



目录
StringBuilder(最大到int最大值21亿) 36
红黑树(是二叉查找树,但是不是高度平衡的,条件:特有的红黑规则)(增删改查的性能都很好)... 69
Map的遍历方式(在Map里面找键实际上是找值,在键值对对象找键才是键)... 76
盘符名称+冒号
说明:盘符切换
举例:E:回车,表示切换到E盘
dir
说明:查看当前路径下的内容
cd目录
说明:进入单级目录(可以通过输入部分目录名称按tab来进行关联以提升速度)
举例:cd itheima
cd..
说明:回退到上一级目录
cd目录1\目录2\...
说明:进入多级目录
举例:cd itheima\JavaSE
cd\
说明:回退到盘符目录
cls
说明:清屏。
exit
说明:推出命令提示符窗口。
常见的进制以及不同进制在代码中的表现形式
二进制:代码以0b开头
十进制:前面不加任何前缀
八进制:代码中以0开头
十六进制:0~9和a~f组成—代码中以0x开头
种类:
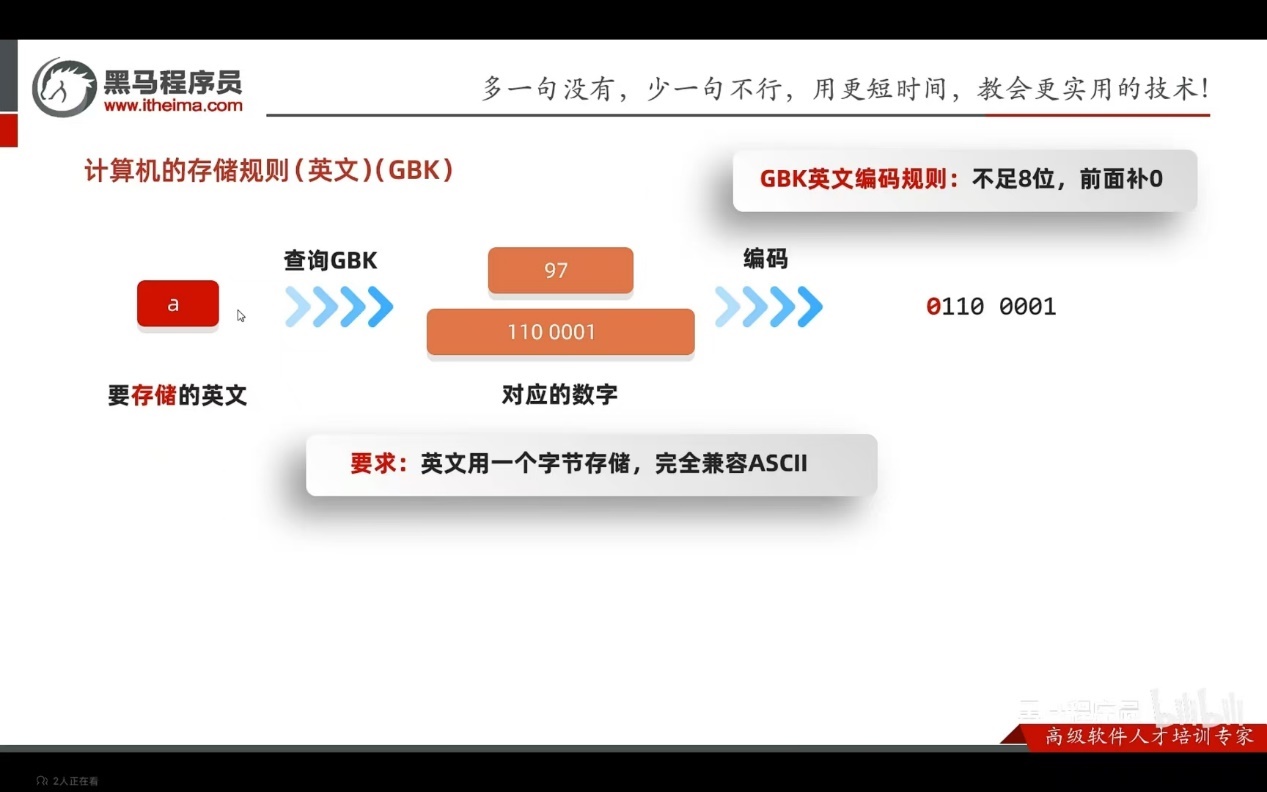
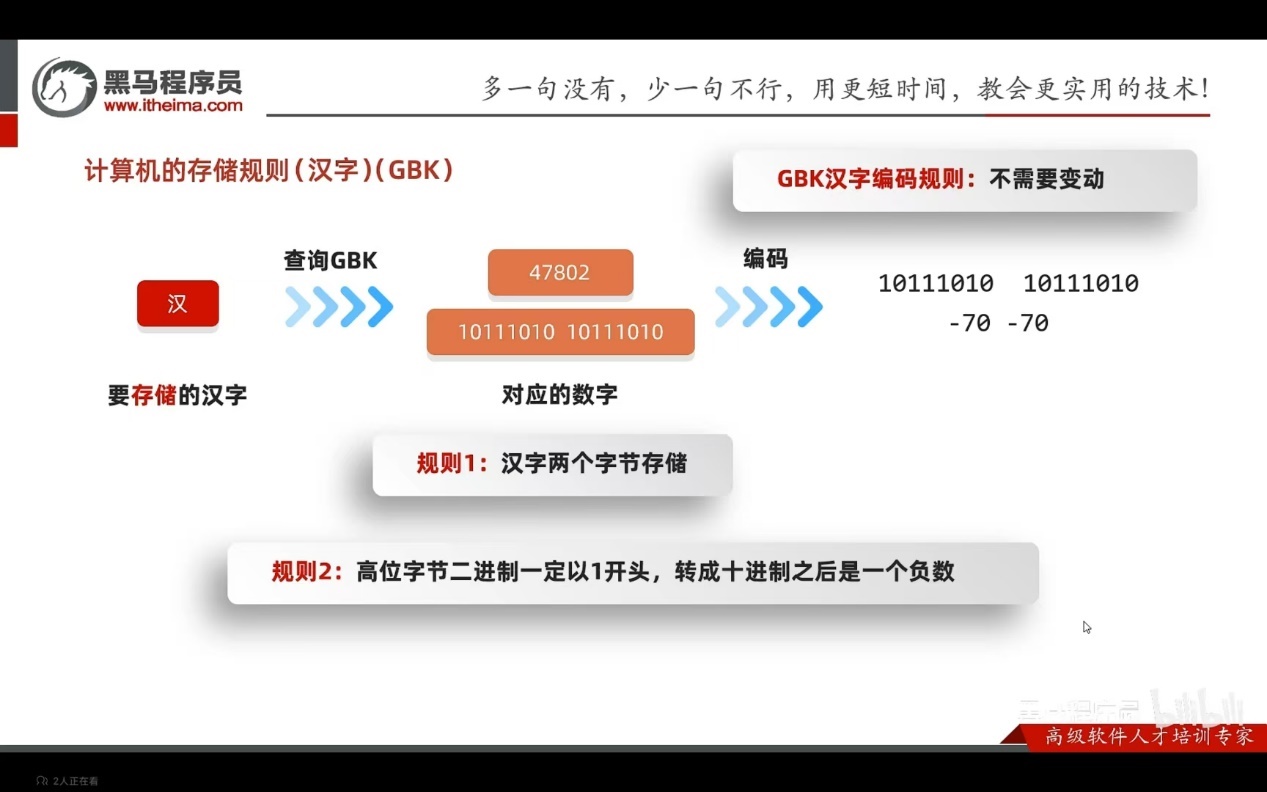
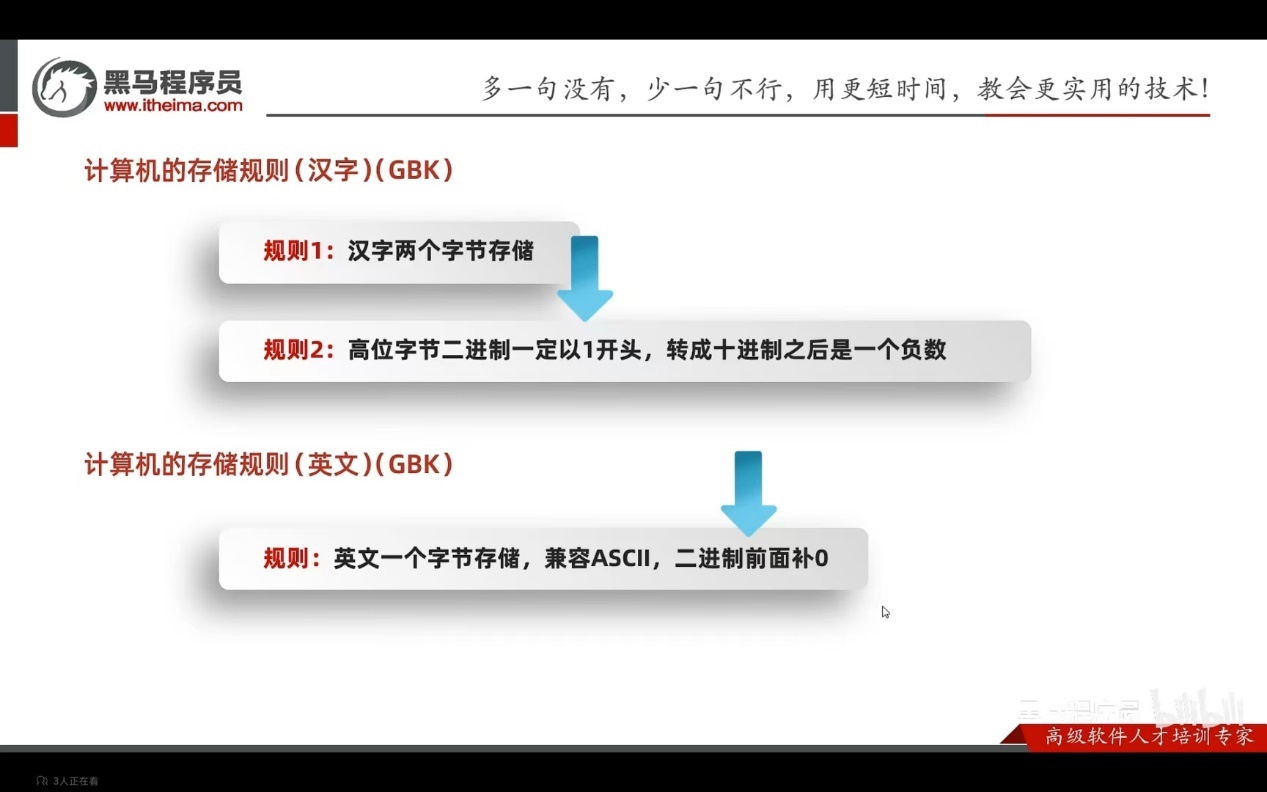
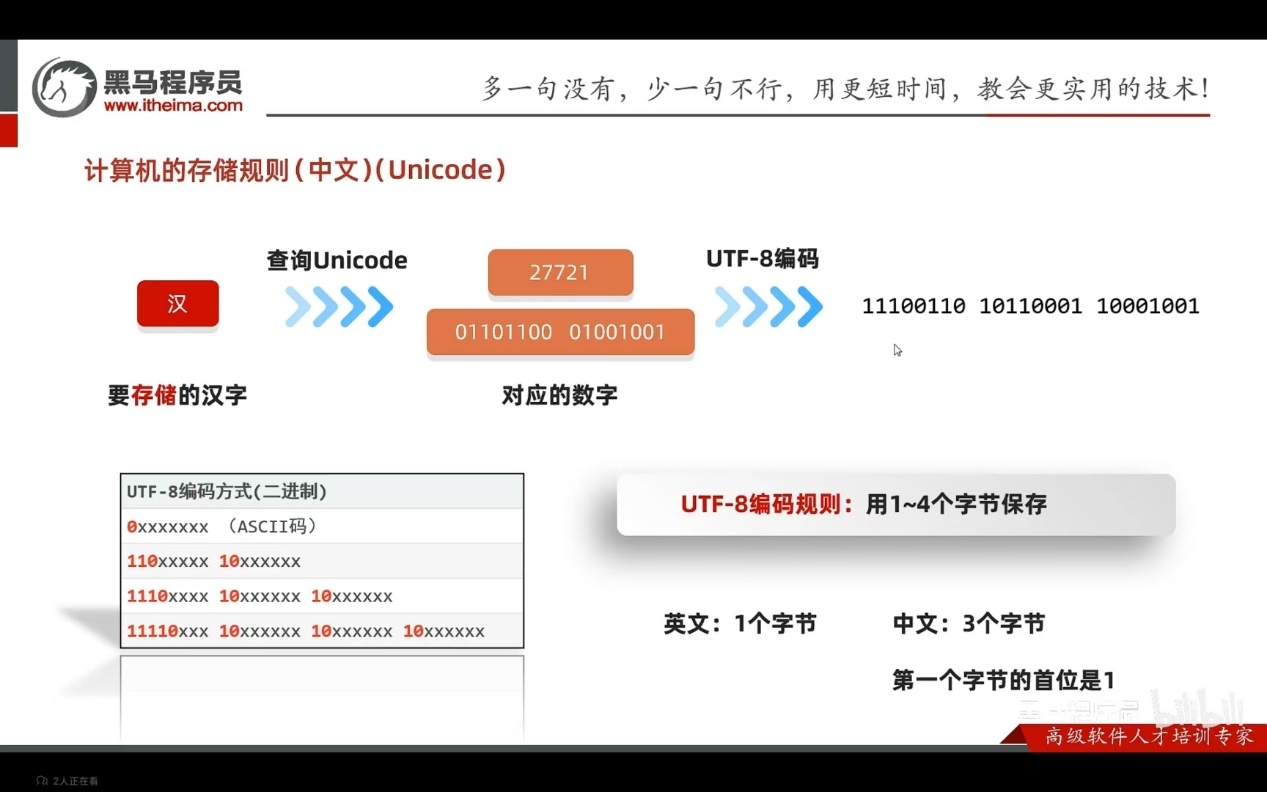
Text数据
数字:转二进制
字母:查询码表
汉字: 查询码表
Image图片:通过每一个像素点的RGB三原色来存储
黑白
灰度
彩色
- 计算机中的压缩呢采用光学三原色
- 分别为:红,绿,蓝.也成为RGB
- 可以写成十进制的表示形式.(255,255,255)
- 也可以写成16进制(FF,FF,FF)
Sound声音:对声音的波形图进行采样在进行存储
任意进制转十进制
公式:系数*基数的权次幂 相加
系数每一位上的数字
基数:当前进制的数字
权:从左往后,依次为0 1 2 3 4 5 …
十进制转其他进制
除基取余数
不断的除以基数(几进制,基数就是几)得到余数,直到商为0,再将余数到这拼起来即可.





