






通过一个小案例来快速体验Pandas
1. Pandas数据结构
在 Pandas 库中,Series 和 DataFrame 是两个最核心的数据结构。它们的关系可以简单理解为:DataFrame 是由多个 Series 组成的。
让我用一个形象的比喻来解释:
-
Series → 就像 Excel 中的一列数据
-
DataFrame → 就像整个 Excel 表格,包含多列数据
什么是 Series?
Series 是一个一维的、带有标签的数组结构,可以存储任何数据类型(整数、字符串、浮点数、Python对象等)。关键特点:
一维结构:只有一行数据(但有多列?不,它只有一"列"概念)
Series既可以表示一行,也可以表示一列,这完全取决于上下文。但最常用、最自然的方式是将Series看作DataFrame中的一列。
什么是 DataFrame?
DataFrame 是一个二维的、表格型的数据结构,可以看作是由多个 Series 组成的字典(每个 Series 是一列)。
关键特点:
二维结构:有行和列
带有行索引和列名:既有行标签也有列标签
异构数据:不同的列可以是不同的数据类型
大小可变:可以动态添加/删除行列
带有索引:每个元素都有一个对应的标签(索引)
同构数据:通常所有元素是相同的数据类型(但不是强制要求)
2. 准备数据集
数据说明:历年各国gdp数据
数据资源已放置文章顶端,可点击下载
3. 数据分析
本演示基于Anaconda 数据分析平台,代码编写及效果呈现都使用 Jupyter Notebook
- 查看当前文件路径
import os
os.getcwd()

3.1 数据展示
- 导包并加载数据
import pandas as pd
# 我的数据文件放置在当前项目下jupyterdata下
df = pd.read_csv('./juyperdata/1960-2019全球GDP数据.csv', encoding='gbk', )
df # 显示全部数据

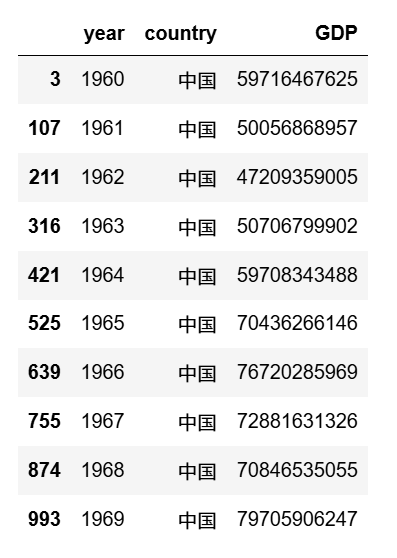
- 查询中国的GDP
china_gdp = df[df.country=='中国'] # df.country 选中名为country的列
china_gdp.head(10) # 显示前10条数据
- 将year年份设为索引
china_gdp = china_gdp.set_index('year')
china_gdp.head() # 默认显示前5条

