



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
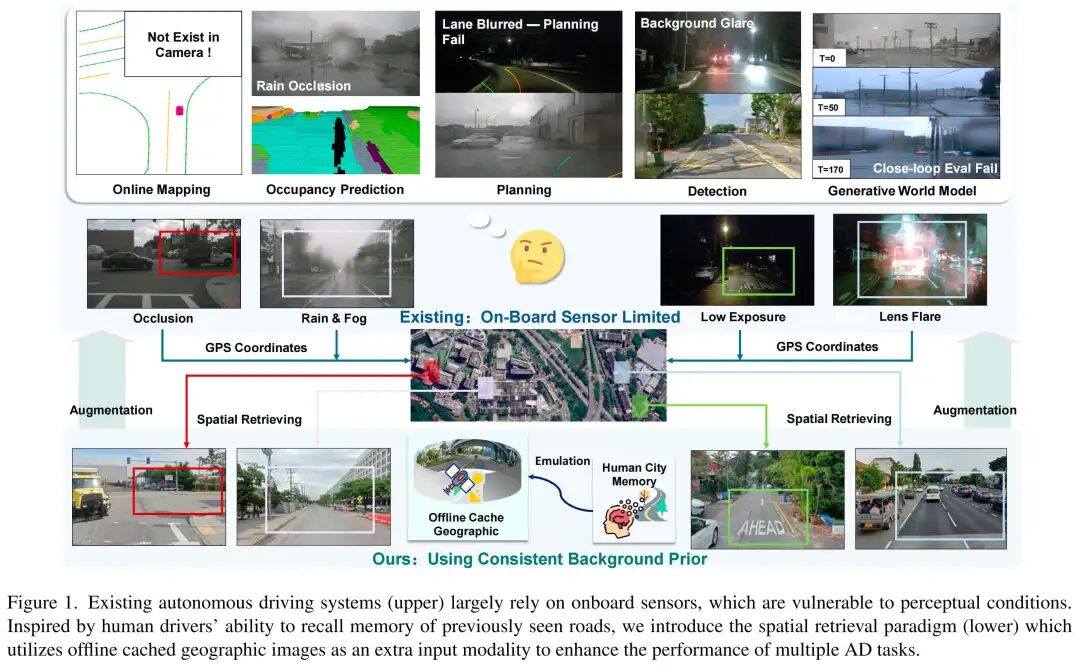
现有自动驾驶系统非常依赖车载传感器进行实时精确的环境感知。然而,这种模式受行驶过程中的感知范围限制,在视野受限、遮挡或黑暗、降雨等极端条件下常出现性能失效。相比之下,人类驾驶员即使在能见度不佳的情况下,仍能回忆起道路结构。为了让模型具备这种“回忆”能力,针对这个特点,复旦可信具身智能和上交等合作,将离线检索的地理图像作为额外输入引入系统。这些图像可从离线缓存(如谷歌地图或已存储的自动驾驶数据集)中轻松获取,无需额外传感器,是现有自动驾驶任务的即插即用型扩展方案。
在实验中,首先通过谷歌地图API检索地理图像,扩展了nuScenes数据集,并将新数据与自车轨迹对齐。并在五个核心自动驾驶任务上建立了基准:目标检测、在线建图、占用预测、端到端规划和生成式世界模型。其中在线建图mAP提升13.4%,占用预测静态类mIoU +2.57%,夜间规划碰撞率从0.55%降至0.48%,为复杂场景自动驾驶提供低成本、高鲁棒的感知增强方案。大量实验表明,该扩展模态能够提升部分任务的性能。我们将开源数据集构建代码、数据及基准测试,为这一新自动驾驶范式的后续研究提供支持。
论文标题:Spatial Retrieval Augmented Autonomous Driving
论文链接:https://arxiv.org/abs/2512.06865
项目主页:https://spatialretrievalad.github.io/