Java是什么:
Java程序初体验
Java的安装目录:
1:bin:该路径下存放了各种工具命令。其最终比较重要的有:javac和java
2:conf:该路径下村返回了相关配置文件
3:include:该路径下存放了平台特定的头文件
4:jmods:该路径下存放了各种模板
5:legal:该路径下存放了各种模块的授权文档
6:lib:该路路径下存放了工具的一些补充JAR包
程序编写
Hello world案例编写:
1:用记事本编写程序
2:编译文件
3:运行程序
案例常见问题
1:中英文符号问题
2:单词拼写错误
环境变量
配置path环境变量的目的
我们想在任意目录下都可以打开指定软件.
就可以把软件的路径配置到环境变量中
Java可以做什么
三大使用平台:
JavaSE
Java语言的标准版,适用于桌面应用的开发,是其他两个版本的基础.
(桌面应用:用户只需要打开程序,程序的界面会让用户在最短的时间内找到他们需要的功能,同时主动带领用户万恒他们的工作并得到最好的体验,例如:计算器和坦克大战.但是Java编写桌面应用时运行较慢,而C语言和C++则运行较快)
学习目的:为今后要从事的javaEE的开发打基础
JavaME(凉了)
Java语言的(小型版),用于开发嵌入式电子设备(电视机-微波炉-照相机)或者小型移动设备手机)
JavaEE
Java语言的企业版,用于Web方向的网站开发.在这个领域,Java最牛.
应用领域:
1:桌面应用(各种税务管理软件,IDEA,Clion,Pycharm)
2:企业级应用开发(微服务,springcloud)
3.移动应用的开发(鸿蒙,Android,医疗设备)
4.科学计算(matlab)
5.大数据开发(Hadoop)
6.游戏开发(我的世界:mine craft)
1;用户量
2;适用面
3;与时俱进
4:自身特点
- 面向对象:根据你想得模板把东西创造出来
- 安全性,漏洞少
- 多线程:同时做多件事情
- 简单易用
- 开源:给源代码安装包
- 跨平台(操作系统):Java可以在任意的操作系统上运行
为什么Java可以跨平台
高级语言的编译运行程序方式
编程---编译---运行
编程:Java程序员写.Java代码,c语言程序员写.c代码,python程序员写的.py代码
编译:机器只认识0011的机器语言,把.java.c.py的代码做转化让机器语言认识的过程
编译型(c,产生新文件):全部解释
解释型(python,不产生新文件):读一行解释一行
混合型(Java),半编译,半解释
运行:让机器执行编译后的指令
JRE和JDK
JDK(Java development kit)
JVM(Java virtual machine):Java的虚拟机,真正运行java程序的地方
核心类库:Java已经写得好的东西
(必不可少的)
开发工具:java编译工具,Java运行工具,java调试工具,jhat内存分析工具…
JRE(Java Runtime Environment)
JVM
核心类库
运行工具
为什么要有注释?
概念:程序指定位置添加的说明性信息
分类:
单行注释://注释信息
多行注释:/*注释信息*/
文档注释:/**注释信息*/(暂时用不上)
Ps:注释内容不参与编译和运行,仅仅是对代码的解释说明.
不管单行注释还是多行注释都不要嵌套
概念:被Java赋予了特殊含义的英文单词
特点:
关键字的字母全都小写
常用的代码编辑器中,针对关键字都有特殊的颜色标记,非常直观
class(+类名):用于定义/创建一个类,类是Java最基本的组成单元,例如细胞
概念:告诉程序员数据在程序中的书写格式
分类:
整数类型:不带小数点的数字,如:666,-88
小数类型:带小数点的数字,如:13.14,-5.21
可以直接书写
字符串类型:用双引号括起来的内容,如:”HelloWorld”,”黑马程序员”
字符类型:用单引号括起来的,内容只能有一个,如:’A’,’0’,’我’
布尔类型:布尔值,表示真假,只有两个值:true/false
空类型:一个特殊之,空值,值是:null
扩展点:特殊字符
\t:制表符
在打印的时候,会把前面的字符串的长度补齐到8,或者8 的整数倍.最少补一个空格,最多补8个空格
概念:在程序执行过程中,其值有可能发生改变的量(数据)
使用场景:
当某个数据经常发生改变时,我们也可以用变量储存.当数据变化时,只需要修改变量里面的记录的值即可.
重复使用某个值
变量范围属于当前大括号范围的,超出了当前大括号就用不到了
定义格式:
数据类型(为空间中存储的数据,加入类型(限制):整数,小数,) 变量名(为空间(小箱子)起的名字) = 数据值(存在空间里的数值);
数据类型
整数:int
浮点数:double
变量的使用方式:
- 输出打印
- 参与计算
- 修改记录的值
注意事项:
- 只能存在一个值
- 变量名不允许重复定义
- 一条语句可以定义多个变量
- 变量在使用之前一定要赋值
- 变量的作用范围
Java的基础语法
数据类型
基本数据类型
整数:
Byte: -128~127内存占用:1
Short: -32768~32767内存占用:2
Int()默认): ~2147483648~2147483647(十位数) 内存占用:4
Long: -9223372036854775808~9223372036854775807(19位数) 内存占用:8
浮点数
Float: -3.401298e-38到3.402823e+38内存占用:4
Double(默认): -4.9000000e-324到1.797693e+308内存占用:8
字符
Char0-65535内存占用:2
布尔
Boolean: true/false内存占用:1
引用数据类型
标识符(变量名)
键盘录入(数据值)
小结:
Java语言的数据类型分为:引用数据类型,基本数据类型
基本数据类型分为四类和八种
整数
浮点数
字符
布尔
Byte的取值范围
整数和小数取值范围大小
Double>float>long>short>byte
Long类型变量:需要加入L标识(大小写都可以)
Float类型变量:需要加入F表示(大小写都行)
标识符:
概念:就是给类,方法,变量等起的名字.
命名规则:
硬性要求:
- 由数字,字母,下划线(_)和美元符$组成
- 不能以数字开头
- 不能是关键字
- 区分大小写
软性要求:
- 小驼峰命名法:方法,变量
规范1:标识符是一个单词的时候,全部小写
例如:name
规范2:标识符是由多个单词组成的时候,第一个单词首字母小写,其他单词首字母大写.
规范:firstName
- 大驼峰命名法
规范1:标识符是一个单词的时候首字母大写
范例:Student
规范2:标识符有多个单词组成的时候,每个单词的首字母大写
范例2:GoodStudent
见名知意
键盘录入:
介绍:java帮我们写好了一个类Scanner,这个类就可以接受键盘输入的数字.
步骤:
- 导包—Scanner这个类在哪
Import java.util.Scanner;导包的动作必须写在类定义的上边
- 创建对象---表示我要开始用Scanner这个类了
Scanner sc =new Scanner(System.in);
以上这个格式里面,只有sc是变量名,可以变,其他的都不允许变.
- 接受数据—真正开始干活了
Int I = sc.nextInt();
以上这个格式里面,只有是变量名,可以变,其他的都不允许变.
IDEA(Intellij IDEA):适用于Java语言开发的集成环境,他是业界公认的目前用于Java程序开发最好的工具.
集成环境:把代码的编写,编译,执行,调试等多种功能综合到一起的开发工具
IDE项目结构介绍(大小依次变小)
- project(项目)-微信软件
- module(模块)-消息,通讯录,发现,我
- 包(package):文件夹
- 类(class)
Psvm/main :快速生成public static void main(String[] args){}
Sout:快速生成:System.out.println()
IDEA中类相关操作
类:
- 修改类名
- 删除类
- 新建类
模块
- 新建模块
- 删除模块
- 修改模块
- 导入模块
运算符和表达式
运算符
概念:对字面量或者变量进行操作的符号
类别:
- 算数运算符
小学运算:+-*/,
%取模,取余
- 自增自减运算符
- 赋值预算符
- 关系运算符
- 逻辑运算符
- 三元运算符
表达式
概念:用运算符把字面量或者变量连接起来,符合java语法的句子就可以称为表达式.不同运算符连接的表达式体现的市不同类型的表达式
Int a = 10;
Int b =20;
Int c = a + b;
+:运算符(算数运算符)
a + b 是表达式(算数表达式)
“+”操作的三种情况
数字相加
数字进行运算时,数据类型不一样不能运算,需要转出一样的,才能运算
类型转换分类
隐式转换(自动类型提升) 取值范围小的→取值范围大的数值
规则:
取值范围显得,和取值范围大的进行计算,小的会提升为大的,在进行运算
Byte short char三种类型的数据在运算的时候,都会先提升为int,在进行运算
小结:
取值范围:
Double>float>long>short>byte
什么时候转换
数据类型不一样,不能进行计算,需要转出一样的才可以进行计算.
规则:
取值范围显得,和取值范围大的进行计算,小的会提升为大的,在进行运算
Byte short char三种类型的数据在运算的时候,都会先提升为int,在进行运算
- 强制转换:取值范围大的→取值范围小的数值
如果把一个取值范围大的数值,赋值给取值范围小的变量是不允许直接赋值的.如果一定要这么做就需要加入强制转换.
格式:
目标数据类型 变量名 = (目标数据类型) 被强制转换的数据;
字符串相加(没有- * /)
- 当”+”操作中出现字符串时,这个”+”是字符串连接符,而不是运算符了.会将前后的数据进行拼接,并产生一个新的字符串.
- 连续进行”+”操作时,从左到右逐个执行.
- 1 + 99 +”年黑马” = “100年黑马”
字符相加
- 当字符+字符/数字的时候,会把字符通过ASII码表查询到对应的数字再进行计算
- 自增自减运算符
- 自增(减)运算符
符号:++/--
作用:加(变量的值加(减)1)
注意事项:++和—即可以放在变量的前边,也可以放在变量的后边.只要单独写一行那么作用一样.
Int a =10;
a++;或者++a
System.out.println(a)
参与计算
- Int a =10;
Int b =a++;
- int a =10;
int b =++a;
- 赋值运算符
- 符号
= :赋值
+=: a + = b,将a+b的值给a(下同理)
-=
*=
/=
%=
注意事项:扩展的赋值运算符隐含了强制类型转换
- 关系运算符(比较运算符)
符号:
==:判断两边是否相等,成立为true,不成立为false
!=:判断两边是否不等,成立为true,不成立为false(下同理)
<
<=
>
>=
注意事项;
关系运算符的结果都是boolean类型,要么true要么false.把不要把”==”写成=
- 逻辑运算符
&
作用:逻辑与(且)
并且,两边都为真,结果才是真
|
逻辑或
都懂
^
逻辑异或
相同false,不同为true
!
逻辑非
取反
- 短路逻辑运算符
为什么要有短路逻辑运算符
验证一个不通过的话后续步骤无需验证
符号
&&
||
注意事项:
&,|,无论左边如何,右边都要执行
&&,||如果左边能确定整个表达式的结果,右边不执行
最常用的逻辑运算符:&&,||,!
- 三元运算符(三元表达式)
需求:定一个变量记录两个整数的较大值
格式:关系表达式?表达式1:表达式2;
范例:求两个数的较大值
a >b ? a : b
计算规则:
首先计算关系表达式的值
如果值为true,表达式1的值就是运算的结果
如果值为false,表达式2的值就是运算的结果
- 运算符优先级
小括号优先于所有
原码,反码,补码
原码:十进制数据的二进制表现形式,最左边是符号位,0为正,1为负
弊端:正数没有任何问题,但是负数就是错的与实际运算方向相反
反码:正数的补码反码是其本身,负数的反码是符号位保持不变,其余位取反(为了解决原码不能计算负数的问题而出现的)
弊端:计算结果不跨0可以,跨0则会差1
补码:正数的补码是其本身,负数的补码是在其反码的基础上+1(计算机上的储存方式)
目的:解决负数的计算跨0的问题而出现的.
计算规则: 正数的补码是其本身,负数的补码是在其反码的基础上+1
另外补码还能多记录一个特殊的值-128,该数据在一个字节下,没有原码和反码
注意点:计算机中的储存和计算都是以补码的方式进行的.
&:逻辑与
0为false,1为true
|:逻辑或
0为false,1为true
<<:左移
向左移动,低位补0
>>:右移
向右移动,高位补0或1
>>>:无符号右移
向右移动,高位补0
顺序结构
Java程序默认的执行流程,按照代码的先后顺序,从上到下依次执行.
分支结构
If:判断
原因:
执行流程:
- 首先计算关系表达式的值
- 如果关系表达式的值为true就执行语句体
- 如果关系表达式的值为false就不执行语句体
- 继续执行后面的其他语句
第二种格式:
- 首先计算关系表达式的值
- 如果关系表达式的值为true就执行语句体1
- 如果关系表达式的值为false就执行语句体2
- 继续执行后面的其他语句
第三种格式
- 首先计算关系表达式1的值
- 如果为true就执行语句体1;如果为false就计算关系表达式2的值
- 如果为true就执行语句体;如果为false就计算关系表达式3的值
- …
- 如果所有关系表达式结果都尉false,就执行语句体n + 1.
Switch:选择
执行流程:
- 首先计算表达式的值
- 依次和case后面的值比较,如果有对应的值,就会执行相应的语句,如果遇到break就会结束
- 如果所有的case后面的值和表达式的值都不匹配,就会执行default里面的语句体,然后结束整个switch
格式说明:
- 表达式(将要匹配的值)取值为byte, short ,int ,char ,JDK5以后可以是枚举,JDK7以后可以是String.
- case:后面跟的是要和表达式进行比较的值(被匹配的值).
- break:表示中断,结束的意思,用来结束switch语句
- default:表示所有情况都不匹配的时候,就该执行该处内容,和if语句的else相似
- case后面的值只能是字面量,不能是变量
- case给出的值不允许重复
其他四个小知识点:
default的位置和省略
case穿透
switch新特性
switch和if的第三种格式和各自的使用场景
快捷生产多行注释
Ctrl + shift+/
快捷生成单行注释
Ctrl + /
循环结构
概念:
重复的做某件事
具有明确的开始和停止标记
分类:
For(100.fori)
执行流程
- 执行初始化语句(只执行一次)
- 执行条件判断语句,看其结果时true还是false
如果是false,循环结束
如果是true,执行循环体语句
- 执行条件控制语句
- 回到2继续实行条件判断语句
While
初始化语句只执行一次
判断为true,循环继续
判断为false,循环结束
对比:
相同点:运行规则一样
区别:
For循环中,控制循环的变量,因为归属for循环的语法结构中,在for循环结束后,就不能再次被访问到了(但是for也可以拆出来)
知道循环次数或者循环范围时使用
While循环中,控制循环的变量,对于while循环来说不归属其语法结构中,在while循环结束后,该变量还可以继续使用
不知道循环次数和范围,只知道循环的结束条件
(以上重点掌握)
Do…while(先用后付)
格式:
初始化语句;
do{
循环体语句;
条件控制语句;
}while(条件判断语句);
- 无限循环
- 跳转控制语句
在循环过程中,跳到其他语句上执行
- 练习
获取随机数
Java已经帮我们写好了一个类叫做Random,这个类就可以生成一个随机数.
参考Scanner的学习数据
- 导包(导包的动作必须写在类定义上面)
Import java.util.Random;
- 创建对象(表示我要开始用Random这个类了)
Random r = new Random();
上面这个格式里面,只有r是变量名,可以变,其他的都不允许变
- 生成随机数
Int number = r,nextInt(随机数的范围);
上面这个格式里面,只有number是变量名,可以变,其他的都不允许变.
介绍:一个容器可以用来存贮同种类型的多个值
- 数组容器在存储数据时,需要结合隐式转换考虑
建议:容器类型和存储数据类型一致
数组的定义和静态初始化
数组的定义:
- 数据类型[]数组名
例如:int [] array
- 数据类型 数组名[]
Int array[]
数组的初始化
初始化:在内存当中为数组容器开辟空间,并将数据存入到容器的过程中.
方式1:静态初始化
格式:
数据类型[]数组名=(new 数据类型[]){元素1,元素2,元素3…};
范例:int[]array = new int[]{11,22,33};
Double[]array =new double[]{11.1,22.2,33.3};
数组的地址值就是数组在内存中的位置
数组的元素访问
格式:数组名[索引];
索引:
下标或者角标
特点:从0开始,逐个+1增长,连增不间断
数组的遍历:
将数组中所有的内容取出来,取出来之后可以(打印,求和,判断..)
遍历是指取出数据的过程,不要局限的理解,遍历就是打印
数组的动态初始化
概念:动态初始化只指定数组的长度,由系统为数组分配初始值
格式:
数据类型[]数组名==new 数据类型[数组长度]
动态初始化和静态初始化的区别
- 动态初始化只指定数组的长度,由系统为数组分配初始值
- 静态初始化:手动指定数组元素,系统会根据元素个数,计算数组长度.
常见问题:
1-当访问数组中不存在的索引,就会引发索引越界问题
数组的常见操作
- 求最值
- 求和
- 交换数据
- 打乱数据
Java的内存分配
- 栈:方法运行时使用的内存,比如main方法运行,进入方法栈中执行
- 堆
存储对象或者数组的,new来创建的,都存储在堆内存
- 方法区(后来拆了,变成了元空间但是功能有的放在了堆有的放在了元空间里)
存储运行的class文件
- 本地方法栈
Jvm在使用操作系统功能的时候使用,和我们开发无关
- 寄存器
给cup使用,和我们开发无关.
什么是方法:
程序当中最小的执行单元
实际开发中,什么时候会用到方法
重复的代码.具有独立功能的代码可以抽取到方法中
好处
提高代码复用性
提高代码的可维护性
格式:
把一些代码打包到一起,用到的时候就调用
方法定义:
把一些代码打包到一起,该过程称为方法的
定义
格式:
- 最简单
Public static void 方法名(){
方法体(就是打包起来的代码)
}
- 带参数的
Public static void 方法名(参数1,参数2){…}
- 带返回值方法的定义和调用
方法的返回值其实就是方法运行的最终结果.
public static 返回值类型 方法名(参数){
方法体;
return 返回值;
}
调用:
方法定义后并不是直接运行的,需要手动调用才能执行,该过程称为方法调用.
- 方法名():
- 方法名(参数1,参数2)
- 1.直接调用:方法名(实参);
2.赋值调用:整数类型 变量名 = 方法名(实参);
3.输出调用:System.out.println(方法名(实参));
小技巧:
干嘛-------方法体
咋样才能完成---------形参
注意事项:
- 方法不调用就不执行
- 方法与方法之间是平级关系,不能互相嵌套定义
- 方法的编写顺序和执行顺序无关
- 方法的返回值类型为void,表示该方法没有返回值,没有返回值的方法可以省略return不写.如果要写return后面不能跟具体数据.
- Return语句的下面,不能编写代码,因为永远执行不到,属于无效代码
Return
- 方法没有返回值: 可以省略不写.如果书写,表示方法结束方法
- 方法有返回值:必须要写.表示结束方法和返回结果
- 在同一个类中,定义了多个同名的方法,这些同名的方法具有同种的功能.
- 每一个方法具有不同的参数类型或参数个数,这些同名的方法,就构成了重载关系
- 简单记忆:同一个类中方法名相同,参数不同的方法.与返回值无关
- 方法调用的基本原理
压子弹先进后出
基本数据类型:
数据值是储存在自己空间中的
特点:赋值给其他变量,也是赋的真实的值
传递的是真实的数据
引用数据类型
数据值是存储在其他空间中,自己空间储存的是地址值.
特点:赋值给其他变量,赋的地址值
传递的是地址值
- 方法传递基本数据类型的内存原理
- 方法传递引用数据内存的内存原理
静态初始化:
格式:数据类型[][]数组名 = new 数据类型[][]{{元素1,元素2,元素3},{元素1,元素2,元素3}};
简化格式:数据类型[][]数组名 = {{元素1,元素2,元素3},{元素1,元素2,元素3}};
动态初始化
格式: 数据类型[][]数组名 = new 数据类型[m][n]
M表示这个二维数组,可以存放多少个一维数组
N表示每一个一维数组,可以存放多少个元素
二维数组的内存图
面向:拿,找
对象:能干活的东西
面向对象编程:拿东西过来做对应的东西
设计对象并使用
类和对象
类(设计图):是对类共同特征的描述
如何定义类:
Public class 类名{
- 成员变量(代表属性,一般是名词)
- 成员方法(代表行为,一般是动词)
- 构造器
- 代码块
- 内部类
}
对象:是真实存在的具体东西
在java中必须先设计类,才能或的对象
类的几个注意事项
- 用来描述一类事物的类,叫做javabean类.
在javabean类中,是不写main方法的
- 在以前,编写main方法的类,叫做测试类
我们可以在测试类中创建javabean类的对象并精心赋值调用
注意:
- 类名首字母建议大写,需要见名知意.驼峰命名
- 一个javabean中可以定义多个class类,且只能一个类是public修饰,而且public修饰的类名必须成为代码文件名
- 实际开发中建议还是一个文件定义一个class类
- 成员变量的完整定义格式:
修饰符 数据类型 变量名称 = 初始化值;一般无需指定初始化值,存在默认值
封装(三大特征之一)
对象代表什么,就得封装对应数据,并提供数据对应行为
Private关键字
- 是一个权限修饰符
- 可以修饰成员(成员变量,成员方法)
- 被private修饰的成员只能在本类中才能访问
- 针对于private的成员变量,如果需要被其他类使用,提供相应的操作
- 提供”setXxx(参数)”方法,用于给成员变量赋值,方法用public修饰
- 提供”getXxxx()”方法,用于获取成员变量的值方法用public修饰
This关键字
就近原则
System.out.println(age);
System.out.println(this.age);
This的作用?
可以去别成员变量和局部变量
This的本质和内存图
也叫做构造器.构造函数
作用:在创建对象的时候给成员变量进行初始化的
特点:
- 方法名与类名相同,大小写也要一致
- 没有返回值类型,连void都没有
- 没有具体的返回值(不能由return带回结果数据)
执行时机
- 创建对象的时候由虚拟机调用,不能手动调用构造方法
- 每创建一次对象,就会调用一次方法
注意事项
- 构造方法的定义
- 如果没有定义构造方法,系统将给出一个默认的无参数构造方法
- 如果定义了构造方法,系统将不再提供默认的构造方法
2-构造方法的额重载
- 带参构造方法,和无参构造方法,二者方法名相同,但是参数不同,这就叫做构造方法的重载
3-推荐使用方式
- 无论是否使用,都手动书写无参构造方法,和带有全部参数的构造方法
- 类名需要见名知意
- 成员变量使用private修饰
- 提供至少两个构造方法
- 无参构造方法
- 带全部参数的构造方法
4-成员方法
- 提供每一个成员变量对应的setXxx()/getXxx()
- 如果还有其他行为记得写上
一个对象的内存图
多个对象的内存图
两个变量指向一个对象的内存图
This的内存原理
作用:区分局部变量和成员变量
本质:所在方法调用的地址值
基本数据类型和引用数据类型的区别
基本数据类型:
数据储存在自己的空间当中
特点:
赋值给其他变量也是赋的真实的值
引用数据类型
数据是存储在其他空间中,自己空间中存储的是地址值.
特点:
赋值给其他变量,赋的是地址值
局部变量和成员变量的区别
局部变量
成员变量
Ctrl + p 会展示参数
Alt + insert 构造方法
Ctrl + Alt+l 格式化
Ctrl + m生成方法
Ctrl + enter :显示要填入的参数类型
Alt+insert 构造函数重写方法
Ctrl + f:搜索
AIP(应用程序编程接口)
别人写好的东西,我们不需要自己编写,直接使用即可
API:目前是JDK中提供的各种功能的java类
这些将底层的实现封装了起来,我们不需要这些类是如何实现的,只需要学习这些类如何使用即可
API帮助文档:
帮助开发人员更好的使用AIP和查询API的一个工具
String一旦赋值无法改变
创建String对象的两种方式
- 直接赋值
- New
构造方法
- public String()
创建空白字符串,不含任何内容
- public String(String original )
根据传入的字符串,创建字符串对象
- public String(char[] chs)
根据字符数组,创建字符串对象
- public String (byte[] chs)
根据字节数组,创建字符串对象
Java的常用方法
比较
基本数据类型的比较的是数据值
引用数据类型比较的是地址值
字符串比较
Boolean equals方法(要比较的字符串)
完全一样结果才是true ,否则为false
Boolean equalsIgnoreCase(要比较的字符串)
忽略大小写
遍历字符串
- Public char charAt(int index): 根据索引返回字符
- Public int length():返回字符串的长度
- 数组长度:数组名.length
- 字符串长度:字符串对象.length()
裁剪:
String substring(int beginIndex, int endIndex)
包头不包尾,包左不包右
String substring(int beginIndex)
表示截取到末尾
替换:
String replace(旧值,新值)
注意点:只有返回值才是替换以后的结果
StringBuilder(最大到int最大值21亿)
概述:可以看作一个容器,创建之后里面的内容是可变的
作用:提高字符串的操作效率
构造方法:
- public StringBuilder()
无参构造:
创建一个空白可变字符串对象,不包含任何内容
- public StringBuilder(String str)
有参构造:根据字符串内容,来创建可变字符串对象
成员方法:
Public StringBuilder append(任意类型)
添加数据,返回对象本身
Public StringBuilder reverse()
反转容器中的内容
Public int length()
返回长度(字符出现的个数)
Public String toString()
通过toString就可以实现把StringBuilder转换为String
概述: StringJoiner和StringBuilder一样,也可以看成一个容器,创建之后里面的内容可变的.
作用:提供字符串的运行操作效率,而且代码特别简洁,但是目前市场上很少有人要.
Jdk8出现的
构造方法:
public StringJoiner (间隔符号)
创建一个StringJoiner对象,指定拼接时的间隔符号
Public StringJoiner(间隔符号,开始符号,结束符号)
创建一个StringJoiner对象,指定拼接时的间隔符号,开始符号,结束符号
成员方法:
- public StringJoiner add(添加内容)
添加数据,并返回对象本身
- public int length()
返回长度(出现字符的个数)
3- Public String toString()
返回一个字符串(该字符就是拼接之后的结果)
- 字符串储存的内存原理
- 直接赋值会复用字符串常量池中的
- New则不会复用
2-==号比较的到底是什么
- 基本数据类型比较数据值
- 引用数据类型比较地址值
- 字符串拼接的底层原理
- 如果没有变量参与,都是字符串相加,编译之后就是拼接之后的结果,会复用串池中党的字符串
- 如果有变量参与,每一行拼接的代码,都会在内存中创建新的字符串,浪费内存
- StringBuilder提高效率原理图
- 所有要拼接的内容都会往StringBuilder中放,不会创建很多无用的空间,节约内存
- StringBuilder源码分析
- 默认创建一个长度为16的字节数组
- 添加内容小于16,直接存
- 添加的内容大于16,会扩容(原来容量的*2+2)
- 如果扩容之后还不够,以实际长度为准
// 为方便统计,将字符串中的字母都转为小写
line = line.toLowerCase();
// 如果是数字0开头,返回false
if (id.startsWith("0")) {
return false;
}
集合和数组对比
不同点:
- 数组长度固定,集合长度可变
- 数组可以存基本数据类型和引用数据类型,集合可以存引用数据类型,村基本数据类型则需要转变为包装类
基本数据类型所对应的包装类
byte Byte
short Short
char Charcter
int integer
long Long
float Float
boolean Boolean
alt + enter
自动创建方法
personID.startsWith(“0”);
是不是以0开头
表示静态,是java中的一个修饰符,可以修饰成员方法,成员变量
注意事项
1-静态方法只能访问静态变量和静态方法
2-非静态方法可以访问所有
- 静态方法中是没有this关键字
- 非静态跟对象有关
- 被static修饰的成员变量,叫做静态变量
特点:
被该类所有对象共享
优先于对象而出现的伴随着类的加载而加载
不属于对象,属于类
调用方式:
类名调用(推荐)
对象名调用
- 被static修饰的成员方法,叫做静态方法
特点:
多用在测试类和工具类当中
Javabean类中很少会使用
调用方法
类名调用(推荐)
对象名调用
Javabean:
描述一类事物的类.例如student,teacher.dog,cat
测试类
用来检查其他的类是否书写正确,带有main方法的类,是程序的入口.
工具类:
帮我们做一些事情,但是不描述任何事物的类
- 见名知意
- 构造方法私有化
- 方法都定义为静态的方便调用
重新认识main方法
Public:权限修饰符
被Jvm调用,访问权限足够大
Static:
被JVM调用,不用创建对象,直接类名访问
因为main方法是静态的,所以测试类中其他方法也是需要静态的
Void:
被JVM调用,不需要给虚拟机返回值
Main:
一个通用的名称,虽然不是关键字,但是被JVM识别
String[] args:以前用于接收键盘录入数据的,现在没用
继承(三大特征之一)
Java中提供一个关键字extends,用这个关键字,我们可以让一个类和另一个类建立起继承关系
Student称为子类(派生类),person称为父类(基类或超类).
好处:
- 可以把多个子类中重复的代码抽取到父类当中,让子类和父类之间产生父子关系,提高代码的复用性
- 子类可以在父类的基础之上,增加其他的功能,使子类更强大
什么时候用:
类与类之间,存在相同的内容,并满足子类是父类的一种,就可以考虑使用继承,来优化代码.
格式:
Public class 子类 extends 父类{}
特点:
子类可以继承父类的属性和行为,子类可以使用
子类可以在父类的基础之上新增其他功能,子类更强大
子类到底可以继承父类中的那些内容(内存图/内存分析工具)
构造方法:
Public不能
Private不能
成员变量:
Public 能
Private 能
成员方法:
Public 能
Private 不能
虚方法表:
非static
非private
非finial
继承的特点:
Java只支持单继承(一个子类仅支持一个直接父类),不支持多继承(一个子类不能继承多个父类),但是支持多层继承
每一个类都是直接或者间接的继承于Object
继承中:成员变量的访问特点
就近原则:谁离我近,我就用谁
出现重名了的成员变量怎么办
Name
This.name
Super.name
继承中:成员方法的访问特点
就近原则:谁离我近,我就用谁
Super调用访问父类
方法的重写
当父类的方法不能满足子类现在的需求的时候,需要进行方法重写
格式:
在继承体系中,子类出现了和父类一模一样的方法声明,我们就称子类这个方法是重写的方法.
@Override重写的注解
- @Override是放在重写后的方法上,校验子类重写时语法是否正确
- 加上注解后如果有红色波浪线,表示语法错误
- 建议重写方法都加@Override注解,代码安全,优雅
本质
如果重写就会覆盖父类的对应虚方法
注意事项和要求
- 重写方法的名称,形参列表必须与父类一致
- 子类重写父类方法时,访问权限必须大于等于父类(暂时了解:空着不写<protected<public)
- 子类重写父类方法时,返回值类型子类必须小于等于父类
- 建议:重写的方法尽量和父类保持一致
- 只有被添加到虚方法表里面的方法才能被重写
- 私有方法不能被重写
- 子类不能重写父类的静态方法如果重写会报错
继承中:构造方法的访问特点
- 父类中的方法时不会被子类继承的
- 子类中所有的构造方法默认先访问父类中的无参构造,在执行自己的
Why:
- 子类在初始化时,会用到父类中的数据,如果父类没有完成初始化,子类将无法使用父类的数据
- 子类初始化之前,一定要调用父类构造方法先完成父类数据空间的初始化.
怎么调用父类的构造方法
- 子类构造方法第一行语句默认都是:
Super(),不写也存在,且必须在第一行.
This,super的使用总结
- this:理解为一个变量,表示当前方法调用者的地址值;
多态(三大特征之一)
什么是多态:
同种类的对象表现出的不同形态
表现形式
父类类型 对象名称 = 子类对象
多态前提
- 有继承/实现关系
- 父类引用指向子类对象
- 有方法重写
好处:
使用父类类型作为一个形参,可以接受所有的子类对象
多态调用成员的特点:
- 变量调用:编译看左边,运行也看左边
- 方法调用:编译看左边,运行看右边
多态的优势和弊端
优势:
- 在多态的形势下,右边对象可以实现解耦合(可以接受所有子类对象),便于拓展和维护.
Person p =new Student();直接改对象.
p.work();//业务逻辑发生改变时,后续代码无需修改
- 定义一个方法的时候,使用父类类型作为参数,可以接收所有子类对象,体现多要的扩展性和便利
弊端:
不能使用子类的特有功能
引用数据类型的数据转换有几种’
- 自动类型转换
- 强制类型转换
解决问题:
可以转换成真正的子类类型,从而调用子类独有功能
转换类型与真实对象不一致会报错
转换的时候用instanceof关键字进行判断
就是文件夹.用来管理各种不同功能的java类,方便后期代码维护
命名规则:公司域名反写 + 包的作用 + 包名,需要全部英文小写,见明知意.
使用其它类的规则
1-使用其他类时,需要使用全类名.
Public class Test{
Psvm
Com.itheima.domain.Student s =new Com.itheima.domain.Student();
}
Import com.itheima,domain.Student;
Public class Test{
Psvm
Student s =new Student();
}
2-使用同一个包中的其他类时,不需要导包
- 使用java.lang包中的类时,不需要导包
- 其他情况都需要导包
- 如果同时使用两个包中的同名类,需要用全类名
最终,不可被改变
修饰对象
方法
表示该方法时最终方法,不能被重写
类
表示该类时最终类,不能被继承
变量
叫做常量,只能被赋值一次
常量:
实际开发中,常量一般作为系统的配置信息,方便维护,提高可读性.
命名规范:
单个单词:全部大写
多个单词:全部大写,单词之间用下划线隔开
细节:
Final修饰的变量时基本数据类型:那么常量存储的数据值不能发生改变
Final修饰的变量是引用数据类型:那么变量存储的地址值不能发生变化,对象内部的可以改变
定义:
用来控制一个成员能够被访问的范围
可以修饰成员变量,方法,构造方法,内部类
分类
有四种作用范围由小到大(private <空着不写<protected<public)
Private: 私房钱,只能自己用
默认: 只能在本包中用
Protected: 其他包里面的子类也能用
Public 所有的地方都能用
权限修饰符的使用规则
实际开发中,一般只用private和public
- 成员变量私有
- 方法公开
- 特例:如果方法中的代码是抽取其他方法中共性代码,这个方法一般也私有.
局部代码块
提前结束变量的周期
构造代码块
抽取构造方法中的重复代码
先于构造方法运行
静态代码块
格式: static{}
特点:需要通过static关键字修饰,随着类的加载而加载,并且自动触发,只执行一次
使用场景:在类加载的时候,做一些数据初始化的时候使用
抽象方法:
将共性的行为(方法)抽象到父类之后.由于没一个子类执行的内容不一样,所以,在父类中不能确定具体的方法体.该方法就是定义为抽象方法
抽象类和抽象方法的定义格式
- 抽象方法的定义格式
Public abstract 返回值类型 方法名(参数列表);
- 抽象类的定义格式;
Public abstract class类名{}
注意事项:
1-抽象类不能实例化(创建对象)
- 抽象类中不一定有抽象方法,有抽象方法的类一定是抽象类
- 可以有构造方法
- 抽象的子类
要么重写抽象类中的所有抽象方法
要么是抽象类
作用:
抽取共性时,无法确定方法体,就把方法定义为抽象的.强制让子类按照某种格式重写.
抽象方法所在的类,必须是抽象类.
格式:
Public abstract 返回值类型 方法名(参数列表);
Public abstract class 类名{}
定义和使用:
- 接口用关键字interface来定义
Public interface 接口名{}
- 接口不能实例化
- 接口和类之间是实现关系,通过implements关键之表示
Public class 类名 implements 接口名{}
- 接口的子类(实现类)
要么重写接口中所有的抽象方法
要么是抽象类
注意:
- 接口和类的实现关系,可以单实现,也可以多实现.
Public class 类名 implements 接口名1, 接口名2{}
- 实现类还可以在继承一个类的同时实现多个接口.
Public class 类名 extends 父类 implements 接口1, 接口2{}
接口当中成员的特点
- 成员变量
只能是常量
默认修饰符:public static final
- 构造方法
没有
- 成员方法
只能写抽象方法
默认修饰符:public abstract
JDK7以前:接口中只能定义抽象方法
JDK8的新特性:接口中可以定义有方法体的方法(后面单独说)
- 类和类的关系
继承关系,只能单继承,不能多继承,但是可以多层继承
- 类和接口的关系
实现关系,可以单实现,也可以多实现,还可以在继承一个类的同时实现多个接口
- 接口和接口的关系
继承关系,可以单继承,也可以多继承
JDK8开始接口中新增的方法
JDK7以前:接口中只能定义抽象方法
JDK8的新特性:接口中可以定义有方法体的方法(后面单独说)
JDK9的新特性:接口中可以定义私有方法.
JDK8以后接口中新增的方法
允许在接口中定义默认方法,需要使用关键字default修饰
作用:解决接口升级的问题
接口中默认方法的定义格式:
格式: public default 返回值类型 方法名(参数列表){ }
范例: public default void show(){ }
接口中默认方法的注意事项
- 默认方法不是抽象方法,所以不强制被重写.凡是如果被重写,重写的时候去掉default关键字
- Public可以省略,default不能省略
- 如果实现多个接口,多个接口中存在相同名字的默认方法,子类就必须对该方法进行重写
允许在接口中定义静态方法,需要static修饰
接口中静态方法的定义格式
格式: public static 返回值类型 方法名(参数列表){ }
范例: public static void show(){ }
注意事项:
- 静态方法只能通过接口名调用,不能通过类名或者对象名调用
- Public可以省略,static不能省略
JDK9新增的方法
接口中私有方法的定义格式:
格式1:private 返回值类型 方法名(参数列表){ }
范例: private void show(){ }
给默认方法服务的
格式2: private static 返回值类型 方法名(参数列表){ }
范例2: private static void method(){ }
为静态方法服务的
- 接口代表规则,是行为的对象.想要让那个类拥有一个行为,就让这个类实现对应的接口就可以了
- 当一个方法的参数是接口时,可以传递接口所实现类的对象,这种方法称之为接口多态
设计模式(Design pattern):
是一套被反复使用,多数人知晓的,经过分类编目的,代码设计经验的总结.
设计模式是为了可重用代码,让代码更容易被人理解,保证代码可靠性,程序的重用性
简单理解:
设计模式就是解决各种问题的套路
适配器的设计模式:解决接口与接口实现类之间的矛盾问题
总结:
- 当一个接口抽象方法过多,但是我只要使用其中一部分的时候,就可以适配器设计模式
- 书写步骤:
编写中间类XXXAdapter ,实现对应接口
对接口中抽象方法进行空处理
让真正的实现类继承中间类,并重写需要用的方法
为了避免其他类创建适配器对象,中间的适配器类用abstract进行修饰
类的五大成员:
属性,方法,构造方法,代码块,内部类
内部类:
在一个类的里面,再定义一个类
什么时候用到内部类?
B类表示的事物是A类的一部分,且B单独存在没有意义.
为啥要学:
需求:写一个JavaBean类表述汽车
属性:汽车的品牌,车龄,颜色,发动机品牌,使用年限.
内部类表示的事物是外部类的一部分
内部类单独出现没有任何意义
内部类的访问特点:
- 内部类可以直接访问外部类的成员,包括私有
- 外部类要访问内部类的成员,必须创建对象
成员内部类
静态内部类
局部内部类
以上了解
匿名内部类
写在成员位置的,属于外部类的成员
成员内部类可以被一些修饰符所修饰,比如:private ,默认,protect,public,static等
在成员内部类里面,JDK16之前不能定义静态变量,JDK16开始才可以定义静态变量
获取成员内部类对象
1-
在外部类中编写方法,对外提供内部类的对象
2-
直接创建格式:外部类类名.内部类名 对象名 = 外部内对象.内部类对象;
成员内部类如何获取外部类的对象
静态内部类也是成员内部类的一种
只能访问外部类中静态的变量和静态方法,如果想要访问非静态的需要创建对象
创建静态内部类对象的格式:
外部类名.内部类名.对象名 = new 外部类名.内部类名();
调用非静态方法的格式:
先创建对象,用对象调用
调用静态方法的格式:
外部类名.内部类名.方法名();
- 将内部类定义在方法里面的就叫做局部内部类,类似于方法里面的局部变量.
- 外界无法直接使用,需要在方法里面创建对象并使用
- 该类可以直接访问外部类的成员,也可以访问方法里面的局部变量.
本质:隐藏了名字的内部类,可以写在成员位置,也可以写在局部位置
格式:
New 类名或者接口名(){
重写方法;
};
格式的细节:
包含了继承或实现,方法重写,创建对象
整体就是一个类的子类或者结构的实现类对象
使用场景
当方法的参数是接口或者类时,
以接口为例,可以传递这个接口的实现类对象,如果实现类只要使用一次,就可以用匿名内部类来简化代码.
包含:
- 继承\实现关系
- 方法重写
- 创建对象
事件是可以被组件识别的操作
当你对组件干了某件事之后,就会执行对应的代码
事件源:按钮 图片 窗体
事件:某些操作
如:鼠标单击,鼠标划入..
绑定监听:当事件源发生了某个时间,则会执行某段代码
Key Listener(键盘监听)
Mouse Listener(鼠标监听)
划入
点击
松开
以上为动作监听
移走
Action Listener(动作监听)
游戏打包exe要考虑的因素
- 一定要包含图形化界面
- 代码要打包起来
- 游戏用到的图片也要打包起来
- JDK也要打包起来
核心步骤:
1-把所有代码打包成一个压缩包,jar后缀的压缩包
- 把jar包转换成exe安装包
- 把第二步的exe,图片,jdk整合在一起,变成最终的exe安装包
- 是一个帮助我们用于进行数学计算的工具类
- 私有化构造方法,所有的方法都时静态的
常用方法:
Public static int abs(int a)
获取参数绝对值
Public static double ceil(double a)
向上取整
Public static double floor(double a)
向下取整
Public static int round(float a)
四舍五入
Public static int max(int a ,int b)
获取两个int值中较大值
Public static double pow(double a ,double b)
返回a的b次幂的值
Public static double random()
返回为double的随机值,范围[0.0,1.0)
System也是一个工具类,提供了一些与系统相关 的方法
Public static void exit (int status)
终止当前运行的java虚拟机
Public static long currentTimeMillis()
返回当前系统的时间毫秒值形式
Public static void arraycopy(数组源数组 , 起始索引, 目的地数组, 起始索引, 拷贝个数)
数组拷贝
计算机中的时间原点
1970年1月1日 00:00:00
C语言的生日
我们有时差8小时
所以要加8小时
表示当前虚拟机的运行环境
public static Runtime getRuntime() //当前系统的运行环境对象
public void exit(int status) //停止虚拟机
public int availableProcessors() //获得CPU的线程数
public long maxMemory() //JVM能从系统中获取总内存大小(单位byte)
public long totalMemory() //JVM已经从系统中获取总内存大小(单位byte)
public long freeMemory() //JVM剩余内存大小(单位byte)
public Process exec(String command) //运行cmd命令
- object是java中的顶级父类,所有的类都直接或者i按揭的继承于Object类
- object类中的方法可以被所有子类访问,所以我们要学习Object和其方法
- toString(): 一般会重写,打印对象时打印属性
- equals(): 比较对象时会重写,比较对象属性是否相同
- clone(): 默认浅克隆.
如果需要深克隆需要重写方法或者使用第三方工具类.
构造方法
只有空参构造
成员方法:
public string tostring() 返回对象的字符串表示形式
public boolean equals(Object obj) 比较两个对象是否相等
protected object clone(int a) 对象克隆
把A对象的属性值完全拷贝给B对象,也叫做对象拷贝,对象复制
浅克隆
不管对象内部的属性是否是基本数据类型还是引用数据类型,都完全拷贝过来
深克隆
基本数据类型拷贝
字符串复用
引用数据类型会重新创建新的
Objects是一个对象工具类,提供了一些操作对象的方法
public static boolean equals(Object a, Object b) 先做非空判断,比较两个对象
public static boolean isNull(Object obj) 判断对象是否为null,为nul1返回true ,反之
public static boolean nonNull(Object obj) 判断对象是否为null,跟isNull的结果相反
Java中,整数有四种类型:byte,short,int,long
在底层占用字节个数:1 ,2 , 4 , 8
构造方法:
Public BigInteger(int num, Random rnd) 获取随即大整数 ,范围:[0-2的num-1次方]
Public BigInteger(String val) 获取指定的大整数
Public BigInteger(String val, int radix)获取指定进制的大整数
Public static BigInteger valueOf(long val)静态方法获取BigInteger的对象,内部有优化
对象一旦创建,内部记录的值不能发生改变。
BigInteger常见的成员方法
public BigInteger add(BigInteger val) 加法
public BigInteger subtract(BigInteger val) 减法
public BigInteger multiply(BigInteger val) 乘法
public BigInteger divide(BigInteger val) 除法,获取商
public BigInteger[] divideAndRemainder(BigInteger val) 除法,获取商和余数
public boolean equals(Object x) 比较是否相同
public BigInteger pow(int exponent) 次幂
public BigInteger max/min(BigInteger val) 返回较大值/较小值
public int intValue(BigInteger val) 转为int类型整数,超出范围数据有误
public int longValue(BigInteger val) 转为long类型整数,超出范围数据有误
BigInteger底层存储方式
- 对于计算机而言,其实是没有数据类型的概念的,都是0101010101.
- 数据类型是编程语言自己规定的。
存储上限
存储方式:[84921011, 2034348789, 351923245]
数组的最大长度是int的最大值:2147483647
数组中每一位能表示的数字:-2147483648 ---- 2147483647
BigInteger能表示的最大数字为:42亿的21亿次方
用于小数的精确计算
用来表示很大的小数
构造方法获取BigDecimal对象
public BigDecimal(String val)
public BigDecimal(double val)
静态方法获取BigDecimal对象
public static BigDecimal valueOf(double val)
BigDecimal的使用
public BigDecimal add(BigDecimal val) 加法
public BigDecimal subtract(BigDecimal val) 减法
public BigDecimal multiply(BigDecimal val) 乘法
public BigDecimal divide(BigDecimal val) 除法
public BigDecimal divide(BigDecimal val,精确几位,舍入模式)除法
- 正则表达式可以校验字符串是否满足一定的规则,并用来检验数据格式的合法性。
- 在一段文本中查找满足要求的内容
字符类:
[abc] 只能是a,b,c
[^abc] 除了a,b,c之外的字符
[a-zA-Z] a到z A到Z,包括(范围)
[a-d[m-p]] a到d或m-p
[a-z&&[def]] a-z和def的交集。为d e f
[a-z&&[^bc]] a-z和非bc的交集
[a-z&&[^m-p]] a到z和除了m到p的交集
预定义字符(只匹配一个字符)
. 任何字符(\
N回车符号不匹配)
\d 一个数字: [0-9]
\D 非数字: [^0-9]
\s 一个空白字符: [\t\n\x0B\f\r]
\S 非空白字符: [^\s]
\w [a-zA-Z_0-9]英文,字母,下划线
\W [^\w]一个非单词字符
数量词
X? X,一次或0次
X* X,零次或多次
X+ X,一次或多次
X{n} X,正好n次
X{n,} X,至少n次
X{n,m} X,至少n但是不超过m次
正则表达式在字符串方法中的使用
Public String[] matches(String regex)
判断字符串是否符合正则表达式的规则
Public String replaceAll(String regex,String newStr)
按照正则表达式的规则进行替换
Public String[] split(String regex)
按照正则表达式的规则切割字符串
分组:
每组有组号
规则1:从1开始,连续不间断。
规则2: 以左括号为基准,最左边的是第一组,其次为第二组,依次类推。
捕获分组:
后续还要继续使用本组的数据
正则内部使用: \\组号
正则外部使用: $组号
非捕获分组
分组之后不需要再使用本组数据,仅仅是吧数据括起来
符号:
(?:正则) 获取所有 java(?:8|11|17)
(?=正则) 获取前面部分 java(?=8|11|17)
(?!正则) 获取不是指定内容的前面部分 java(?!8|11|17)
Jdk7以前时间相关类
Date 时间
SimpleDateFormat 格式化时间
Calendar 日历
时间的相关知识点
世界标准时间:
格林尼治/格林威治时间,简称GMT。
目前世界标准时间(UTC)已经替换为:原子钟
中国标准时间: 世界标准时间+8小时
Date时间类
是一个JDK写好的JavaBean类,用来描述时间,精确到毫秒。
利用空参构造创建的对象,默认表示系统当前时间。
利用有参构造创建的对象,表示指定的时间。
public Date() 创建Date对象,表示当前时间
public Date(long date) 创建Date对象,表示指定时间
public void settime(long time) 设置/修改毫秒值
public long gettime() 获取时间对象的毫秒值
格式化:把时间变成我们喜欢的格式
解析:把字符串表示的时间变成Date对象
public simpleDateFormat() 默认格式
public simpleDateFormat(String pattern) 指定格式
public final string format(Date date) 格式化(日期对象 ->字符串)
public Date parse(string source) 解析(字符串 ->日期对象)
格式化的时间形式的常用的模式对应关系如下
y 年
M 月
d 日
H 时
m 分
s 秒
代表了系统当前的日历对象,可以单独修改,获取时间中的年,月,日
细节:Calendar是一个抽象类,必能直接创建对象
public static Calendar lgetInstance() 获取当前时间的日历对象
public final Date getTime() 获取日期对象
public final setTime(Date date) 给日历设置日期对象
public long getTimeInMillis() 拿到时间毫秒值
public void setTimeInMillis(long millis) 给日历设置时间毫秒值
public int get(int field) 获取日期中的某个字段信息
public void set(int field,int value) 修改日历的某个字段信息
public void add(int field,int amount) 为某个字段增加/减少指定的值
JDK8新增的时间相关类
Date类
ZoneId:时区
static Set<string> getAvailableZoneIds() 获取Java中支持的所有时区
static ZoneId systemDefault() 获取系统默认时区
static Zoneld of(string zoneld) 获取一个指定时区
Instant:时间戳(标准时间)
static Instant now() 获取当前时间的Instant对象(标准时间)
static Instant ofXxxx(long epochMilli) 根据(秒/毫秒/纳秒)获取Instant对象
ZonedDateTime atZone(ZoneIdzone) 指定时区
boolean isxxx(Instant otherInstant) 判断系列的方法
Instant minusXxx(long millisToSubtract) 减少时间系列的方法
Instant plusXxx(long millisToSubtract) 增加时间系列的方法
ZoneDateTime:带时区的时间
static ZonedDateTime now() 获取当前时间的ZonedDateTime对象
static ZonedDateTime ofXxxx(。。。) 获取指定时间的ZonedDateTime对象
ZonedDateTime withXxx(时间) 修改时间系列的方法
ZonedDateTime minusXxx(时间) 减少时间系列的方法
ZonedDateTime plusXxx(时间) 增加时间系列的方法
日期格式化类(SimpleDateFormat)
DateTimeFormatter
用于时间的格式化和解析
日历类(Calendar)
LocalDate:年,月,日
LocalTime:时,分,秒
LocalDateTime: 年,月,日,
时,分,秒
工具类
Duration:时间间隔(秒,纳秒)
Period:时间间隔(年,月,日)
ChronoUnit:时间间隔(所有单位)
基本数据类型对应的引用数据类型
用一个对象把数据包起来
JDK5之前
public Integer(int value) 根据传递的整数创建一个Integer对象
public Integer(String s) 根据传递的字符串创建一个Integer对象
public static Integer valueOf(int i) 根据传递的整数创建一个Integer对象
public static Integer valueof(String s) 根据传递的字符串创建一个Integer对象
public static Integer valueof(String s, int radix) 根据传递的字符串和进制创建一个Integer对象
JDK5之后
增加了自动拆箱、自动装箱
不需要new,不需要调用方法,直接复制即可
Integer I = 10;
Integer成员方法
public static string toBinaryString(int i) 得到二进制
public static string toOctalString(int i) 得到八进制
public static string toHexString(int i) 得到十六进制
public static int parseInt(string s) 将字符串类型的整数转成int类型的整数
常用算法(查找算法)
基本查找
二分查找
前提条件:数组中的数据必须是有序的
核心逻辑:每一次排除一半的查找范围
优势:提高查找效率
分块查找
原则1:前一块中的最大数据,小于后一块所有的数据(块内无序,块间有序)
原则2:块数量一般等于数字的个数开根号,比如:16和数字一般分为4块
核心思路:先确定要查找的元素在哪一块然后在块内挨个查找
插值查找
在介绍插值查找之前,先考虑一个问题:
为什么二分查找算法一定要是折半,而不是折四分之一或者折更多呢?
其实就是因为方便,简单,但是如果我能在二分查找的基础上,让中间的mid点,尽可能靠近想要查找的元素,那不就能提高查找的效率了吗?
二分查找中查找点计算如下:
mid=(low+high)/2, 即mid=low+1/2*(high-low);
我们可以将查找的点改进为如下:
mid=low+(key-a[low])/(a[high]-a[low])*(high-low),
这样,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
**细节:**对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
代码跟二分查找类似,只要修改一下mid的计算方式即可。
斐波那契查找
Java基础-资料\day21-API(算法,lambda,练习)\笔记\算法.md
树表查找
哈希查找
排序算法
冒泡排序:
相邻的数据两两比较,小的放前面,大的放后面。
选择排序:
从0索引开始,拿着每一个索引上的索引的元素跟后面的元素依次比较,小的放前面,大的放后面,以此类推
插入排序:
将0索引的元素到N索引的元素看作是有序的,把N+1索引的元素到最后一个当作无序的。遍历无无序的数据,将遍历到的元素插入有序序列中适当的位置,入狱相同的数据,插在后面。
递归算法
递归就是方法中再次调用方法本身的现象
注意点:递归要有住口,否则就会出现内存溢出
把一个复杂的问题层层转化为与原问题相似的规模较小的问题来求解
递归策略只需要少量的程序就可以描述出解题过程所需的多次重复计算
书写递归的两个核心
- 找出口:什么时候不在调用方法
- 找规则:如何把大问题变成规模较小的问题
快速排序
第一轮:把0索引的数字组为基准数,确定基准数在数组当中正确的位置
比基准数小的全部在左边,比基准数大的全部在右边
如果0索引当作基准数的话先end再start
Public static String toString(数组) 把数组拼接成一个字符串
Public static int binarySearch(数组,查找元素) 二分查找发查找元素
Public static int[] copyOf(原数组,新数组长度) 拷贝数组
Public static int[] copyOfRange(原数组,起始索引,结束索引) 拷贝数组(指定范围)
Public static void fill(数组,元素) 填充数组
Public static void sort (数组) 按照默认方式进行数组排序
Public static void sort(数组,排序规则) 按照指定的规则排序
Lambda表达式
函数式编程(functional programing):思想特点。
函数式编程思想,忽略面向对象的复杂语法,强调做什么,而不是谁去做
表现为Lambda表达式
面向对象:先找对象,让对象做事情。
Lambda表达式是JDK8开始后的一种新语法形式。
标准格式:
()->{
}
():对应着方法的形参
->:固定格式
{}:对应方法体
注意点:
Lambda表达式可以用来简化匿名内部类的书写
Lambda表达式只能简化函数式接口的匿名内部类的书写
函数式接口:有且仅有一个的抽象方法的接口叫做函数式接口,接口上方可以加@FunctionalInterface注解
省略写法:
可推导,可省略
lambda表达式的省略模式
1.参数类型可以省略不写
2.如果只有一个参数,参数类型可以省略,同时()也可以省略
3.如果Lambda表达式的方法体代码只有一行代码,大括号,分号,return关键字都可以省略,需要同时省略
Collection:单列集合
每次添加一个
Collection
List:
ArrayList
LinkedList
Vector(不用了)
Set:
HashSet
LinkedHashSet
TreeSet
红色的是接口
黑的是实现类
List系列集合:添加的元素是有序(存取顺序一样)、可重复、有索引
Set系列集合:添加的元素是无序、不重复、无索引
Map:双列集合
每次添加一对集合
Collection是单列集合的祖宗接口,他的功能是全部单列集合的都可以继承使用的。

