



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Jialv Zou等
编辑 | 自动驾驶之心
时隔一年,DiffusionDrive终于升级到v2了。华科王兴刚教授团队近年来产出了很多大家耳熟能详的工作,比如MapTR、VAD系列、ReCogDrive、首个闭环3DGS训练框架-RAD、DiffusionDrive等等工作,而廖本成博士也是这些工作的核心开发者。

在端到端自动驾驶的轨迹规划任务中,扩散模型常面临mode collapse的问题,倾向于生成保守且单一的行为。尽管DiffusionDrive通过预定义的锚点(代表不同驾驶意图)对动作空间进行划分,从而生成多样化轨迹,但该方法依赖模仿学习,缺乏足够约束,导致在多样性与持续高质量之间陷入两难困境。本文提出DiffusionDriveV2,利用强化学习既约束低质量模式,又探索更优轨迹。
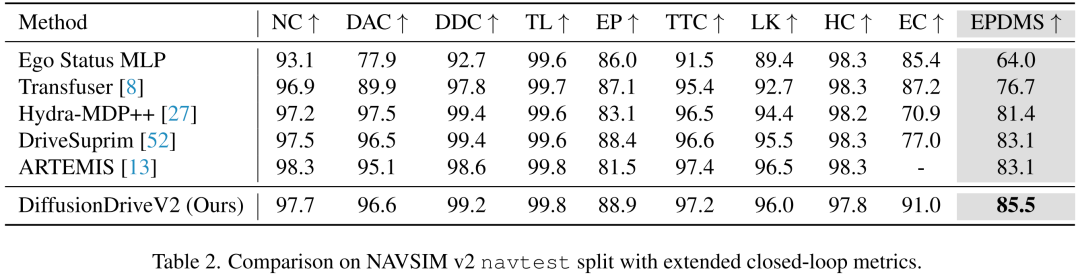
该方法在保留核心高斯混合模型固有多模态特性的同时,显著提升了整体输出质量。首先,引入适用于轨迹规划的尺度自适应乘法噪声,以促进更广泛的探索;其次,采用锚点内GRPO管理单个锚点生成样本间的优势估计,并通过锚点间截断GRPO整合不同锚点的全局视角,避免不同意图(如转弯与直行)间不当的优势比较(此类比较可能进一步导致mode collapse)。在NAVSIM v1数据集的闭环评估中,DiffusionDriveV2结合对齐的ResNet34网络实现了91.2的PDMS,在NAVSIM v2数据集上实现了85.5的EPDMS,创下新纪录。进一步实验验证,该方法解决了截断扩散模型在多样性与持续高质量之间的矛盾,实现了最优权衡。
论文链接:https://arxiv.org/abs/2512.07745
论文标题:DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
开源链接:https://github.com/hustvl/DiffusionDriveV2
一、背景回顾
近年来,随着3D目标检测、多目标跟踪、预训练、在线建图和运动预测等传统任务的日益成熟,自动驾驶系统的发展浪潮已转向端到端自动驾驶(E2E-AD)——该方法直接从原始传感器输入中学习驾驶策略。
