



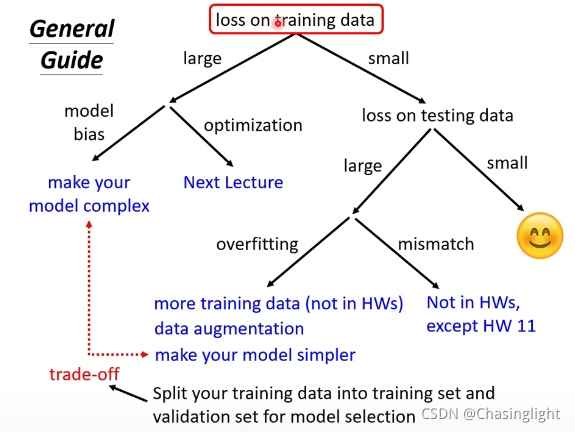
 本文讨论了在深度学习中,20层网络的loss比56层小的情况,指出这可能不是过拟合问题,而是优化问题。提出增加训练集、数据增强和限制模型复杂性作为解决过拟合的常见方法。同时,提到了在临界点遇到鞍点时如何利用Hessian矩阵的特征值和向量进行优化。还涉及了批量大小对梯度下降的影响,以及学习率调整策略中的warmup概念。
本文讨论了在深度学习中,20层网络的loss比56层小的情况,指出这可能不是过拟合问题,而是优化问题。提出增加训练集、数据增强和限制模型复杂性作为解决过拟合的常见方法。