 利用背景去除和OpenCV实现图像矫正
利用背景去除和OpenCV实现图像矫正





图像矫正技术用于修正因透视、镜头畸变等导致的几何失真,以及调整颜色偏差。常用方法包括透视变换、镜头畸变校正、白平衡调整和去噪滤波,广泛应用于摄影、文档扫描、医学成像等领域。
预先安装环境
本案例使用环境
- Python3.10.2
- win11
(Linux系统如果安装了python3也可以使用)
环境安装
前往python官网下载python3版本,官网Windows | Python.org

windows版本下载网址如下
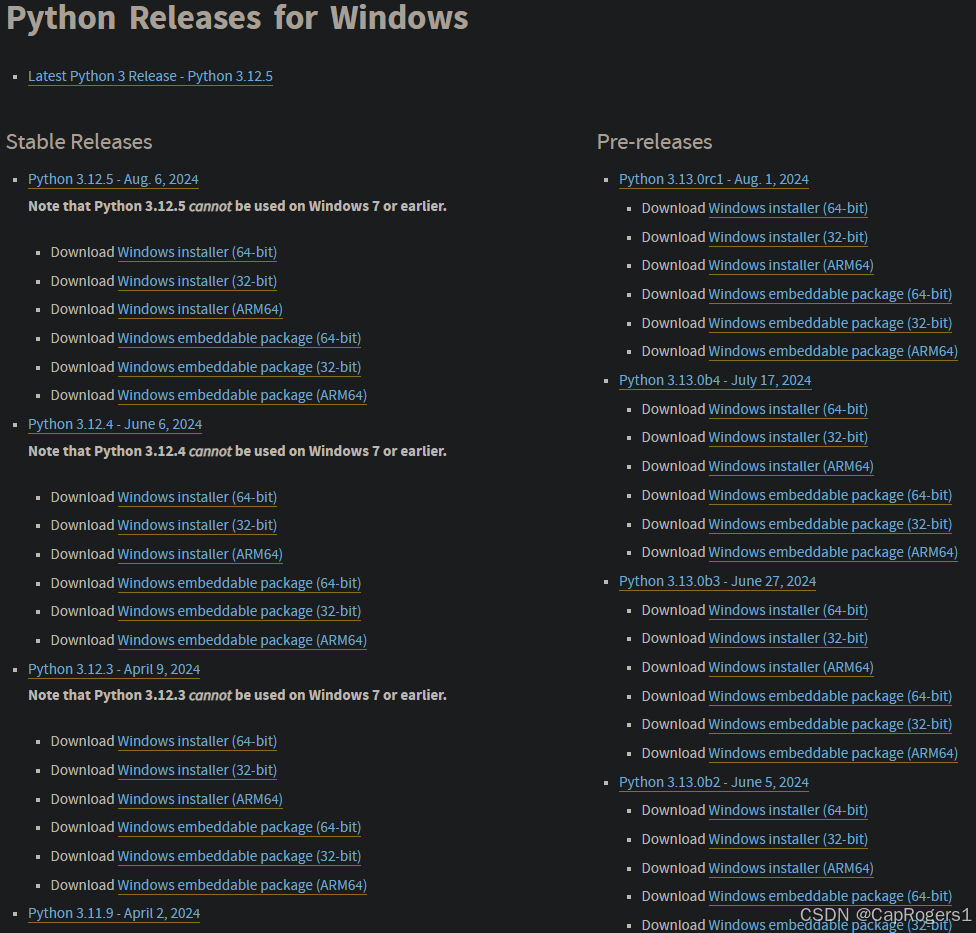
选择任意一个版本(大于3.8版本)的64或者32bit版本:
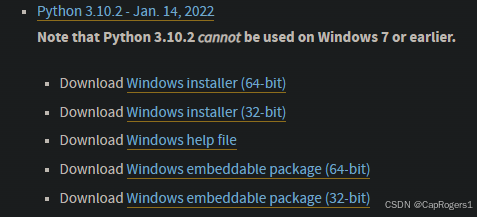
下载python3后点击exe执行文件安装,安装界面如下:
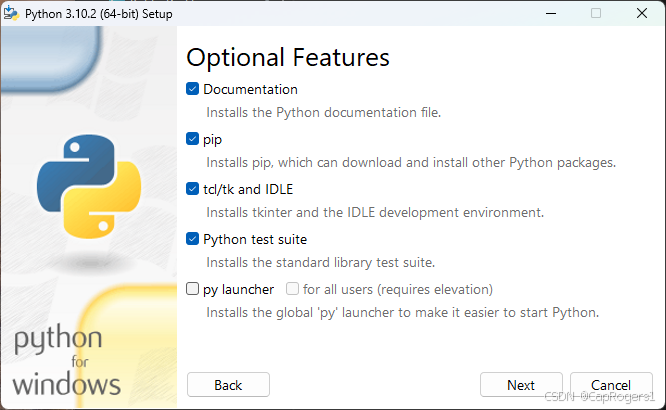
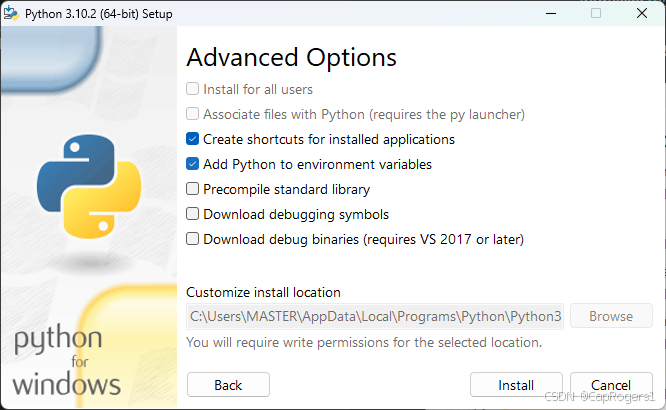
注意勾选添加环境变量(Add Python to environment variable)不然还需要手动添加环境变量,添加python环境变量详见:python手动添加环境变量(超详细)
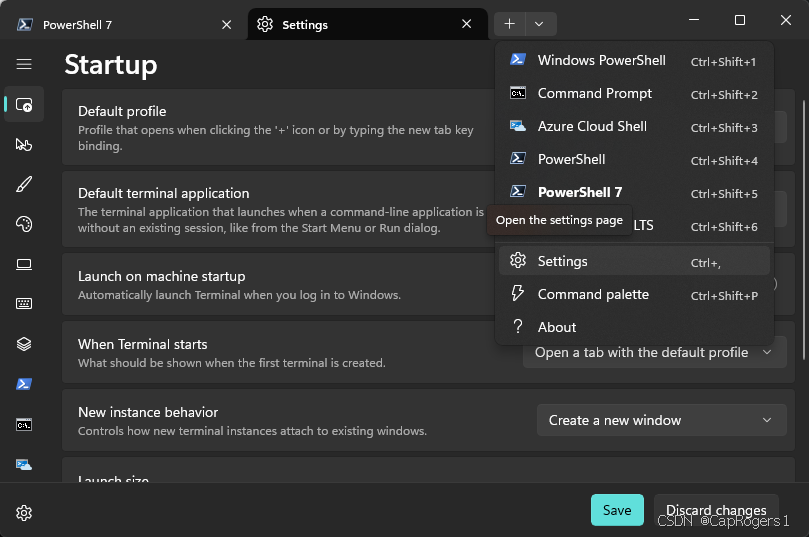