该领域的早期方法在建模方面存在局限性:传统端到端单模态规划器仅回归单一轨迹,无法在高不确定性的复杂驾驶场景中提供备选方案;基于选择的方法采用大型静态候选轨迹词汇库,但这种离散化方式灵活性有限。
近年来,已有多项研究将扩散模型应用于轨迹生成,该模型可根据周围场景动态生成少量候选轨迹。然而,将原始扩散模型直接应用于多模态轨迹生成时,会面临模式崩溃的挑战——模型会收敛到单一高概率模式,无法捕捉未来的多样性可能,如图1(a)所示。为解决这一问题,DiffusionDrive提出利用多个预定义轨迹锚点定义的高斯混合模型(GMM)构建初始噪声的先验分布。这种结构化先验将整个生成空间划分为多个子空间,每个子空间对应特定驾驶意图(例如,一个模式用于变道,另一个用于直行),从而有效促进多样化行为模式的生成。
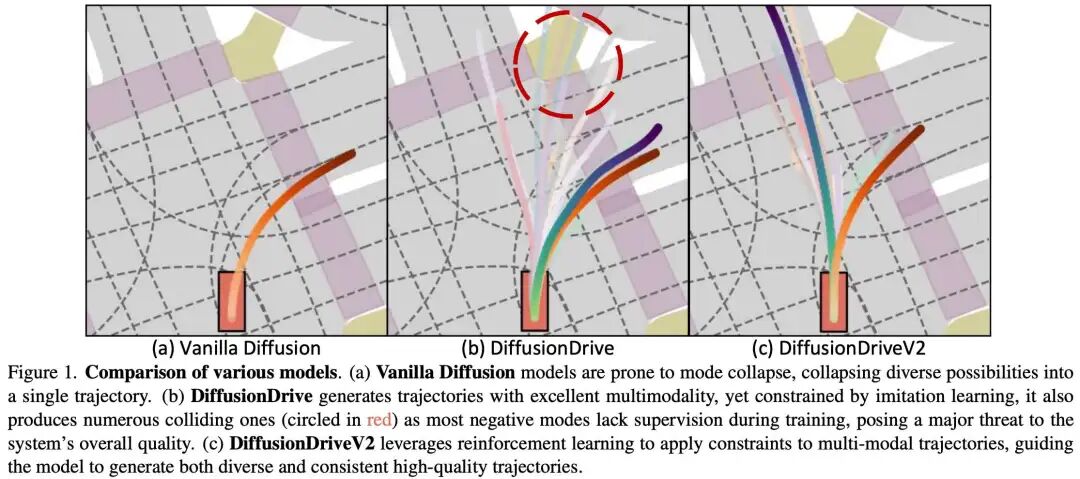
然而,DiffusionDrive受限于模仿学习(IL)范式,在生成轨迹的多样性与持续高质量之间陷入根本性两难。尽管高斯混合模型先验确保了模式生成的多样性,但其训练目标旨在最大化整个混合模型中专家轨迹的似然性,而在实际应用中被简化为仅优化单一正模式(即与专家轨迹最接近的模式)的参数。因此,该方法忽略了对来自负模式(占样本绝大多数)的采样轨迹施加任何显式约束,导致模型在生成高质量轨迹的同时,也会产生大量无约束、低质量且常发生碰撞的轨迹,无法保证持续的高质量,如图1(b)所示。
这种危险的混合轨迹迫使系统依赖下游选择器,但由于选择器的参数通常远少于生成器,其鲁棒性更弱。这种过度依赖存在显著风险:当筛选大量低质量轨迹时,尤其是在分布外场景中,选择器容易失效。
强化学习(RL)为这一困境提供了强有力的解决方案。与局限于单一正模式的模仿学习不同,强化学习采用“探索-约束”范式:一方面,通过对所有模式施加目标对齐约束来提高模型的下限——奖励期望行为,同时惩罚负模式的不安全动作;另一方面,通过推动模型探索更广泛的动作空间来提高模型的上限,寻求在质量和效率上可能超越专家的策略。
受DeepSeek-R1成功的启发,已有多项研究将GRPO引入端到端自动驾驶领域,但这些应用仅限于原始扩散模型。与这些方法不同,在基于锚点的截断扩散模型中,每个预定义轨迹锚点代表不同的驾驶意图。若直接对不同驾驶意图对应的轨迹进行优势估计,会加剧模式崩溃。例如,左转轨迹和直行轨迹应共存,而非进行优劣比较。这一见解促使我们提出锚点内GRPO:通过仅在每个锚点内进行组优势估计,阻止不同意图间的比较,从而防止模式崩溃;同时引入锚点间截断GRPO,以提供全局视角并稳定训练。