自动驾驶之心非常荣幸邀请到复旦大学可信具身智能研究院的贾萧松教授,为大家分享这篇最新的工作。周三晚上七点半锁定自动驾驶之心直播间~

一、背景回顾
最新的自动驾驶方法依赖车载传感器捕获环境信息。尽管这种模式已取得良好性能,但其输入本质上受限于在线传感的有限范围和视线传播特性。因此,在视野受限、遮挡、曝光异常或雨雪雾等恶劣天气等视觉挑战场景下,系统性能会显著下降,如图1所示。例如,在线建图和占用预测等任务旨在估计场景结构,而有限能见度或遮挡会降低其环境识别能力,进而影响规划决策。同样,近年来的自动驾驶世界模型在自车偏离记录日志较大时,难以生成新颖场景,这一局限源于车载视野的狭小范围,限制了其作为闭环评估和强化学习模拟器的应用能力。
相比之下,当当前视觉输入不足时,人类驾驶员会回忆近期的场景记忆。在本研究中,我们旨在通过空间检索为自动驾驶系统增添车载传感器即时范围之外的更广泛上下文信息。空间地理数据可来自谷歌地图,该平台提供包含经纬度信息的街景和卫星图像。对于自动驾驶企业而言,也可使用其离线缓存的数据集。与车载传感器不同,这些地理数据是离线的、全球可访问的,且不受行驶过程中干扰因素的影响。它们从自车之外的视角提供丰富的上下文线索,无需额外传感器或人工标注,是一种经济高效的空间上下文增强方式。
为系统研究这一新范式,我们首先构建了一个将地理数据整合到现有自动驾驶数据集的框架。该框架通过谷歌地图API和自车姿态信息实现数据收集和空间对齐的自动化,以获取并对齐坐标系。利用这一框架,我们随后为nuScenes数据集扩展了相应的地理图像和基于坐标的空间检索API。最后,为探究这一新模态的效果,我们在五个关键自动驾驶任务上建立了基准:目标检测、在线建图、占用预测、端到端规划和生成式世界模型。我们设计了一个即插即用的适配器,将地理图像无缝整合到现有模型中。大量实验表明,该模态能够提升多个任务的性能。