Collection的遍历方式
迭代器遍历(不依赖索引)
迭代器在Java中的类是Iterator,迭代器是集合专用的遍历方式。
Iterator<E> iterator(): 返回此集合中元素的迭代器,通过集合对象的iterator()方法得到
Iterator中的常用方法
boolean hasNext(): 判断当前位置是否有元素可以被取出
E next(): 获取当前位置的元素,将迭代器对象移向下一个索引位置
细节点注意:
1.报错NoSuchElementException
2.迭代器遍历完毕,指针不会复位
3.循环中只能用一次next方法
4.迭代器遍历时,不能用集合的方法进行增加或者删除
增强for遍历
增强for的底层就是迭代器,为了简化迭代器的代码写的。
它是JDK5之后出现的,其内部原理就是一个Iterator迭代器
所有的单列集合和数组才能用增强for进行遍历。
细节:
修改增强for循环中的变量,不会改变集合中原本的数据
Lambda表达式遍历
List集合
- 有序:存取的元素顺序一致
- 有索引:可通过索引操作元素
- 可重复:存储的元素可以重复
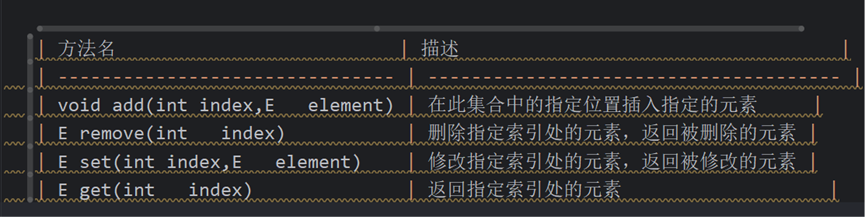
.特有方法:
Collection的方法List都继承了
List集合因为有索引,所以多了很多索引操纵的方法
遍历方式:
迭代器遍历:在遍历的过程中删除元素,请使用迭代器
列表迭代器遍历(特有):在遍历的过程中需要添加元素,请使用列表迭代器
增强for遍历
Lambda表达式遍历:仅仅想遍历,那么使用增强for或者Lambda表达式
普通for循环遍历(因为List有索引):如果遍历的时候想操作索引,可以使用普通for
计算机存储数据、组织数据的方式,
是指数据相互之间是以什么方式排列在一起的,
数据结构是为了更加方便的管理和使用数据结构,需要结合具体的业务场景进行选择。
一般情况下,精心的选择数据结构可以带来更高的运行或者存储效率
不同的业务场景要选择不同的数据结构
特点:先进后出,后进先出
数据进入栈模型的过程称为:压/进栈
数据离开栈模型的过程称为:弹/出栈
特点:先进后出,后进先出
数据进入队列模型的过程称为:入队列
数据离开队列模型的过程称为:出队列
查询速度快:
查询通过数据地址值和索引定位,查询任意数据耗时相同(元素在内存中是连续存储的)
删除效率低:
要将原始数据删除,同时后面每个数据前移
添加效率低:
添加位置后的每个数据后移,在添加元素。
查询快,增删慢
链表中的结点是一个独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址
链表查询慢,无论查询哪个数据都要从头开始。首位操作块
链表的增删相对快
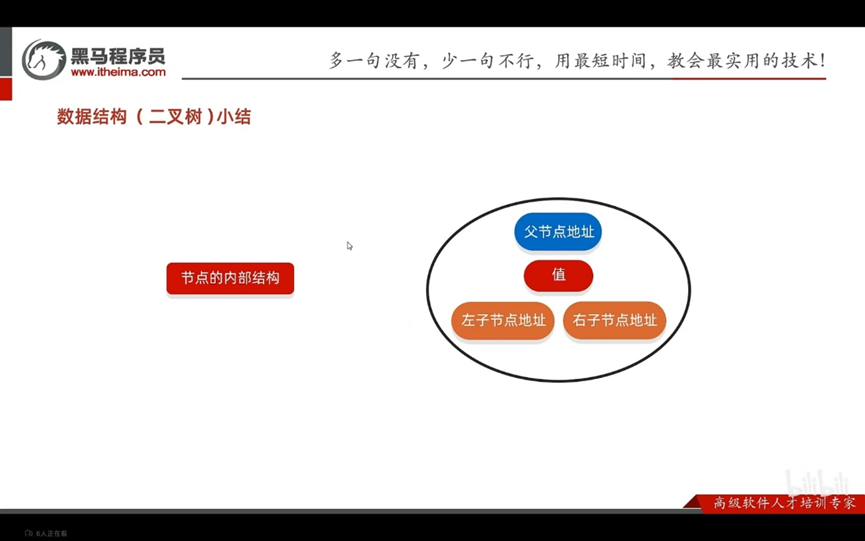 结点:
结点:
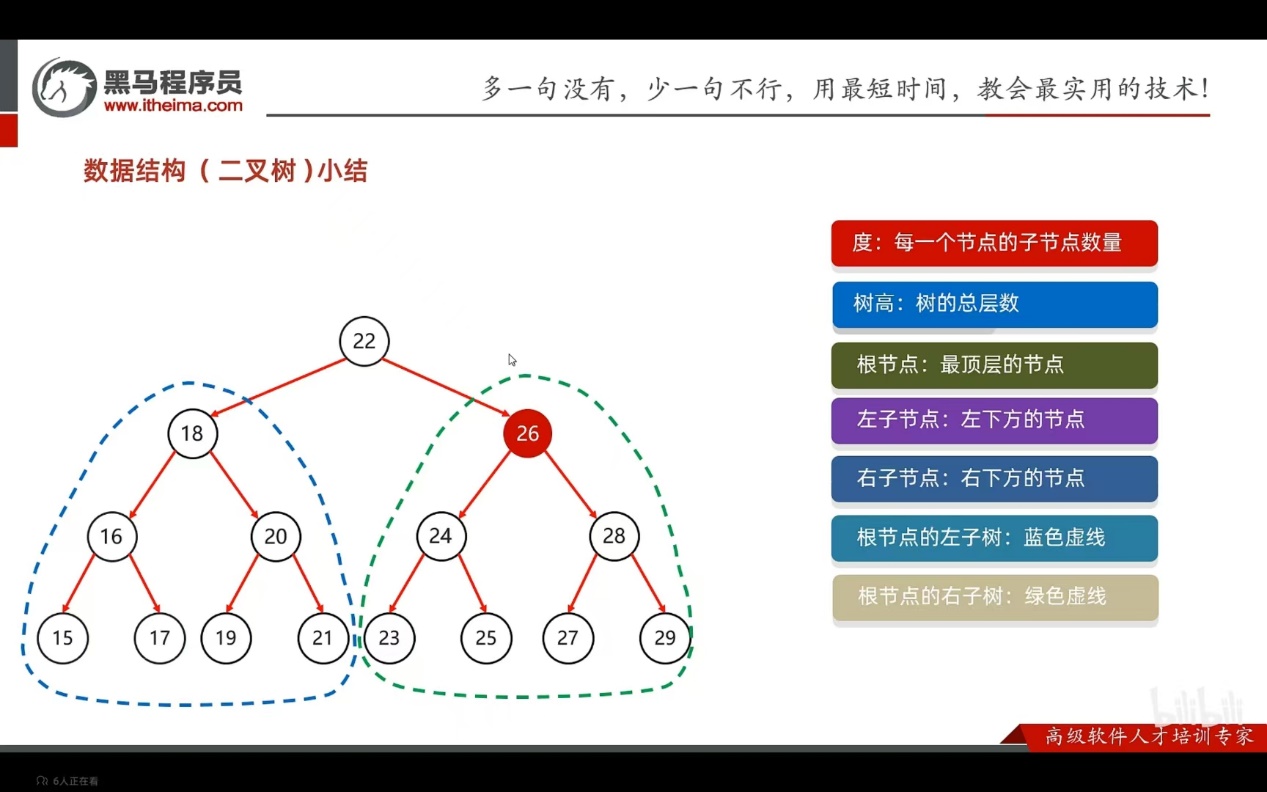
度:每一个节点子节点的数量
树高:书的总层数
根节点:最顶层的节点
左子节点:最下方的结点
右子节点:右下方的结点
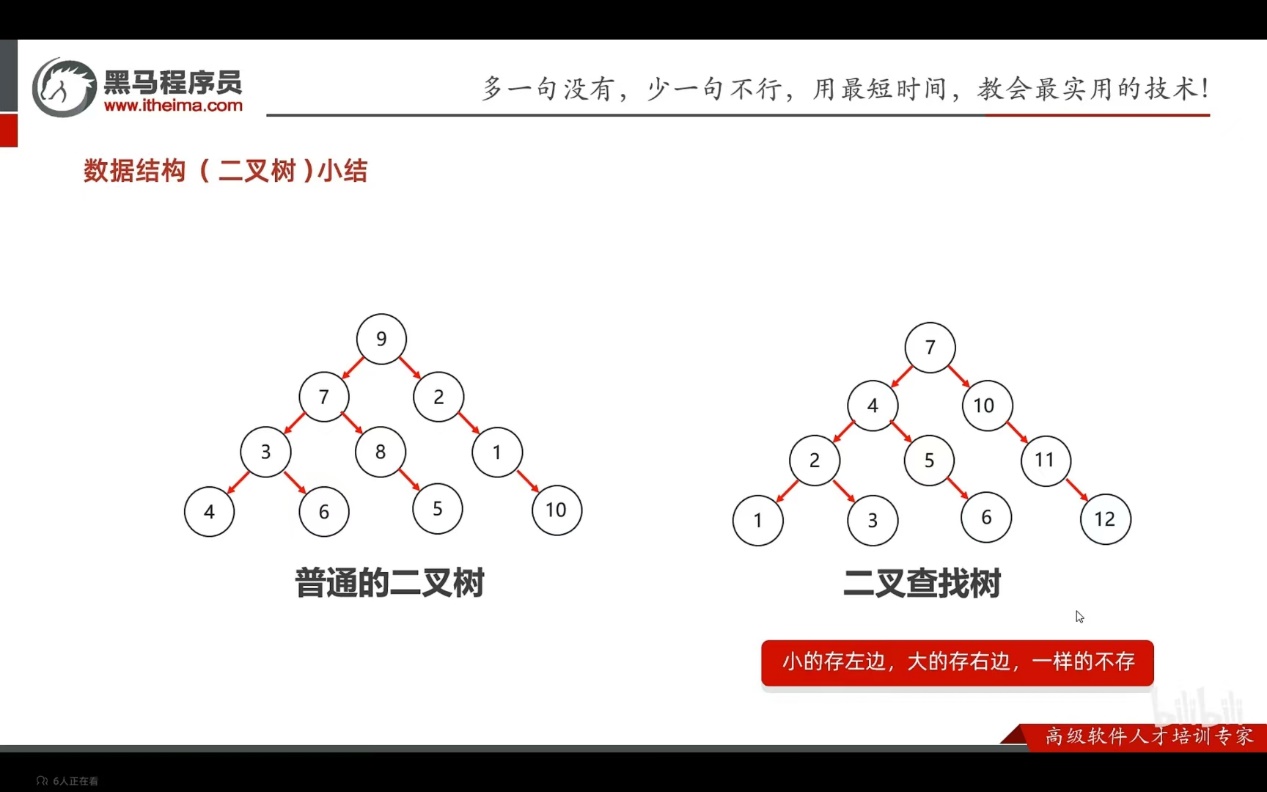
二叉查找树,又称二叉排序树或者二叉搜索树
特点;
- 每一个节点上最多有两个子节点
- 任意节点的左子树上的值都小于当前节点
- 任意节点的右子树上的值都大于当前节点
规则:
- 小的存左边
- 大的存右边
- 一样的不存
遍历方式:
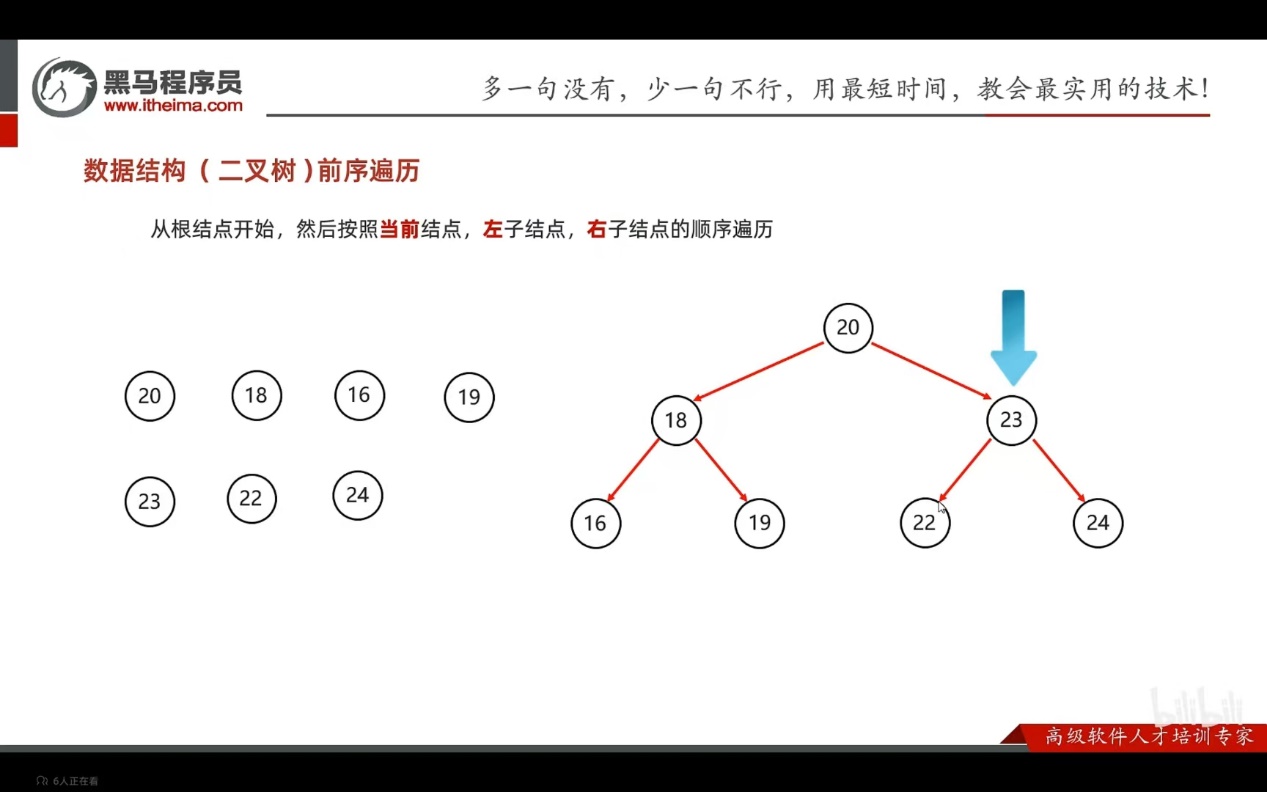
- 前序遍历
从根节点开始,按照当前节点,左子节点,右子节点的顺序遍历
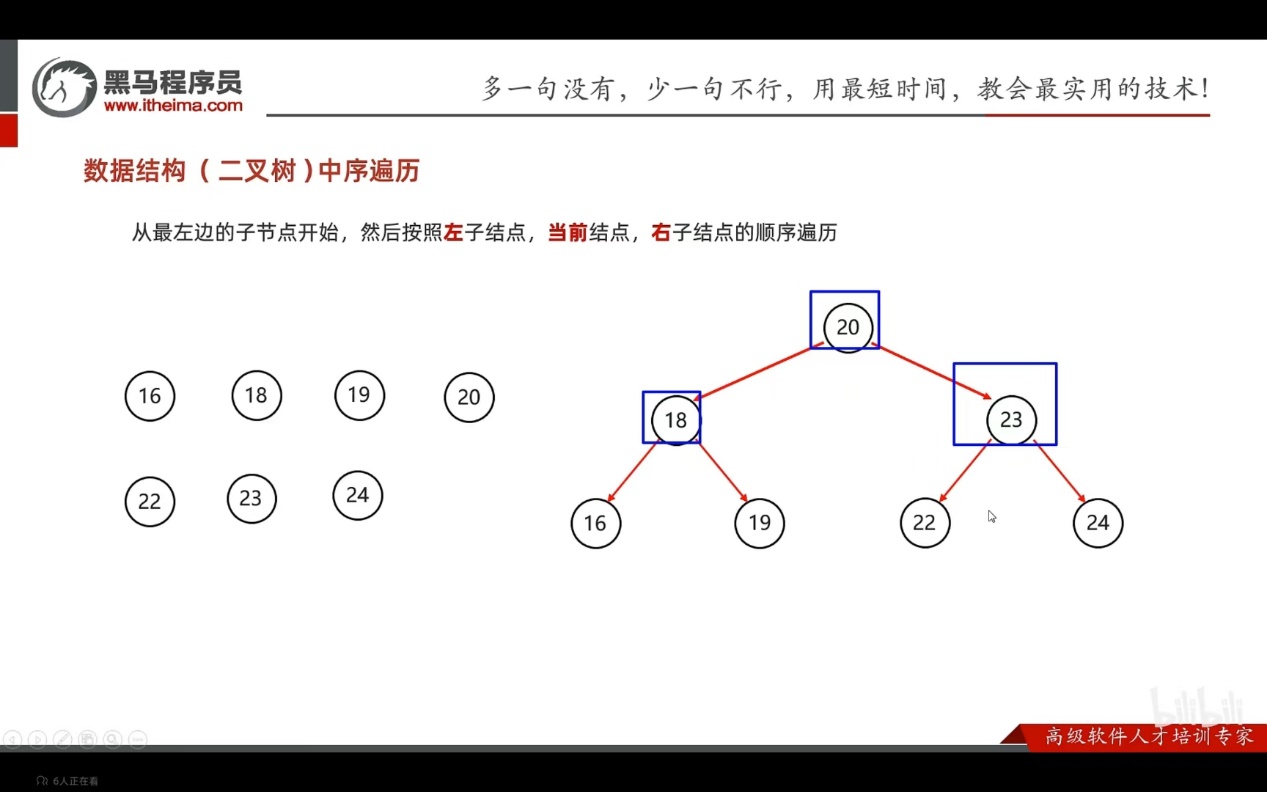
- 中序遍历(用的最多)
从根节点的最左的子节点开始,然后按照左子节点,当前节点,右子节点的顺序遍历
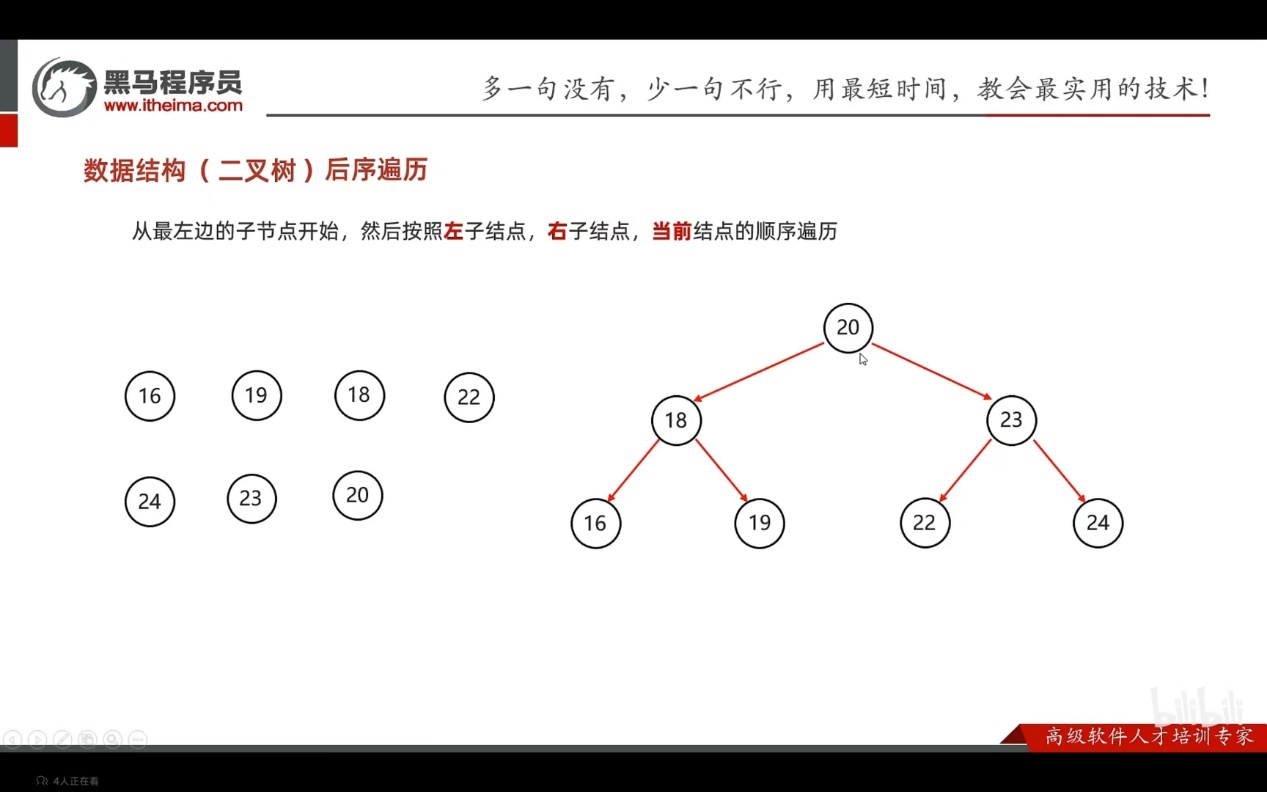
- 后序遍历
从最左边的子节点开始,然后按照左子节点,右子节点,当前节点的顺序遍历
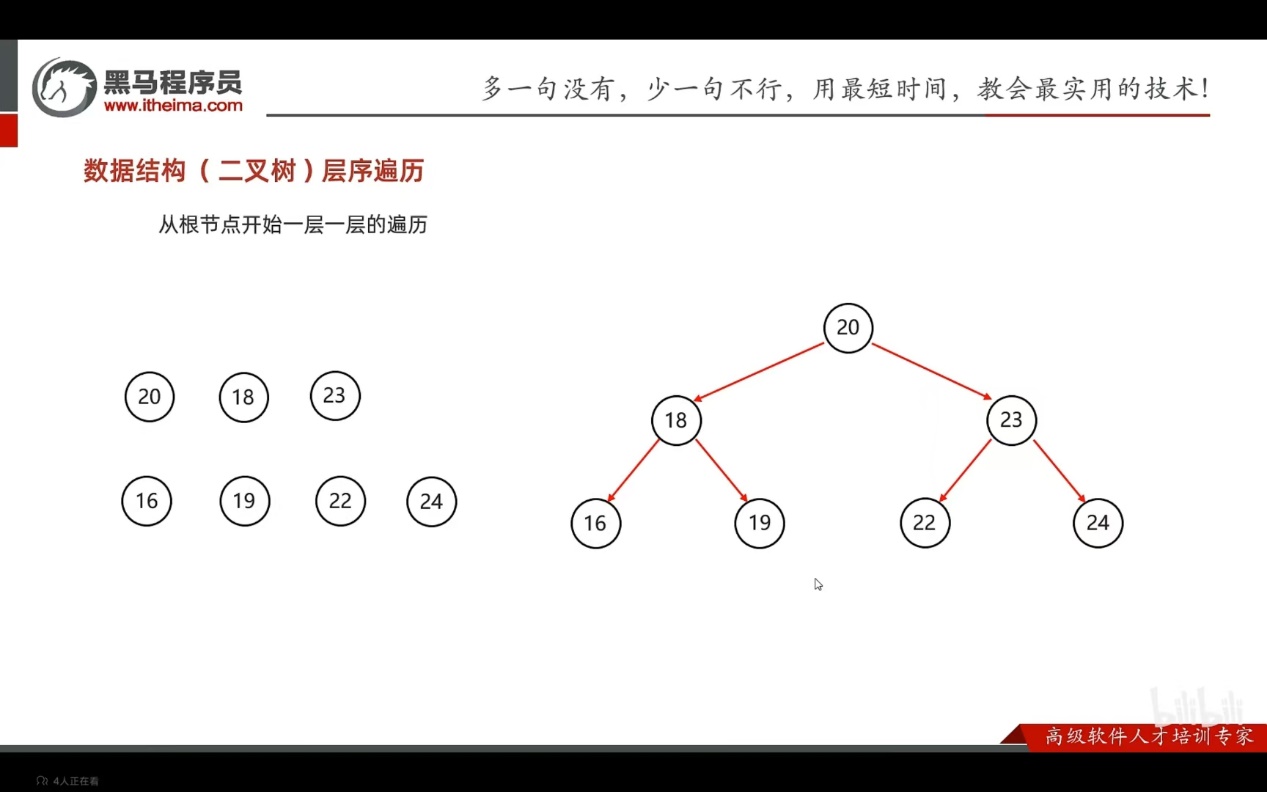
- 层序遍历
从根节点开始一层一层的遍历
小结:
- 前序遍历
当前节点,左子节点,右子节点
- 中序遍历
左子节点,当前节点,右子节点
- 后序遍历
左子节点,右子节点,当前节点
- 层序遍历
一层一层的遍历
弊端:
阿松大
规则:
任意节点左右子树的高度差不超过1
旋转机制:
规则1:左旋
- 确定支点:从添加节点,不断的往父类节点找不平衡的节点
步骤:
情况一:
- 以不平衡的点作为支点
- 把支点左旋降级,变成左子节点
- 晋升原来的右子节点
情况二:(不平衡出现在根节点)
- 以不平衡的点作为支点
- 将根节点的右侧往左拉
- 原先的右子节点变成新的父类节点,并把多余的左子节点出让,给已经降级的根节点当右节点。
规则2:右旋
- 确定支点:从添加节点,不断的往父类节点找不平衡的节点
步骤:
情况一:
- 以不平衡的点作为支点
- 把支点右旋降级,变成右子节点
- 晋升原来的左子节点
情况二:(不平衡出现在根节点)
- 以不平衡的点作为支点
- 将根节点的左侧往右拉
- 原先的左子节点变成新的父类节点,并把多余的右子节点出让,给已经降级的根节点当左节点。
需要旋转的四种情况:
- 左左:当根节点的左子树的左子树有节点插入,导致二叉树不平衡(一次右旋)
- 左右:当根节点左子树的右子树有节点插入,导致二叉树不平衡(先局部(下一级)的左旋,再整体右旋)
- .右右:当根节点的右子树的右子树有节点插入,导致二叉树不平衡(一次左旋)
- 右左:当根节点右子树的左子树有节点插入,导致二叉树不平衡(先局部(下一级)的右旋,再整体左旋)
触发机制:当添加了一个节点之后,该树不再是一个平衡树
小结:
平衡二叉树,如何添加节点
从上往下比较,先和根节点比较
在平衡二叉树中,如何查找单个节点?
为什么要旋转?
添加节点后导致二叉树不平衡需要通过旋转保证平衡
旋转的触发机制?(同上)
左左是什么意思?如何旋转?
左右是什么意思?如何旋转?
右右是什么意思?如何旋转?
右左是什么意思?如何旋转?
红黑树(是二叉查找树,但是不是高度平衡的,条件:特有的红黑规则)(增删改查的性能都很好)
红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构。
1972年出现,党史被称之为平衡二叉B树。后来。1978年呗修改为如今的红黑树
它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色
每一个节点可以是红或者黑;红黑树不是高度平衡的,他的平衡是通过“红黑规则”进行实现的
规则
- 每一个节点或是红色的,或者是黑色的
- 根节点必须是黑色
- 如果没有一个节点没有子节点或者父节点,则该节点相应的指针属性为Nil,这些Nil是为叶节点,每一个叶节点(Nil)是黑色的
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点。
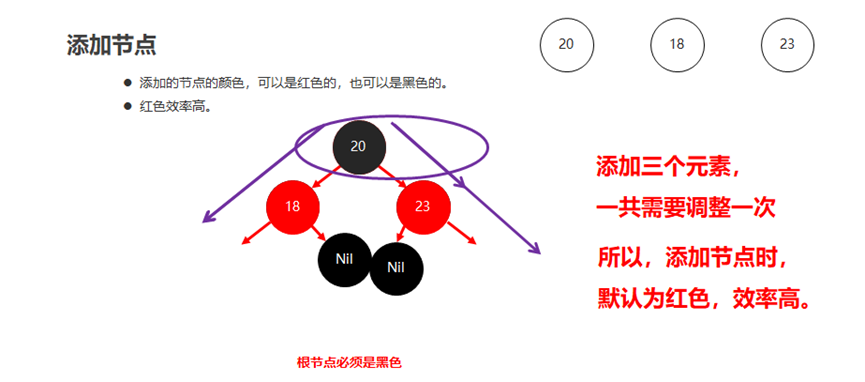
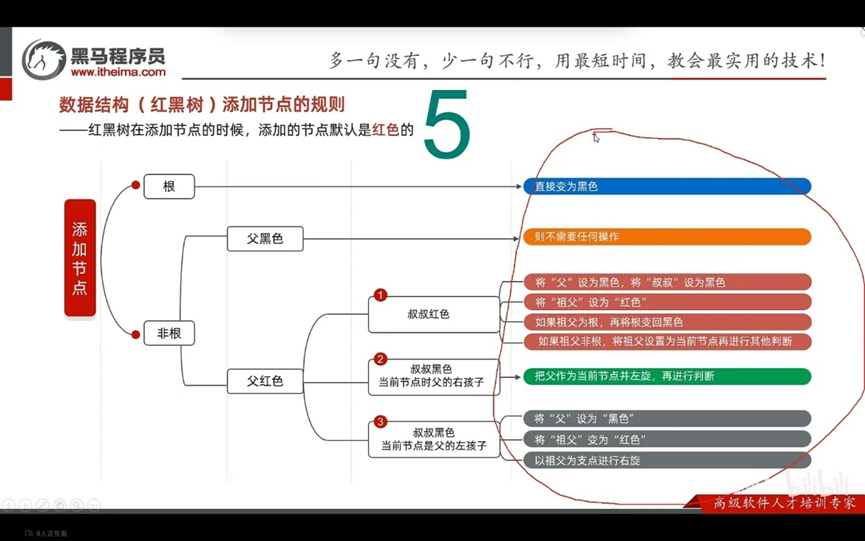
添加节点的规则:
默认颜色:添加节点默认是红色的(效率高)
ArrayList底层是数据结构,
- 利用空参创建的集合,在底层创建一个默认长度为0的数组。
- 添加第一个元素时,底层会创建一个新的长度为10的数组。
- 存满时,会扩容1.5倍。
- 如果一次添加多个元素,1.5倍放不下,则新数组的长度以实际为准。
Alt + 7:列出大纲
底层数据结构时双链表,查询慢,增删快,但是如果操作的是收尾元素,速度也很快
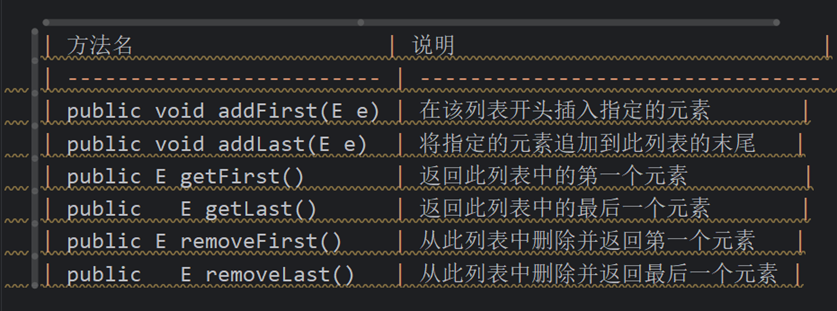
LinkedList、本身多了很多直接操作首位元素的特有API
了解即可。
泛型:是JDK5中引入的新特性,可以在编译阶段约束操作的数据类型,并进行检查
泛型格式:<数据类型>
注意:泛型只能支持应用数据类型
好处:统一了数据类型
把运行十七的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来
拓展知识点:
Java中的泛型是伪泛型
细节:
- 泛型中不能写基本数据类型
- 指定泛型的具体类型后,传递数据时,可以传入该类类型或者其他子类类型
- 如果不写泛型,类型默认是Object
泛型可以在很多地方进行定义
类后面
使用场景:当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
格式:
修饰符 class 类名<类型>{
}
此处的E可以理解为变量,但是不是用来记录数据的而是用来记录数据的类型,可以写成:T、E、K、V
方法上面
方法中形参类型不确定时,可以使用类名后面定义的泛型<E>
方法形参不确定时
- 使用类名后面定义的泛型-----------所有方法都可以用
- 在方法申明上定义自己的泛型-------只有本方法能用
格式
;
修饰符<类型>返回值类型 方法名(类型 变量名){
}
此处的T可以理解为变量,但是不是用来记录数据的而是用来记录数据的类型,可以写成:T、E、K、V
接口后面
格式:
修饰符 interface 接口名<类型>{
}
重点:如何使用一个带泛型的接口
方式1:实现类给出具体类型
方式2:实现类延续泛型,创建对象时在确定
泛型的继承和通配符
- 泛型不具备继承性,但是数据具有继承性(方法只能调用目标类型的函数,但是集合可以加上子类)
- 泛型的通配符:?
?extend E
?super E
使用场景:
定义类、方法、接口的时候,如果类型不确定。就可以定义泛型
如果类型不确定,但是能知道是哪个继承体系中的,就可以使用泛型的通配符
Set系列集合
- 无序:存取顺序不一样
- 不可重复:可以去除重复
- 无索引:没有索引的方法,所以不能使用普通的for循环遍历,也不能通过索引来获取元素
Set集合的实现类:
HashSet:无序,不重复,无索引
LinkHashSet:有序、不重复、无索引
TreeSet:可排序、不重复、无索引
Set接口中的方法上基本上与Collection的API一致
HashSet集合底层采取哈希表储存数据
哈希表是一种对于增删改查数据性能都较好的结构
哈希表组成
JDK8之前:数组+链表
JDK8开始:数组+链表+红黑树
哈希值
对象的整数表现形式
根据hashCode方法算出来的int类型的整数
该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
对象的哈希值特点:
- 如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
- 如果已经重写了hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样(哈希碰撞)
HashSet JDK8以前底层原理
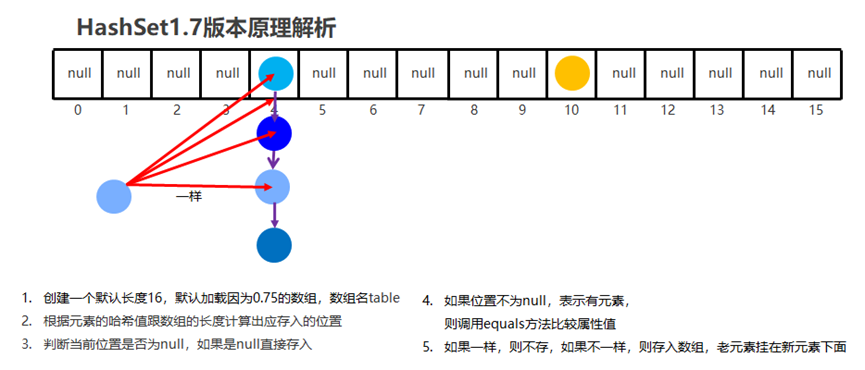 位置公式:
位置公式:
Int index= (数组长度-1)&哈希值
5------JDK8以后就是新元素挂在老元素的下面
加载因子:
当数组里面的元素的个数=数组长度*0.75时。就扩容两倍
当链表的长度大于8而且数组的长度大于等于64时,链表就会转为红黑树0
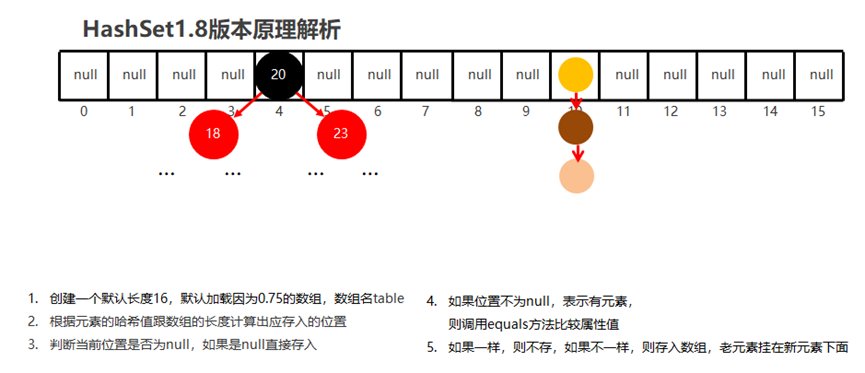 如果集合中存储的是自定义的对象,必须重写hashCode和equals方法
如果集合中存储的是自定义的对象,必须重写hashCode和equals方法
HashSet的三个问题
- HashSet为什么存取顺序不一样
链表遍历的,而链表的先后顺序能会因为数据的添加而变化致使无序状态的出现
- HashSet为什么没有索引
不纯粹,不知道如何定义索引
- HashSet是利用什么机制保证数据去重的
HashCode方法 equals方法
底层原理:
有序、不重复、无索引
这里的有序指的是保证存储和取出的元素顺序一致
原理:底层数据的结构依然是哈希表,知识每个元素有额外的多了一个双链表的机制记录存储的数据
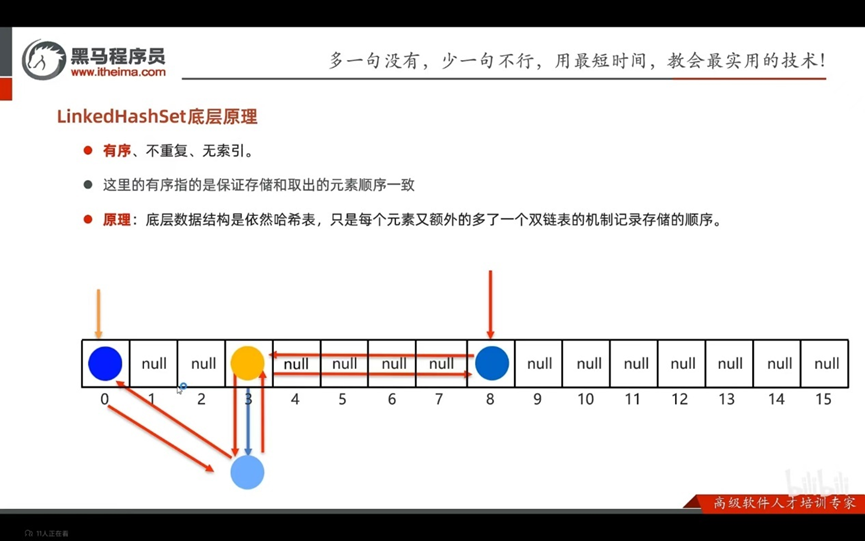 在以后如果要数据去重,我们要使用哪个
在以后如果要数据去重,我们要使用哪个
默认使用HashSet
如果要求去重且存取有序,才使用LinkedHashSet(慢一些);
特点:
- 不重复、无索引、可排序
- 可排序:按照元素的默认规则(由小到大排序)
- TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都比较好
TreeSet集合默认的规则:
- 对于数值类型:integer Double,默认按照从小到大的顺序进行排列
- 对于字符、字符串类型:按照字符在ASCII码表中的数字升序进行排序
TreeSet的两种比较方式
- 默认排序/自然排序:JavaBean类实现Compareable接口指定比较规则
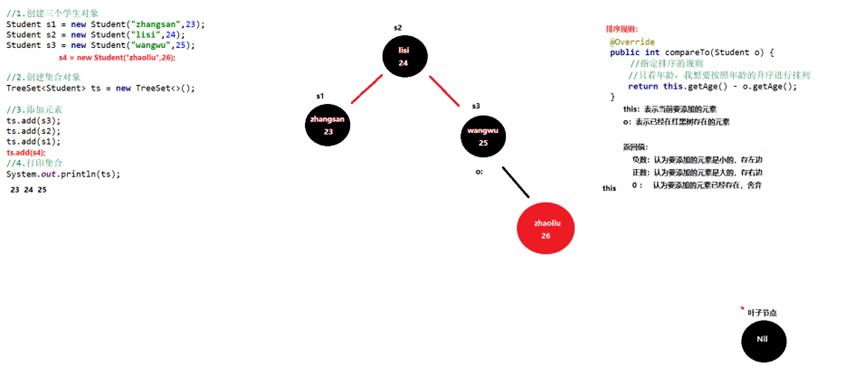 比较器排序:创建TreeSet对象时候,传递比较器Comparetor制定规则
比较器排序:创建TreeSet对象时候,传递比较器Comparetor制定规则
使用原则:默认使用第一种,如果第一种不能满足当前需求,就使用第二种
总结:

键----值:键值对/键值对对象/entry
键:唯一
值:可重复
特点:
- 双列集合一次需要添加一对数据,分别为键和值
- 键不能重复,值可以重复
- 键和值是一一对应的,每一个键只能找到自己对应的值
- 键+值这个整体我们称之为“键值对”或者“键值对对象”,在java中叫做“Entry对象”
Map的常见API
Map是双列集合的顶层接口,他的功能是全部双列集合都可以继承的
方法介绍
| 方法名 | 说明 |
| ----------------------------------- | ------------------ |
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
Map集合的获取功能【应用】
- 方法介绍
| 方法名 | 说明 |
| -------------------------------- | ------------ |
| V get(Object key) | 根据键获取值 |
| Set<K> keySet() | 获取所有键的集合 |
| Collection<V> values() | 获取所有值的集合 |
| Set<Map.Entry<K,V>> entrySet() | 获取所有键值对对象的集合 |
Map的遍历方式(在Map里面找键实际上是找值,在键值对对象找键才是键)
- 键找值
1.获取所有键的集合,把键放到一个单列集合当中
2遍历键的集合,获取到每一个键
3根据键获取值
- 键值对
1遍历键值对对象的集合,获取每一个键值对对象
2通过键值对对象获取键和值
- Lambda表达式
default void forEach(BiConsumer<? Super K ,? Super V> action)
HashMap的特点:
- HashMap是Map里面的一个实现类
- 没有额外需要学习的特有方法,直接使用Map里面的方法就可以了
- 特点都是由键确定的,无序,不重复,无索引
- HashMap跟HashSet底层原理是一模一样的,都是哈希表
- 由键决定:有序、不重复、无索引
- 这里的有序值得是保证存储和取出的元素顺序一致
原理:底层数据结构依然是哈希表,知识每个键值对元素有额外的多了一个双链表的机制记录存储的顺序
- TreeMap跟TreeSet底层原理一样,都是红黑树结构
- 由键决定特性:不重复、无索引、可排序
- 可排序:对键进行排序
- 注意:默认按照从小到大的进行排序,也可以根据自己规定的排序规则
代码书写两种排序规则
- 实现compareble接口,指定比较规则
- 创建集合时传递Comparator比较器对象,指定比较规则
- 可变参数本质就是一个数组
- 作用:在形参中接收多个数据
- 格式:数据类型…参数名称
- 举例:int…a
- 注意事项:
- 形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
Java.util:是集合工具类
作用:Collection不是集合,而是集合的工具类
Collections常用API:
public static <T> boolean addAll(Collection<T> c, T... elements) 批量添加元素
public static void shuffle(List<?> list) 打乱List集合元素的顺序
不可变集合:不可以被修改的集合
应用场景:如果某个数据不能被修改,把它防御性的拷贝到不可变集合中是个很好的时间。
当集合对象被不可信的库调用时,不可变形式是安全的。
简单理解:不让被人修改集合中的内容
如何创建:
List、Set、Map接口中,都存在of方法可以创建不可变集合
三种方式的细节:
List:直接用
Set: 元素不能重复
Map:元素不能重复、键值对数量最多10个
超过10个用ofEntries
版本超过JDK10可以直接用copyof方法
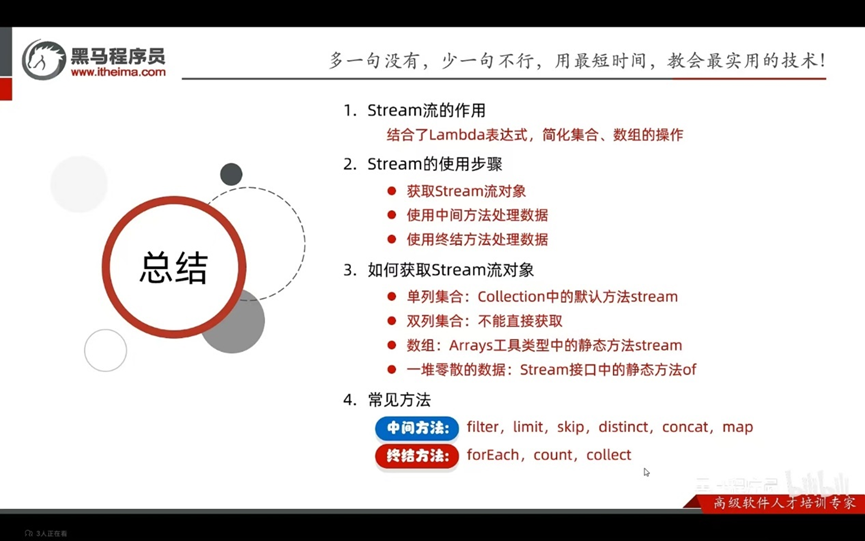
作用:结合了Lambda表达式,简化集合、数组操作
步骤:1-先得到一条Stream流(流水线),并把数据放上去
- 利用Stream中的API进行各种操作
 中间方法:过滤、转换、:方法调用完毕之后,还可以调用其他方法
中间方法:过滤、转换、:方法调用完毕之后,还可以调用其他方法