借助这些创新,本文提出一种新型框架DiffusionDriveV2,利用强化学习解决DiffusionDrive因依赖模仿学习而面临的多样性与持续高质量之间的两难问题。我们在面向规划的NAVSIM v1和NAVSIM v2数据集上通过闭环评估对该方法进行基准测试。DiffusionDriveV2在两个基准测试中均达到当前最优水平:结合ResNet-34主干网络,在NAVSIM v1上实现91.2的PDMS,在NAVSIM v2上实现85.5的EPDMS,相比现有方法有显著提升。此外,与其他基于扩散的生成模型相比,DiffusionDriveV2在轨迹多样性与持续高质量之间实现了最优权衡。
本文的贡献可总结如下:
提出DiffusionDriveV2——一种引入强化学习的新型方法,用于解决DiffusionDrive因模仿学习中多模态监督不完整而导致的多样性与持续高质量两难问题。据我们所知,DiffusionDriveV2是首个直接面对并解决这一困境的工作。
引入锚点内GRPO和锚点间截断GRPO,解决了将原始GRPO直接适配到DiffusionDrive时,在高斯混合模型框架下无法跨不同模式进行组优势估计的问题。DiffusionDriveV2是首个成功将GRPO迁移到截断扩散模型的工作。
采用尺度自适应乘法噪声作为探索噪声,而非加法噪声,有助于保留探索轨迹的平滑性和连贯性。
在NAVSIM v1和NAVSIM v2基准测试中的大量评估表明,DiffusionDriveV2在保留底层高斯混合模型生成多模态轨迹能力的同时,显著提升了整体输出质量,实现了当前最优性能。
二、预备知识
端到端自动驾驶
端到端自动驾驶(E2E-AD)系统通过模仿学习习得专家驾驶策略,将原始传感器数据映射为未来自车轨迹预测结果。轨迹由一系列未来路径点表示,记为 ,其中 为第 时刻路径点的位置, 代表规划时域。
截断扩散模型
扩散策略模型通过学习反向马尔可夫噪声过程,对随机高斯噪声进行迭代优化,从而生成轨迹。然而实验表明,原始扩散模型易出现模式崩溃问题,无法生成多样化驾驶行为。这使其难以应对复杂驾驶场景,无法提供丰富的备选轨迹(例如跟车与超车、路口直行与左转等场景)。