我们的主要贡献总结如下:
提出自动驾驶空间检索范式,减轻车载感知对环境的敏感性,并提供广泛的远距离上下文信息。
构建扩展nuScenes数据集——nuScenes-Geography,包含地理图像和空间检索API,为新范式的系统研究提供支持。
设计模型无关的适配器,并在五个自动驾驶任务上建立基准,验证新模态的广泛适用性。
开源数据构建流程、扩展数据集及所有基准模型,以促进后续研究。
算法详解
空间检索范式与任务定义
假设一段自动驾驶数据 由 个时序化的传感器和姿态数据 组成,其中每个时间步 包含车载传感器数据 (例如带有相机内参和外参的多视角图像 )和自车姿态 。
引入离线地理数据库 ,该数据库由地理图像 及其对应的元数据(全球坐标和相机参数) 构成。
我们在五个自动驾驶任务上评估空间检索范式的有效性(表1)。对于车载任务(3D目标检测、在线建图、占用预测和运动规划),每个时间步 都会应用检索函数 ,该函数以当前图像 和自车姿态 为输入,从 中检索最相关的地理数据:
为简化起见,本研究中我们为每个相机在每个时间步检索最近的地理图像。若3D距离大于阈值,API返回“无(NONE)”。未来可探索更先进的检索方式,例如检索更多邻域图像作为全局上下文。
对于离线任务(生成式世界模型),会沿生成目标行驶轨迹检索多张地理图像,为长时域、全局一致的场景生成提供空间支架,减少幻觉现象。
空间检索适配器
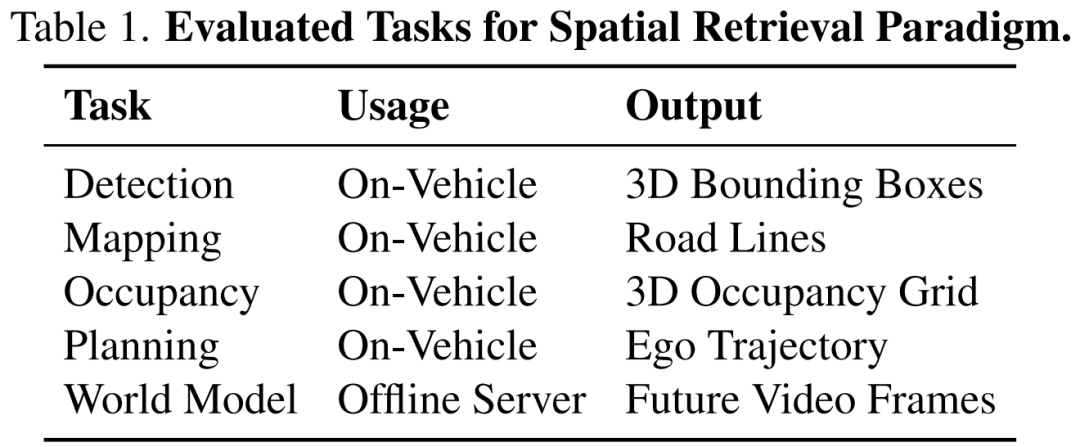