终结方法:统计、打印:最后一步,方法调用完之后,不能调用其他方法

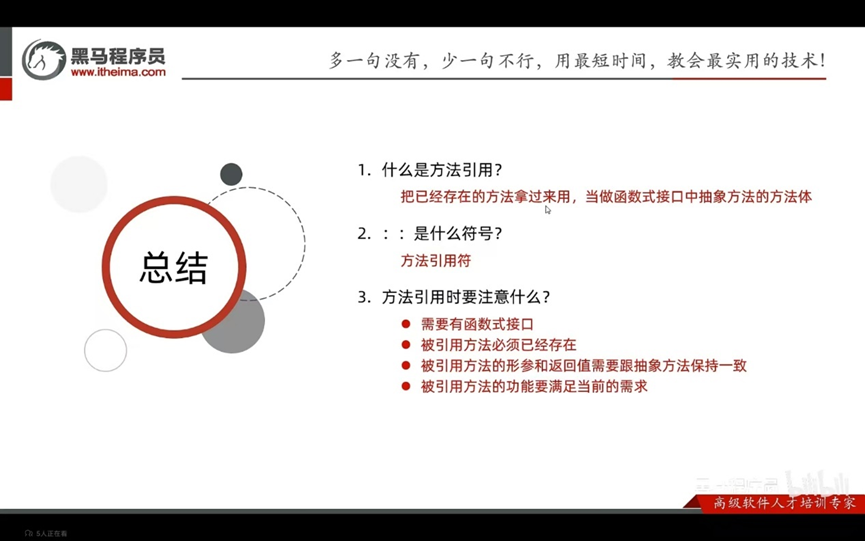
把已经有的方法拿过来用,当作函数时接口中抽象方法的方法体
注意:
- 被引用的方法必须已经存在
- 被引用方法的形参和返回值需要跟抽象方法保持一致
- 被引用的方法能够满足当前需求
方法引用的分类
- 引用静态方法
格式:
类名::静态方法
Integer::parseInt
- 引用成员方法
格式:对象:成员方法
- 引用其他类的成员方法
其他类对象::方法名
- 引用本类的成员方法
This : : 方法名
- 引用父类的成员方法
super ::方法名
以上两种引用处不能是静态方法
- 引用构造方法
格式:类名::new
范例:Student::new
 使用类名引用成员方法:
使用类名引用成员方法:
格式:类名::成员方法
范例:String::substring
引用数组的构造方法
格式:数据类型[] ::new
范例:int[] ::new0

代表程序出现的问题
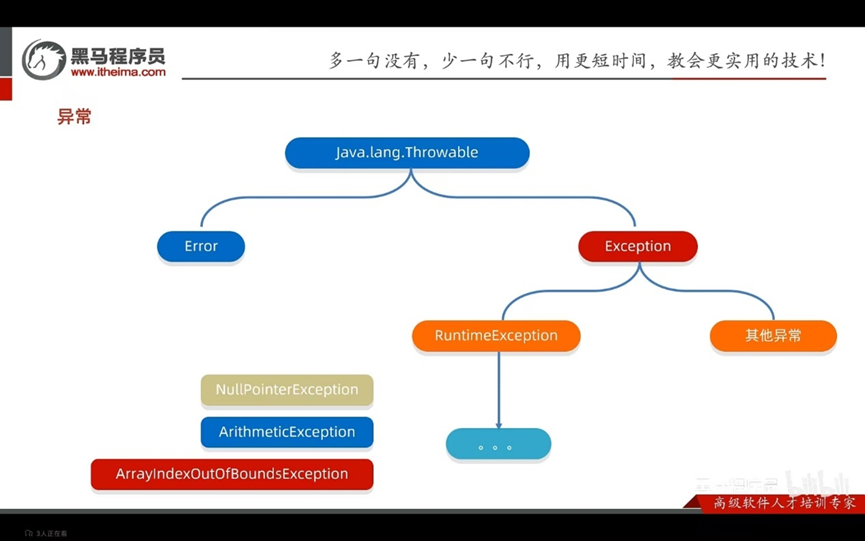
误区:不是让我们以后不出现异常,而是程序出现了异常之后,该如何处理
Error:代表的系统级别的错误(属于严重问题)系统一旦出错,sun公司会把这些错误封装成Error对象。Error是给sun公司自己用的,不是给我们程序员用的。因此我们开发人员不不用管
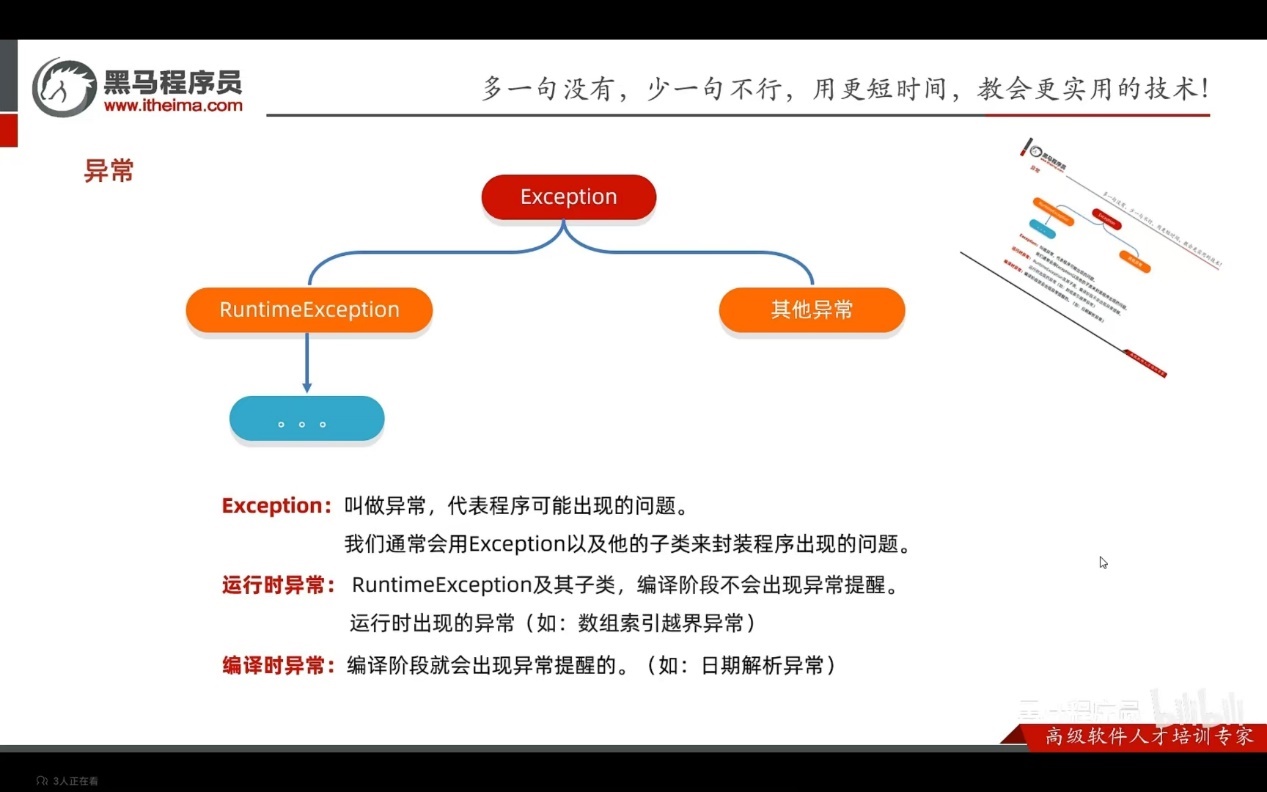
Exception:叫做异常,代表程序可能出现的问题。我们通常会用exception以及它的子类来封装程序出现的问题。
运行时异常:RuntimeException及其子类,编译阶段不会出现异常提醒。运行时出现的异常(如数组索引越界异常)
编译时异常:编译阶段就会出现异常提醒的。如日期解析异常
小结:

异常的作用:
- 异常是用来查询bug的关键参考信息
- 异常可以作为方法内部的一种特殊返回值,以便通知调用者底层执行情况
异常的处理方式:
- jvm默认的处理方式
把异常的名称,异常的原因及异常出现的位置等信息输出在控制台
程序停止运行,下面的代码不会再执行了
- 自己处理
格式:
Try{
可能出现异常的代码;
}catch(异常类名 变量名){
异常的处理代码;
}
目的:当代码出现异常的时候,可以让程序继续往下执行。
- 抛出异常
灵魂四问

Throwable的成员方法:
public String getMessage() 返回此 throwable 的详细消息字符串
public String toString() 返回此可抛出的简短描述
public void printStackTrace() 在底层是利用System.err.println进行输出
把异常的错误信息以红色字体输出在控制台
细节:仅仅是打印信息,不会停止程序运行
抛出处理
throws
注意:写在方法定义处,表示声明一个异常,告诉调用者,使用本方法可能会有哪些异常
编译时异常:必须要写
运行时异常:可以不写
throw
注意:写在方法内,结束方法手动抛出异常对象,交给调用者,方法总下面的代码就不再执行了
总结