为解决原始扩散模型的模式崩溃问题,DiffusionDrive提出将轨迹分布建模为高斯混合模型(Gaussian Mixture Model, GMM)分布。该方法通过K-Means算法对专家驾驶行为进行聚类,得到 个锚点轨迹 ,用这组离散轨迹表示不同的驾驶意图。每个锚点对应轨迹空间中的特定区域,进而代表一种具体驾驶意图(如超车、左转或直行)。锚点 对应的轨迹分布可表示为:
值得注意的是,与直接从随机噪声中预测轨迹的原始扩散模型不同,DiffusionDrive的训练目标是预测轨迹与其对应锚点 之间的偏移量。其中 表示基于场景上下文 的、相对于锚点状态 的场景特定偏移量。整个轨迹分布可表示为:
该分布即为高斯混合模型,其中 为混合权重,表示在给定场景上下文 时,选择锚点 所对应驾驶意图的概率。
DiffusionDrive采用截断扩散过程,通过缩短标准噪声调度表,将每个锚点轨迹扩散为对应的锚定高斯分布:
其中 ,且 ( 为标准扩散模型的噪声步数), 为截断扩散步数。训练阶段,DiffusionDrive以锚定高斯分布中采样的带噪轨迹 为输入,预测去噪后的轨迹 及概率得分 (其中 是公式(2)中 的简写)。
然而,DiffusionDrive仍受限于模仿学习(IL)的固有缺陷。尽管其基于锚点的设计缓解了模式崩溃问题并提供了多样化轨迹选择,但训练过程本质上受限于每个场景仅存在一条真实轨迹(GT trajectory)。因此,模型在训练时仍需选择一个锚点作为正模式进行优化:将与真实轨迹 最接近的锚点指定为正样本( ),其余锚点则为负样本( )。训练目标函数为:
受模仿学习的约束,每个场景中仅有一个模式能获得监督。这导致模型虽能生成多样化轨迹,但也会产生大量可能引发碰撞的低质量轨迹,对系统安全性构成重大威胁。
DiffusionDriveV2算法详解
截断扩散生成器
本文提出的DiffusionDriveV2整体架构如图2所示。为生成多模态轨迹,我们直接采用DiffusionDrive作为轨迹生成器,并利用其在真实轨迹上通过模仿学习预训练得到的权重实现冷启动,使模型初步具备多模态轨迹生成能力。基于感知网络提取的特征,截断扩散解码器以锚定高斯分布中采样的带噪轨迹 为输入,经过 步迭代优化后,生成最终的去噪轨迹。
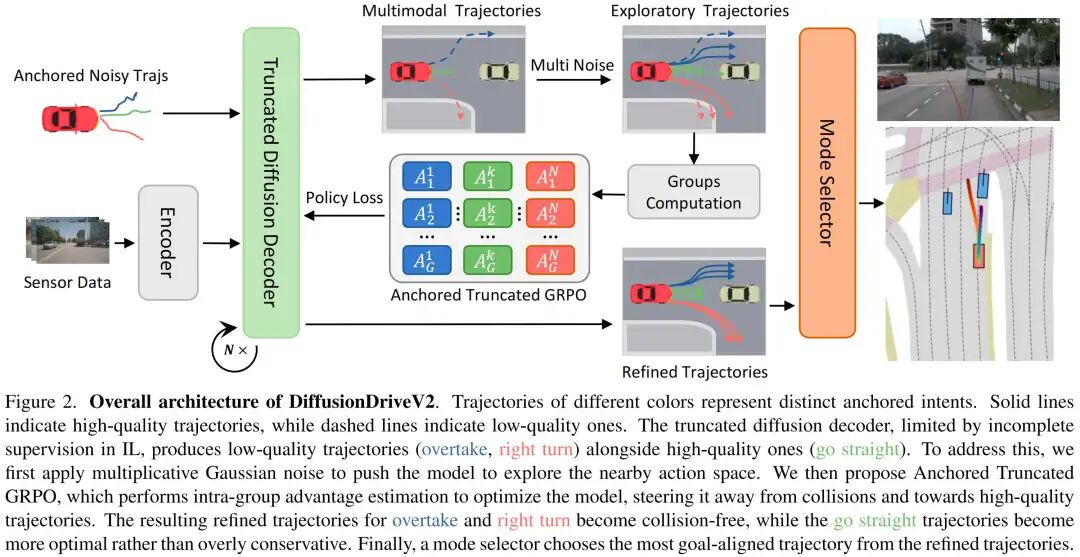
面向扩散生成器的强化学习