同时,提到了在临界点遇到鞍点时如何利用Hessian矩阵的特征值和向量进行优化。还涉及了批量大小对梯度下降的影响,以及学习率调整策略中的warmup概念。


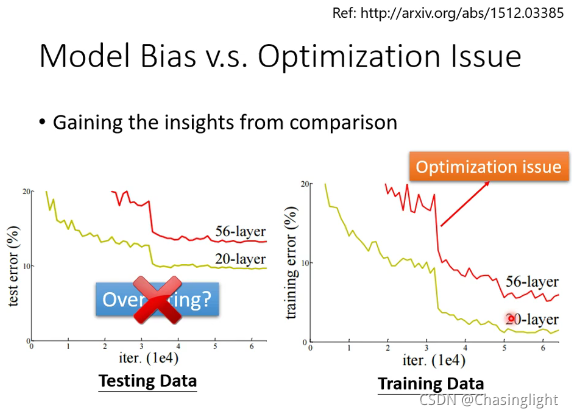
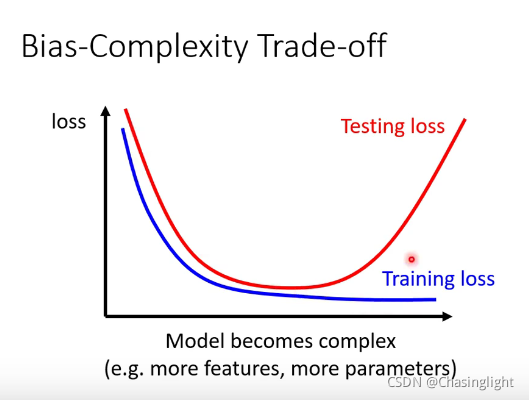
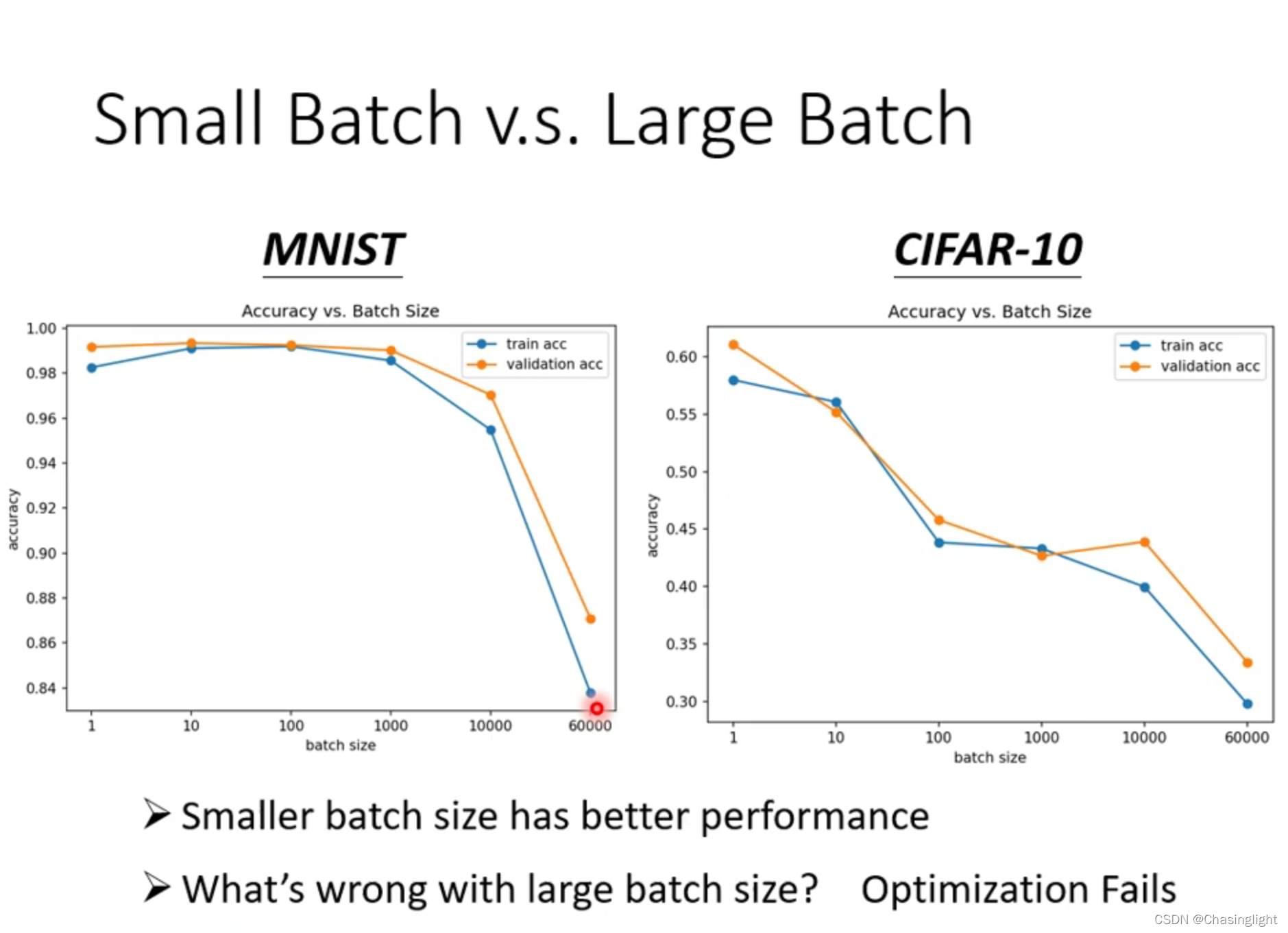
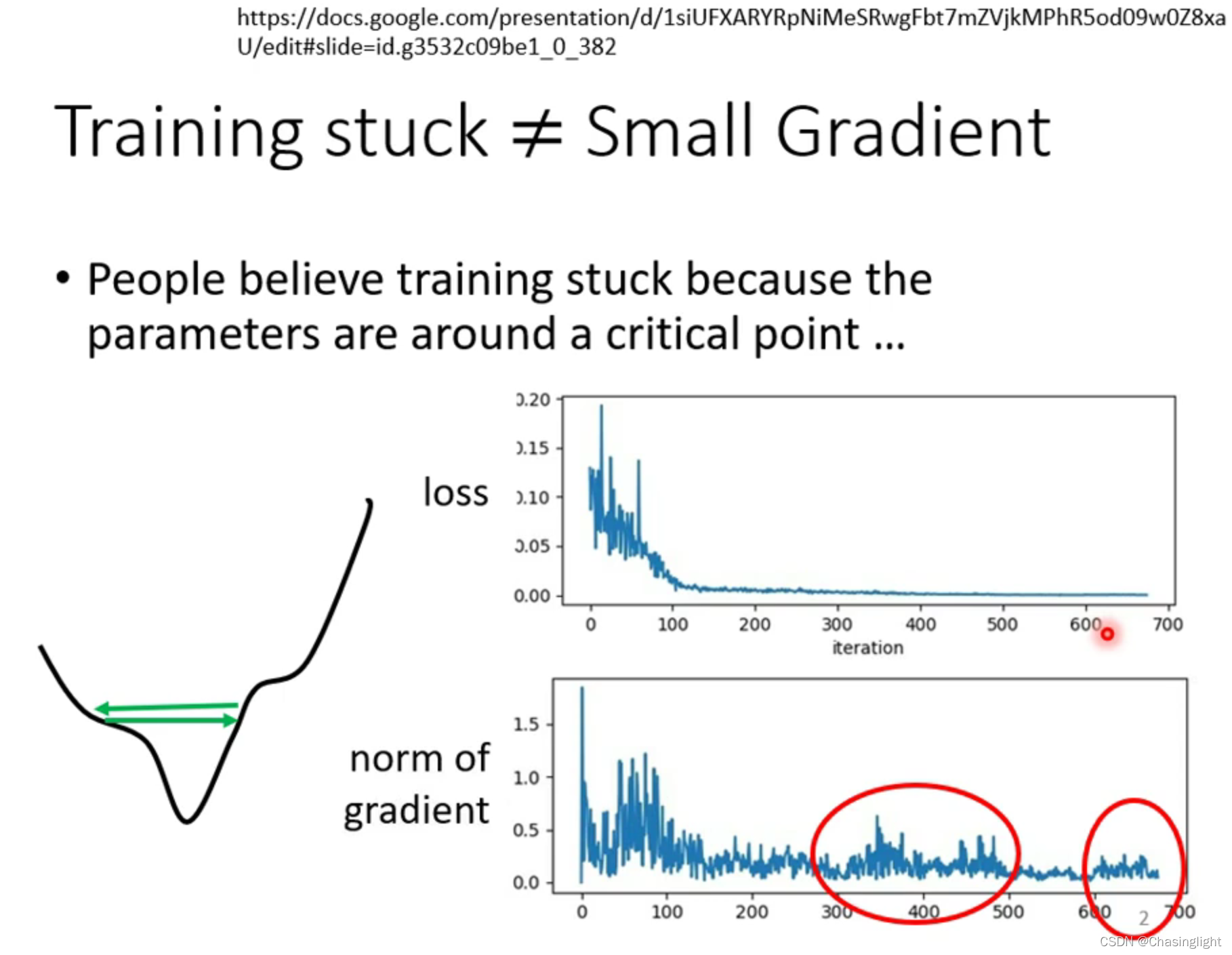
(解释:在测试数据集20层network比56层的loss 更小,考虑over fitting(过拟合)的原因? 