




HTTP与HTTPS的介绍

HTTP(Hypertext Transfer Protocol,超文本传输协议)和HTTPS(Hypertext Transfer Protocol Secure,超文本传输安全协议)都是用于在Web上传输数据的协议,但它们之间存在一些重要的差异,特别是在安全性和加密方面。
- HTTP:是不安全的,传输的数据都是未加密的明文。这意味着在传输过程中,任何在路径上的设备都可以读取或篡改数据。
- HTTPS:是安全的,通过传输加密和身份认证保证了传输过程的安全性。HTTPS在HTTP的基础上加入了SSL/TLS协议,SSL/TLS协议负责数据的加密和解密,以及服务器身份验证和消息完整性检查。
- HTTP:不需要证书和密钥。
- HTTPS:使用SSL/TLS协议进行通信时,服务器需要提供一个证书来证明其身份。这个证书是由一个受信任的证书颁发机构(CA)签发的。同时,服务器和客户端还会协商一个会话密钥,用于后续通信的加密和解密。
HTTP协议
认识URL
我们平时说的网址就是URL:
https://mp.youkuaiyun.com/mp_blog/creation/editor/139219562?spm=1001.2014.3001.4503但是现在几乎都是更加安全的HTTPS协议。
- https://就是协议方案名。//用于协议与域名的分隔符
- mp.youkuaiyun.com就是服务器地址,也就是域名,一般通过应用层协议DNS进行域名解析成我们的IP地址。
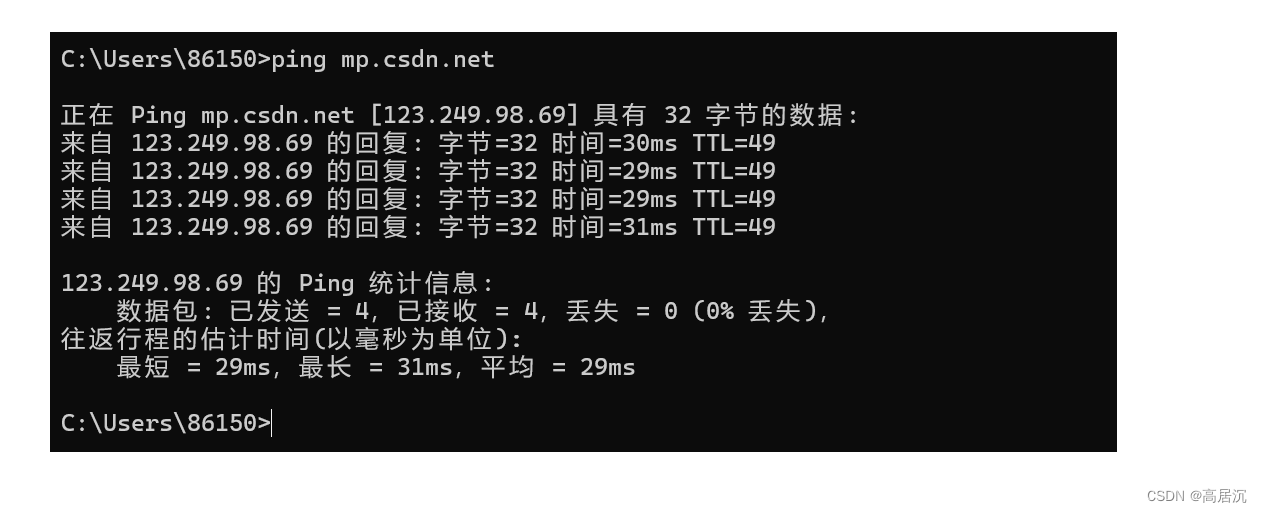
- 还有省略的端口号。HTTP:通常默认使用80端口,HTTPS:通常默认使用443端口。
- /mp_blog/creation/editor/139219562表示的就是后端Linux服务器上的路径,但是最前面的/并不一定表示的是根目录,而是web根目录。/同时也作为域名和路径的分隔符。
- ?spm=1001.2014.3001.4503这里采用?进行隔开,后面spm表示的是参数名,后面一串是参数的内容。如果有多组参数就用&符号作为参数间隔。
URL的编码与解码
因为我们的URL中是含有特殊的分割字符的,如:/?等这样的字符,所以URL中不能随意的出现类似于这种特殊字符,如果某个参数中需要带有这样的字符,就必须先对这些字符进行转义。
转移规则:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格
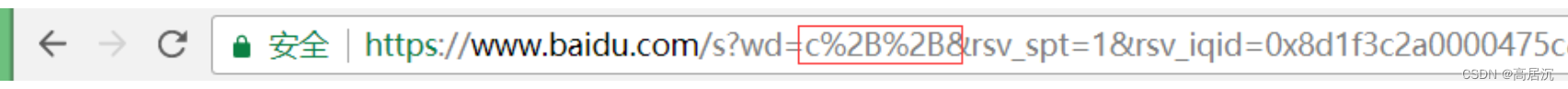
HTTP协议的内容
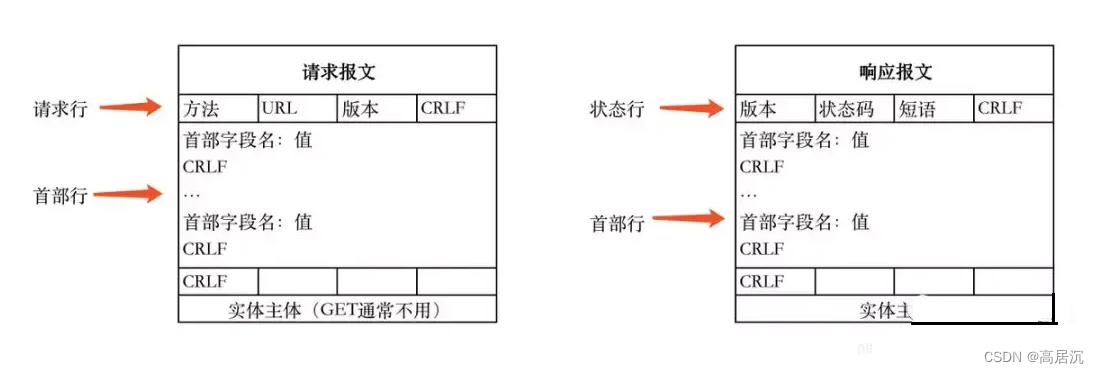
HTTP请求协议内容
POST /index.html HTTP/1.1
Host: www.example.com
Content-Length: 15
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: http://www.example.com/index.html
Accept-Encoding: gzip, deflate, sdch, br
Accept-Language: en-US,en;q=0.8
Cookie: name=value; name2=value2
username=alice&password=secret第一行是请求行内容。
请求行包含三个主要部分:HTTP方法、请求资源的URL和HTTP协议版本。
第二行开始到空行是请求头。
请求头包含一系列的字段,每个字段都包含一个名字和一个值,它们之间用冒号(
:)分隔。空行后面的内容就是请求体。
请求体不是每个HTTP请求都必需的,它通常用于POST和PUT等请求中,以发送数据给服务器。请求体的格式取决于
Content-Type头字段的值。而当前请求体是一个表单数据,它包含了用户名(username)和密码(password)两个字段。每一行的数据结尾用\r\n作为换行
请求资源的URL
当我们通过访问http协议资源时,是通过IP和端口port与请求URL来访问服务器指定路径下的资源的,服务器运行起来其实就是一个进程,而该进程并不一定是在根目录下执行的,而我们服务器一般会创建一个主文件夹,其中存放有我们客户端所需要访问的资源数据,而该主文件夹就是web根目录,所以当服务端接收到客户端访问的URL时就可以进行路径解析,然后到指定web下的路径中读取资源内容并返回。
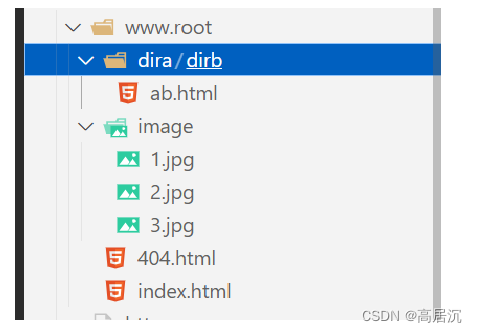
请求内容解析代码部分
请求和响应代码是源自同一个头文件Http_protocol.hpp中:
#pragma once
#include "socket.h"
#include <sstream>
#include <fstream>
const string http_sep = "\r\n";
const string wwwroot = "./www.root"; // 这就是url下的根目录/
const string homepage = "index.html"; // 访问根目录下的默认文件
class HttpRequest
{
bool Get_line(string &request, string &ret) // 实现读取每一行数据的功能
{
int pos = request.find(http_sep);
if (pos == string::npos)
return false;
ret = request.substr(0, pos);
request.erase(0, pos + http_sep.size());
return true;
}
public:
HttpRequest()
: _req_blank(http_sep), _targetpath(wwwroot)
{
}
void Parse_reqline() // 分析请求行,并根据url确定路径_targetpath
{
//_method _url _http_version
stringstream ss(_req_line);
ss >> _method >> _url >> _http_version; // 以空格作为分隔符一次放到三个string流中
// 路径解析
if (_url == "/")
{
_targetpath += "/" + homepage;
}
else // 粗略处理
{
_targetpath += _url;
}
}
void Parse_suffix() // 解析url下的指定文件类型即后缀
{
//_targetpath: www.root/image/1.jpg
int pos = _targetpath.rfind('.');
if (pos == string::npos)
_suffix = "未知类型";
else
_suffix = _targetpath.substr(pos);
}
void parse() // 报文分析
{
// 1.分析请求行,同时提取url路径
Parse_reqline();
// 2.解析url下的指定文件类型即后缀
Parse_suffix();
}
string Get_filecontent_func(string path) // 读取指定路径下的数据
{
ifstream in(path, ios::binary); // 按照二进制方式来读取
if (!in.is_open())
return "";
string ret;
// a.读取一般非二进制数据的方法
// string line;
// while (getline(in, line))
// {
// ret += line;
// }
// getline不能拿来读取二进制文件
// 1.换行符问题 2.编码问题 3.性能问题
// b.读取二进制数据
in.seekg(0, in.end); // 文件流偏移到结尾数
int file_size = in.tellg(); // 读取文件大小
in.seekg(0, in.beg); // 回到文件开头指向
ret.resize(file_size);
in.read((char *)ret.c_str(), file_size);
in.close();
return ret;
}
string Get_filecontent()
{
return Get_filecontent_func(_targetpath);
}
string Get_404()
{
return Get_filecontent_func("www.root/404.html");
}
void Deserialize(string &request) // 反序列化
{
Get_line(request, _req_line);
string line;
while (1)
{
bool ok = Get_line(request, line);
if (ok && line.empty()) // 读到空行,即报头解析完毕
{
_req_content = request; // 空行后面就是实际内容
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