尽管DiffusionDrive在多模态轨迹生成方面表现出较强能力,但它继承了模仿学习的核心缺陷——对负模式缺乏监督。这往往导致低质量轨迹的生成,对系统构成严重威胁。为解决该问题,我们引入轨迹级强化学习目标,对所有模式施加约束,同时推动模型探索更优驾驶策略。受DPPO启发,我们将去噪过程视为马尔可夫决策过程(MDP)。从锚点 出发的扩散链中,每个条件去噪步骤均可视为一个高斯策略:
其中 为模型预测的均值, 由预定义的噪声调度表确定。
该式表示高斯似然,可通过解析方式求解,且适用于基于REINFORCE的策略梯度更新:
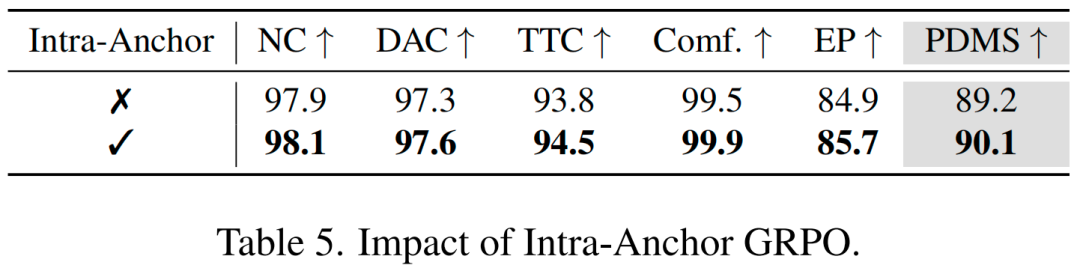
,其 中 表示优势函数。 ### 尺度自适应乘法探索噪声 DiffusionDrive采用DDIM更新规则,将去噪步数大幅减少。该更新规则通常通过设置 作为确定性采样器使用。为实现更广泛的探索并避免狄拉克分布下的似然计算问题,我们在训练阶段设置 以引入探索噪声(等价于采用DDPM),而在验证阶段保持 以实现确定性推理。 然而,由于轨迹的近端段与远端段存在固有尺度不一致性,直接在每个点施加加法高斯噪声会破坏轨迹的结构完整性,降低探索质量。如图3(a)所示,对标准化轨迹 施加加法高斯噪声 后,生成的探索路径通常呈锯齿状(类似折线),丧失了原始轨迹的平滑性。为保留轨迹连贯性,我们提出仅添加两个乘法高斯噪声(一个纵向噪声、一个横向噪声),其表达式为 ,其中 。这种尺度自适应乘法噪声确保生成的探索路径保持平滑,如图3(b)所示。 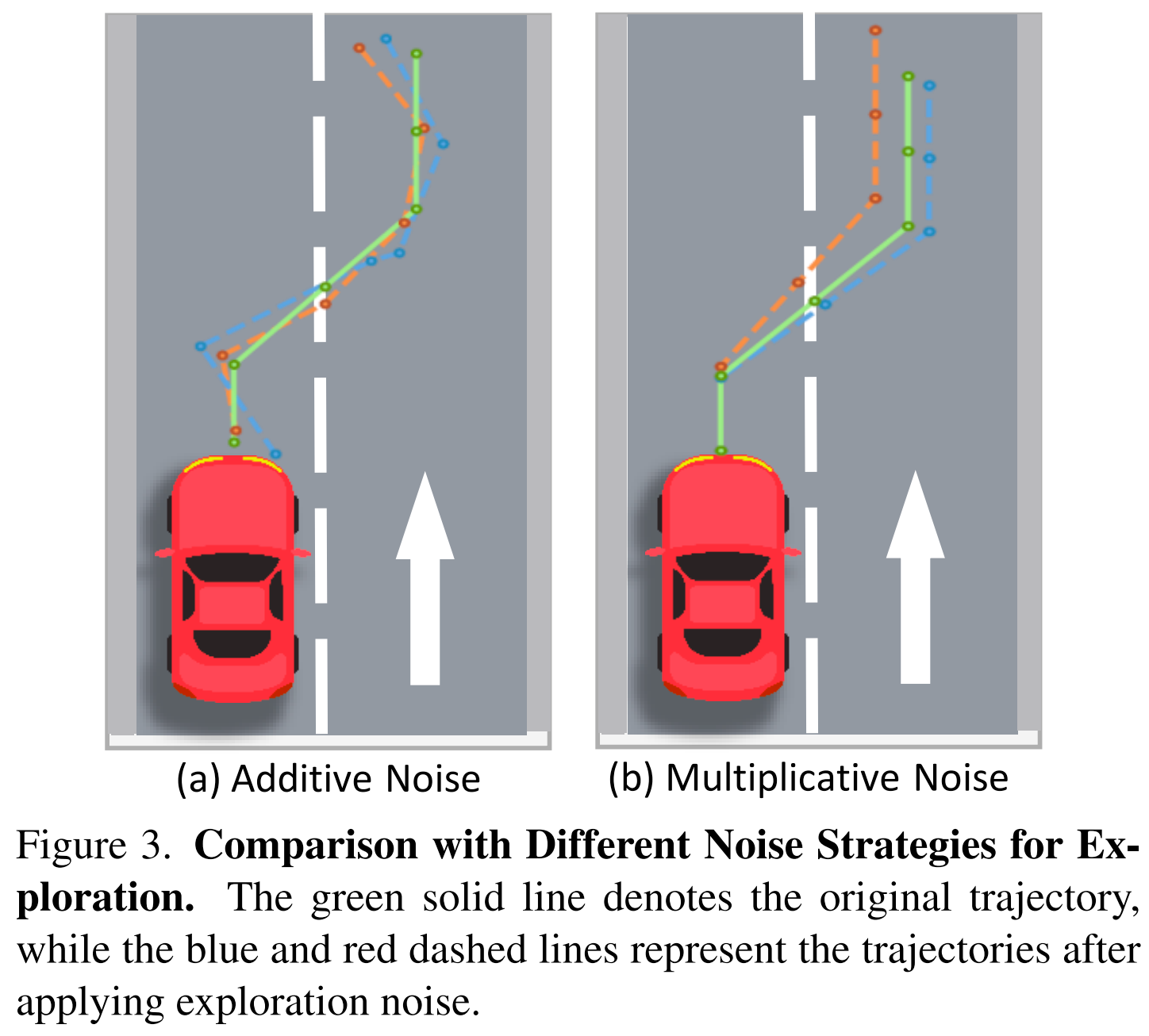 ### 面向轨迹生成的锚点内GRPO GRPO是一种适用于多智能体或多模式场景的强化学习方法,其通过共享的组级基线更新每个智能体的策略。与传统PPO不同,该方法通过基于组条件期望归一化的优势函数定义策略梯度。通过利用轨迹级奖励优化非可微目标,GRPO对标准模仿学习进行了增强,可引导扩散模型生成多样化、面向目标的轨迹,且性能有望超越人类驾驶员。 然而,若直接将不同锚点采样的轨迹作为GRPO策略更新的“组”,则会适得其反。这种做法与我们利用锚点将轨迹空间划分为不同驾驶意图对应区域的核心动机相冲突,甚至会导致模式崩溃。例如,若将代表“右转”和“直行”的锚点采样轨迹(如图2中红色和绿色轨迹)进行相对优化,策略可能会崩溃为更常见的“直行”单一模式。这些锚点代表本质不同的意图,不应在同一优化组内直接比较。 基于这一洞察,我们提出锚点内GRPO(Intra-Anchor GRPO)。对于每个锚点,首先通过随机高斯噪声和探索噪声对其进行扩散,生成 个轨迹变体组成的组;随后在该组内执行GRPO更新,而非跨不同锚点的组进行更新。