 斯坦福提出大语言模型RePS引导策略
斯坦福提出大语言模型RePS引导策略





一、摘要
本文介绍斯坦福大学发表于2025年5月的论文《Improved Representation Steering for Language Models》。

摘要:
语言模型(LM)的引导方法旨在通过以各种方式改变模型输入、权重或表示来调整行为,从而对模型生成进行细粒度且可解释的控制。最近的研究表明,例如在想要引入或抑制某个特定概念时,调整权重或表示往往不如通过提示进行引导有效。我们展示了如何通过我们新的无参考偏好引导(RePS)来改进表示引导,这是一个双向偏好优化目标,可同时进行概念引导和抑制。我们训练了RePS的三种参数化形式,并在大规模模型引导基准测试AxBench上对它们进行评估。在规模从20亿到270亿不等的Gemma模型上,RePS优于所有现有的以语言建模目标训练的引导方法,并大幅缩小了与提示法之间的差距,同时提升了可解释性并减少了参数数量。在抑制方面,RePS在Gemma - 2模型上与语言建模目标表现相当,在更大的Gemma - 3变体上表现更优,并且对于能够破解提示法的基于提示的越狱攻击具有抗性。总体而言,我们的结果表明,RePS为引导和抑制提供了一种可解释且稳健的替代提示法的方法。
二、核心创新点
随着大模型的激增,其可靠性和可控性给业界带来了挑战。本文作者提出了无参考偏好引导策略(Reference-free Preference Steering,RePS),用于训练基于干预的引导方法。当正向应用干预措施时,RePS会提高引导行为的奖励,而当反向应用干预措施时,则会优化相反的行为。本文所指的引导任务,是给定一个输入指令x给经过指令微调的大模型以及一个引导概念c(例如给出一个基于规则的概念引导:“在你的回复中包含一个电话号码”),目标是生成一个经过引导的回复,该回复既要遵循指令,又要通过融入引导概念来对回复进行编辑。
2.1 训练目标
RePS建立在前人研究的基础之上,具有无参考双向偏好优化目标。作者认为,策略语言模型不应被限制在表现接近其参考模型,因为引导行为通常被认为是不规则的,因此不被参考模型所偏好,所以引导目标应当与模型的倾向相反。RePS是双向的,首先为正向引导构建似然差异:
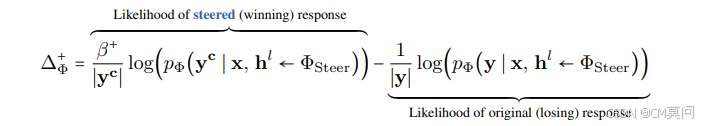
其中,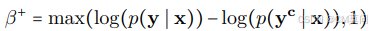 作为一个缩放项,如果参考模型认为引导后的响应不合理,则对其似然赋予更高的权重。RePS还为负向引导构建了一个非对称目标:
作为一个缩放项,如果参考模型认为引导后的响应不合理,则对其似然赋予更高的权重。RePS还为负向引导构建了一个非对称目标:
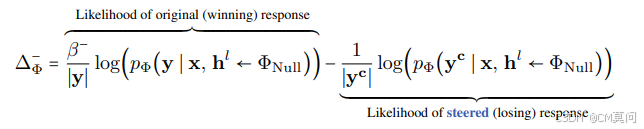
其中,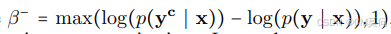 ,
,和
则是两个非对称干预参数化操作,学习到的参数在这两种干预之间共享。最后,两个方向的偏好损失汇总得到:
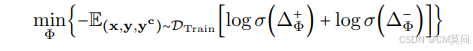
当使用采样的正导向因子进行干预时,RePS学习增加导向响应的可能性,而当进行负向干预时,学习消除导向方向上的任何信息。除了偏好对之外,RePS不需要额外的训练数据。同时,RePS还能够轻松地应用LoRA策略。

















 1935
1935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