自定义异常
- 定义异常类
- 写继承关系
- 空参构造
- 带参构造
意义:就是让控制台的报错信息更加见名知意
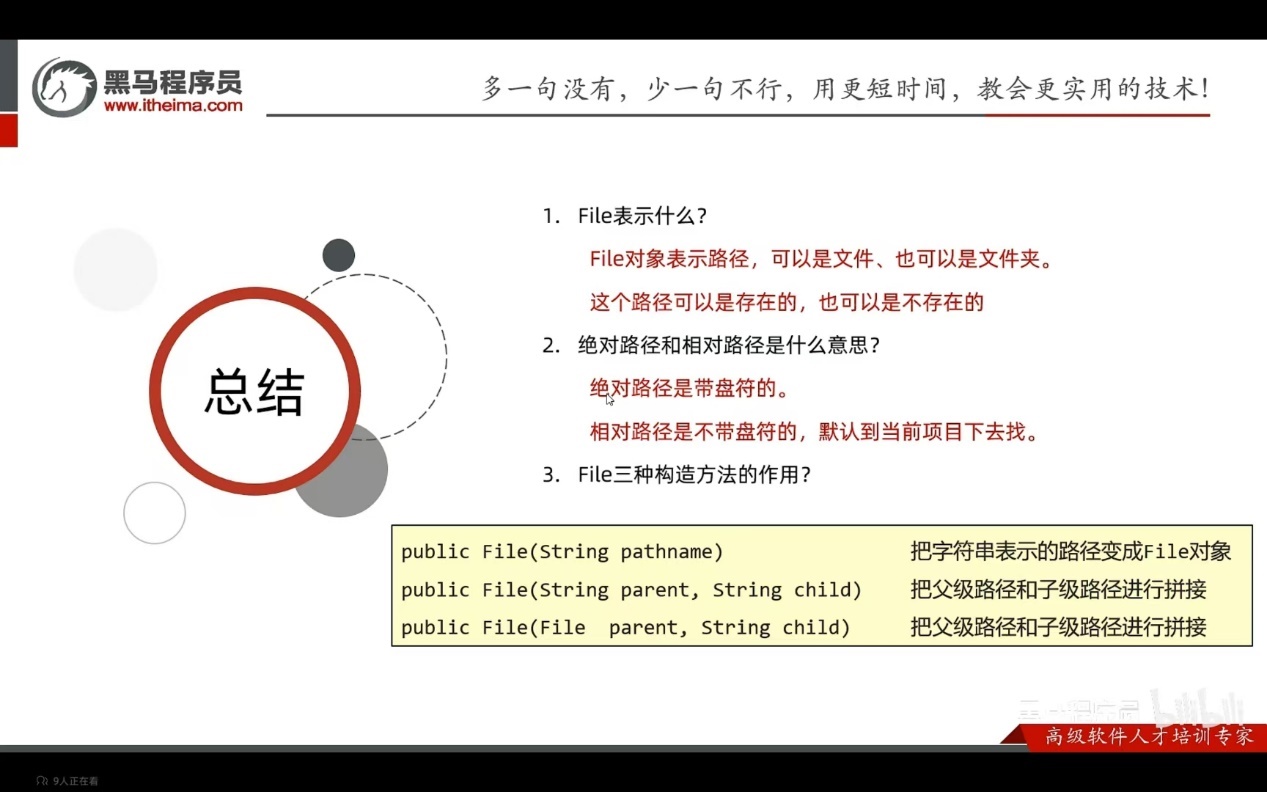
File(有时间看看第五题)
File对象就表示一个路径,可以是文件的路径,也可以是文件夹的路径
这个路径可以是存在的,也允许是不存在的
常用构造方法
public File(String pathname) 根据文件路径创建文件对象
public File(String parent, String child) 根据父路径名字符串和子路径名字符串创建文件对象
public File(File parent, String child) 根据父路径对应文件对象和子路径名字符串创建文件对象
总结:
File的常见成员方法(判断、获取)

File的常见成员方法(创建、删除)

Delete方法默认只能删除文件和空文件夹,delete方法直接删除不走回收站
File的常见成员方法(获取并遍历)

重点:
- 当调用者File表示的路径不存在时,返回null
- 当调用者File表示的路径不是文件时,返回null
- 当调用者File表示的路径是一个空文件时,返回一个长度为0的数组
- 当调用者File表示的路径是一个有内容文件时,将里面所有文件和文件夹的路径放在file数组中返回
- 当调用者File表示的路径是一个有隐藏文件时,将里面所有文件和文件夹的路径放在file数组中返回,包含隐藏文件
- 当调用者File表示的路径是需要有权限才能访问的文件夹时,返回null

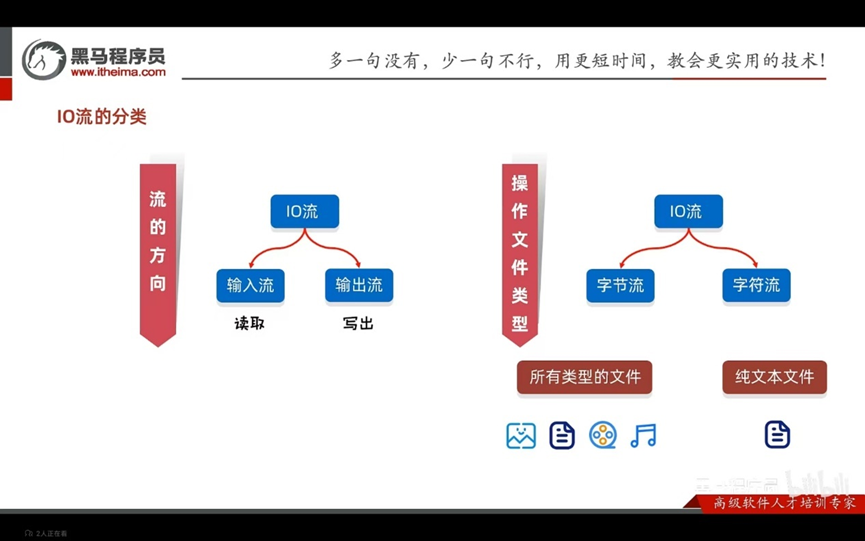
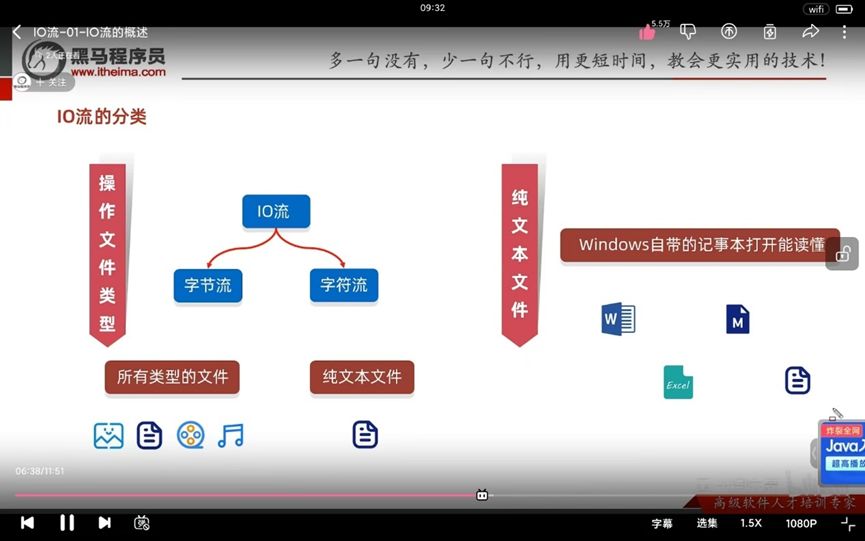
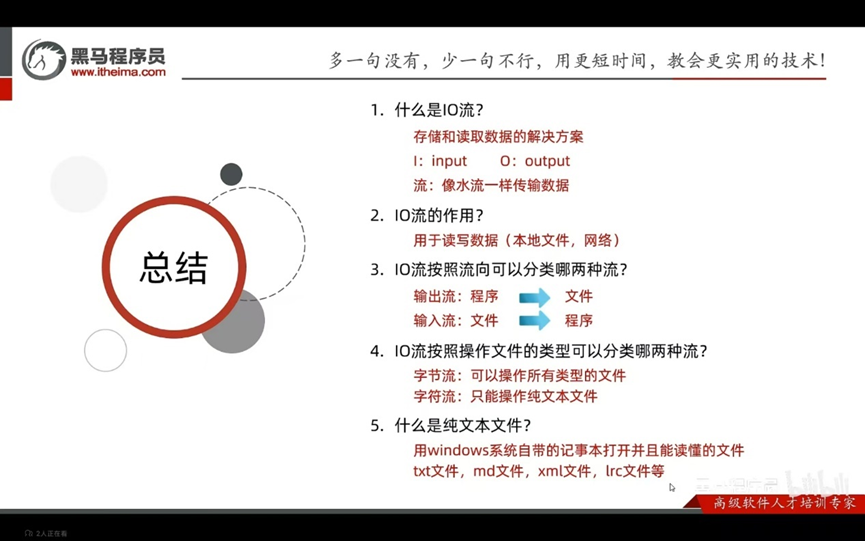
IO流
用于读写文件中的数据(可以读写文件,或网络中的数据)
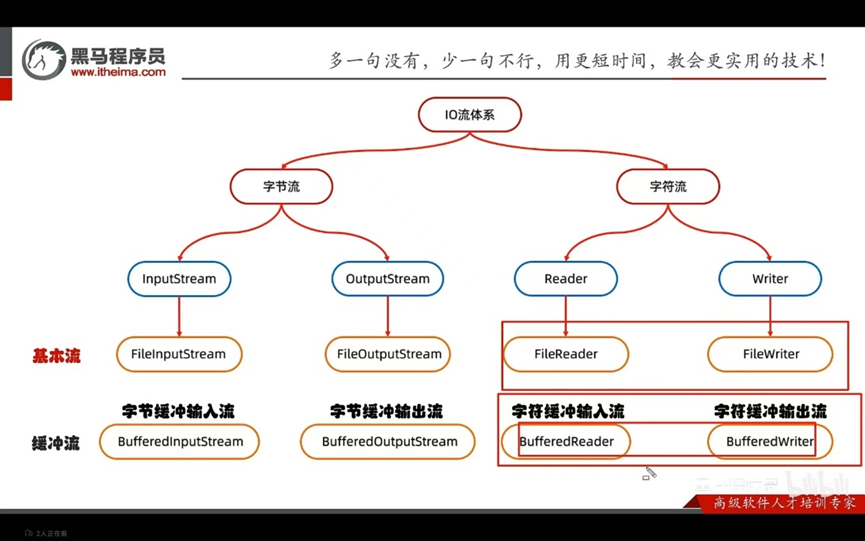
IO流的体系
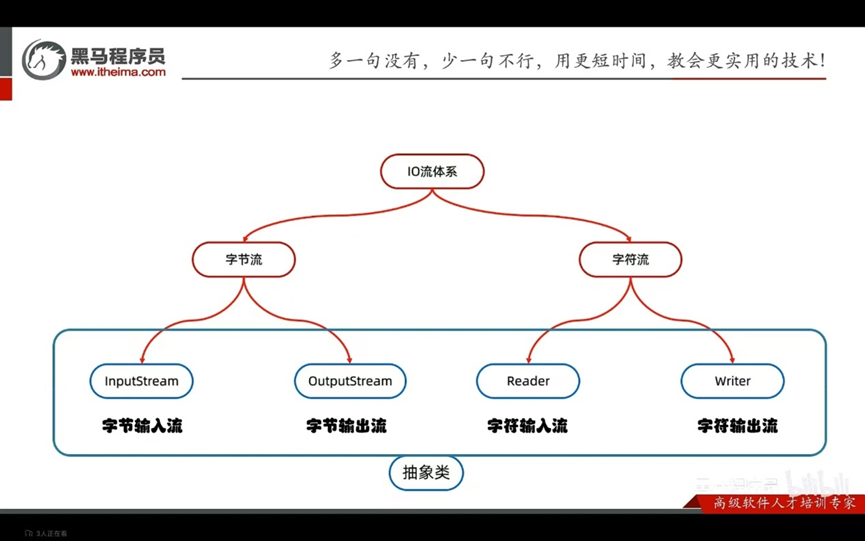
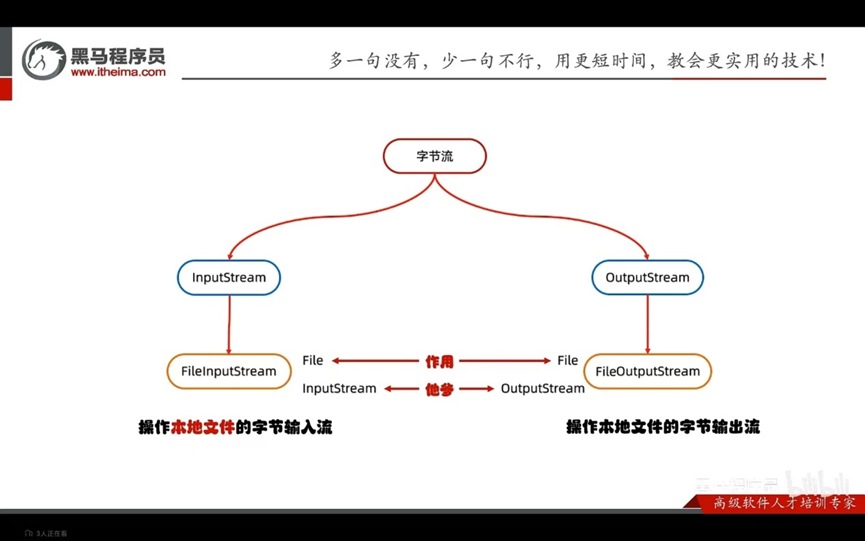
操作本地文件的字节输出流,可以把程序中的数据写到本地文件中
书写步骤:
- 创建字节输出流对象
- 写数据
- 释放资源
总结:

书写数据的三种方式

FileOutStream写数据的两个小问题
换行写
续写

操作本地文件的字节输入流,可以把本地文件中的数据读取到程序中来
书写步骤:
- 创建字节输入流
- 读数据
- 释放资源
书写细节:
- 创建字节输入流对象
细节1:如果文件不存在,就直接报错
- 读取数据
细节1:依次都一个字节,读出来的是数据在ASCII上对应的数字
细节2:读到末尾了,read方法返回-1
- 释放数据
细节1:每次使用完流必须要释放资源
循环读取
FileInputStream一次读写一个字节
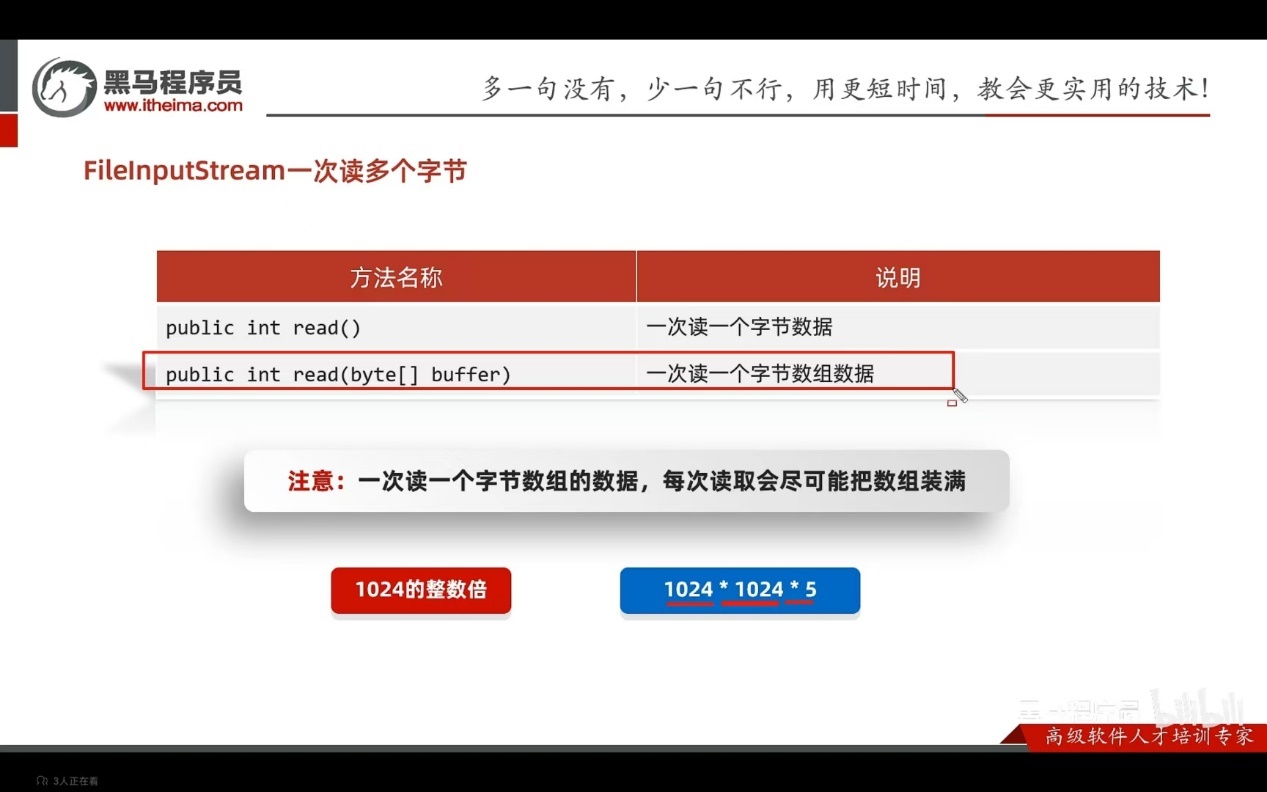
Try…catch异常处理



字节流读取文件时,文件中不要有中文
为什么有乱码?
- 读取数据时未读完整个汉字
- 编码和解码时的方式不统一
如何不产生乱码?
- 不要用字节流去读取文件
- 编码解码时使用同一个码表,同一种编码方式

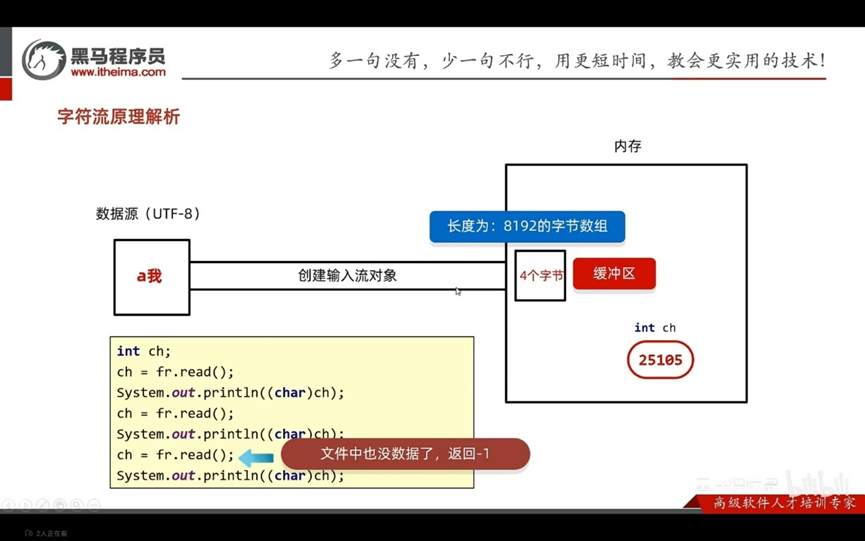
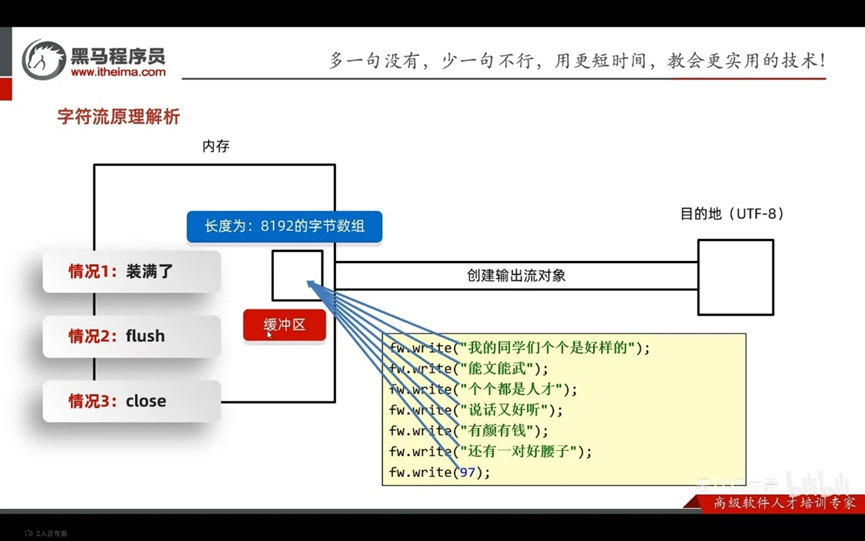
字符流的底层其实就是字节流
字符流 = 字节流 + 字符集
特点:
输入流:一次读一个字节,遇到中文时,一次读多个字节
输出流:底层会把数据按照指定的编码方式进行编码,变成字节再写道文件中
使用场景:
对于纯文本进行读写操作
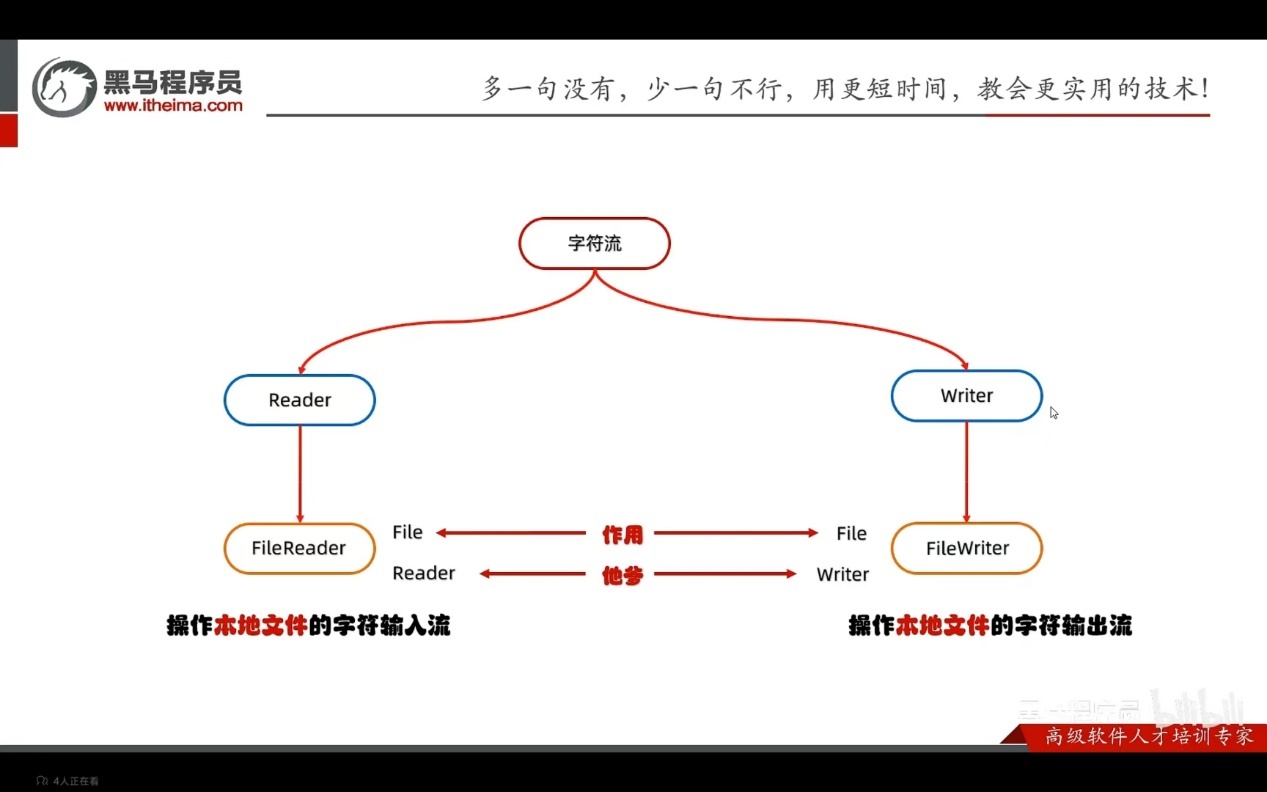



FileWirter构造方法

成员方法:



字符流原理解析

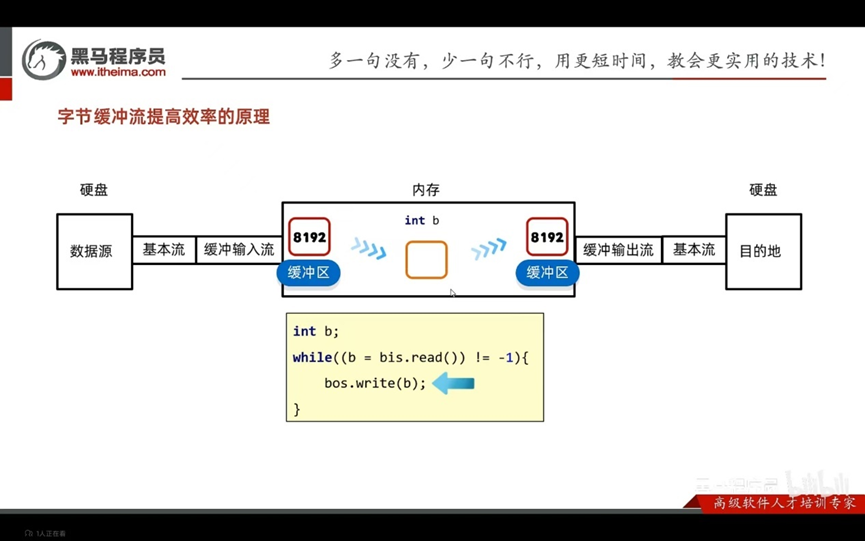
缓冲流:
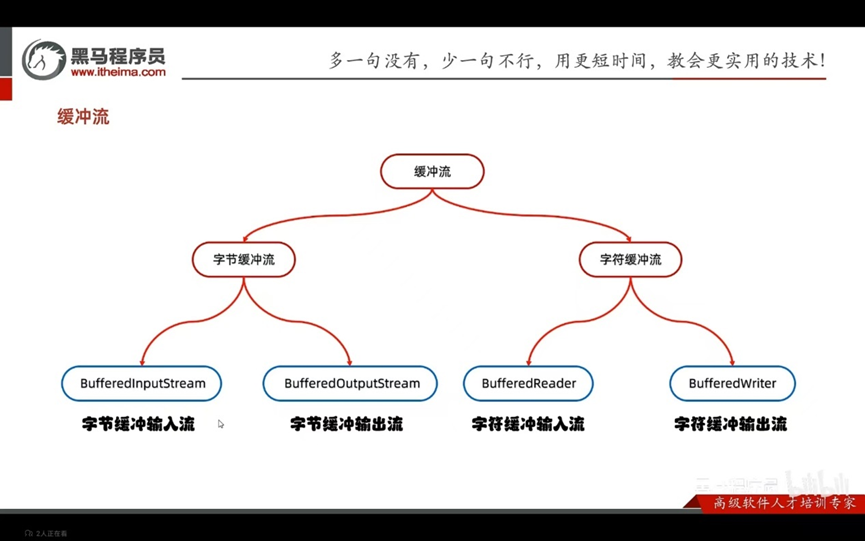
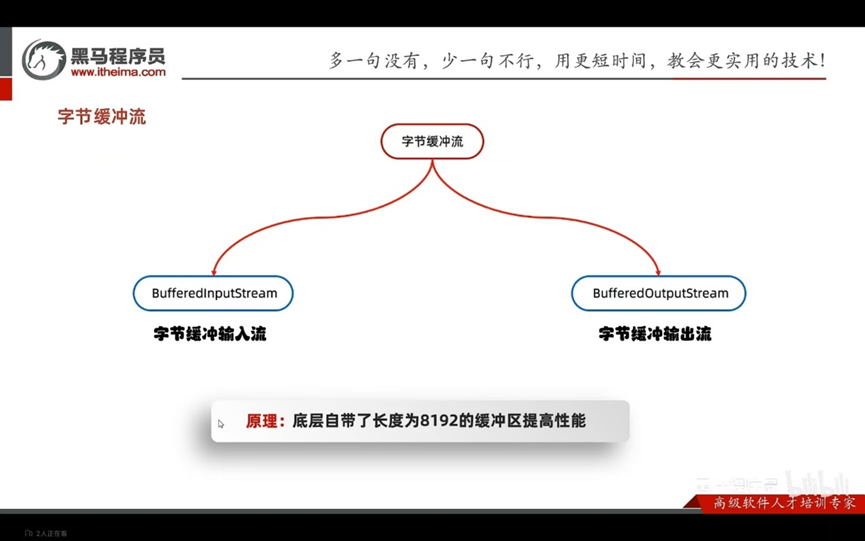

字节缓冲流提高效率的原理
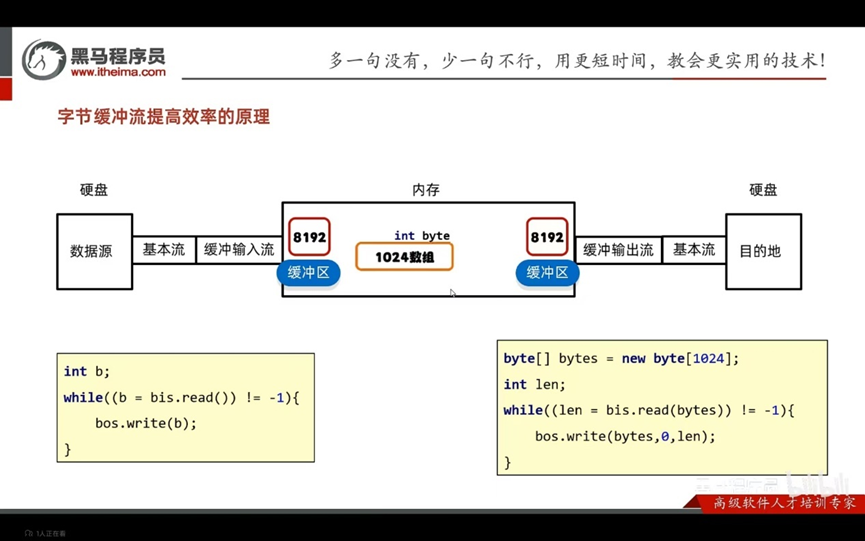
构造方法:
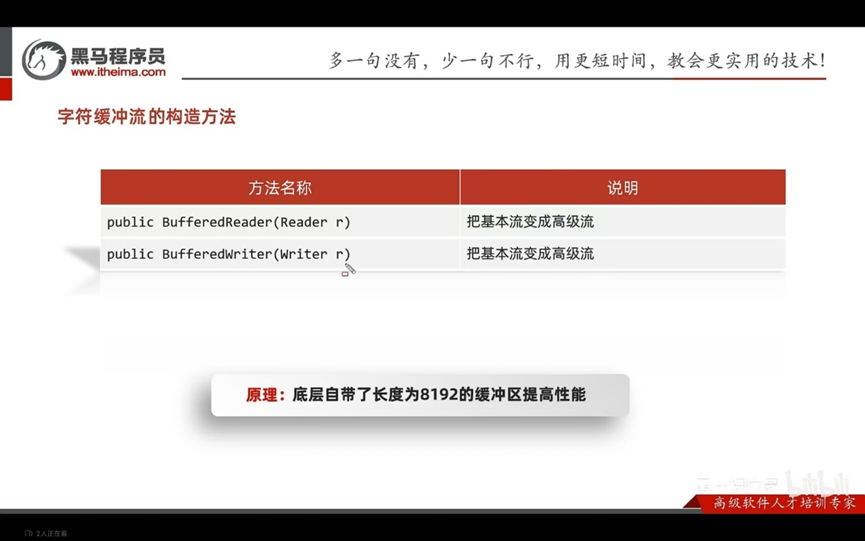

总结

是字符流和字节流之间的桥梁
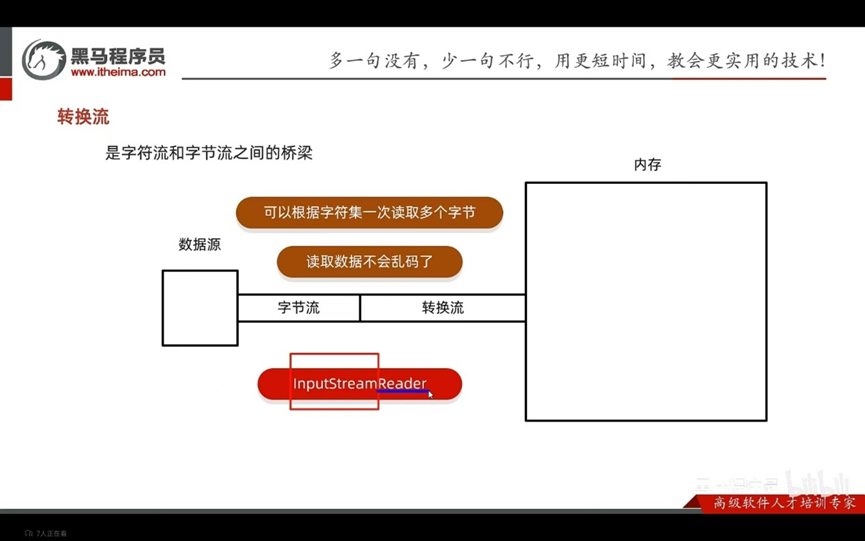
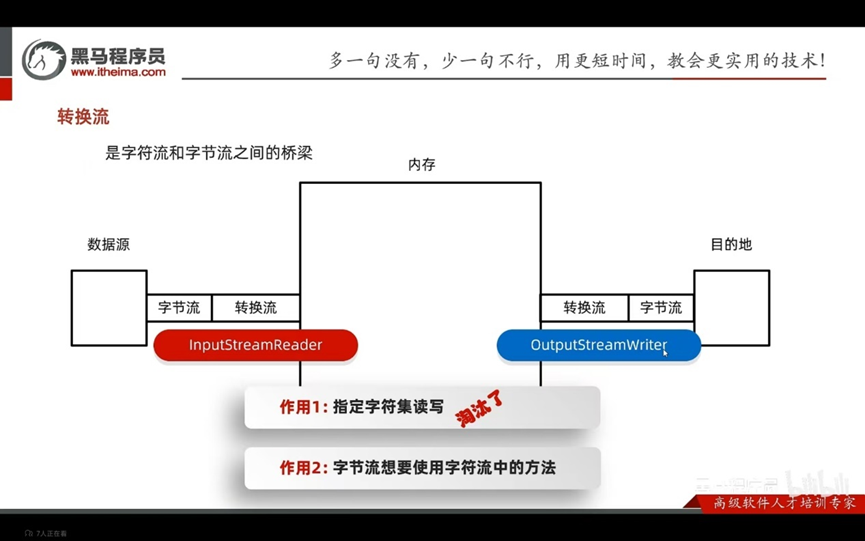
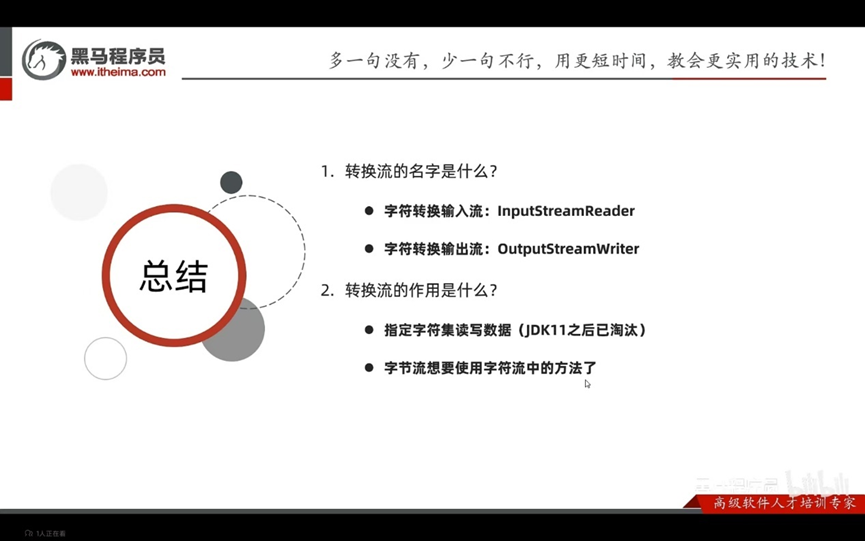
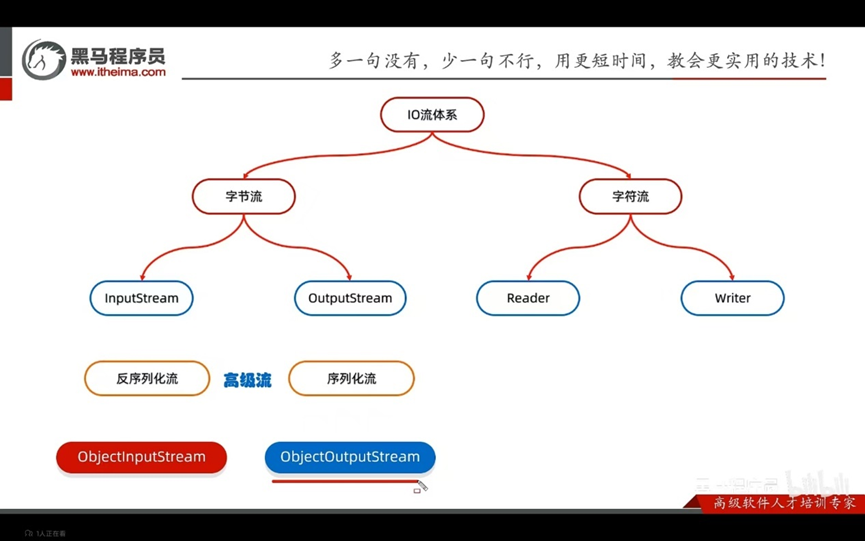
序列化流/对象操作输出流:可以把java中的对象写在本地文件中
构造方法:

小细节:
使用对象输出流将对象保存到文件时会出现NotSerializableException异常
解决方案
需要让JavaBean类实现Serializable接口
反序列化流/对象操作输入流:
可以把序列化到本地文件夹中的对象,读取到程序中来
构造方法:
Public objectInputStream(InputStream out) 把基本流变成高级流
成员方法:
Public Object readObject() 把序列化到本地中的对象,读取到程序中来
序列化流和反序列化流的细节汇总:
- 使用序列化流将对象写到文件时,需要让JavaBean类实现Serializable接口。否则,会出现NotSerializableException异常
- 序列化流写到文件中的数据是不能修改的,一旦修改就无法再次读回来
- 序列化对象后,修改了JavaBean类,再次反序列化,会出现问题,会抛出InvalidClassException异常
- 解决方案:给javabean类添加serialVersionUID(序列号,版本号)
- 如果一个对象中某个成员变量的值不想被序列化,解决方案:给该成员变量加上transient关键字修饰,该关键字标记的成员变量不参与序列化过程
打印流:(不能读只能写)
分类:打印流一般指:PrintStream,PrintWriter两个分类
特点1:打印流只操作文件的目的地,不操作数据源
特点2:特有的写出方法可以实现,数据原样写出
例如:打印97 文件中 97
打印true 文件中:true
特点3:特有的写出方法,可以实现自动刷新,自动换行
打印一次数据 = 写出 + 换行 + 刷新

字节流底层没有缓冲区,开不开自动刷新都一样
成员方法:



总结:

解压缩流/压缩流
Commons-io是apache开源基金组织提供的一组有关IO操作的开源工具包
作用:提高io流的开发效率
使用步骤:
- 在项目中床架一个文件夹:lib
- 将jar包赋值粘贴到lib文件夹
- 右键点击jar包,选择Add as Library->点击ok
- 在类中导包使用
常见方法:
FileUtils类
static void copyFile(File srcFile, File destFile) 复制文件
static void copyDirectory(File srcDir, File destDir) 复制文件夹
static void copyDirectoryToDirectory(File srcDir, File destDir) 复制文件夹
static void deleteDirectory(File directory) 删除文件夹
static void cleanDirectory(File directory) 清空文件夹
static String readFileToString(File file, Charset encoding) 读取文件中的数据变成成字符串
static void write(File file, CharSequence data, String encoding) 写出数据
IOUtils类
public static int copy(InputStream input, OutputStream output) 复制文件
public static int copyLarge(Reader input, Writer output) 复制大文件
public static String readLines(Reader input) 读取数据
public static void write(String data, OutputStream output) 写出数据


Hutool工具包

线程
线程是操作系统能够运行调度的最小单位,它被包含在进程中,是进程中的实际运作单位
进程:
进程是程序运行的基本执行实体
总结:
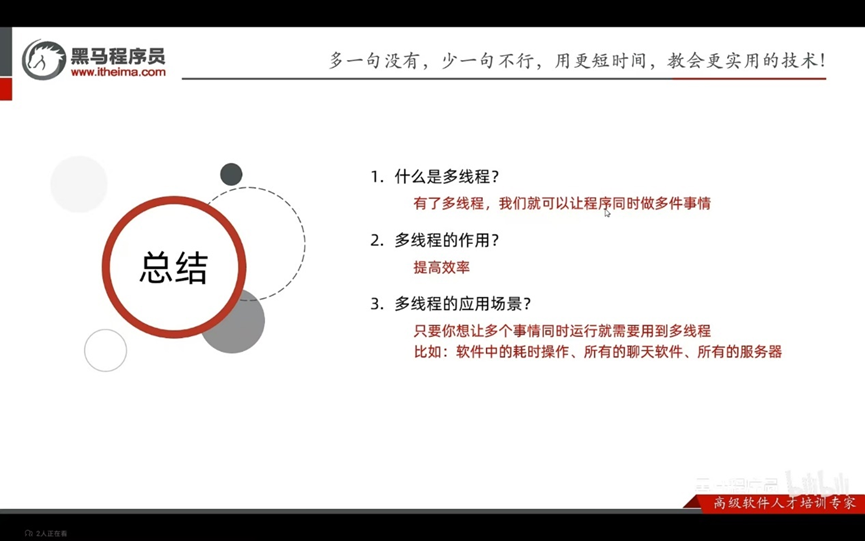
并发和并行
并发:在同一时刻,有多个指令在单个cpu上交替进行
并行:在同一时刻,有多个指令在多个cup上同时执行
多线程的实现方式:
- 继承Thread类的方式进行实现
- 实现Runnable接口的方式进行实现
- 利用Callable接口和Future接口方式实现
多线程三种实现方式对相比
第一种:
优点:
编程简单,可以直接使用Thread类中的方法
缺点:
可扩展性较差,不能再继承其他类
第二种:
第三种:
优点:
扩展性强,实现类该接口的同时还可以继承其他类
缺点:
编程相对复杂,不能直接使用Thread类中的方法
常见的成员方法:
方法名 | 说明 |
| ------------------------------ | ------------------------ |
|void setName(String name) | 将此线程的名称更改为等于参数name |
| String getName() | 返回此线程的名称 |
| Thread currentThread() | 返回对当前正在执行的线程对象的引用 |
| static void sleep(long millis) | 使当前正在执行的线程停留(暂停执行)指定的毫秒数 |
|final int getPriority() | 返回此线程的优先级 |
| final void setPriority(int newPriority) | 更改此线程的优先级线程默认优先级是5;线程优先级的范围是:1-10 |
| void setDaemon(boolean on) | 将此线程标记为守护线程,当运行的线程都是守护线程时,Java虚拟机将退出 |

抢占式调度(随机)
|final int getPriority() | 返回此线程的优先级 |
| final void setPriority(int newPriority) | 更改此线程的优先级线程默认优先级是5;线程优先级的范围是:1-10 |
final void setDaemon(boolean on) 设置为守护线程
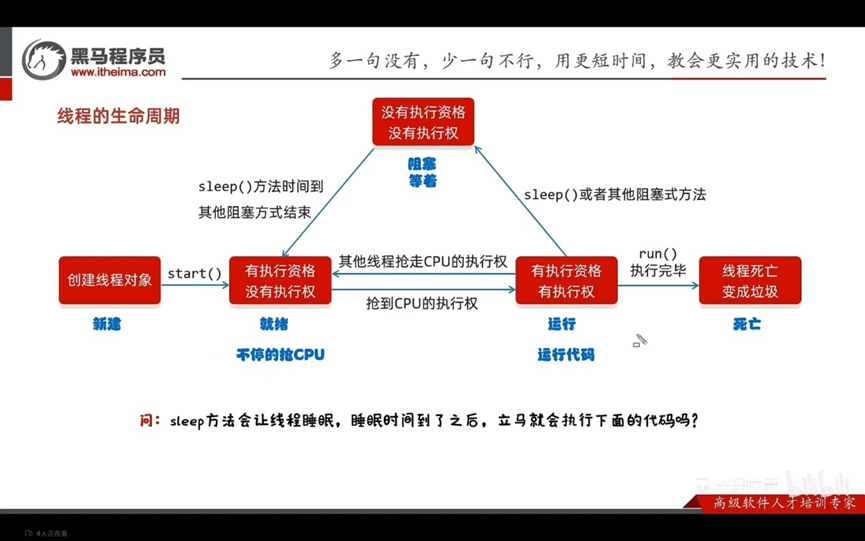
线程的生命周期:
同步代码块:
把操作共享数据的代码锁起来
格式:
Synchronized(锁){
操作共享代码块
}
特点1:
锁默认打开,有一个线程进去了,锁自动关闭
特点2:里面的代码全部执行完毕了,线程出来,锁自动打开
同步方法:
就是把Synchronized关键字加到方法上
格式:
修饰符Synchronized返回值类型 方法名(方法参数){…}
特点1:
同步方法是所著方法里面所有的代码
特点2:
锁对象不能自己指定
非静态:this
静态:当前类的字节码文件对象
Lock锁
死锁:(问题)
别嵌套锁
生产者和消费者(等待唤醒机制)
生产者消费者是一个十分经典的多线程协作的模型
| 方法名 | 说明 |
| ---------------- | ---------------------------------------- |
| void wait() | 导致当前线程等待,直到另一个线程调用该对象的 notify()方法或 notifyAll()方法 |
| void notify() | 唤醒正在等待对象监视器的单个线程 |
| void notifyAll() | 唤醒正在等待对象监视器的所有线程 |
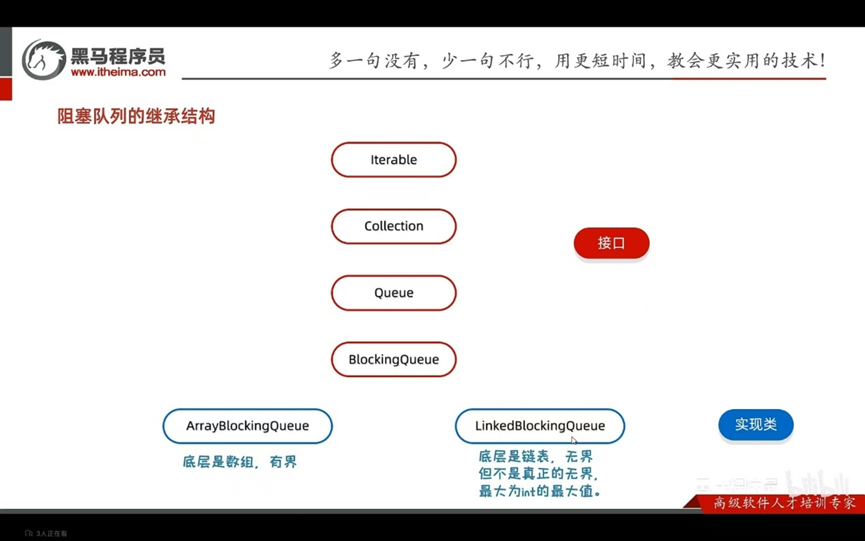
等待唤醒机制(阻塞队列方式实现)
线程的状态:

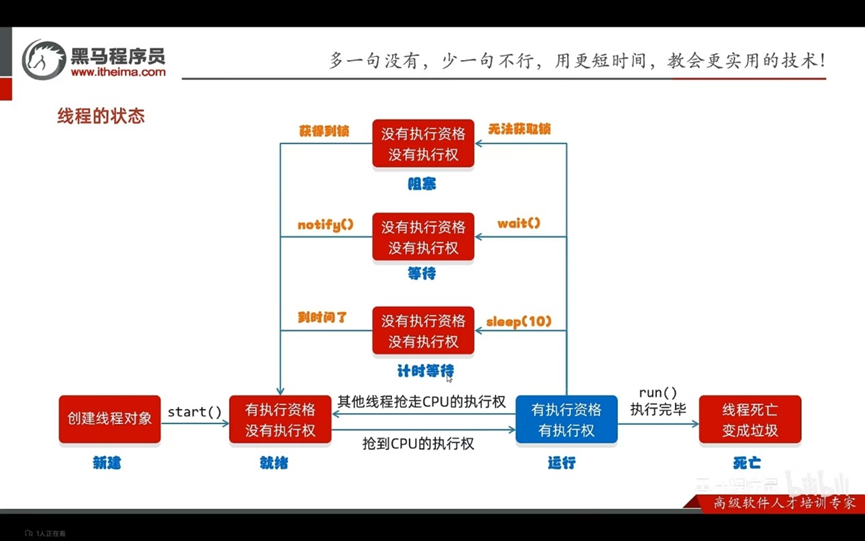
没有运行状态
线程获取了cup之后java就给了操作系统了就不管了所以不在定义状态
线程池:
主要核心原理:
- 创建一个池子,池子中是空的
- 提交任务,池子会创建新的线程对象,任务执行完毕,线程归还给池子下回再提交任务时,不需要创建新的线程,直接服用一头的线程即可
- 但是如果提交任务时,池子中没有空闲线程,也无法创建新的线程,任务就会排队等待
实现:
- 创建线程池
- 提交任务
- 所有的人物全部执行完毕,关闭线程池(实际任务执行过程中线程池一般不关闭,服务器都是一直在运行的)
Excutors:线程池的工具类通过调用方法返回不同类型的线程池对象
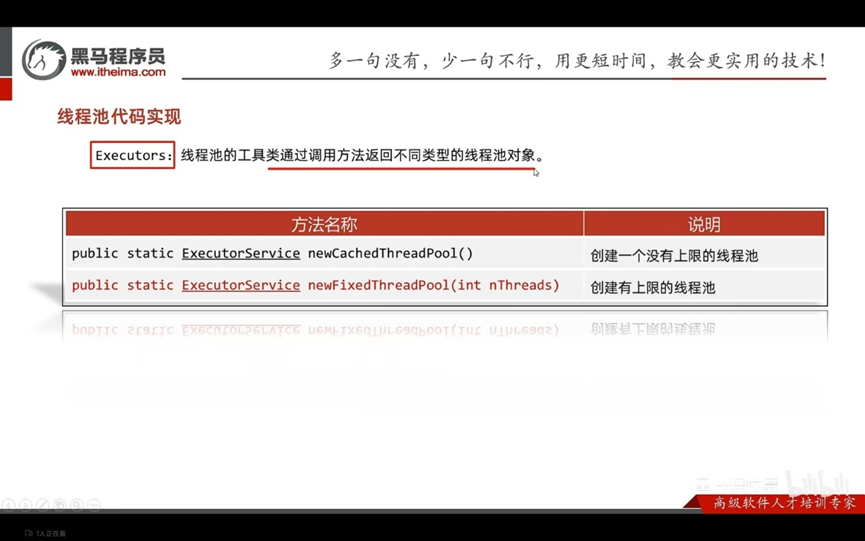
public static ExecutorService newCachedThreadPool() 创建一个没有上限的线程池
public static ExecutorService newFixedThreadPool (int nThreads) 创建有上限的线程池

