




一、摘要
本文介绍论文《Language Models are Few-Shot Learners》。这篇收录于NeurIPS2020的论文提出了模型GPT-3,把GPT系列大模型的能力又提高了一个层次。

译文:
最近的研究表明,通过在大规模文本语料库上进行预训练,然后在特定任务上进行微调,可以在许多NLP任务和基准测试中取得显著的进展。虽然这种方法在架构上通常是任务无关的,但仍然需要成千上万甚至数万个示例的任务特定微调数据集。相比之下,人类通常只需几个示例或简单的指令就能执行新的语言任务,而这是当前NLP系统仍然难以做到的。在此,我们展示了扩展语言模型大大提高了任务无关的少样本性能,有时甚至可以与之前最先进的微调方法竞争。具体来说,我们训练了GPT-3,这是一种具有1750亿参数的自回归语言模型,比之前的任何非稀疏语言模型多10倍,并在少样本设置中测试其性能。对于所有任务,GPT-3在没有任何梯度更新或微调的情况下应用,任务和少样本示例仅通过与模型的文本交互指定。GPT-3在许多NLP数据集上表现出色,包括翻译、问答和完形填空任务,以及一些需要即时推理或领域适应的任务,如解码单词、在句子中使用新词或进行三位数算术。同时,我们也发现了一些数据集,GPT-3的少样本学习仍然存在困难,以及一些GPT-3在大规模网络语料库训练中面临的方法论问题。最后,我们发现GPT-3可以生成新闻文章样本,且人类评估者难以区分这些样本与人类撰写的文章。我们讨论了这一发现以及GPT-3总体的更广泛社会影响。
二、核心创新点
GPT3的基本预训练方式与前作GPT2并无太大区别,只是在模型的规模、数据集规模和多样性、训练时常方面进行了一些扩展。

1、模型和架构
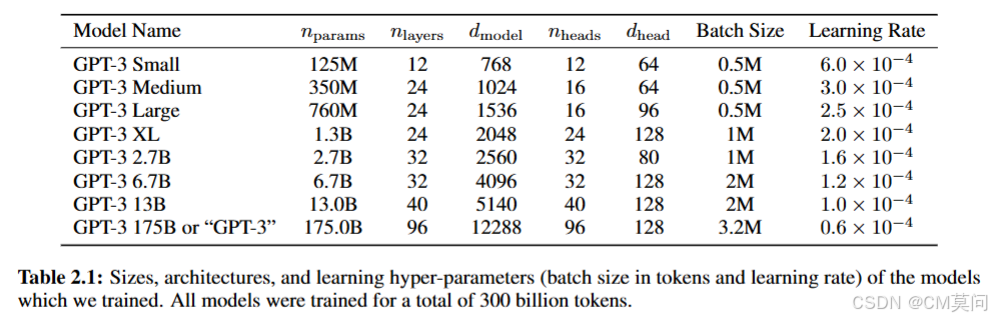
GPT3模型中,Transformer各层使用交替的密集和局部带状稀疏注意力模式(与Sparse Transformer类似)。为了研究机器学习性能对模型大小的依赖性,作者训练了8种不同大小的GPT3模型,参数数量从1.25亿到1725亿不等,见下图。
这里的是可训练参数的总数,
是总层数,
是每个bottleneck层的单元数且作者始终保持FFN层是bottleneck层大小的4倍(
),
是每个注意力头的维度。同时,所有模型都是用大小为
个Token的上下文窗口(现在来看不算什么了,但在当时普遍是512上下文窗口的时期已经很长了)。
2、训练数据集
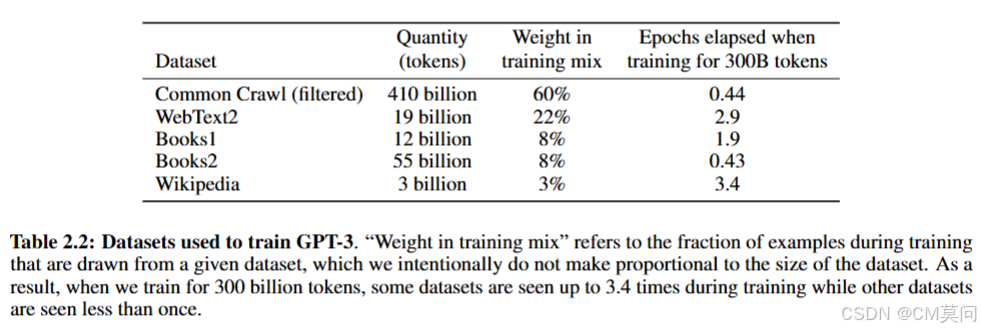
使用的主要数据集是Common Crawl数据集,规模上达到了近一万亿个单词,且为了提高数据集质量,作者做了三个步骤:
- 下载并根据一系列高质量参考语料库的相似性对Common Crawl进行筛选;
- 在数据集内部和跨数据集的文档级别进行了模糊去重,以防止冗余并保持预留验证集的完整性;
- 将已知的高质量参考语料库添加到训练组合中以增加数据多样性。
3、训练过程
较大的模型可以使用较大的batch size,但需要较小的学习率。作者在训练期间测量了梯度噪声scale,并使用它来指导对batch size的选择。为了在不耗尽内存的情况下训练较大的模型,作者还在每个矩阵乘法中都使用模型并行和网络各层之间并行的混合。

















 8182
8182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