答案是不一定的,要再看看训练集,训练集中20层layer还是比56层低。对于训练集来说,20层能拟合的数据,56层网络(函数更为复杂精细)应该更可以拟合精确使得loss function 的值更小,但现在更大,原因应该不是model bias 的问题,所以应该是optimization issue。也不是过拟合的问题,过拟合主要的现象是在训练集loss小测试集loss大)

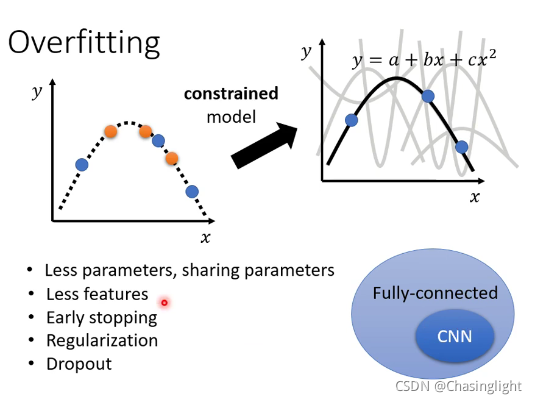
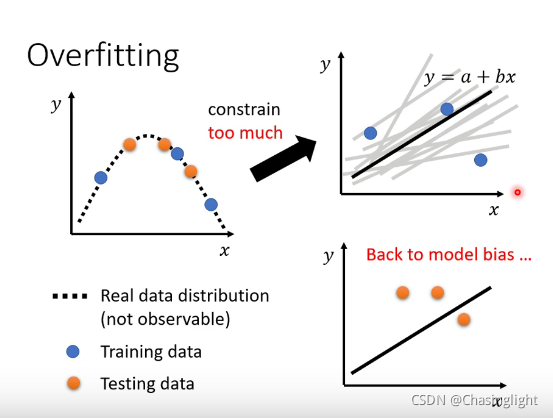
Overfitting
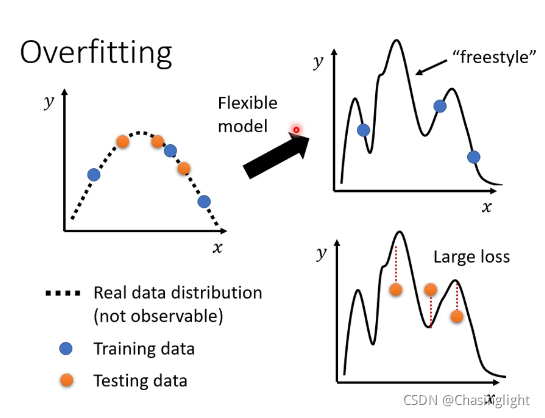