本节介绍一种通用的即插即用模块(图2左),用于将检索到的地理数据融入基于鸟瞰图(BEV)的车载任务,作为直观基准。结合各任务先验知识的更先进模块将留待未来研究。
地理图像与位置编码:检索到的地理图像通过与车载相机相同的骨干网络编码得到 。为编码检索地理图像与当前自车位置的相对空间关系,我们采用PETR对地理图像块进行3D位置编码,得到 。
地理交叉注意力:地理特征通过带位置编码的交叉注意力融入BEV表示,由可靠性分数 调制以处理检索缺失或错误的情:
增强后的BEV特征随后输入原始下游任务头。这种即插即用设计保持所有训练目标和网络架构不变。
生成式世界模型的空间检索
自动驾驶生成式世界模型可作为数据生成器、闭环评估器或强化学习(RL)环境,通常运行在集群和服务器上而非车载设备。因此,这些模型可获取未来自车轨迹,能够沿即将行驶的路径预检索地理图像,类似Bench2Drive-R。通过在生成过程中注入未来位置的地理图像,提供持续的空间线索,维持场景一致性。
地理扩展DiT:参考Bench2Drive-R,为将地理数据融入生成过程,我们在广泛使用的DiT模块的原始注意力层后,额外注入一个地理交叉注意力层:
其中 表示带噪声的 latent 特征, 表示生成片段起始帧和结束帧的检索地理特征。该设计使模型能获取对应未来位置的地理上下文。
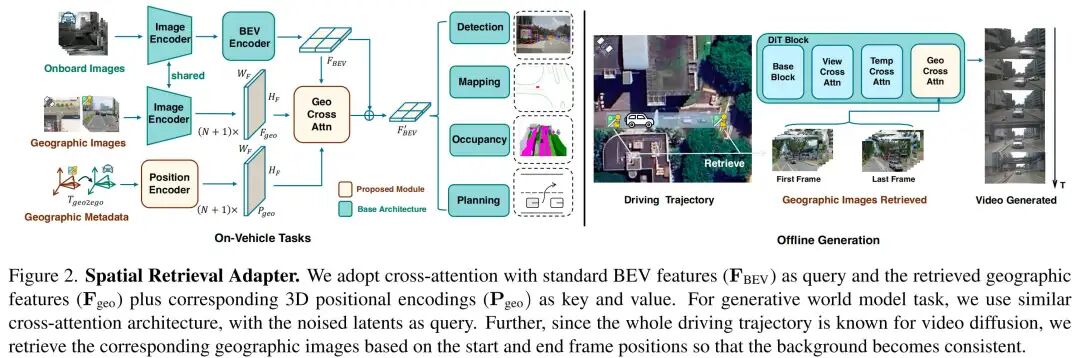
基于可靠性估计的自适应融合
利用地理数据的核心挑战是处理缺失或错位的街景图像(图7)。为减少这类情况的影响并提升模型对不可靠检索的鲁棒性,我们引入自适应融合机制(图3),基于以下两点动态调整地理特征的贡献权重:(i)检索位置与自车姿态的距离;(ii)检索图像与当前车载图像的相似度。
