



作者 | 深蓝学院 来源 | 深蓝AI
原文链接:南洋理工、哈佛提出OpenREAD:用端到端RL统一驾驶认知与轨迹规划
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
「让视觉语言大模型
同时学会“思考”与“执行”」
在自动驾驶研究中,利用大语言视觉语言模型(LLMNLM)学习开放式驾驶知识,进而提升轨迹规划与决策能力,正逐渐成为新的趋势。
然而,传统的监督微调(SFT)范式难以充分挖掘模型的推理潜力,对知识的学习效率也存在不足。DeepSeek-R1的出现向我们展示了强化学习在提升模型推理与思考能力方面的巨大潜力,使模型具备更强的泛化表现。
因此,一个关键问题随之而来:如何通过强化学习增强视觉语言模型的推理能力,让模型“学会思考”,并在同一框架下同时掌握开放式驾驶知识与轨迹规划?这正是基于视觉语言大模型实现端到端自动驾驶所面临的全新挑战。
南洋理工大学与哈佛大学联合推出OpenREAD--一个通过强化学习(RL)全面提升视觉语言大模型(VLM)推理能力的全新框架。
1
—
方法
该方法引入 Qwen3-LLM作为“评判专家”,将强化学习从传统只适用于可验证的下游任务(如决策、规划),成功拓展到“驾驶建议”“场景分析"等开放式任务,实现从高层语义推理到低层轨迹规划的端到端强化微调。在LingoQA知识评测和NuScenes开环评测中,OpenREAD均取得了SOTA表现。
1.大语言模型作为开放式知识学习的打分器
在自动驾驶领域,现有强化学习多应用于轨迹预测或决策规划等“可验证”的下游任务,因为这些任务可以直接根据真值计算误差。但基于语言的驾驶知识学习属于开放式问题:同一个参考答案可能有多种不同表达方式,这给RL的奖励函数设计带来了很大挑战。
为解决这一问题,我们做了以下两步准备:
(1) 构建带显式思维链(CoT)的知识数据。
我们在LingoQA数据集上使用GPT-4标注了一批包含详细推理过程的驾驶知识数据,覆盖“感知类”与“决策类”两大任务,让模型能够学习到可解释的推理链条。
(2) 将OmniDrive数据集转换为RL可用格式。
我们将其统一转换为“思考+回答”的形式,使其能用于强化学习训练,包含两类任务:轨迹规划与伪轨迹分析。
两个数据集上的示例标注如图所示:

在数据准备完成后,我们先利用CoT标注进行冷启动(cold start),让模型快速获得基础的思考与推理能力。随后进入基于GRPO的强化微调阶段,进一步提升推理能力。在这个阶段,我们引入Qwen3LLM被用作评判专家,将问题、参考答案和模型生成的回答一起作为Owen3-LLM的输入,让其判断模型的预测与参考答案是否一致,如果一致则设置奖励值1,反之为0。
为了让模型的回答不仅正确,还要简洁、不啰嗦,我们进一步计算生成答案与参考答案的embedding余弦相似度,将其作为额外奖励,与Owen3的评判结果共同作用,使模型在语言表达上更加贴近高质量输出。通过这种“专家判断+语义相似度”双重奖励机制,模型得以在开放式驾驶知识学习中获得更稳定且更可靠的推理能力。
2.驾驶知识与轨迹规划的协同强化学习
在解决了开放式知识学习的奖励函数难题后,我们进一步将强化学习同时应用于驾驶知识推理与轨迹规划,实现两类任务的协同训练,模型在学习“如何思考驾驶知识”的同时,也学习“如何利用这些知识进行更合理、更安全的轨迹规划”。
对于轨迹规划任务,我们设计了基于轨迹误差的奖励数。县体来说,我们将轨迹误差作为指数函数的变量,对较远时间点的轨迹误差给予更宽松的容忍度,因为此类误差对即时安全性影响较小;对近距离时间点的轨迹误差设置更严格的要求,以确保模型在关键位置的规划更加精准可靠。
在联合强化学习过程中,一个训练批次内可能包含不同类型的任务(如驾驶决策问答、轨迹规划等),我们为每类任务分别计算其对应的奖励函数,最后综合得到当前批次的整体奖励,用于更新模型参数,使模型能够在知识推理与路径规划之间建立自然的联系,从而提升其整体的驾驶智能。
OpenREAD的整体训练框架如下图所示:

2
—
实验结果
为了验证强化学习对知识学习和轨迹规划协同微调带来的提升,我们分别在LingoQA和NuScenes数据集上对OpenREAD进行评测。
RFT VS. SFT
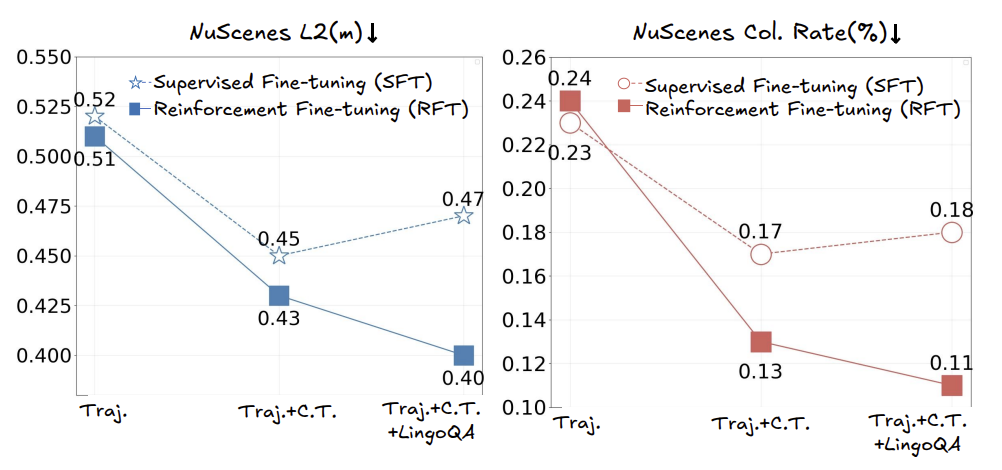
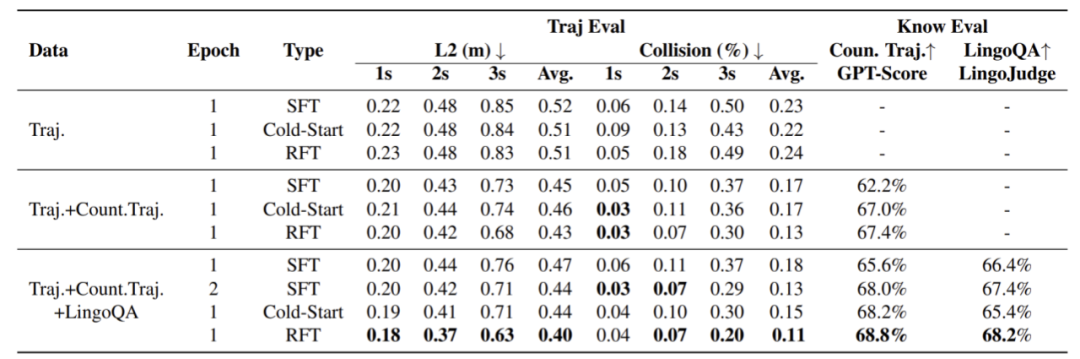
从上图可以看到,在仅使用轨迹规划任务的情况下,即使引入强化学习进行微调,轨迹误差和碰撞率的提升都非常有限。随着相关驾驶知识数据的引入,强化学习微调的效果逐渐显现,最终在轨迹误差、碰撞率和相关驾驶知识的评测中,都超过了SFT,证明了引入强化学习同步学习驾驶知识和轨迹规划的必要性。
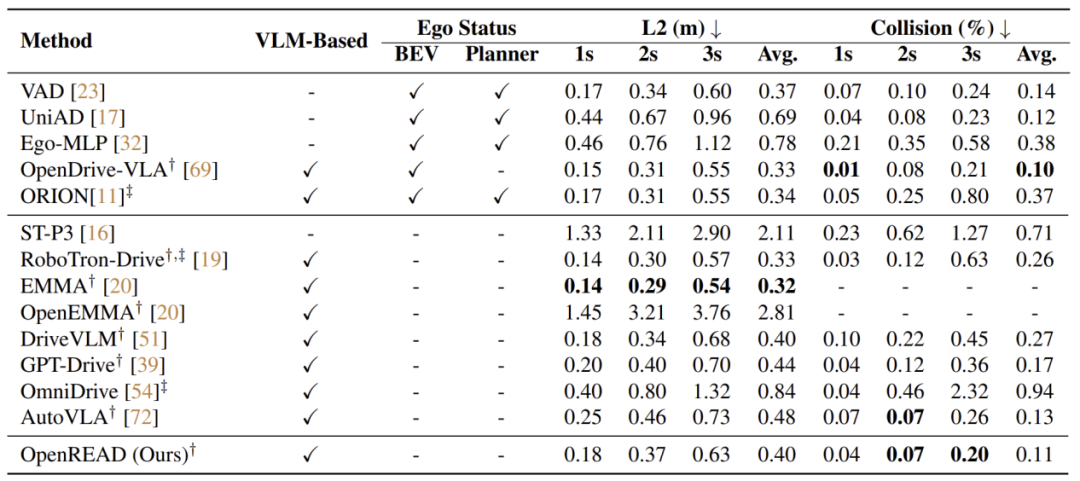
路径规划评测对比
在与其他现有方法的轨迹规划对比中,OpenREAD取得了更为出色的碰撞控制能力,保证了驾驶的安全性。与同样使用GRPO进行强化学习微调的AutoVLA相比,OpenREAD均取得了更为出色的轨迹误差和碰撞率控制,这一差异也进一步说明引入驾驶知识对下游任务的重要意义。
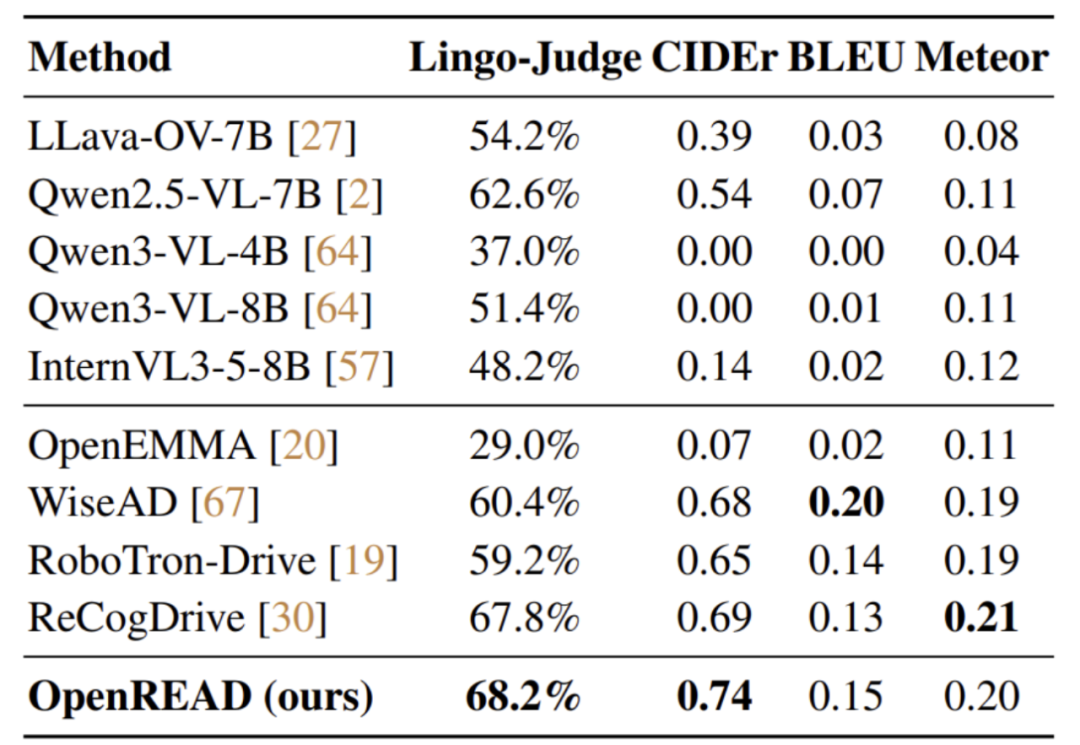
驾驶知识评测对比
在LingoQA数据集的驾驶知识评测中,OpenREAD超过了先前的WiseAD、RecogDrive等一系列工作,取得了最高的Lingo-Judge准确率:
3
—
更多可视化结果
RFT与SFT的轨迹规划结果对比。

OpenREAD与Owen3-VL和WiseAD在LingoQA上的对比。

4
—
总结
OpenREAD通过引入Qwen3-LLM作为“评判专家”,实现了对驾驶知识与轨迹规划的协同强化学习微调,进一步拓展了强化学习在端到端自动驾驶中的应用边界。该框架不仅提升了模型的整体推理与规划能力,也为深入挖掘驾驶知识对下游任务性能的促进作用提供了重要参考。
论文链接:https://arxiv.org/abs/2512.01830
代码链接:https://github.com/wyddmw/OpenREAD
数据连接:https://huggingface.co/datasets/wyddmw/OpenREAD
自动驾驶之心
面向量产的端到端小班课!

添加助理咨询课程!


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