该方法将策略优化约束在每个特定行为意图的状态空间内,引导模型生成更安全、更面向目标的轨迹,同时不损害其多模态能力。强化学习损失函数可表示为:其中 为折扣系数,用于缓解早期去噪步骤中的不稳定性; 为优势函数,GRPO通过计算组相对优势进行估计,无需价值模型:
为基于最终去噪轨迹 计算的单一奖励估计值,该奖励被应用于扩散链中的所有去噪步骤,且每个步骤的影响通过去噪折扣 进行缩放。
此外,与原始GRPO通过添加策略模型与参考模型之间的KL散度实现正则化类似,我们引入额外的模仿学习损失,以防止模型过拟合并保障其通用驾驶能力。组合损失函数为 ,其中 为权重系数。
面向轨迹生成的锚点间截断GRPO
锚点内GRPO虽能防止模式崩溃,但完全隔离不同模式会引发新问题:优势估计丧失全局可比性。例如,某一模式中次优但安全的轨迹可能获得负优势,而另一模式中危险且存在碰撞的轨迹若为其组内“最优”样本,则可能获得正优势。这种依赖局部组内比较的方式会向模型传递误导性学习信号。
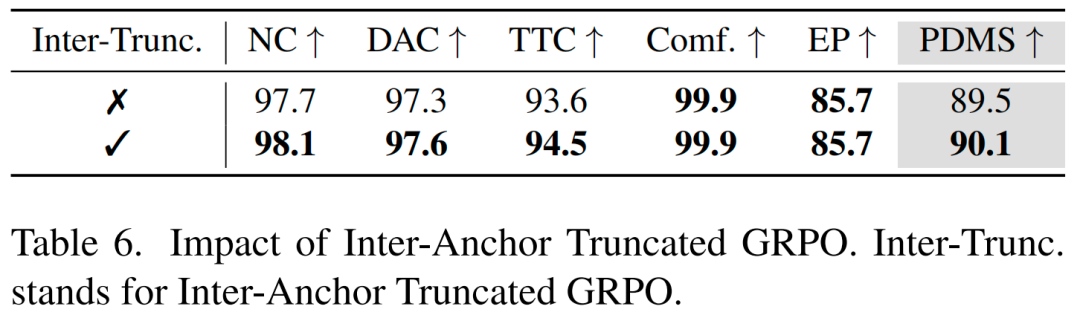
为解决该问题,我们提出锚点间截断GRPO(Inter-Anchor Truncated GRPO),其核心原则简洁而有效:奖励相对改进,但仅惩罚绝对失败。具体实现方式为修改锚点内GRPO的优势估计 :将所有负优势截断为0,并对存在碰撞的轨迹分配-1的强惩罚:
这一设计为模型提供了清晰且一致的学习信号。随后,该截断优势 将替代公式(7)中的 用于强化学习损失计算。
模式选择器
我们在模型末尾添加了一个模式选择器,负责从代表不同意图的多模态预测结果中选择最优、与目标最对齐的轨迹。得分越高表示与整体目标的对齐程度越强。具体而言,轨迹坐标首先作为查询向量,通过可变形空间交叉注意力与BEV特征交互,随后通过与智能体查询和地图查询的交叉注意力层进行优化;最后,富含上下文的特征表示被输入多层感知机(MLP)以预测得分。受DriveSuprim启发,我们采用两阶段“粗到细”评分器:首先由粗评分器筛选出排名前 的候选轨迹,再由细粒度评分器进行更细致的选择。得分学习采用二元交叉熵(BCE)损失。
针对连续指标,我们引入额外的Margin-Rank损失: ,其中 为真实得分, 为预测得分, 为正超参数。该损失引导模型比较轨迹的相对质量,避免直接回归绝对连续值的难题,进而增强模型对细微差异的区分能力。