具体而言,我们设置可靠性估计门控模块输出可靠性分数 ,其中ZNCC计算车载特征与地理特征的零归一化互相关, 是街景位置与自车位置的距离, 是sigmoid函数。训练过程中,我们用二元标签(0表示无效/缺失,1表示有效)监督 的学习。测试时,该学习到的估计器可对不可靠地理特征进行降权。

三、nuScenes-Geography:基于谷歌地图的扩展地理数据
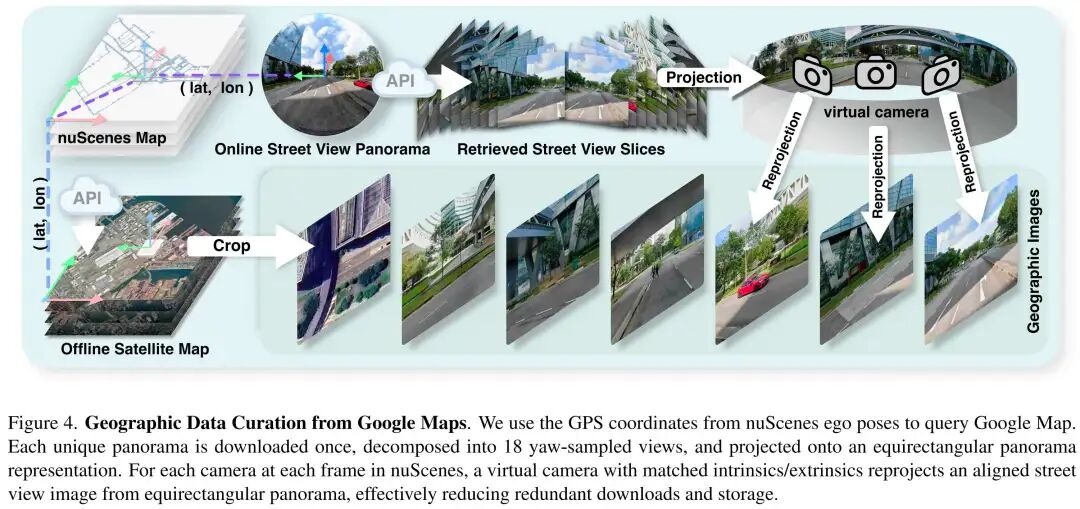
为系统验证空间检索范式的有效性,我们引入nuScenes-Geography数据集——通过谷歌地图API收集地理数据,对广泛使用的nuScenes数据集进行扩展(图4)。
坐标计算
为建立地理数据与nuScenes帧的关联,我们结合nuScenes地图的全球原点和自车姿态,计算每个帧的经纬度坐标。利用这些坐标查询谷歌地图API,获取街景图像和卫星地图切片。
面向高效存储与检索的等矩形全景图表示
由于街景图像的空间采样频率显著低于nuScenes的关键帧速率,同一条道路上的多个nuScenes帧可能对应相同的街景位置(图5)。为最小化存储开销,每个独特的地理数据仅检索一次,并存储该地理数据与其所有最近nuScenes帧的映射关系。
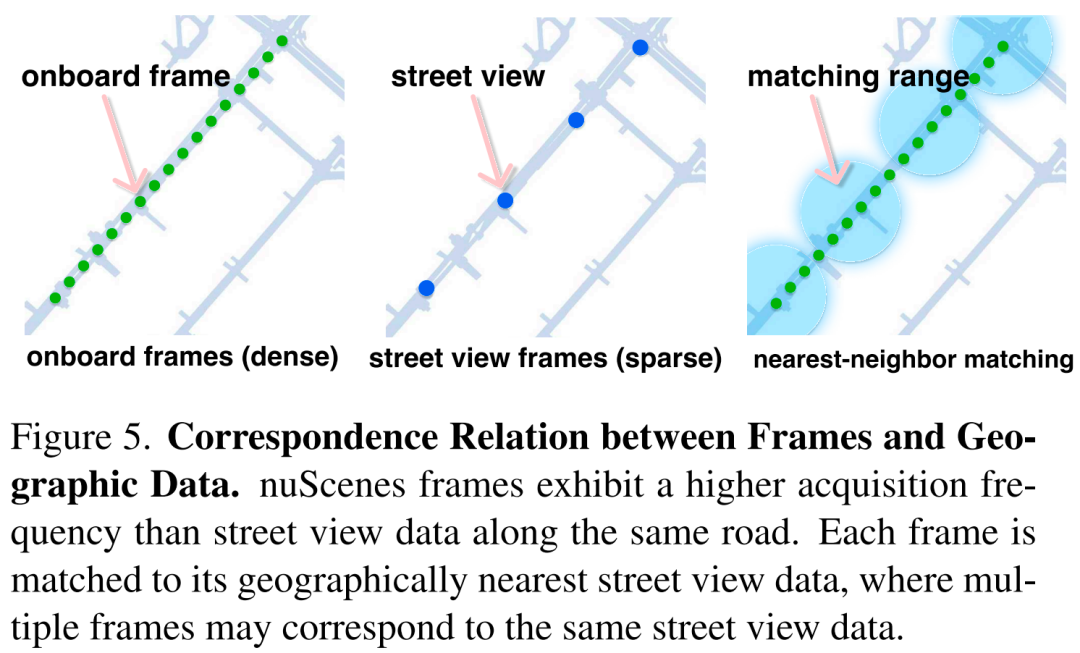
然而,nuScenes中不同帧对同一街景位置需要不同视角。为在保证几何正确视角的同时维持存储效率,我们采用等矩形全景图表示:
数据获取:对于每个街景位置,从API检索18张视角图像,这些图像具有分布式偏航角(覆盖360°)和固定俯仰角0°。