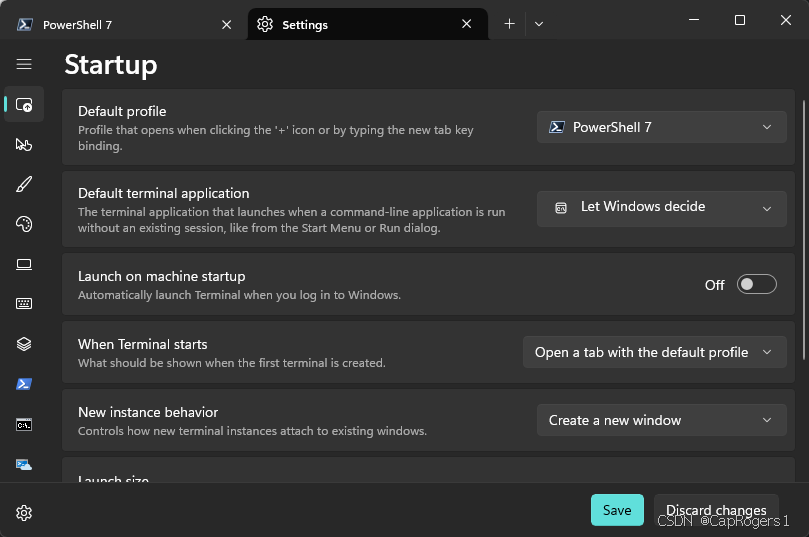
打开win系统下的终端Terminal并点击设置选择PowerShell7或者Command Prompt作为默认配置:
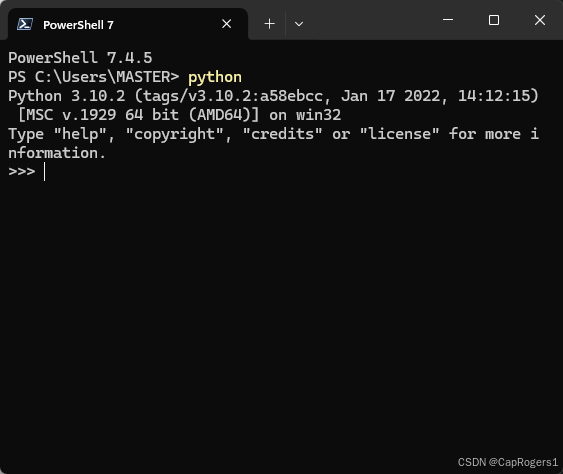
例如打开PS7,在python环境变量设置好后输入python会显示如下:
虚拟环境
为防止接下来安装的python依赖库和本体内部产生版本冲突首先创建一个虚拟环境
我们先创建一个文件夹IMG-Correction,然后在该文件夹内打开终端:
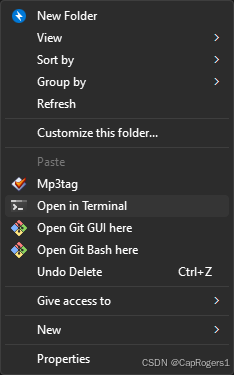
输入下列代码创建一个名字叫venv的虚拟环境:
python -m venv venv输入下列代码进入这个创建的虚拟环境:
.\venv\Scripts\Activate.ps1如果是linux系统创建并进入虚拟环境指令如下(二选一):
pip3 install virtualenv
virtualenv venv
source ./venv/bin/activate
sudo apt-get install python3-venv
python3 -m venv venv
source ./venv/bi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