小结:


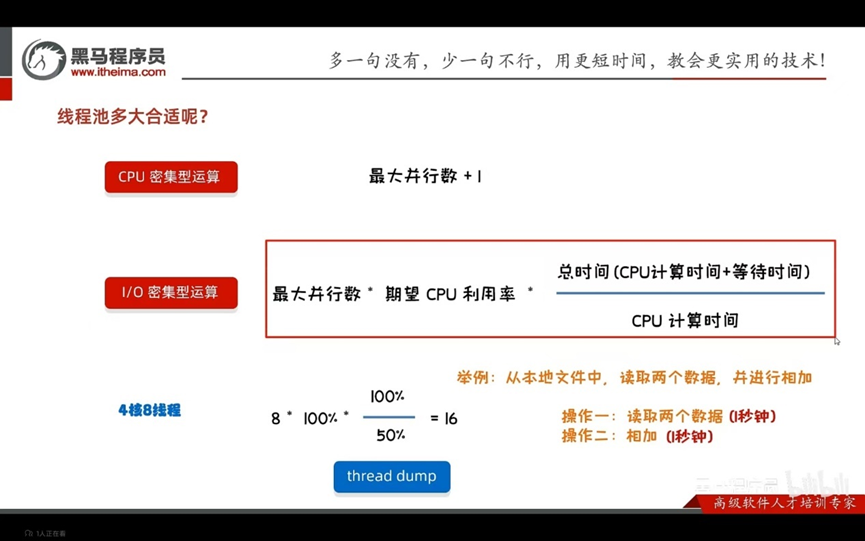
线程池多大合适
CPU密集型运算(计算较多) 最大并行数+1
i/o密集型运算(读取较多) 最大并行数*期望CUP利用率*总时间(CPU计算时间+等待时间)/CUP计算时间
网络编程的概念:
在网络通信协议下,在不同计算机上运行的程序,进行数据传输。
应用场景:
即时通信、网游对战、金融证券、国际贸易、邮件、等等
不管是什么场景,都是计算机跟计算机之间通过网络进行数据传输
Java中可以使用java.net包下的技术轻松开发出常见的网络应用程序
常见的软件架构:bs、cs
C/S:Client/Server:客户端/服务器:在用户本地需要下载并安装客户端程序,在远处有一个服务器端程序
B/S:browser/server:浏览器/服务器:只需要一个浏览器,用户通过不同的网址。客户网文不同的服务器
BS架构的优缺点:
- 不需要开发客户端,只需要页面+服务端
- 用户不用下载,打开浏览器就能使用
- 如果应用过大,用户提体验受到影响
CS架构的优缺点:
- 画面可以做的非常精美,用户体验好
- 需要开发客户端,也需要开发服务端
- 用户需要下载和更新的时候太麻烦


网络编程三要素:
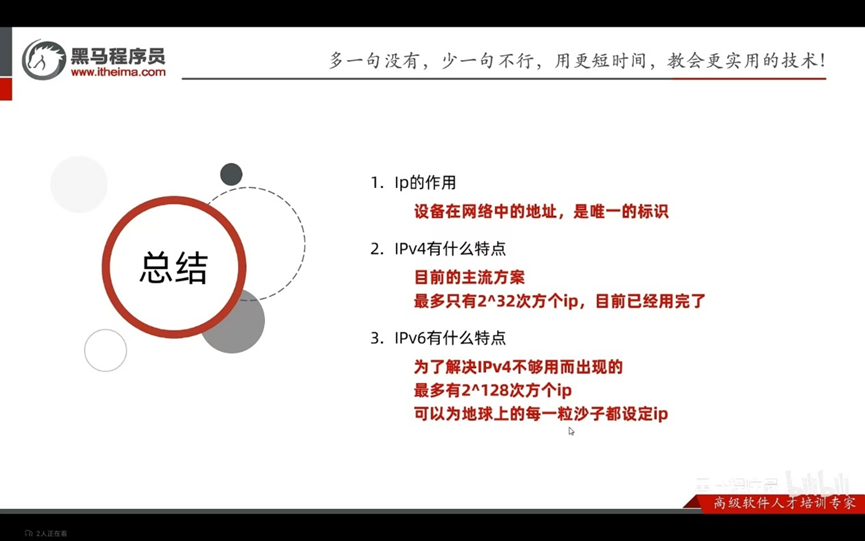
确定对方电脑在互联网上的地址:ip:设备在网络中的地址,是唯一的标识
确定接收数据的软件:端口号:应用程序在设备中唯一的标识
确定网络传输的规则:协议:数据在网络当中传输的规则,常见的协议有UDP,TCP,http,https,ftp

IP:
全程:Internet protocol,是互联网协议地址,也称为IP地址。
是分配给上网设备的数字标签。
通俗理解:
上网设备在网络中的地址,是唯一的
常见的IP分类为:
IPv4、IPv6
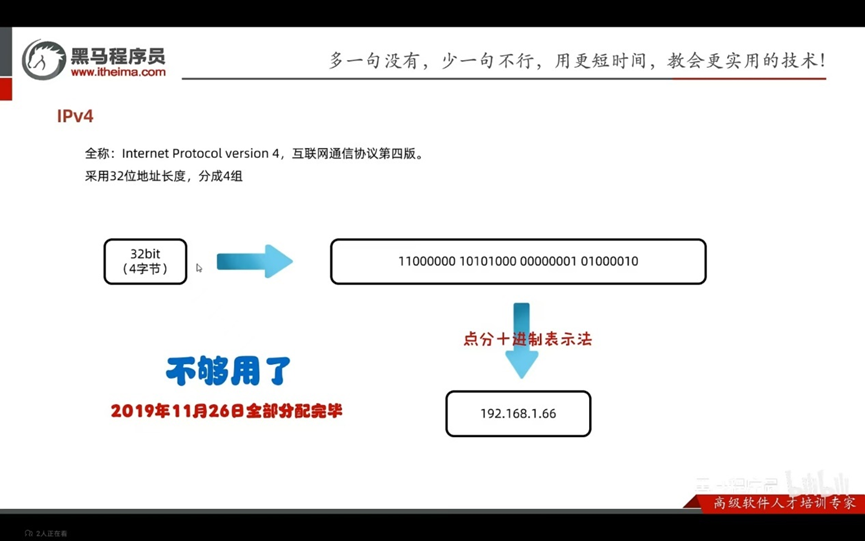
IPv4:
全称:Internet protocol version4,互联网通信协议第四版
采取了32位地址长度,分为4组
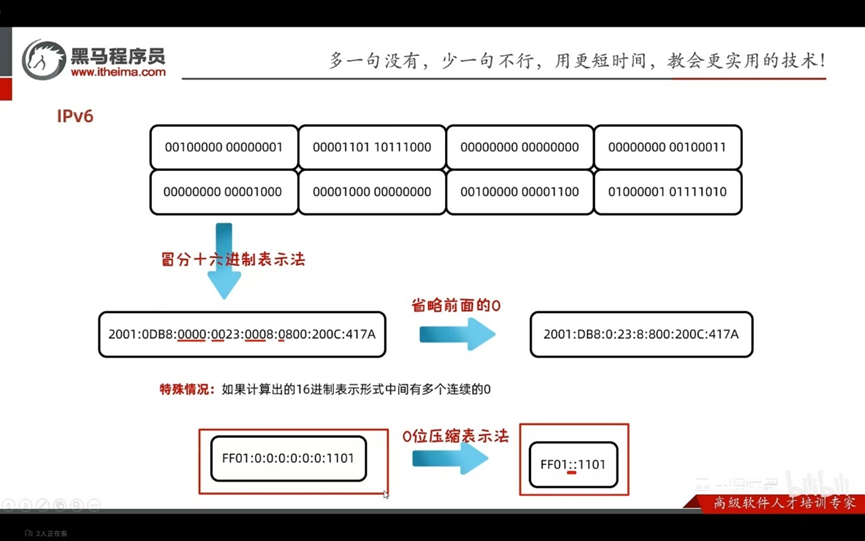
IPv6:
全称:Internet protocol version6,互联网通信协议第六版
由于互联网的蓬勃发展,IP地址的需求量愈来愈大,而IPv4的模式下IP的总数是有限的,采用128位地址长度,分成8组。

目前如何解决IP不够用的问题:
IPv4的地址分类形式:
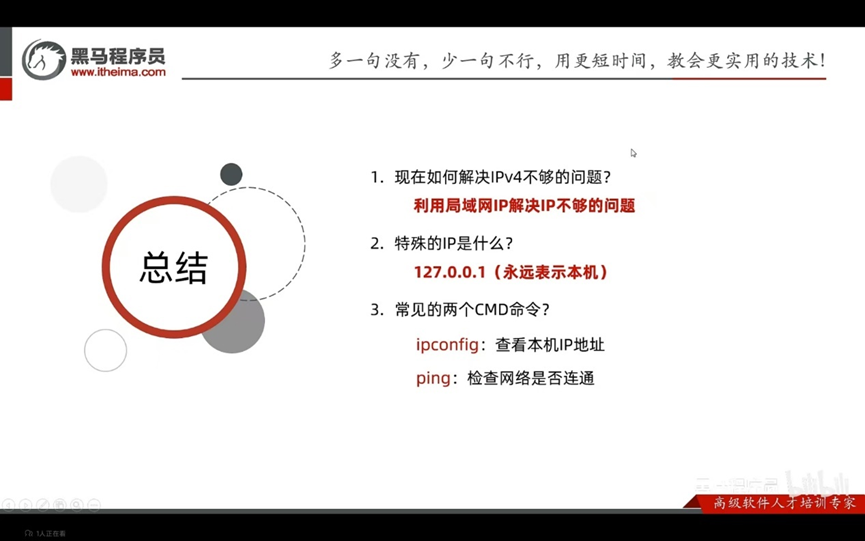
- 公用网络(万维网使用)和西游地址(局域网使用)。
- 192.168.开头的是私有地址,范围即为192.168.0.0—192.168.255.255,专门为组织机构内部服务,以此节省IP
特殊IP地址:
127.0.0.1也可以是localhost:是送回地址也称本地回环地址,也称本机IP,永远只会寻找当前所在本机。
常见的CMD命令
Ipconfig:查看本机IP地址
Ping:检查网络是否连通
InetAddress的使用
端口号:
应用程序在设备中唯一的标识。
端口号:由两个字节表示的整数,取值范围:0-65535
其中0-1023之间的端口号用于一些知名的网络服务或者应用
我们自己使用1024以上的端口号就可以了。
注意:一个端口号只能被一个应用程序使用。
协议:
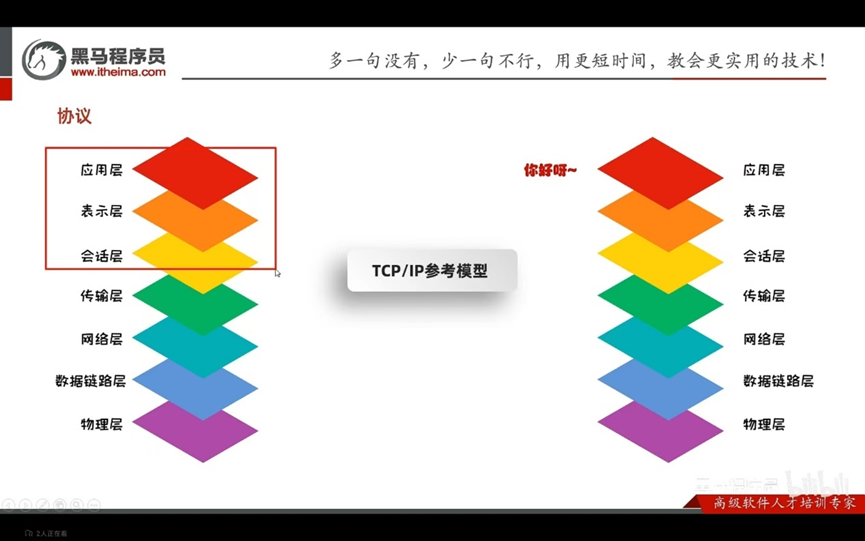
计算机网络中,连接和通信的规则被称为网络通信协议
OSI参考模型:世界互联协议标准,全球通信规范,单模型过于理想化,未能在因特网上进行广泛推广TCP/IP参考模型(或TCP/IP协议):事实上的国际标准。

之前的:
后来的:

UDP协议:
- 用户数据报协议(User Datagram Protocol)
- UDP是面向无连接通信协议
- 速度快,有大小限制一次最多发送64k,数据不安全,易丢失数据
TCP协议:
- 传输控制协议TCP(Transmission Control Protocol)
- TCP协议是面向连接的通信协议
- 速度慢,没有大小限制,数据安全
UDP通信程序(发送数据)
UDP通信程序(接收数据)
UDP的三种通信方式:
- 单播
以前写的代码都是单薄
- 组播
组播地址:224.0.0.0~239.255.255.255
其中224.0.0.0~224.0.0.255为预留的组播地址
- 广播
广播地址:255.255.255.255
TCP的通信程序
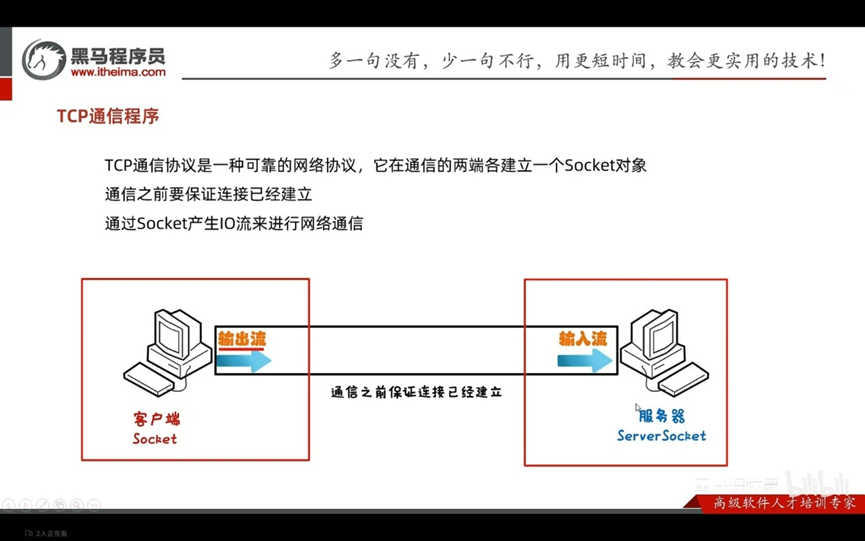
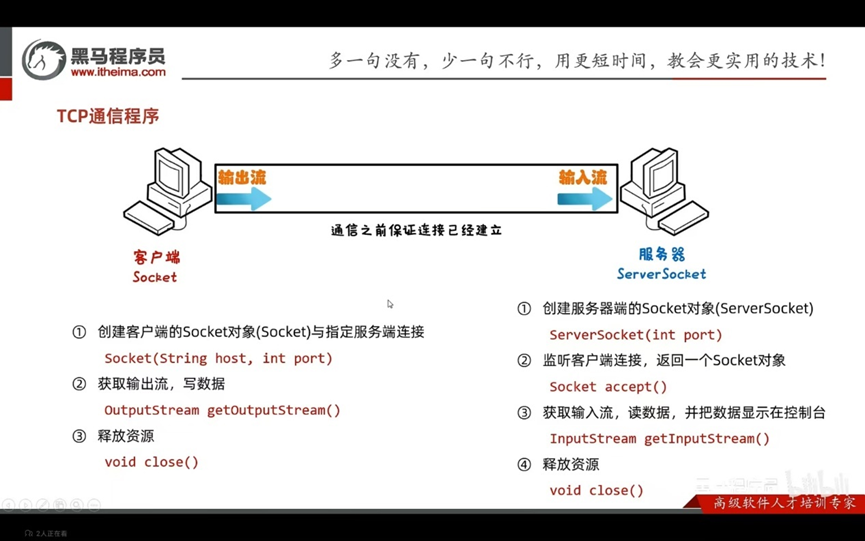
TCP通信协议是一种可靠的网络协议,它在通信的两端各建立一个Scoket对象
通信之前要保证链接呢已经建立
通过Scoket产生IO流来进行网络通信
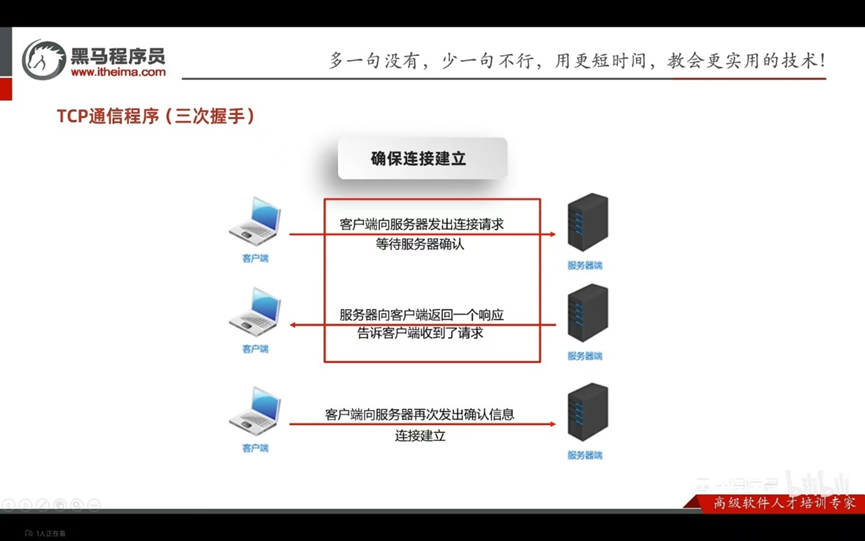
TCP通信程序(三次握手)
确保连接的建立
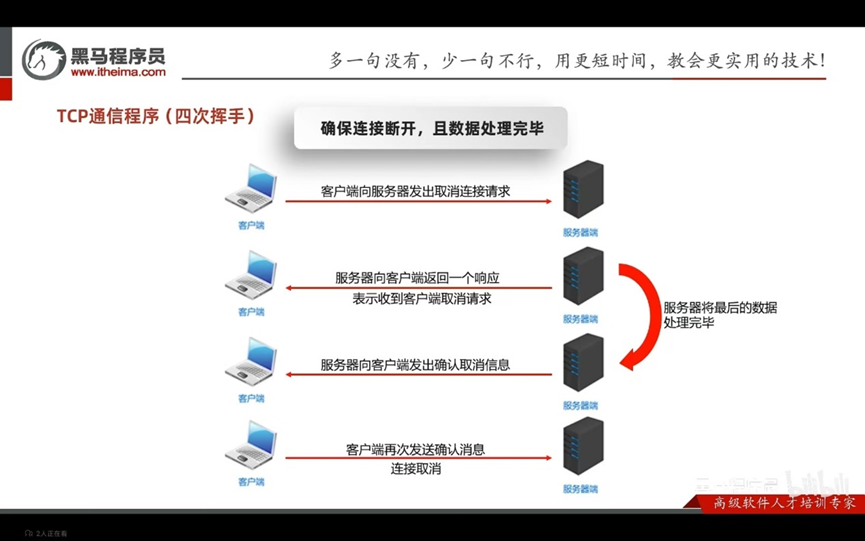
TCP通信程序(四次握手)
确保连接断开,且数据处理完毕
反射允许对封装类的字段(成员变量),方法(成员方法)和构造函数(构造方法)的信息进行编程访问
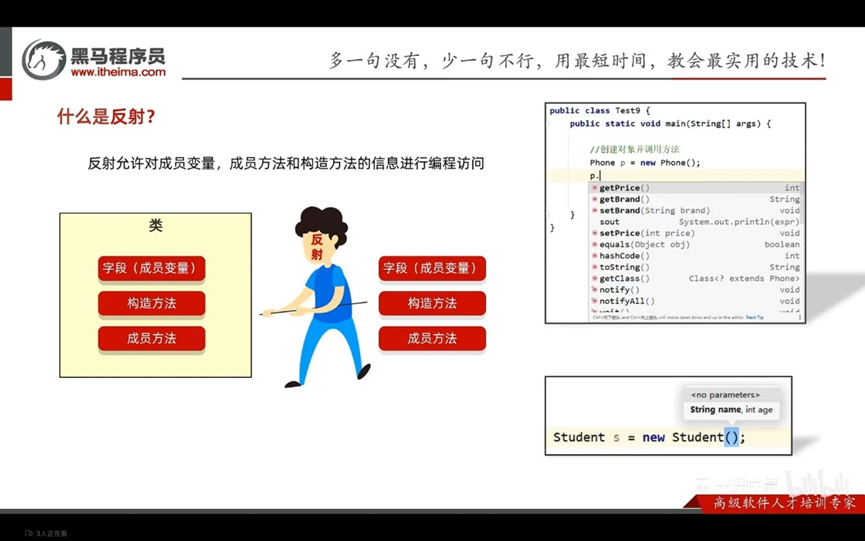

获取Class对象的三种方式:
- Class.forName(“全类名”)
- 类名.class
- 对象.getClass()



反射的作用
- 获取一个类里面所有的信息,获取到之后,在执行其他的业务逻辑
- 结合配置文件,动态的创建对象并调用
总结:

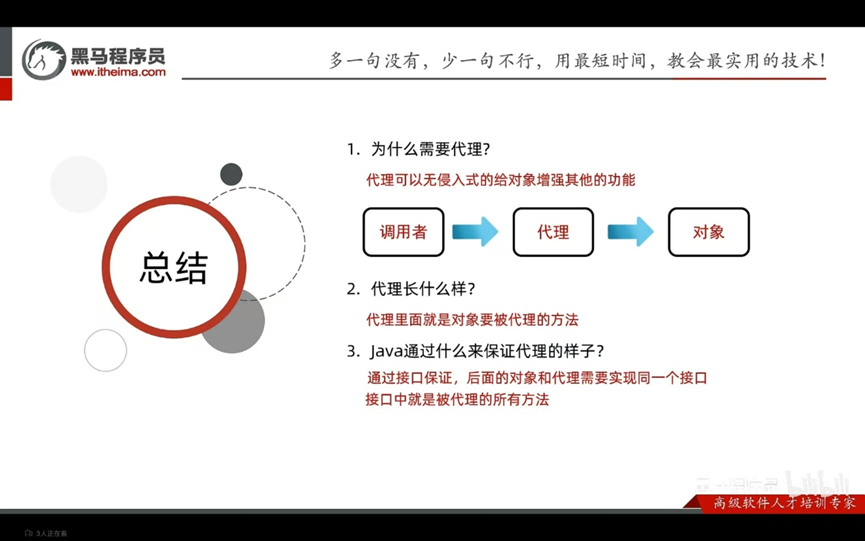
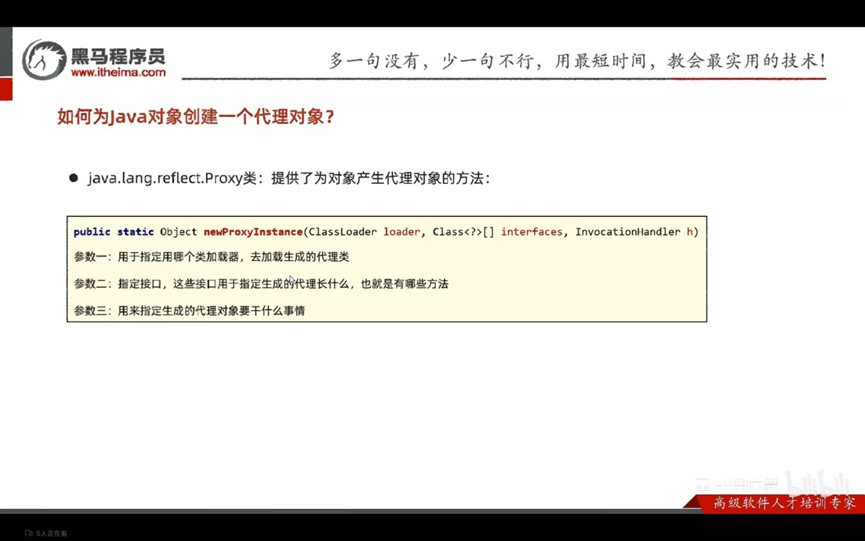
概念:无入侵式的给代码增加额外的功能
以上就是我自己整理的javase阶段的所有笔记,虽然不是很全但是一定很真,具体很多细节还是要靠各位去深入学习,毕竟java知识点太多了,加油程序员!!!

















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