解决over fitting方法:
(1)增加训练集
(2)Date augmentation
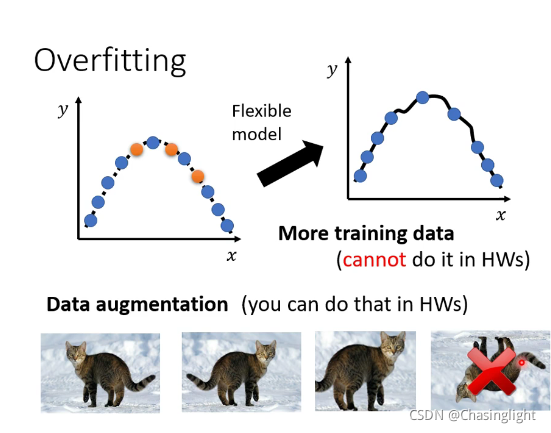
(3)不要让你的model more flexible
constrain your model
但是不要constrain too much

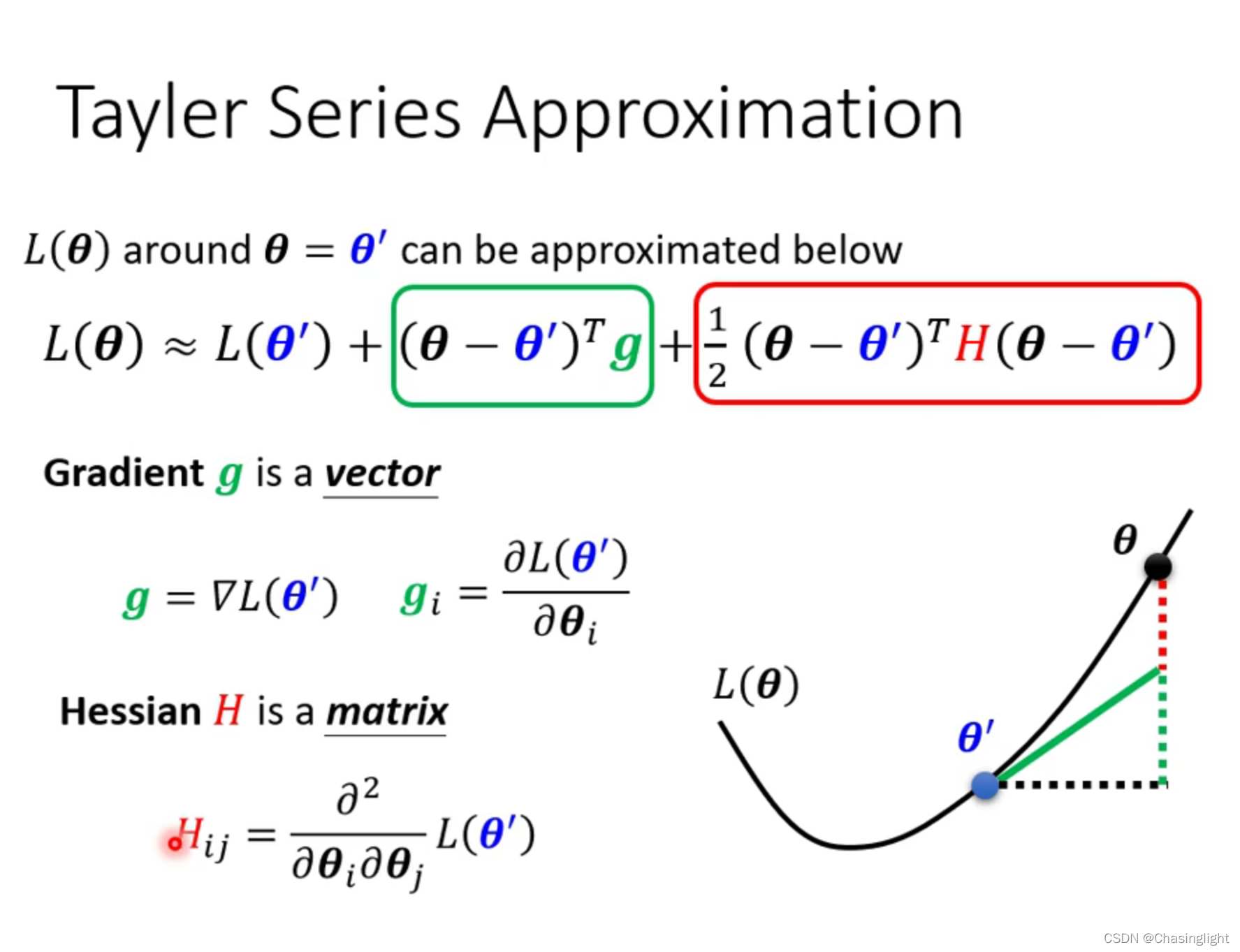
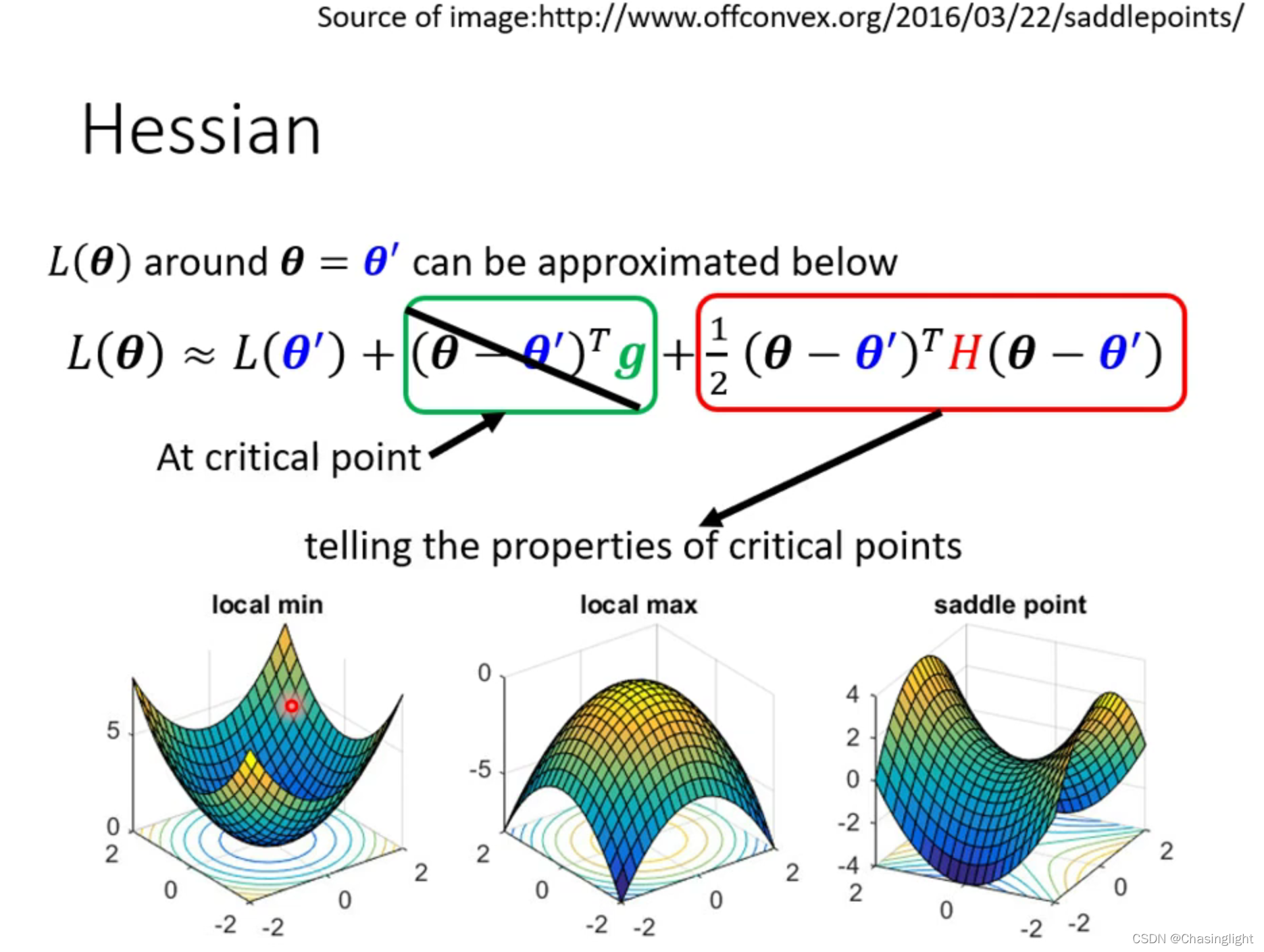

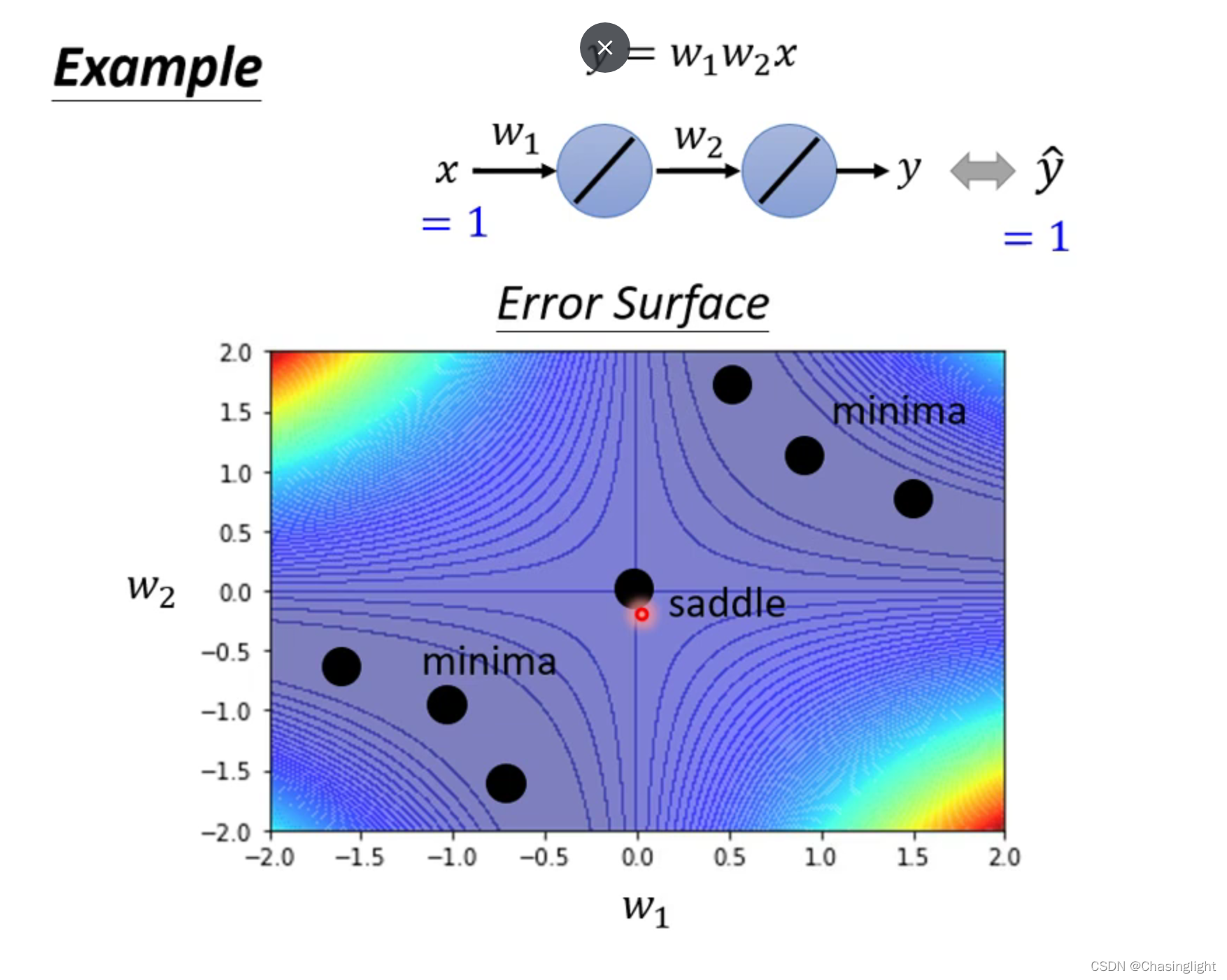