四、实验结果分析
基准测试数据集
我们在NAVSIM v1和NAVSIM v2数据集上对DiffusionDriveV2进行评估。NAVSIM基于OpenScene构建,包含一系列真实世界、以规划为核心的驾驶场景,是大规模nuPlan数据集的精简版本。该数据集的传感器套件包括8台摄像头(提供360°视野)和5台激光雷达(生成融合点云),并分为训练集(navtrain,1192个场景)和测试集(navtest,136个场景)。
实现细节
为保证公平对比,我们的模型采用与Transfuser和DiffusionDrive相同的ResNet-34主干网络,并匹配DiffusionDrive的扩散解码器尺寸。DiffusionDriveV2的输入包括3张裁剪并下采样的前向摄像头图像(拼接为1024×256尺寸),以及激光雷达点云的栅格化鸟瞰图(BEV)表示。我们以DiffusionDrive在模仿学习中预训练的权重作为冷启动,随后在navtrain训练集上通过强化学习训练10个epoch。优化器采用AdamW,学习率为 ,总批次大小为512,分布式训练于8台NVIDIA L20 GPU。模式选择器采用相同配置训练20个epoch。推理阶段与DiffusionDrive一致,仅需2步去噪即可生成预测结果。
主要结果
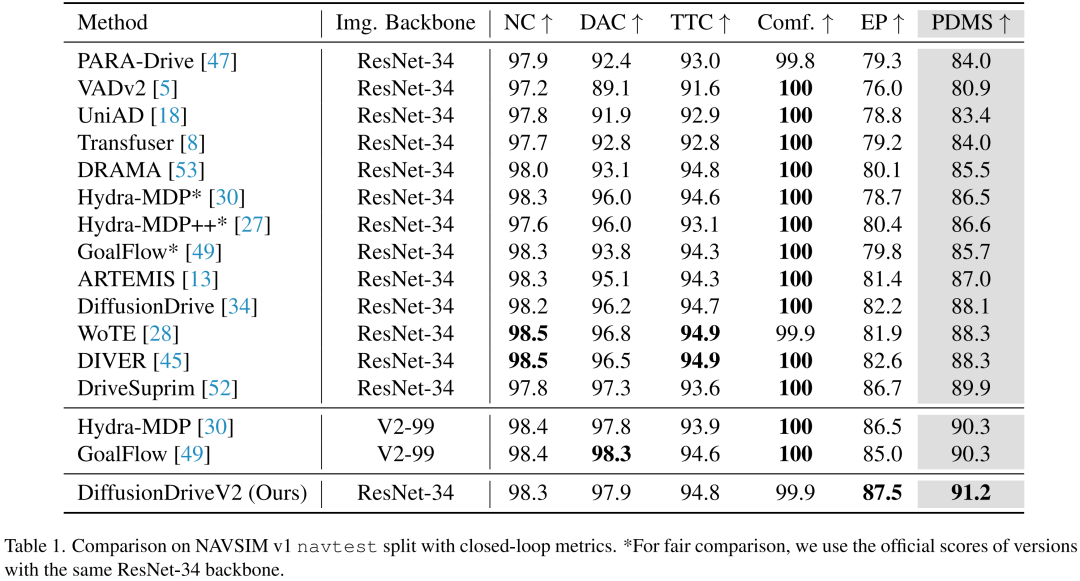
NAVSIM v1数据集结果:如表1所示,DiffusionDriveV2在NAVSIM v1测试集上实现当前最优性能,PDMS(规划决策度量分数)达到91.2。该模型相较于DiffusionDrive提升了3.1个PDMS,且EP(自车进度)分数显著提升5.3,证明其能提供更高质量、更高效的驾驶策略——这一改进归功于精心设计的强化学习方法。与同样基于强化学习的DIVER相比,DiffusionDriveV2的PDMS高出2.9,验证了锚点内GRPO和锚点间截断GRPO训练框架的卓越有效性。此外,仅配备ResNet-34主干网络(2180万参数)的DiffusionDriveV2,性能仍优于基于更大V2-99 主干网络(9690万参数)的GoalFlow和Hydra-MDP。
多样性与质量:受DIVER启发,我们引入多样性指标(Div.)定量评估模型生成多模态轨迹的能力。该指标定义路径点处的未归一化 pairwise 多样性为:
