = requests.get(link,headers = headers,timeout = 10)
print(str(i+1),"页响应状态码:",r.status_code)
print(r.text)
get_TopBooks()
运行结果显示为网页的源代码,使用BeautifulSoup解析内容提取书籍名称
内容解析
创建一个book_list列表,存取书籍名称,将上述代码修改如下:
def get_TopBooks():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Host': 'book.douban.com'
}
book_list = []
for i in range(0,10):
link = 'https://book.douban.com/top250?start='+str(i*25)
r = requests.get(link,headers = headers,timeout = 10)
print(str(i+1),"页响应状态码:",r.status_code)
soup = BeautifulSoup(r.text,"html.parser")
div_list = soup.find_all('div',class_='pl2')
for each in div_list:
book = each.a.get("title")
book_list.append(book)
return book_list
books = get_TopBooks()
print(books)
由于书籍标题的标签长这样:
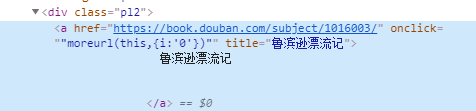
所以通过下面的这段代码来获取到书籍的标题:
div_list = soup.find_all('div',class_='pl2')
for each in div_list:
book = each.a.get("title")
book_list.append(book)
得到的结果如下:
 可以把最终得到的结果保存成文件便于下次的查看,由于是实现一个demo,就先让它控制台输出吧。
可以把最终得到的结果保存成文件便于下次的查看,由于是实现一个demo,就先让它控制台输出吧。

















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