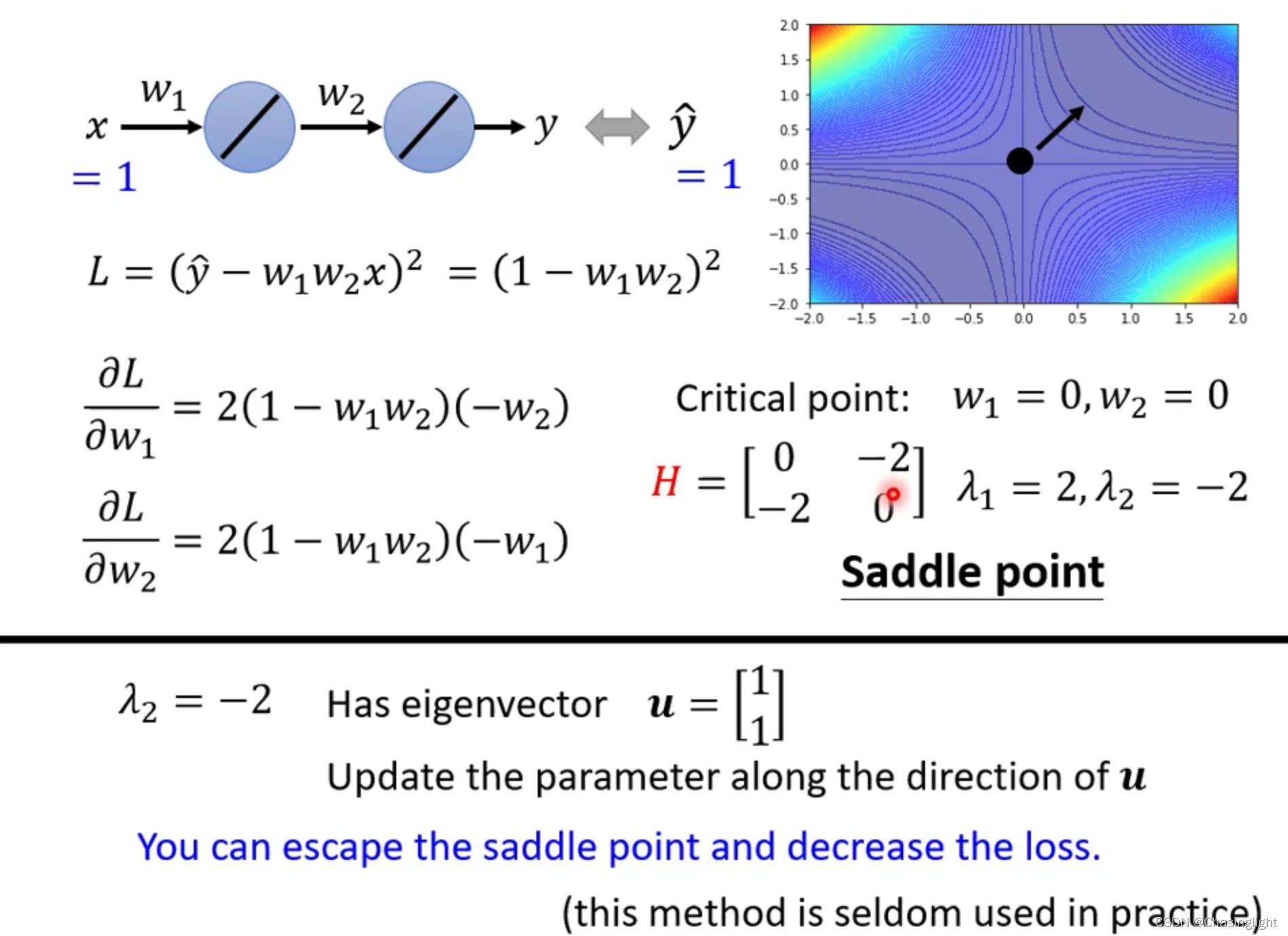
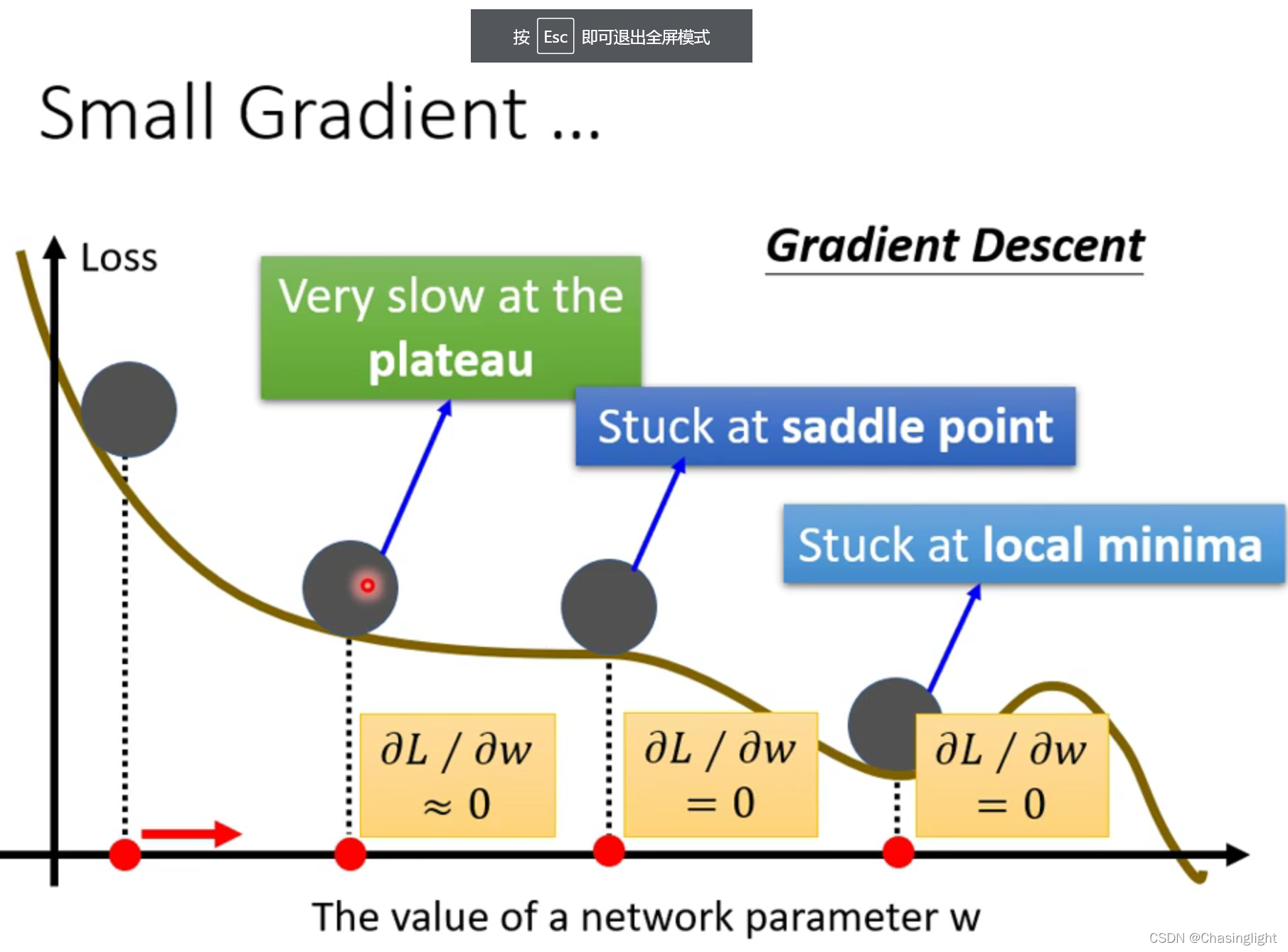
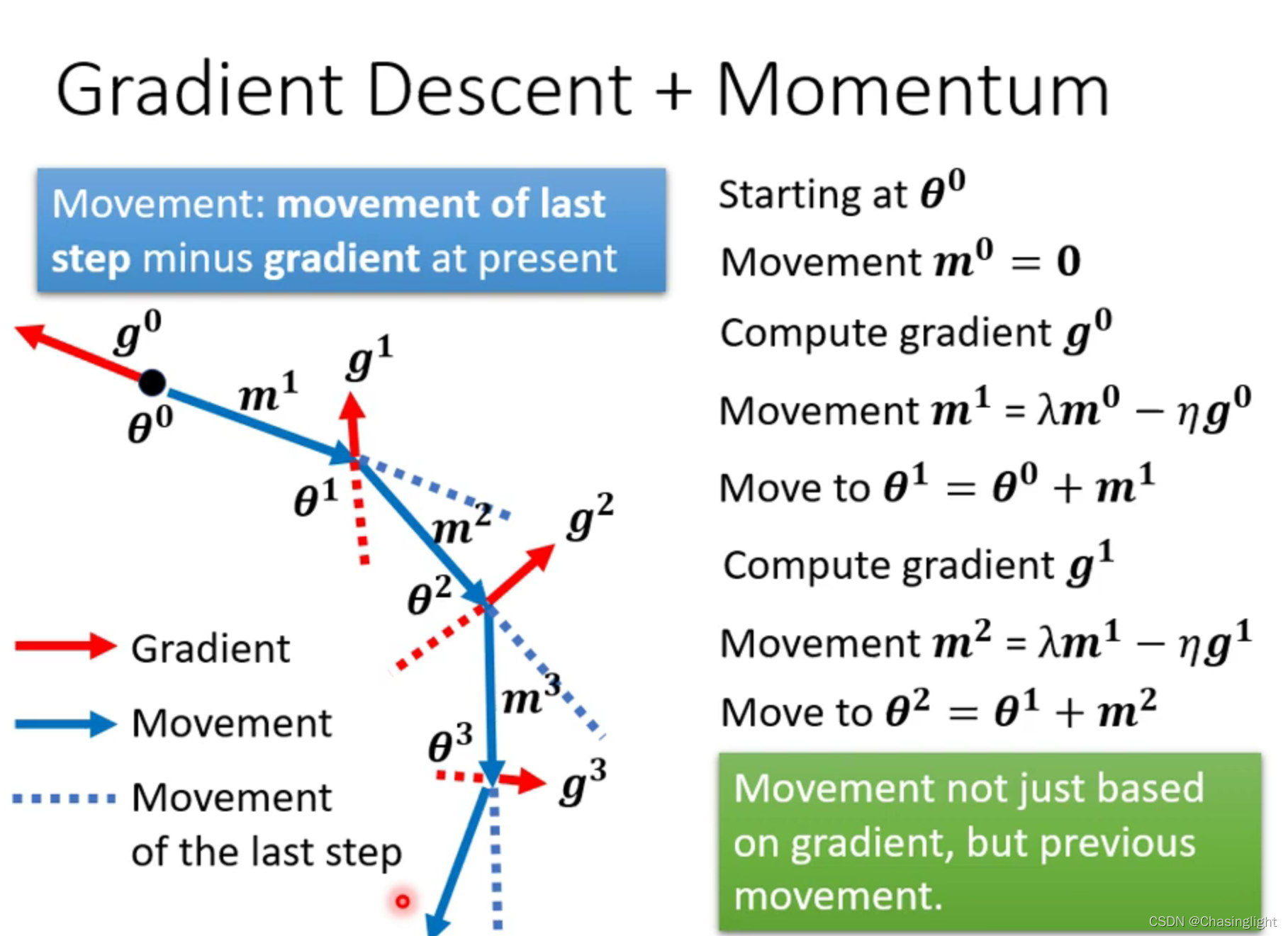
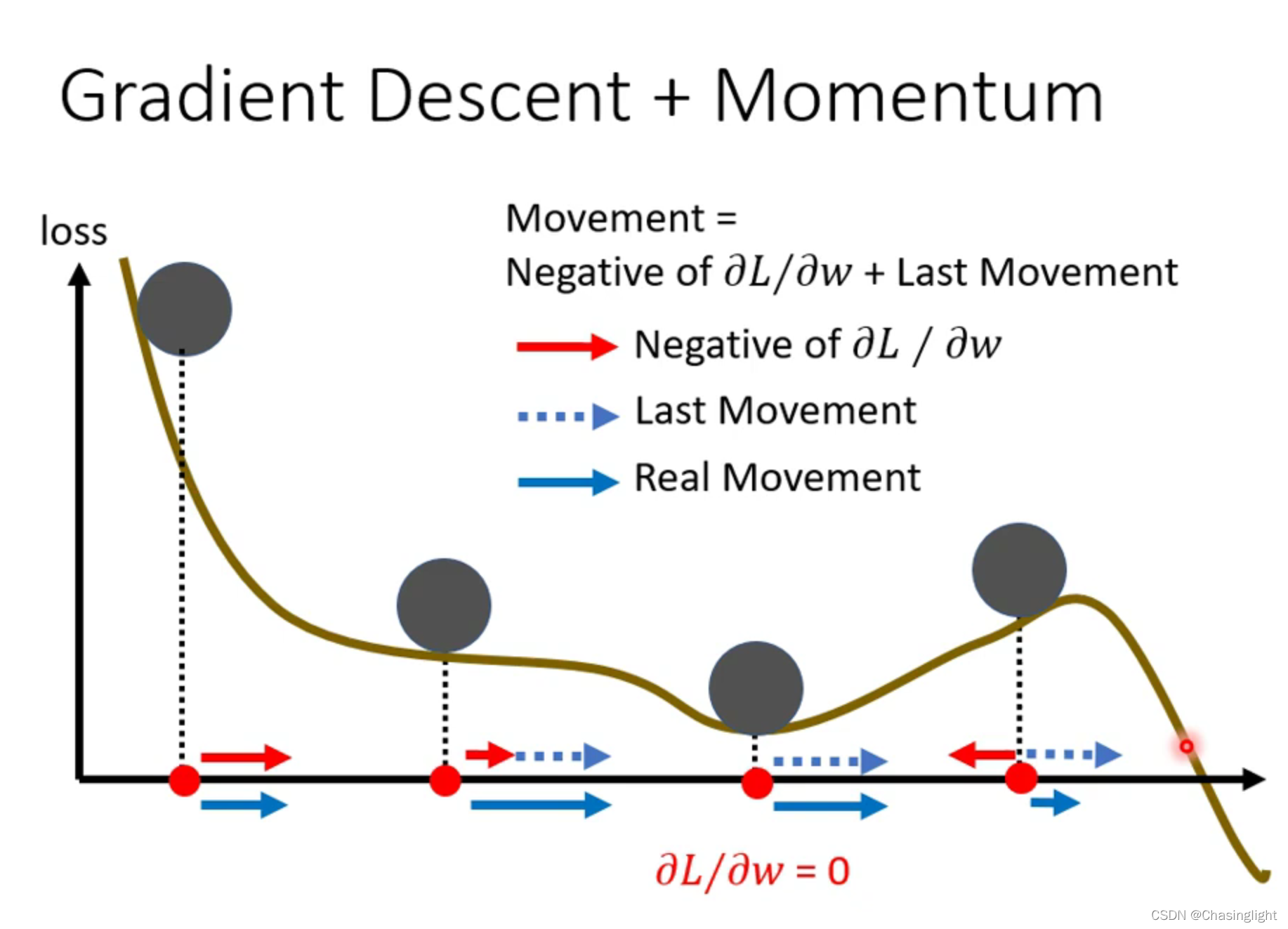
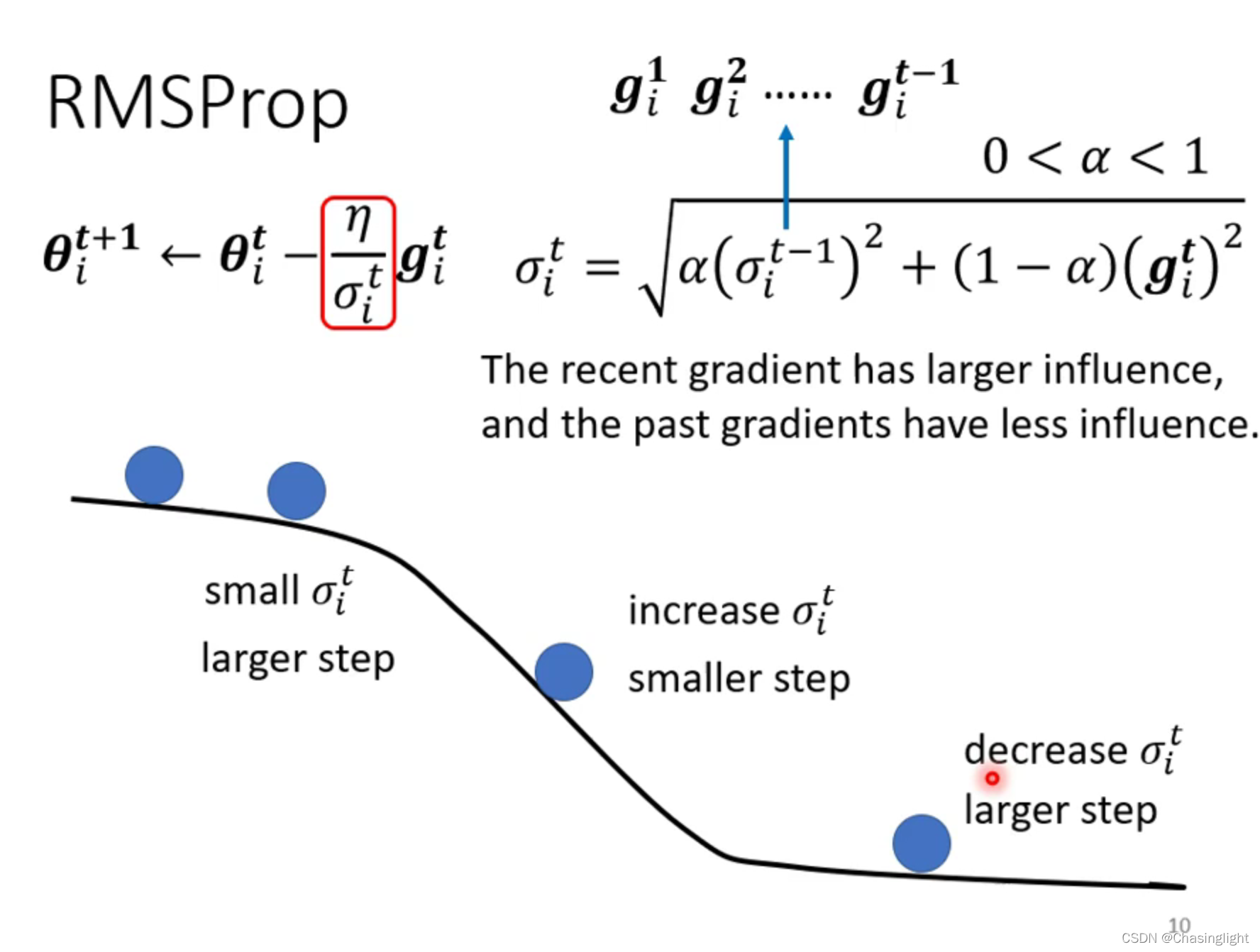
如果在critical point 是属于Saddle point,那么可以通过找Hessian matrix 的eigenvalue 和eigenvector进行下一步梯度下降。
