







 该研究关注单目深度估计,采用无监督学习,同时估计深度和ego-motion。通过几何结构建模场景和运动物体,解决高动态场景中的深度学习难题。方法包括在线优化以适应新环境,以及对运动物体的3D运动建模。通过引入物体大小约束和在线精细化技术,改善深度预测的准确性。
该研究关注单目深度估计,采用无监督学习,同时估计深度和ego-motion。通过几何结构建模场景和运动物体,解决高动态场景中的深度学习难题。方法包括在线优化以适应新环境,以及对运动物体的3D运动建模。通过引入物体大小约束和在线精细化技术,改善深度预测的准确性。
Struct2Depth:Depth Prediction Without the Sensors:Levearging Structure for Unsupervised learning from Monocular Videos
摘要:领域还是单目深度估计,无监督,同时估计深度和ego-motion。
1.在学习过程中引入几何结构,对场景和运动物体建模。相机自我运动和物体运动从单目视频中学习。
2.引入一种在线细化方法,使得动态学习,跨领域使用
监督学习的场景深度需要深度传感器,可能并不可靠,因为他们引入自己的噪声。一些无监督深度估计方法提出来,证明无监督预测方法可能比传感器监督的方法更准确,主要是因为传感器读数问题,比如传感值丢失或噪声。
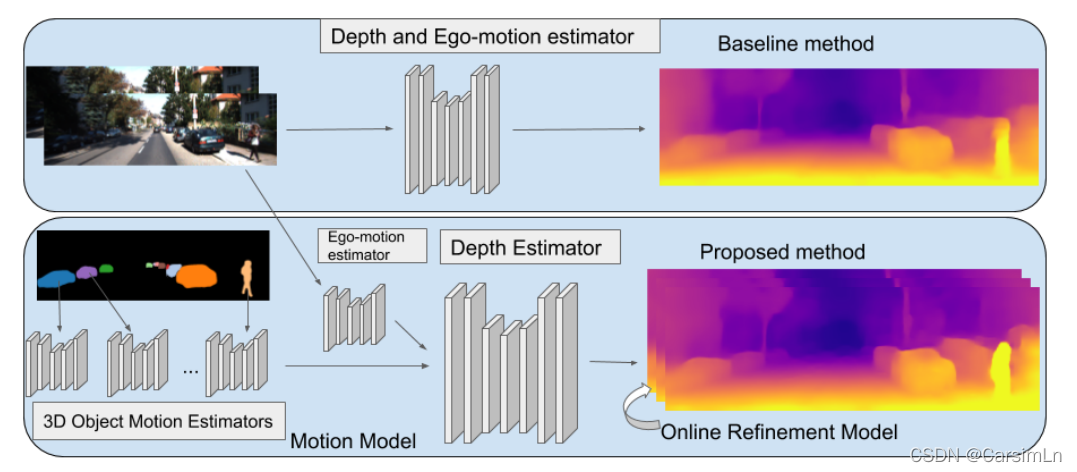
这项研究:建模运动物体的3D运动,自我运动,在线优化适应新环境。
使用有原则的处理运动物体方法和新引入的物体大小约束,我们是第一个有效地从高度动态的场景中学习的放啊。
我们的方法引入结构在学习过程中通过表现物体再3D和建模运动作为SE3transforms。当然,这些操作都是完全可微的。
Previous Work:
主要问题处在high dynamic scenes,as they can not explain object motion。因此出现了一些光流方法,
Main Method
1:model dynamic scenes by
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3953
3953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









