




 本文介绍了数据预处理和划分过程,详细阐述了Bagging(自助法)、Voting(投票法)、Stacking(堆叠模型)和Boosting(尤其是AdaBoost)的理论与应用,包括模型建立、特征重要性和训练结果。
本文介绍了数据预处理和划分过程,详细阐述了Bagging(自助法)、Voting(投票法)、Stacking(堆叠模型)和Boosting(尤其是AdaBoost)的理论与应用,包括模型建立、特征重要性和训练结果。
数据预处理
导入数据
数据划分
将data的数据最后一行之前的数据划分未特征,最后一行的数据划分为y,以y数据作为标签进行分类,将训练集测试集八二分

1 Bagging
理论
在Bagging种,利用boostrap方法(自助法)从整体数据集种采取有放回抽样得到N个数据集学习 出一个模型。最后的结果是由N个模型输出得到。分类问题采取N个模型预测投票的形式,回归问题采取N个模型预测平均的方式。
导入库

模型建立
Bagging一次只能使用一个基础学习器,但是可以将一个基础学习器使用多次。
bootstrap是说样本是否有放回,bootstrap_features是说特征是否放回

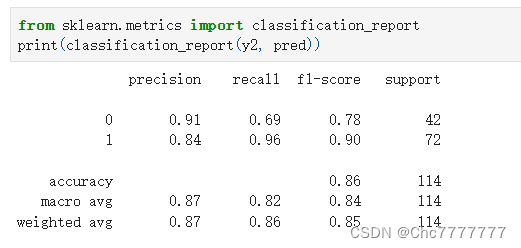
打印报告
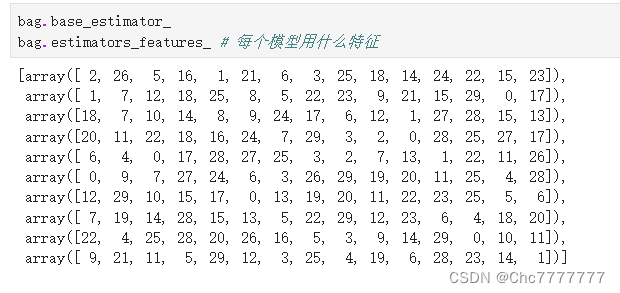
查看模型用的学习器以及查看模型用了什么特征
2 Voting(基学习器一般不同 投票法)
理论
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。
导入库
![]()
导入模型
Voting又称投票学习器, 分为硬投票和软投票
Voting的模型器可以选择多种,如果是硬投票,会把每个模型预测的值进行加法如何选出最好的值,选取基模型的分类结果。
如果是软投票,就要设置权重,将软投票权重最大值给投选处理,输出的预测结果是基模型的分类概率。

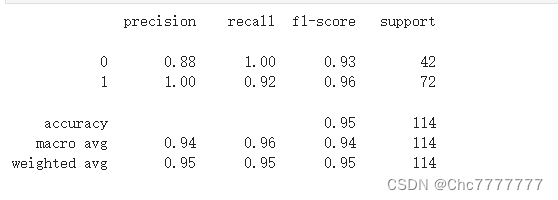
模型报告
模型特征重要性

3 Stacking (堆叠模型)
理论
Stacking是说训练一个模型用于组合其他各个模型。首先我们训练多个不同模型,然后把多个模型的输出结果作为输入来训练一个模型,以得到结果。
导入包
![]()
学习器列表
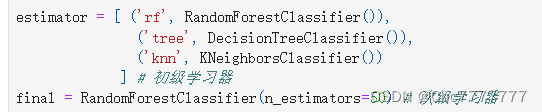
导入模型
Stacking类型神经网络,初级学习器就相当于神经网络的隐藏层,数据经过初级学习器之后到达次级学习器,类似于神经网络的wx+b 经过加权权重来对数据进行处理。这里初级学习器也可以学选择多种,cv=5,是交叉验证,这里我们可以自己定义cv等于多少,stack_method的堆叠方法有三种,![]()

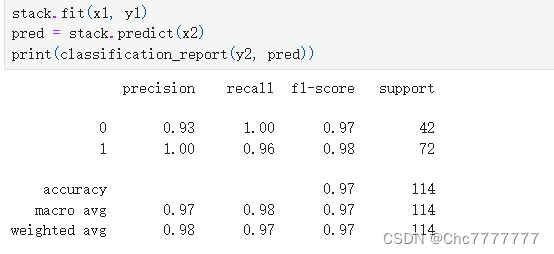
模型训练及结果
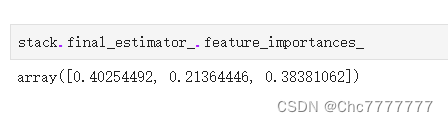
特征重要性
4 Boosting(集成算法)
理论
Boosting是一种可以用来减小监督学习中偏差的机器学习算法,同时也是学习一系列弱分类器,并将其组合为一个强分类器。
下面我们介绍第一种AdaBoost
理论 刚开始训练对每个训练赋予相同权重,利用算法训练n轮,每次训练后,对训练失败的样本赋予较大权重,让学习算法在每次学习中更注意学错的样本,从而得到多个预测函数
导入包
![]()
建立模型
Boosting的默认学习器是决策树,我们可以修改为基础学习器
可以设置模型数量来进行训练,这里有两个优化算法 ![]()

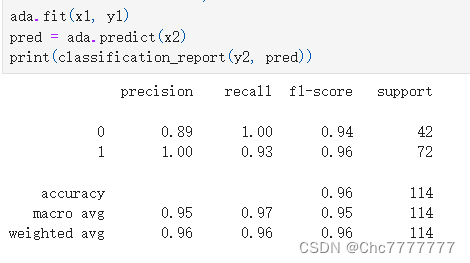
模型训练及结果

















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