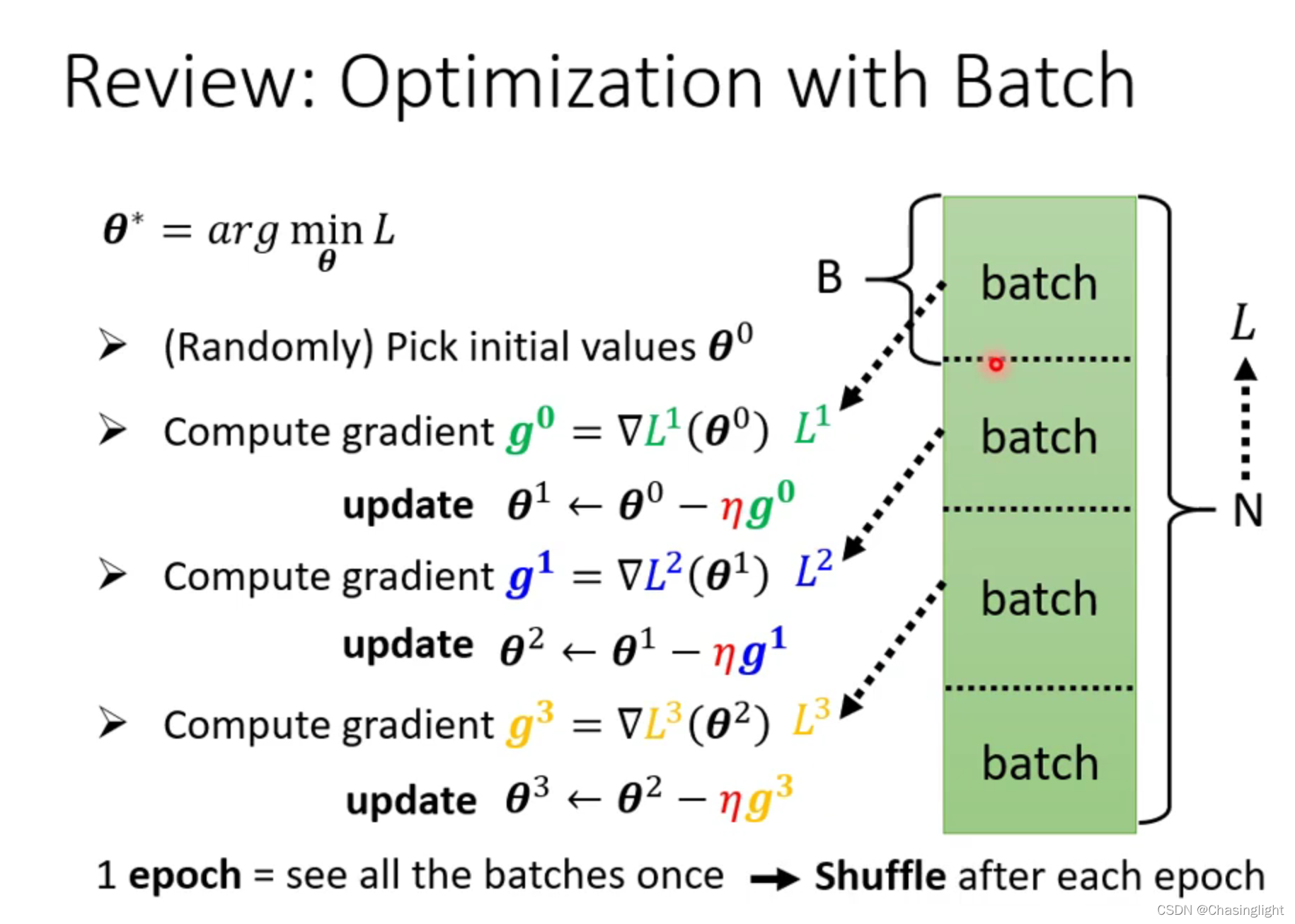

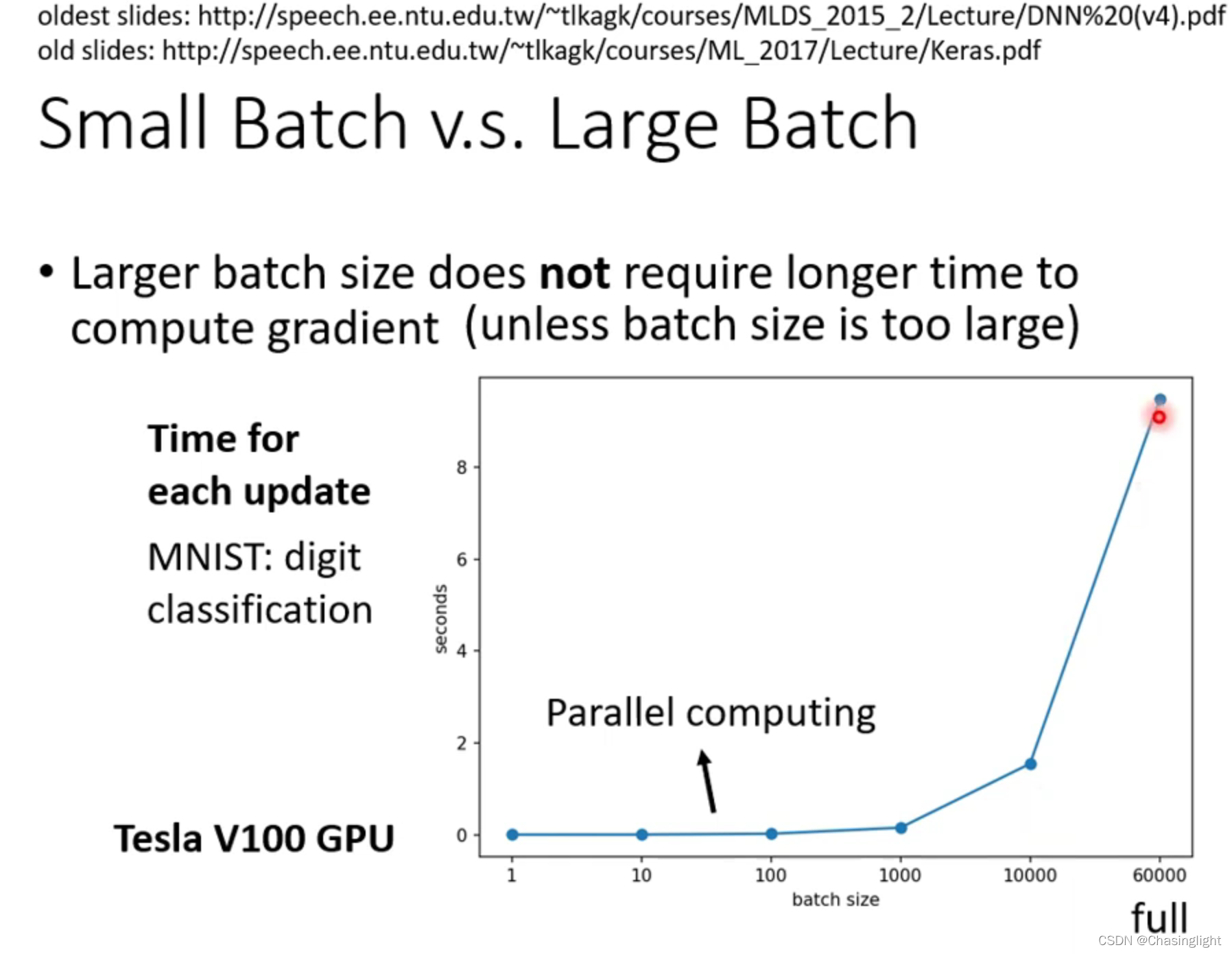
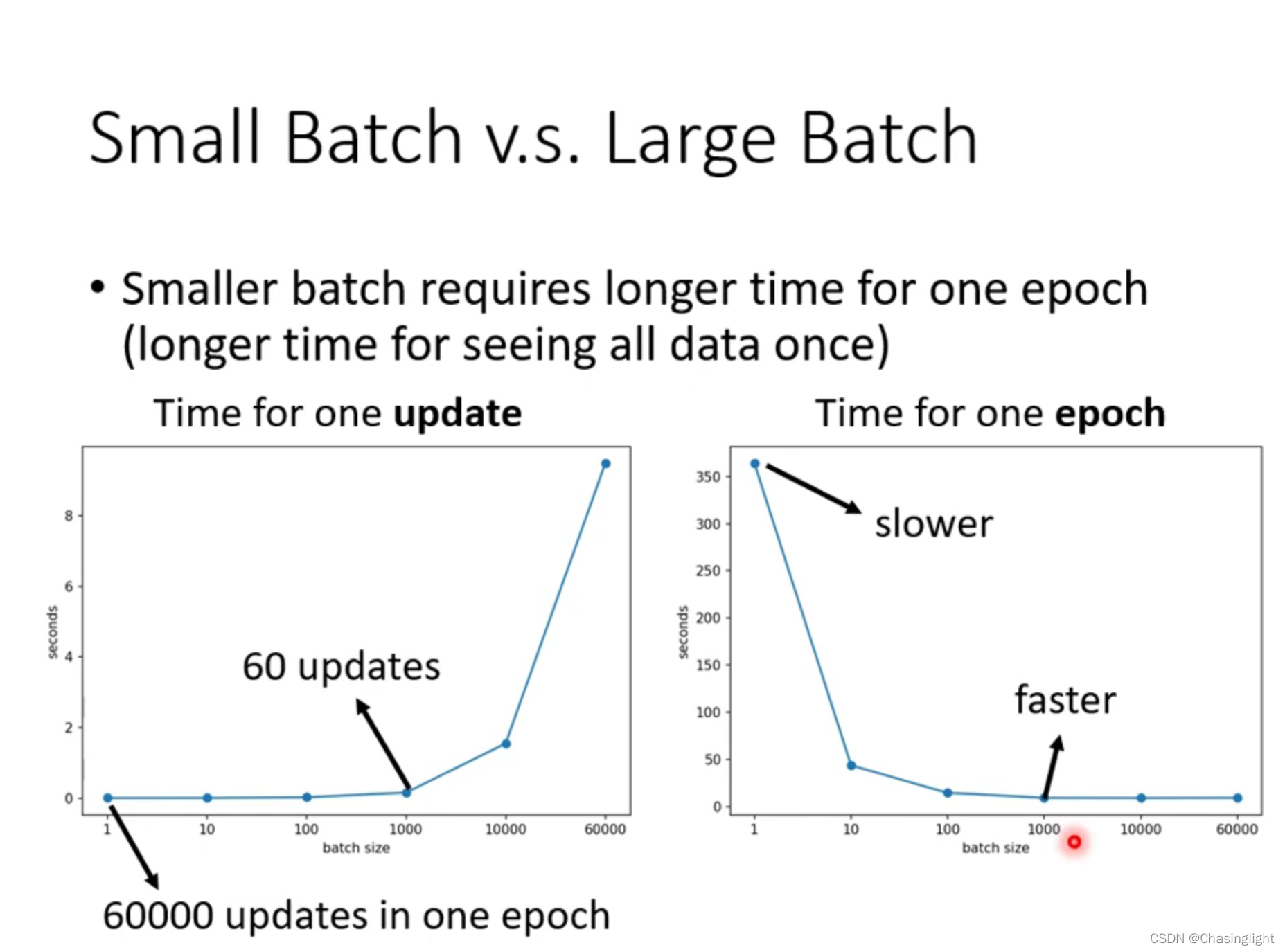
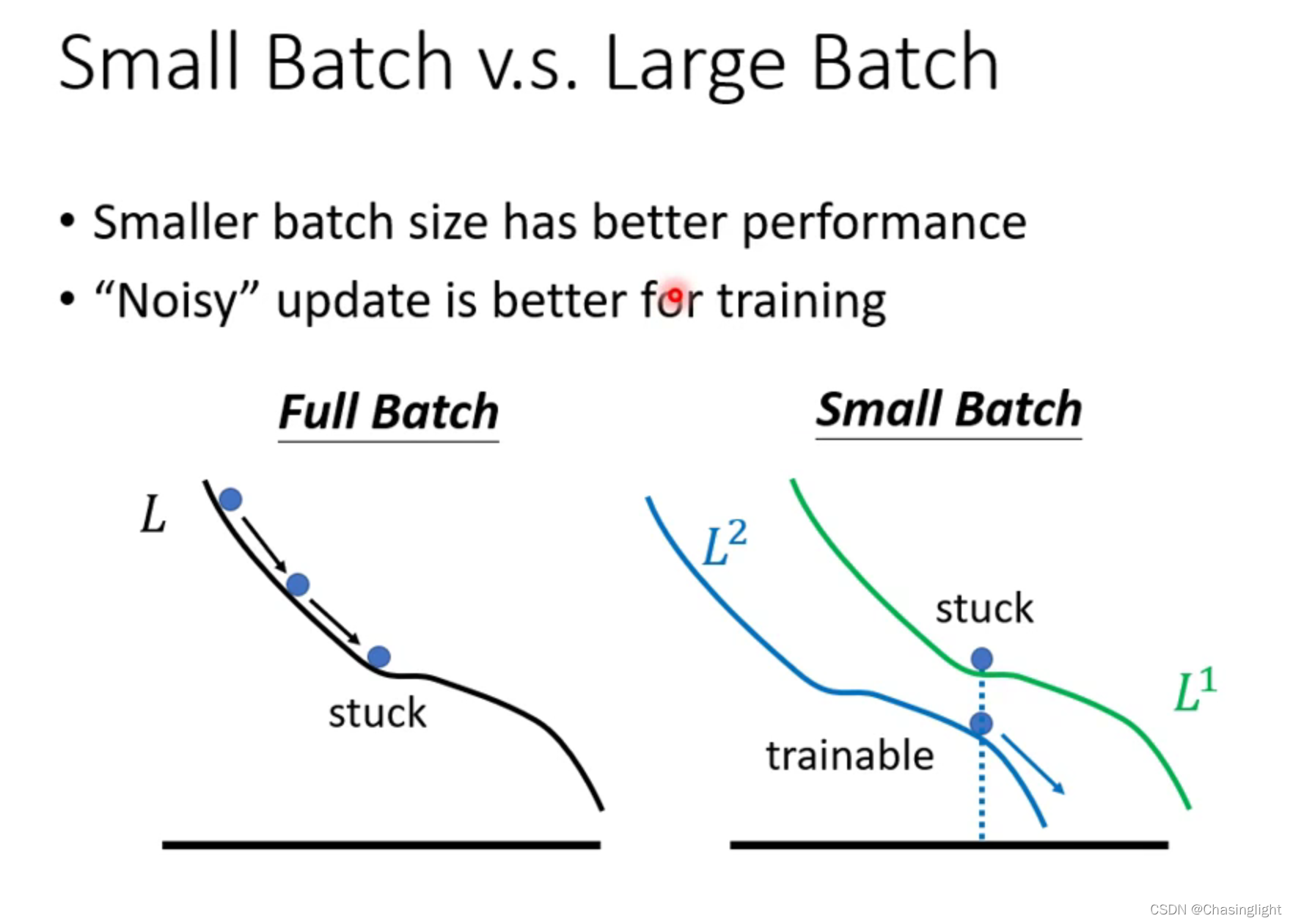
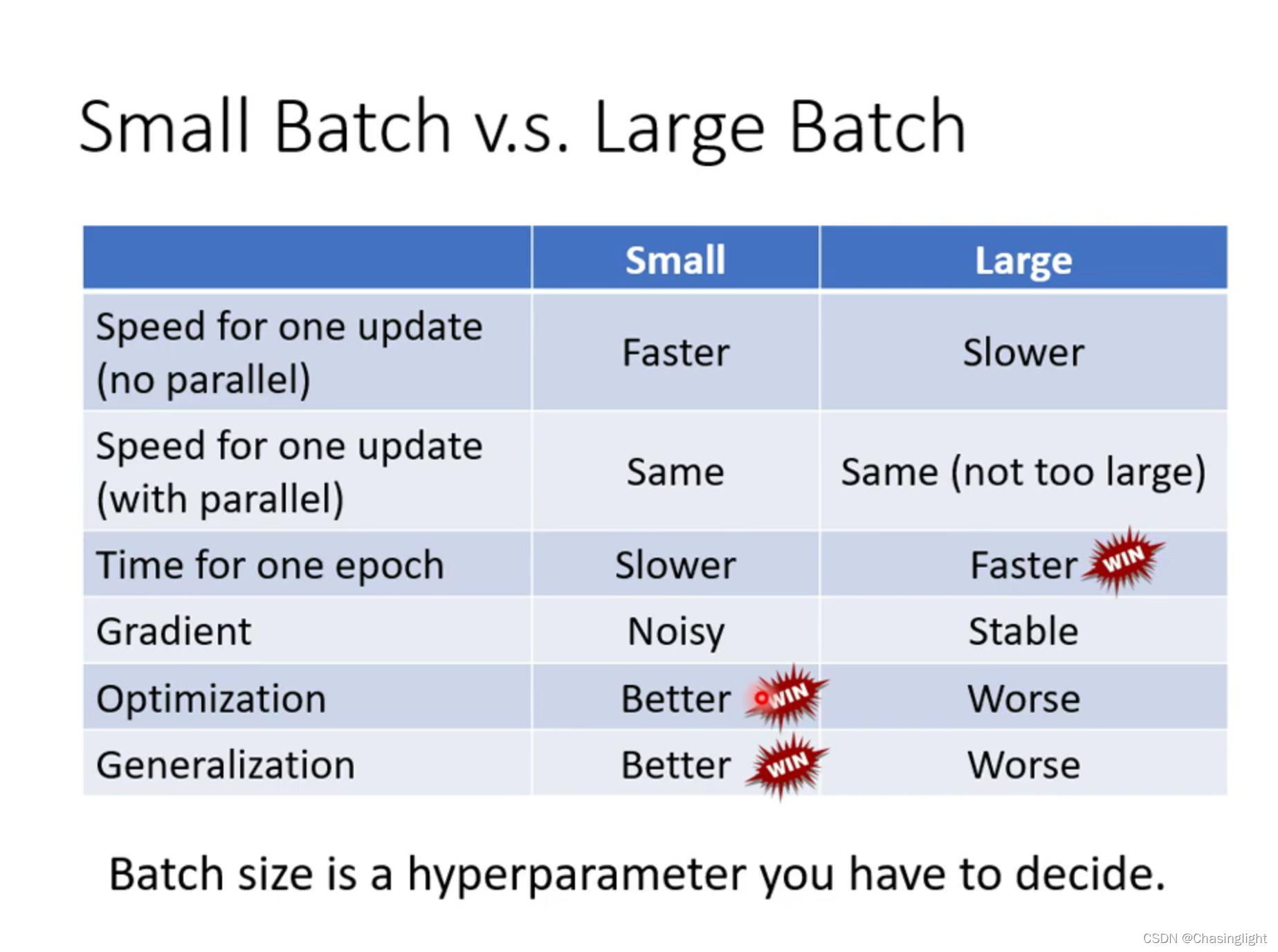
Full batch:等于没有bach 只update一次参数,时间长
Batch size =1 :看1个example就update 一次参数


vanilla :一般的