为保证不同场景下轨迹的尺度一致性,通过平均轨迹尺度对其进行归一化:
最终多样性得分为所有路径点 的平均值。为评估生成轨迹的整体质量,我们进一步报告Top-K PDMS(前K个排名轨迹的PDMS分数)。由于基于回归和基于选择的端到端自动驾驶方法仅能生成确定性轨迹,我们仅在测试集中将本文方法与其他基于扩散的方法进行对比。参考DiffusionDrive的设置,每个模型生成20条轨迹用于评估,结果如表3所示。
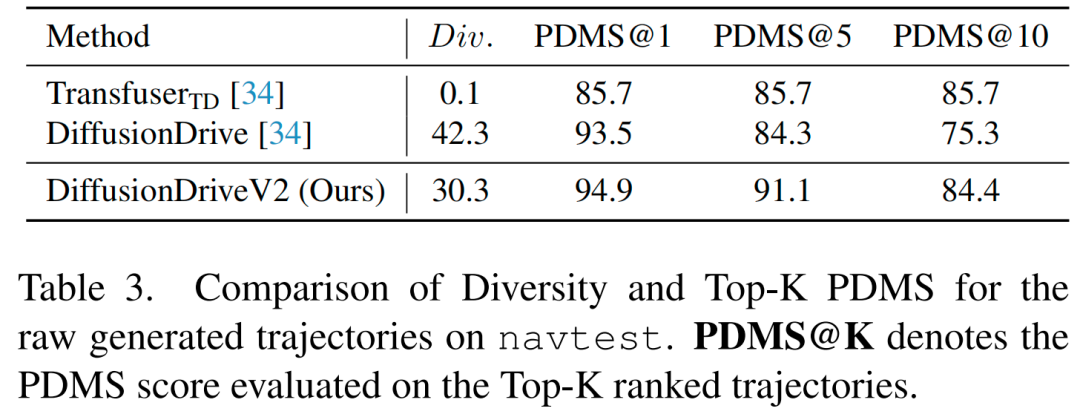
结果验证了我们的理论:原始扩散方法生成质量稳定但缺乏多样性,陷入单一“保守”轨迹;DiffusionDrive生成多样性极高,但无法保证持续高质量;而DiffusionDriveV2通过精心设计的强化学习算法实现“探索-约束”效果——对所有模式施加约束以提高模型下限(Top-10 PDMS),同时推动模型探索更优策略以提高模型上限(Top-1 PDMS)。该方法解决了截断扩散模型在多样性与持续高质量之间的矛盾,实现了最优权衡。
消融实验
我们通过一系列消融实验验证DiffusionDriveV2各设计模块的有效性。为保证公平对比,所有实验采用相同超参数配置,并通过减少训练轮数实现快速验证。
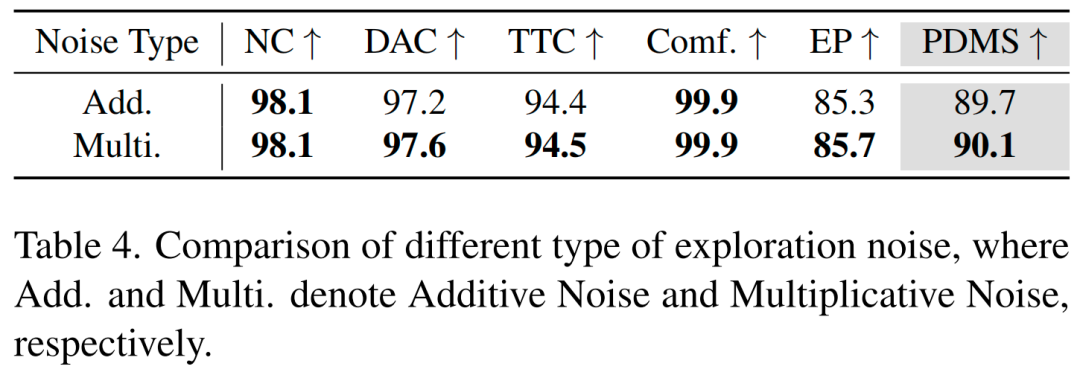
探索噪声类型:表4展示了不同探索噪声的对比结果。实验证实,尺度自适应乘法噪声优于加法噪声,能有效解决轨迹近端与远端的尺度不一致问题。
更多可视化结果

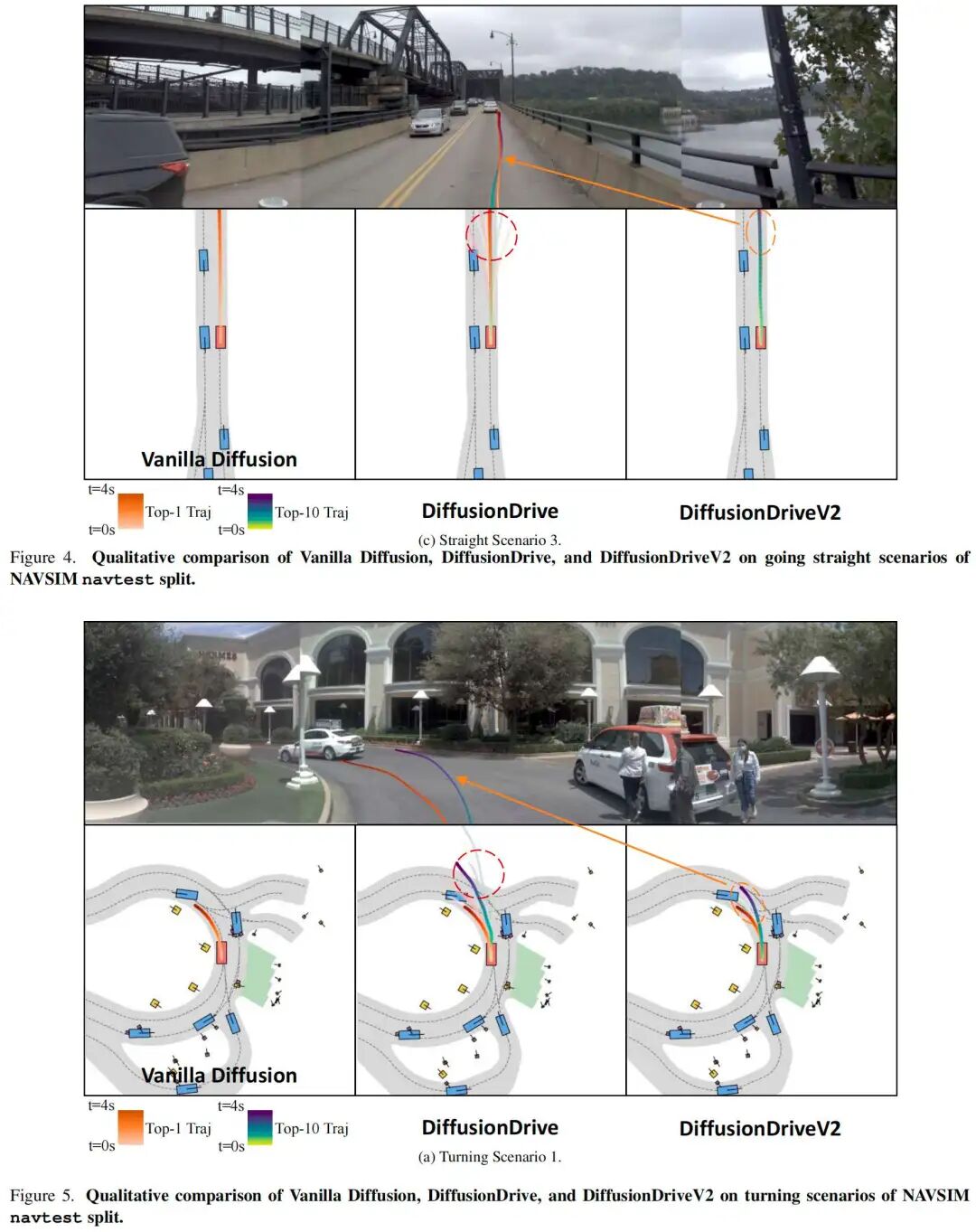
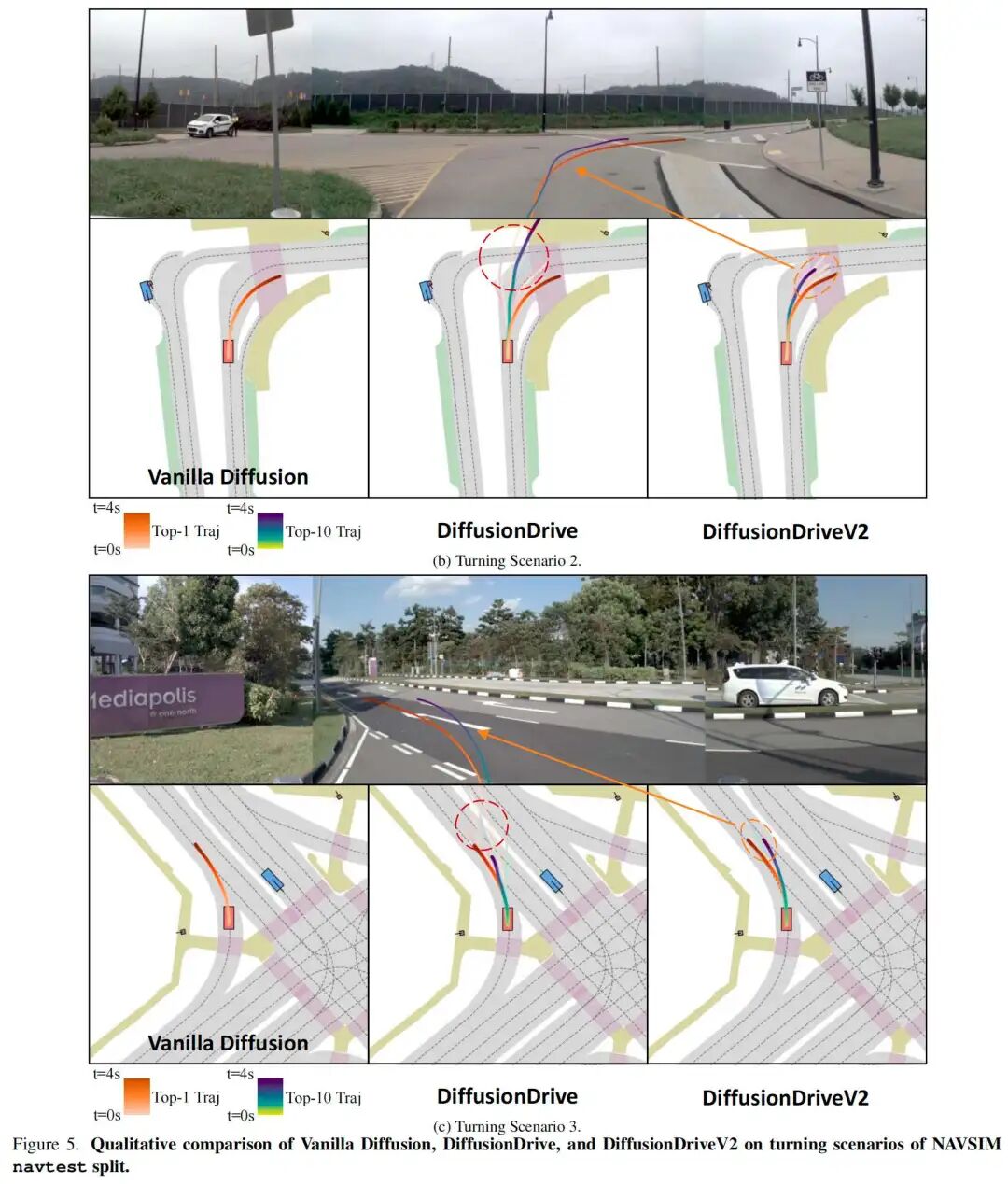
五、结论
本文提出DiffusionDriveV2框架,通过结合锚点内GRPO、锚点间截断GRPO与尺度自适应乘法探索噪声,解决了DiffusionDrive因模仿学习多模态监督不完整而面临的多样性与持续高质量两难问题。大量实验和定性对比验证,DiffusionDriveV2在保证规划质量持续优异与模式多样性之间实现了最优权衡,并取得了当前最优的闭环性能。
自动驾驶之心
面向量产的端到端实战小班课!

添加助理咨询课程!

知识星球交流社区

















 5472
5472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