3.2 图表展示
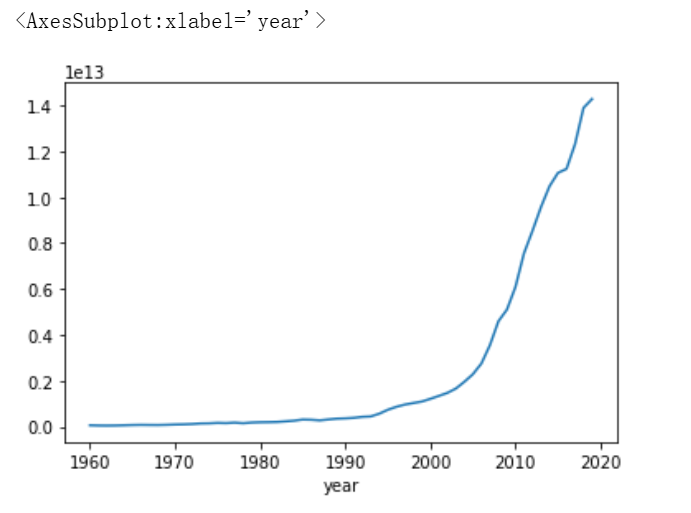
- 画出GDP逐年变化的曲线图
china_gdp.GDP.plot()
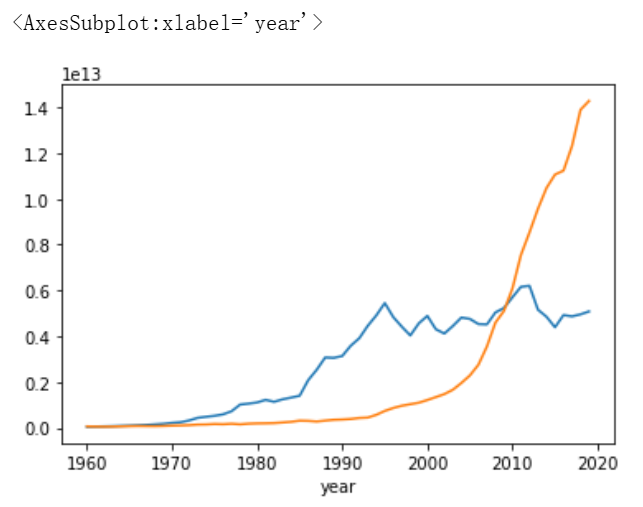
- 使用同样的方法画出日本的GDP变化曲线,和中国的GDP变化曲线进行对比
jp_gdp = df[df.country=='日本'].set_index('year') # 按条件选取数据后,重设索引
jp_gdp.GDP.plot()
china_gdp.GDP.plot()
3.3 复杂图标展示
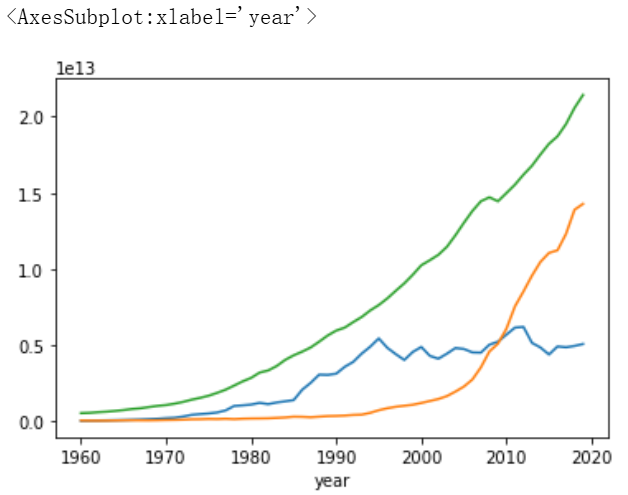
对比中美日三国GDP变化曲线
- 分别查询中国、美国、日本三国的GDP数据,并绘制GDP变化曲线、进行对比
china_gdp = df[df.country=='中国'].set_index('year')
us_gdp = df[df.country=='美国'].set_index('year')
jp_gdp = df[df.country=='日本'].set_index('year')
jp_gdp.GDP.plot()
china_gdp.GDP.plot()
us_gdp.GDP.plot()
- 设置图例
# 按条件选取数据
china_gdp = df[df.country=='中国'].set_index('year')
us_gdp = df[df.country=='美国'].set_index('year')
jp_gdp = df[df.country=='日本'].set_index('year')
# 出图并添加图例
jp_gdp.GDP.plot(legend=True)
china_gdp.GDP.plot(legend=True)
us_gdp.GDP.plot(legend=True)
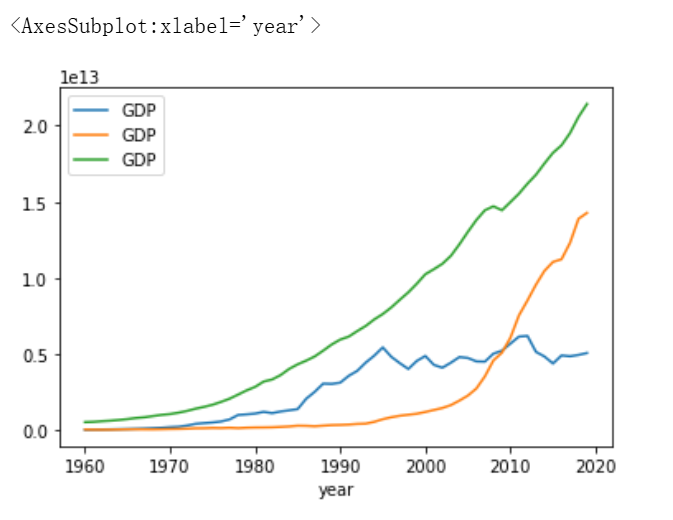
- 修改列名使图例显示为各国名称
# 按条件选取数据
china_gdp = df[df.country=='中国'].set_index('year')
us_gdp = df[df.country=='美国'].set_index('year')
jp_gdp = df[df.country=='日本'].set_index('year')
# 对指定的列修改列名
jp_gdp.rename(columns={'GDP':'日本'}, inplace=True)
china_gdp.rename(columns={'GDP':'中国'}, inplace=True)
us_gdp.rename(columns={'GDP':'美国'}, inplace=True)
# 画图
jp_gdp.japan.plot(legend=True)
china_gdp.china.plot(legend=True)
us_gdp.usa.plot(legend=True)
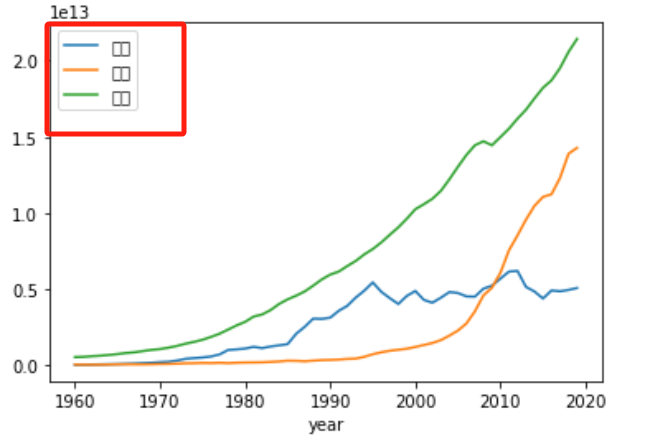
此刻我们发现名称显示不出来,这是因为中文问题,我们需要解决名称问题
3.4 解决中文显示问题
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
- Matplotlib 的默认行为
Matplotlib 默认使用英文字体
当遇到中文字符时,由于默认字体不包含中文字形,会显示为方块(□)或乱码- 字体回退机制
设置 [‘SimHei’] 告诉 Matplotlib:
首先尝试使用 SimHei(黑体)显示所有字符
如果某些字符在黑体中不存在,会回退到其他字体
由于黑体是完整的中文字体,能够正确显示中文
运行以上代码片段后,重新运行上面图表代码:修改列名使图例显示为各国名称、

显示可以正常显示了。
本文简单的进行了演示,如需了解更多知识,请查看专栏

如果有帮助到你,请点赞收藏


















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