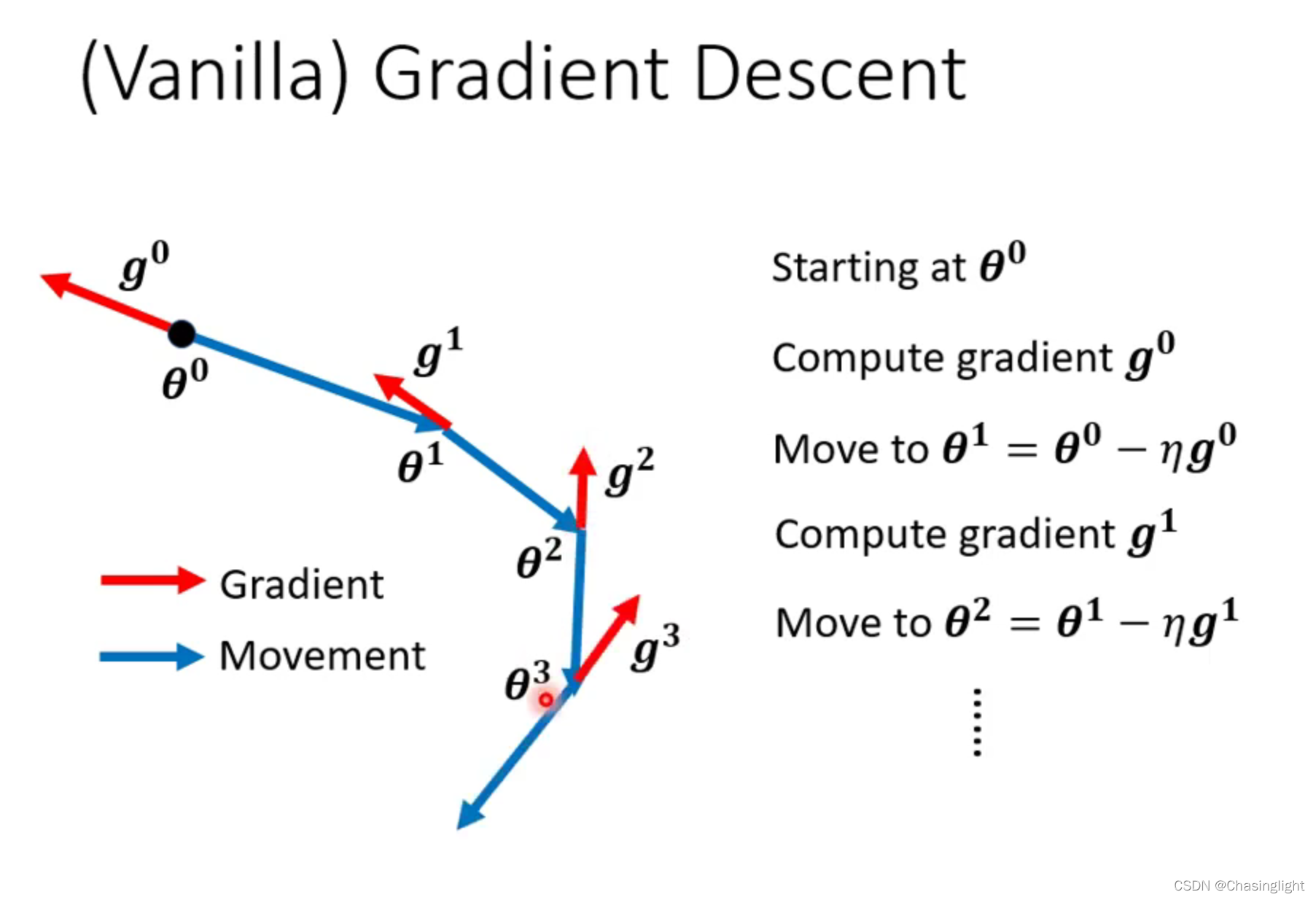
加上


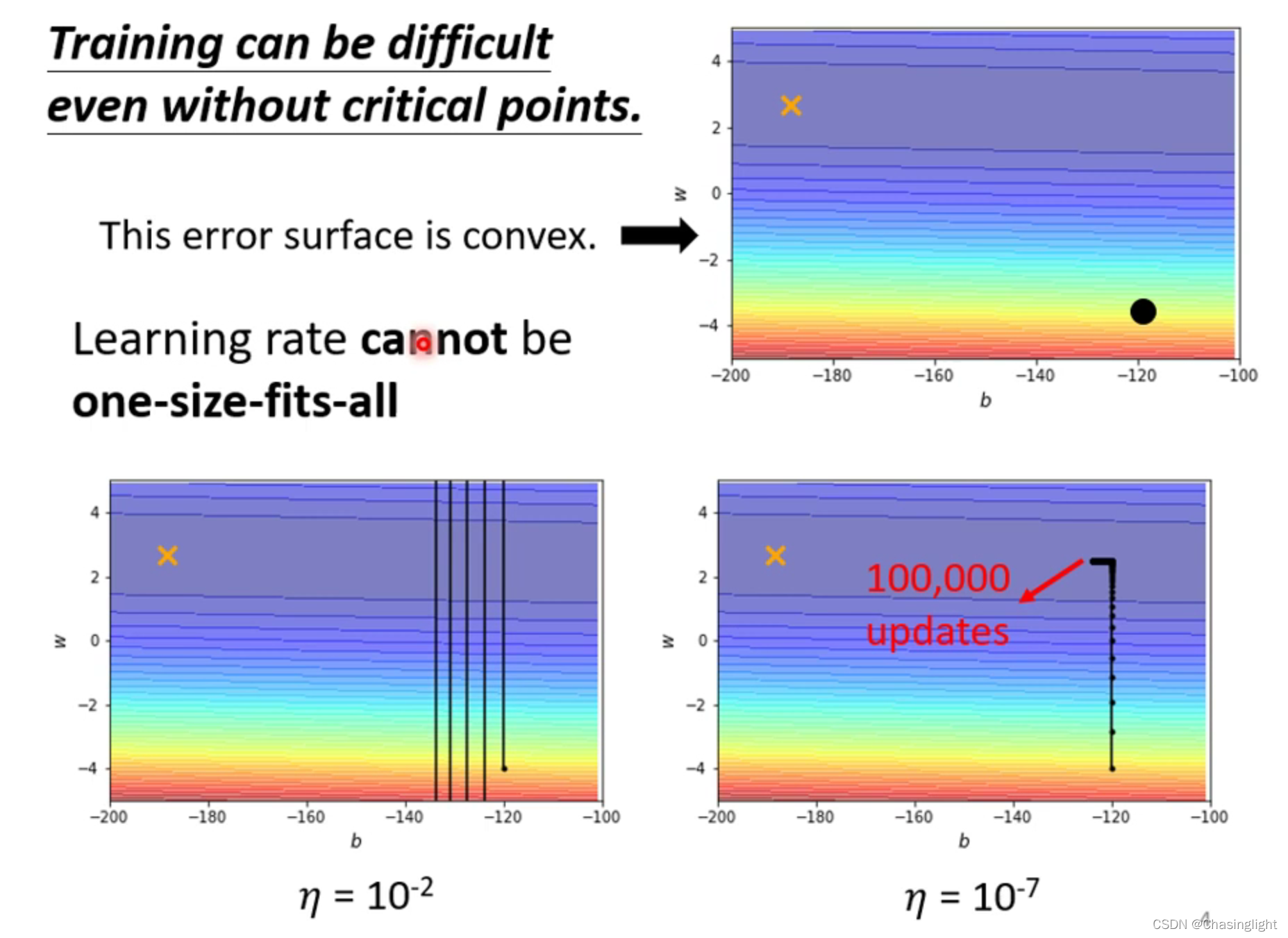
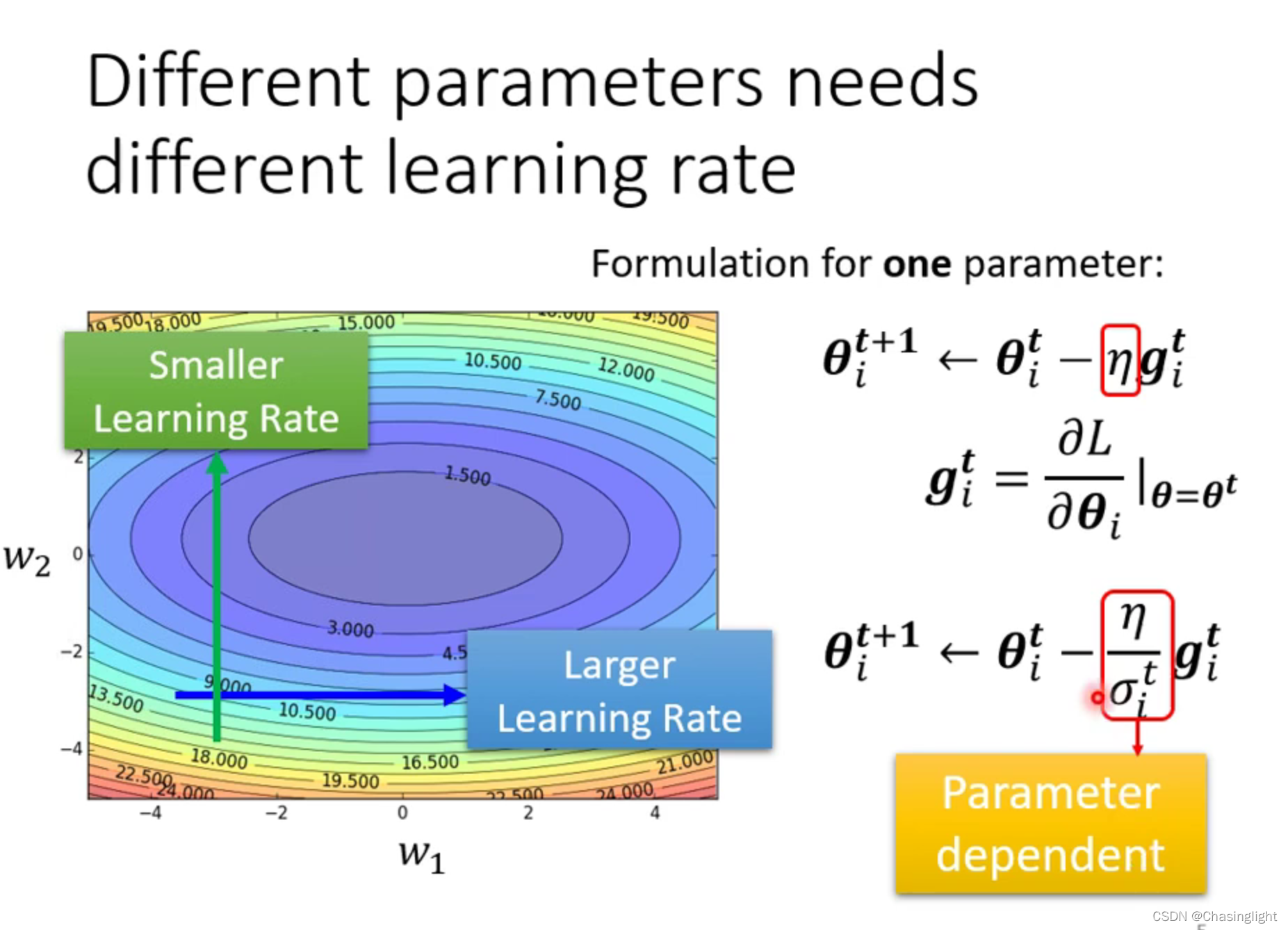
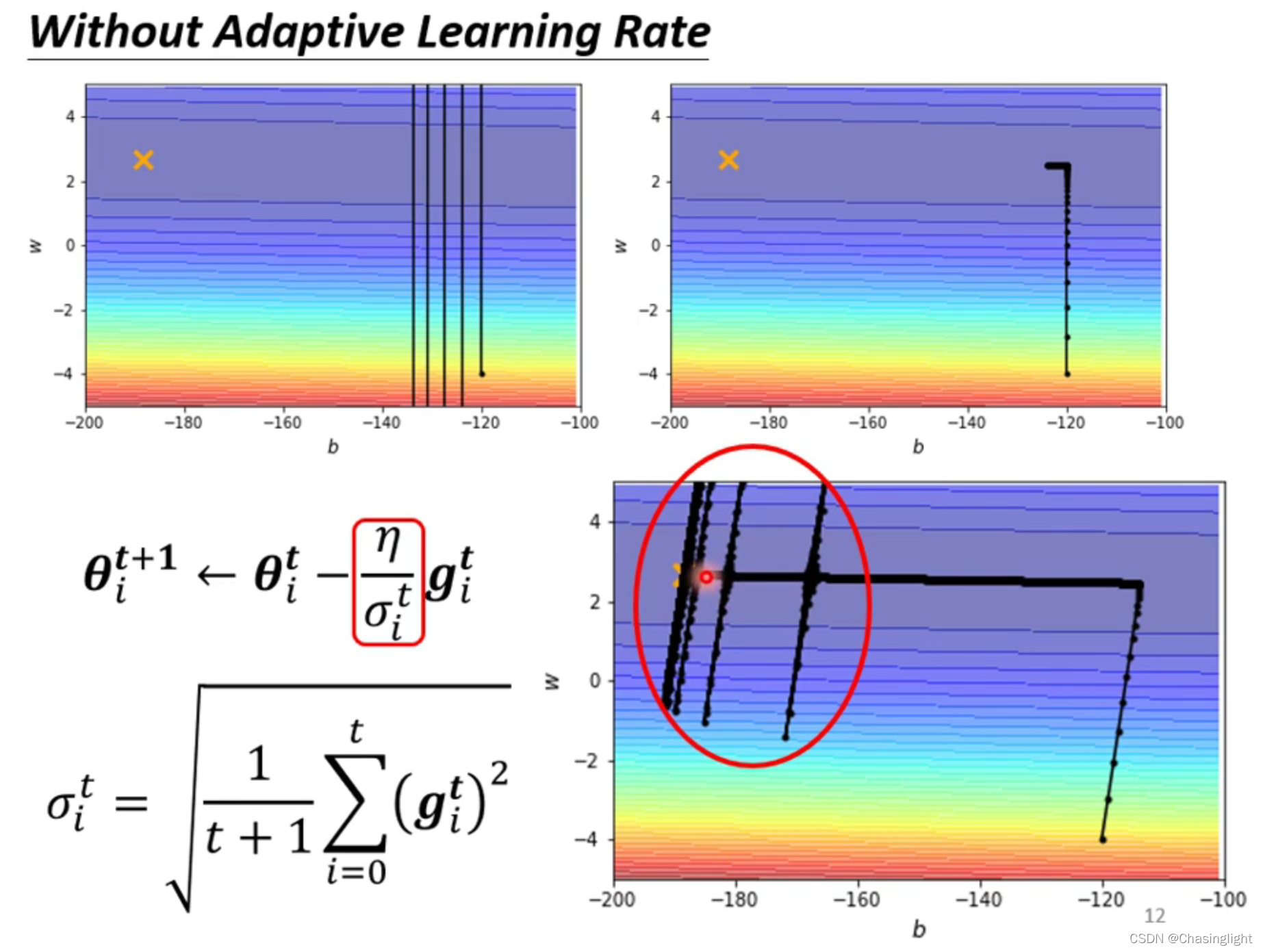
解释:learning rate大的时候会在local minima的梯度线左右两旁来回反复横跳(可以想象成山谷),learning rate 小的时候可以收敛到minima对于的梯度线上,但由于rate太小,始终无法靠近目标点(“×”)。
