




一、摘要
本文介绍论文《GLM-130B: An Open Bilingual Pre-trained Model》,同样是来自清华的唐杰团队,这次的GLM-130B是基于GLM模型框架的优化版本。

译文:
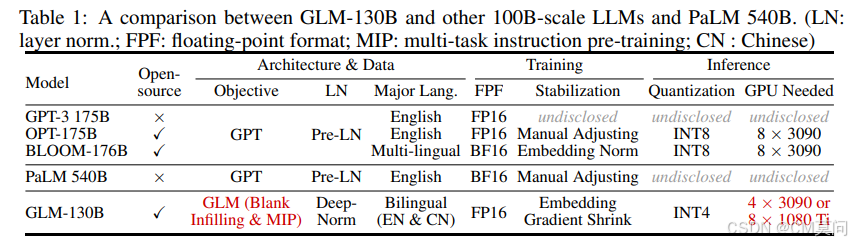
我们介绍了GLM-130B,这是一种具有1300亿参数的双语(英语和中文)预训练语言模型。这是一次开源一个至少与GPT-3(davinci)同等优秀的1000亿规模模型的尝试,并揭示了如何成功预训练如此规模的模型。在这一过程中,我们面临了许多意想不到的技术和工程挑战,特别是在损失峰值和发散问题上。在本文中,我们介绍了GLM-130B的训练过程,包括其设计选择、提高效率和稳定性的训练策略以及工程努力。最终的GLM-130B模型在广泛的流行英语基准测试中显著优于GPT-3 175B(davinci),而在OPT-175B和BLOOM-176B中未观察到这种性能优势。它还在相关基准测试中持续且显著地优于ERNIE TITAN 3.0 260B——最大的中文语言模型。最后,我们利用GLM-130B的独特扩展特性,在几乎没有性能损失的情况下实现了INT4量化,使其成为首个1000亿规模模型,并且更重要的是,使其能够在4个RTX 3090(24G)或8个RTX 2080 Ti(11G)GPU上进行有效推理,这是使用1000亿规模模型所需的最经济实惠的GPU。
二、核心创新点
GLM-130B在基础架构上与之前我们所介绍的GLM是一致的,但有一些局部的改动。
1、掩码
GLM的对未掩码(即未损坏)上下文的双向注意力使得GLM-130B和采用单向注意力的GPT区分开来。为了支持文本理解和生成,作者混合了两个损坏目标,每个目标都有一个特殊的掩码Token来指示,分别是[MASK]和[gMASK]。其中,[MASK]是句子中的短空白,其长度总和占输入的一定比例,而[gMASK]则是在提供前缀上下文的句子末尾随机长度的长空白。
2、归一化层
作者指出训练不稳定性是大语言模型训练的一个主要挑战,通过对前置层归一化、后置层归一化、Sandwich归一化进行了测试,最终集中在后置层归一化的优化上。通过使用一个新提出的深度范数(DeepNorm)初始化的技术,实现了一定程度的训练稳定性。
具体来说,给定GLM-130B的层数N,作者采用如下层归一化:
其中,并对前馈神经网络FFN、v_proj、out_proj使用缩放因子为
的Xavier正态初始化。另外还将所有的偏置项都初始化为零,从而实现了GLM-130B的训练稳定性。
3、位置编码和前馈网络
作者从训练稳定性和下游性能两个方面对位置编码和前馈网络进行了改进。对于位置编码,作者采用了旋转位置编码技术,而前馈网络则选择带有GeLI激活函数的GLU。
4、预训练
GLM-130B的预训练目标不仅包括自监督的GLM自回归空白填充,还包括对一小部分Token进行的多任务学习(这一小部分的Token量占总量的5%),作者称这个任务为多任务指令预训练(Multi-Task Instruction Pre-Training,MIP),该任务包含语言理解、生成和信息提取等各种指令提示数据集。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









