







 本文深入探讨HashMap在何种条件下会从链表转换为红黑树。通过代码实验验证,揭示了HashMap在极限状态下面对扩容机制时,如何判断是否进行结构转换的细节。
本文深入探讨HashMap在何种条件下会从链表转换为红黑树。通过代码实验验证,揭示了HashMap在极限状态下面对扩容机制时,如何判断是否进行结构转换的细节。
在极限状态下,HashMap放多少数组会变成红黑二叉树?
回答问起前,我们先回顾下HashMap
HashMap底层是数组+链表的方式
HashMap具有唯一性
每个链条默认情况下在放入第九个元素后,该链条就会自动从Node变成TreeNode
但情况真的是这样吗?
我们可以使用java来进行验证
public class TextMap {
public static void main(String[] args){
HashMap<User, User> map = new HashMap<User, User>();
for(int i = 1; i <= 20; i++){
User user = new User();
map.put(user , user);
System.out.println("i =" + i);
}
}
}
class user{
//保证每个元素放入同一个索引,将hashcode设置为1
@Override
public int hashCode() {
return 1;
}
//保证在同一个索引中,每个元素不会因为相同被覆盖,将equles设置为false
@Override
public boolean equals(Object obj) {
return false;
}
}
结果:
当放入到第十个元素时,此时的HashMap还是没有转为红黑二叉树
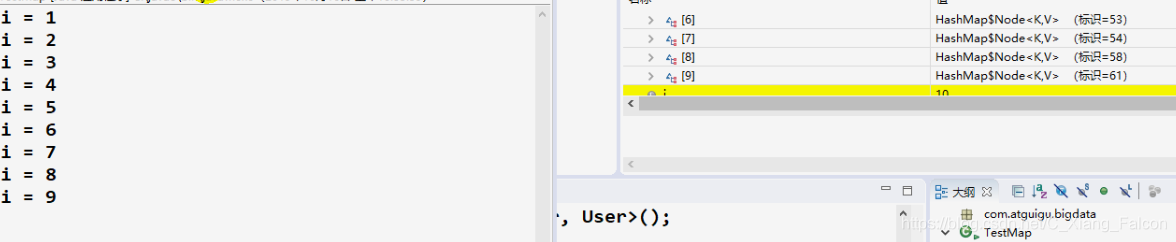
但是当放入第十一个元素的时候,此时的Node转为了TreeNode

因此我们得出结论:
在极限状态下,HashMap在同一索引中放入第十一个元素时才会转变为红黑二叉树
那么由此我们会想为什么会这样呢?Java中明明预设了阈值"8",怎么会到第十一才转为红黑二叉树呢?
其实在HashMap中存在扩容机制,
它一开始默认是长度为16的数组,
当某一个索引中的元素超过到8时,它优先会选择将长度扩容2倍(即长度为32)的数组,
它会认为是不是由于数组的长度不够才导致一个索引中元素过多;
但当它发现长度为32时,某一个索引中的元素还是超过9时,
它还是会优先选择将长度再次扩容到2倍(即长度为64)的数组,
在长度为64的数组中,它发现某一个索引中的元素还是超过10时,它就会对该索引所在的链表转化为红黑二叉树.
所以在第十一个元素时,就会对该索引所在的链表转化为红黑二叉树.

















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