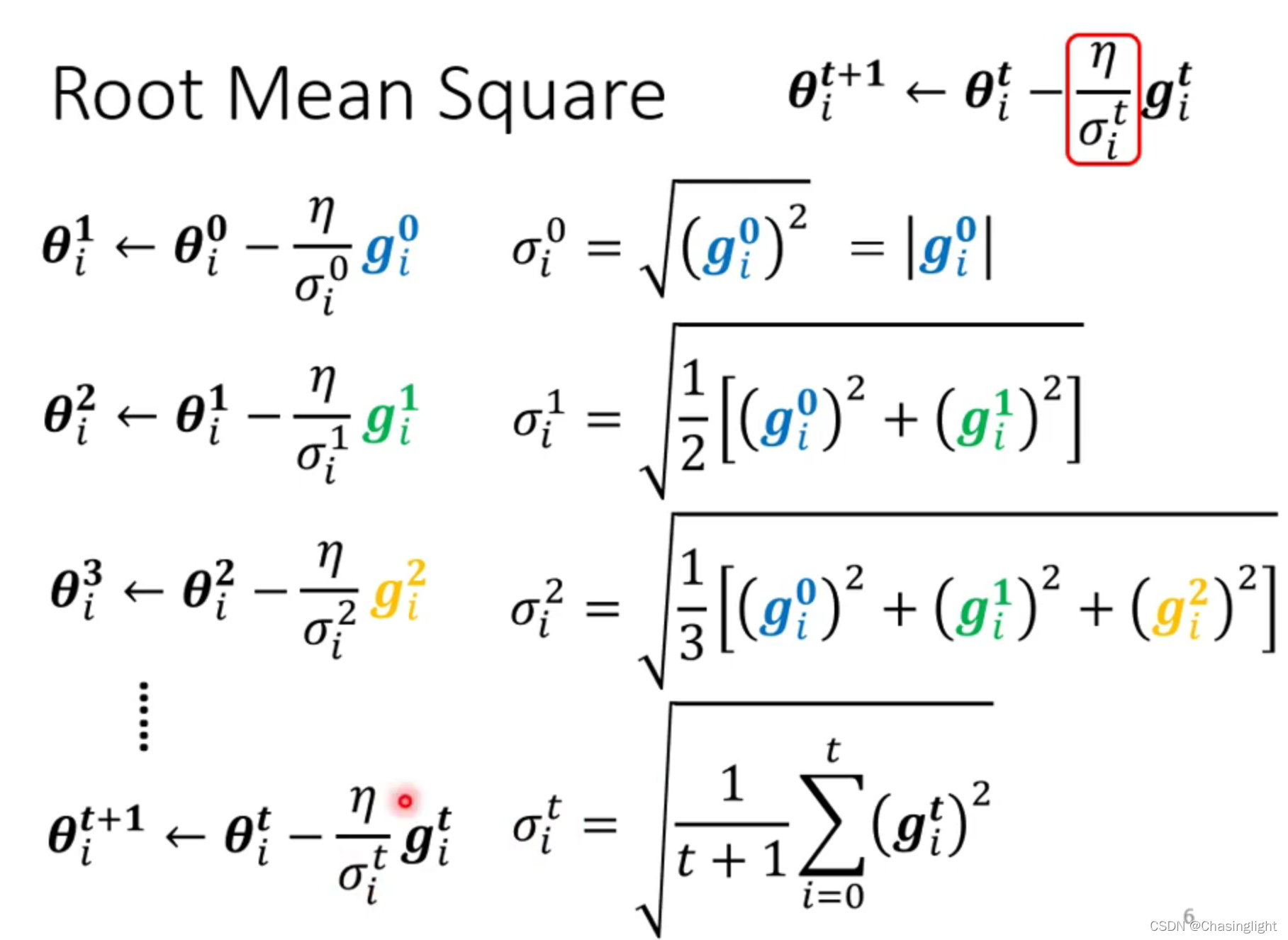
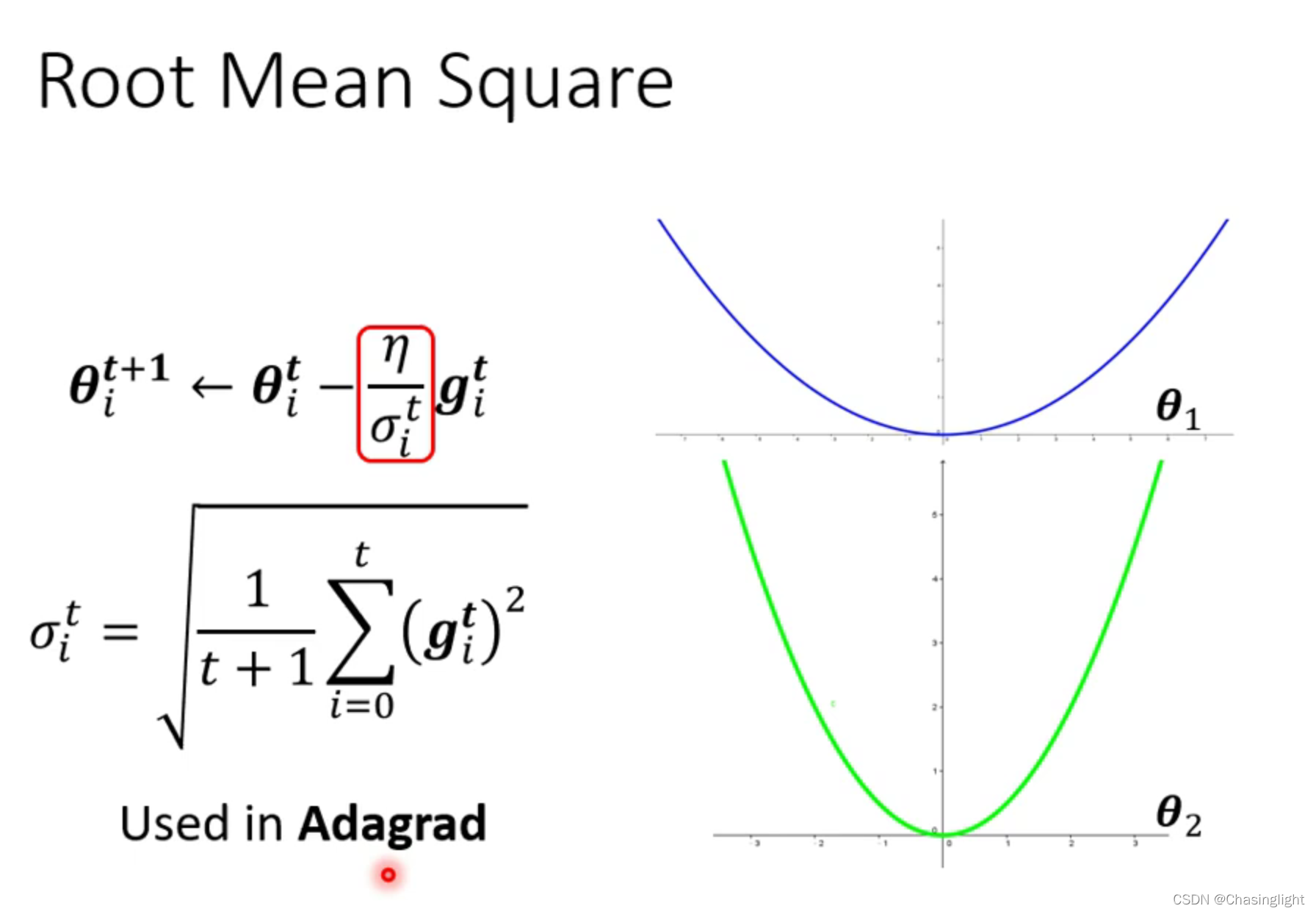
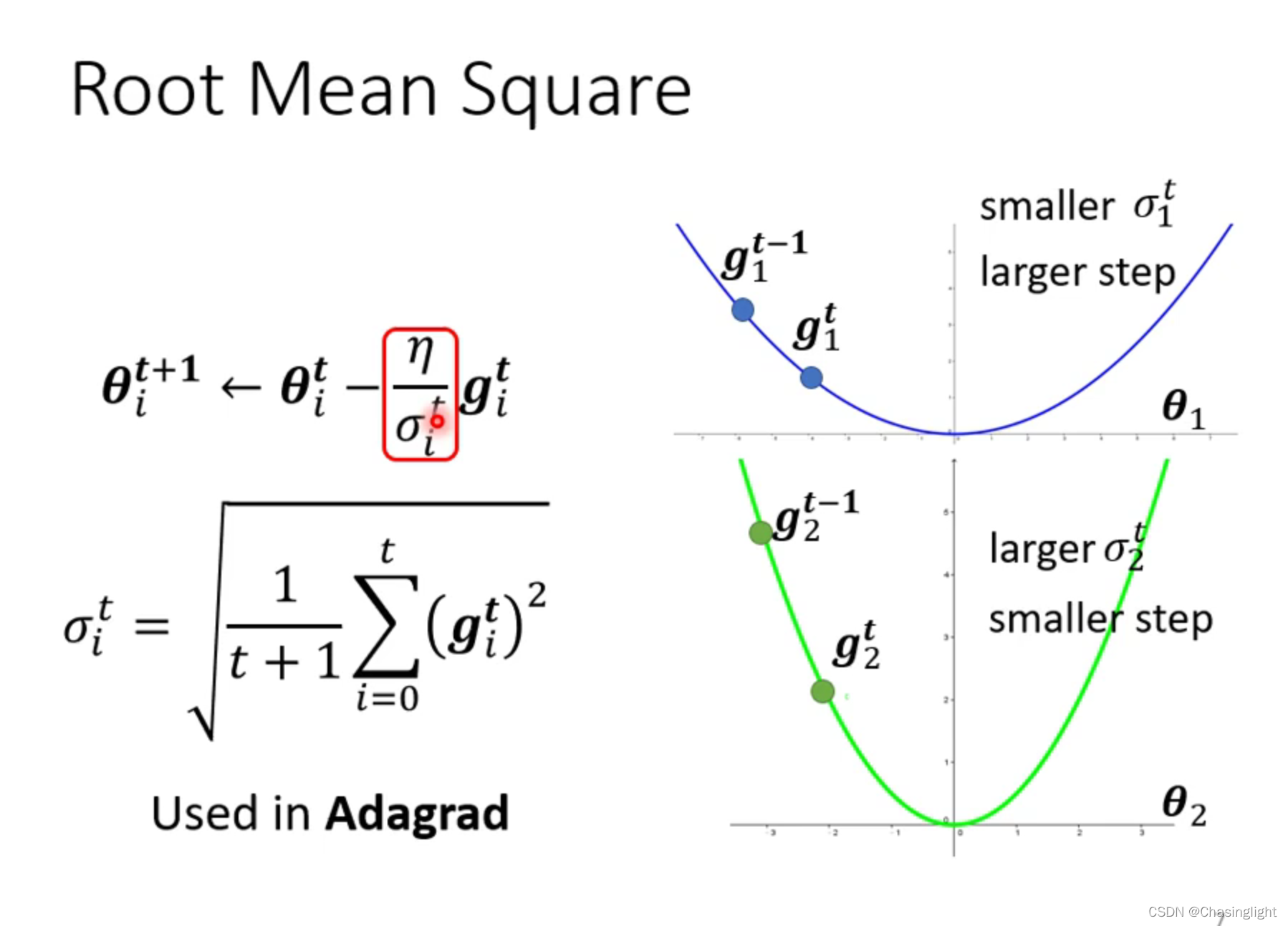
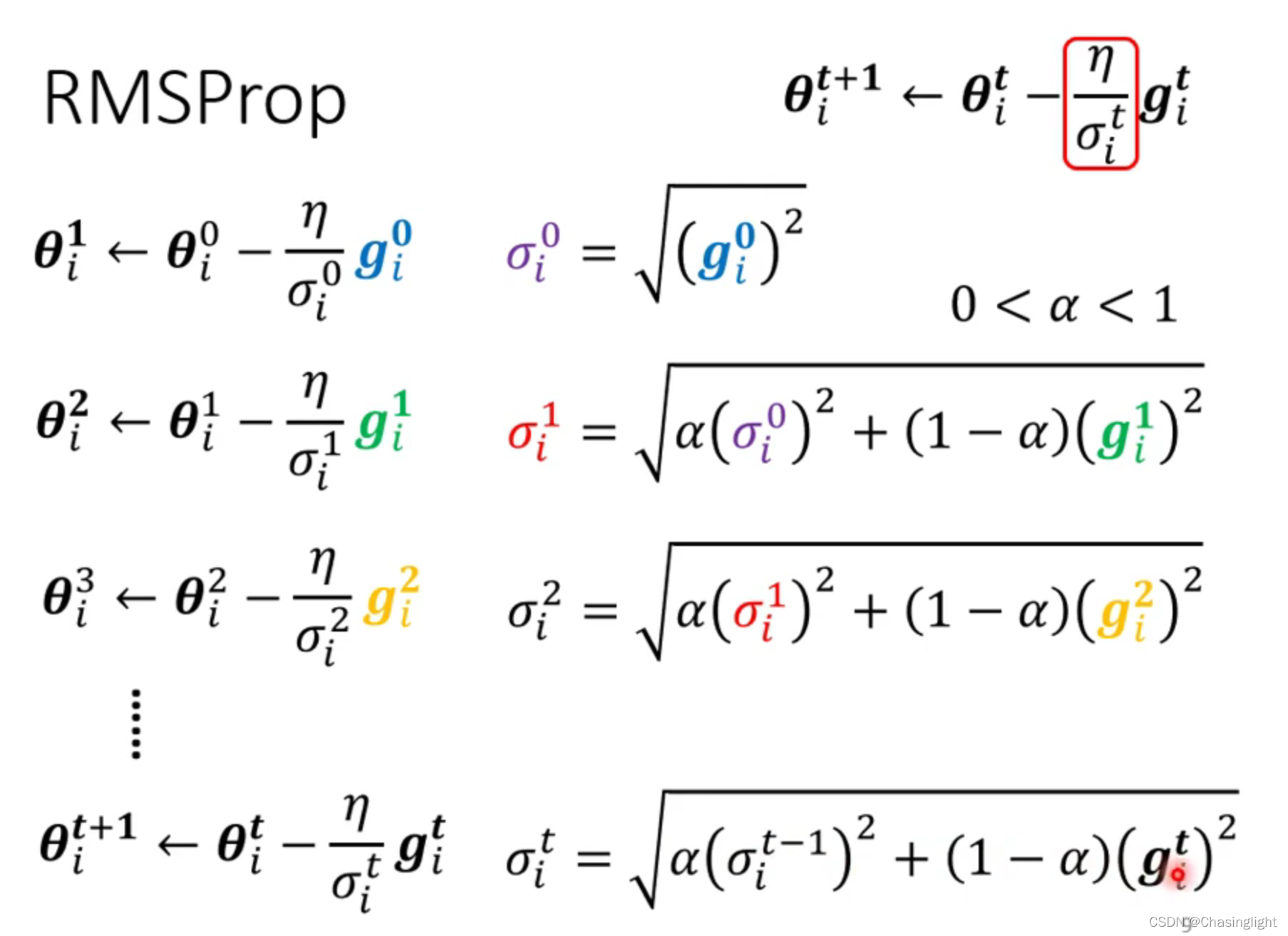

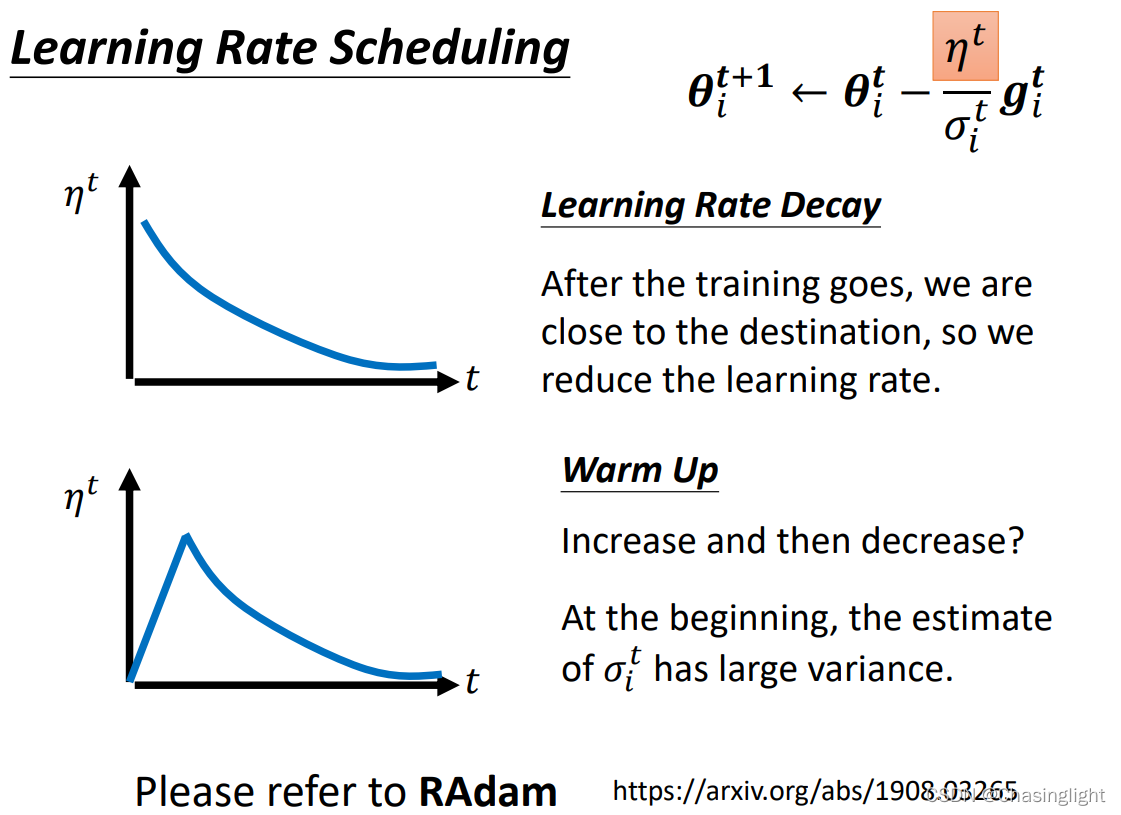
为什么要用 warm up的可能解释?


















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