等矩形全景图格式:将这些图像投影到球面表示,并存储为等矩形全景图格式。
虚拟相机对齐:对于nuScenes的每个帧和每个车载相机,在对应街景位置实例化一个虚拟相机,其内参与nuScenes相机模型一致。外参变换由自车姿态和街景拍摄点推导:旋转遵循原始nuScenes相机朝向,平移由街景与自车的经纬度偏移计算得出,z轴平移设为固定常数。
重投影检索:利用虚拟相机配置,从等矩形全景图进行透视投影,合成与nuScenes帧几何对齐的街景图像。
该过程确保每个车载帧与其合成街景视角的空间一致性和一一对应关系,同时使整个收集流程具备存储高效性——与直接下载每帧街景裁剪图相比,存储量减少超过70%。
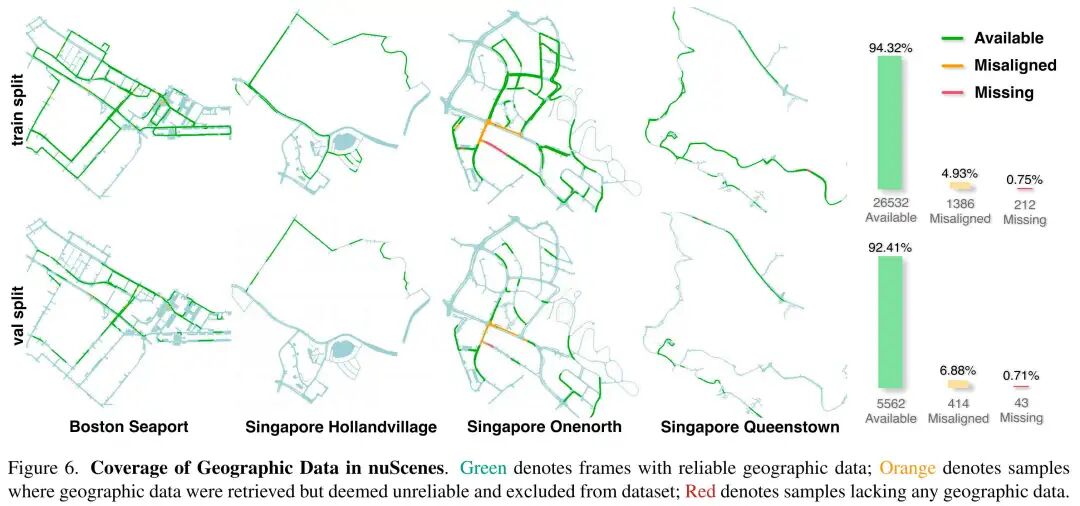
缺失与错位地理数据的处理
如图7所示,谷歌地图API可能返回空响应或错位地理数据。如前文所述,我们设计自适应融合机制,通过残差门控让模型选择性融合可靠的地理信息。在nuScenes-Geography的构建过程中,我们手动检查所有下载的地理图像,识别出1800个错位案例,作为可靠性估计模块的负样本标签。图6展示了nuScenes地理数据的覆盖情况,整体覆盖率较高。
四、实验结果分析
本节在扩展后的nuScenes-Geography数据集上,针对五个任务评估所提出的空间检索范式。我们探究了空间检索的三大潜在优势:提升静态场景理解能力、增强规划鲁棒性以及改善生成式世界模型的空间一致性。
场景理解
空间检索提供了稳定的背景视图,弥补了车载传感器在极端视觉条件下的脆弱性和有限感知范围。
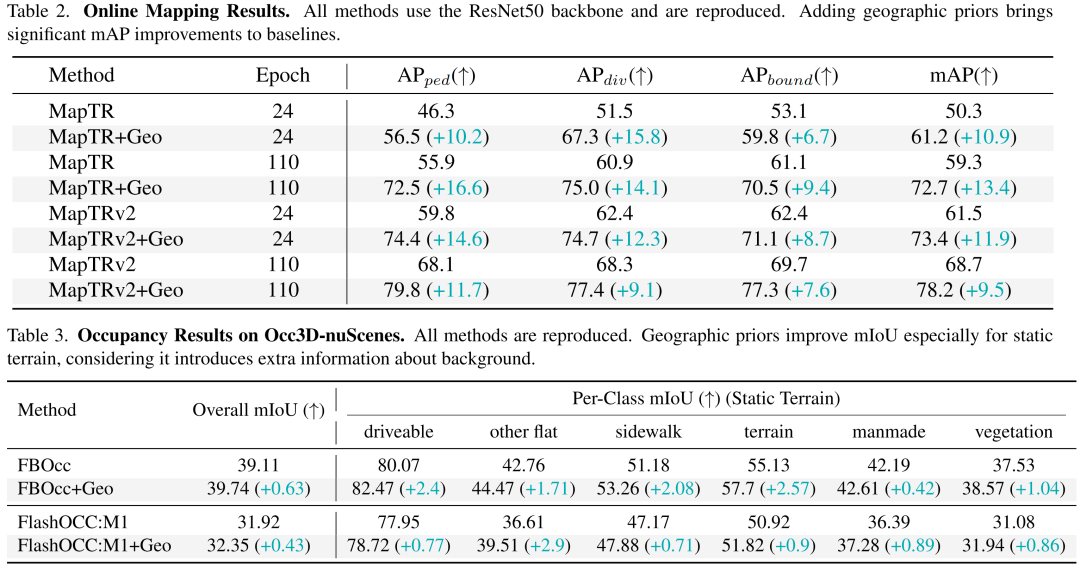
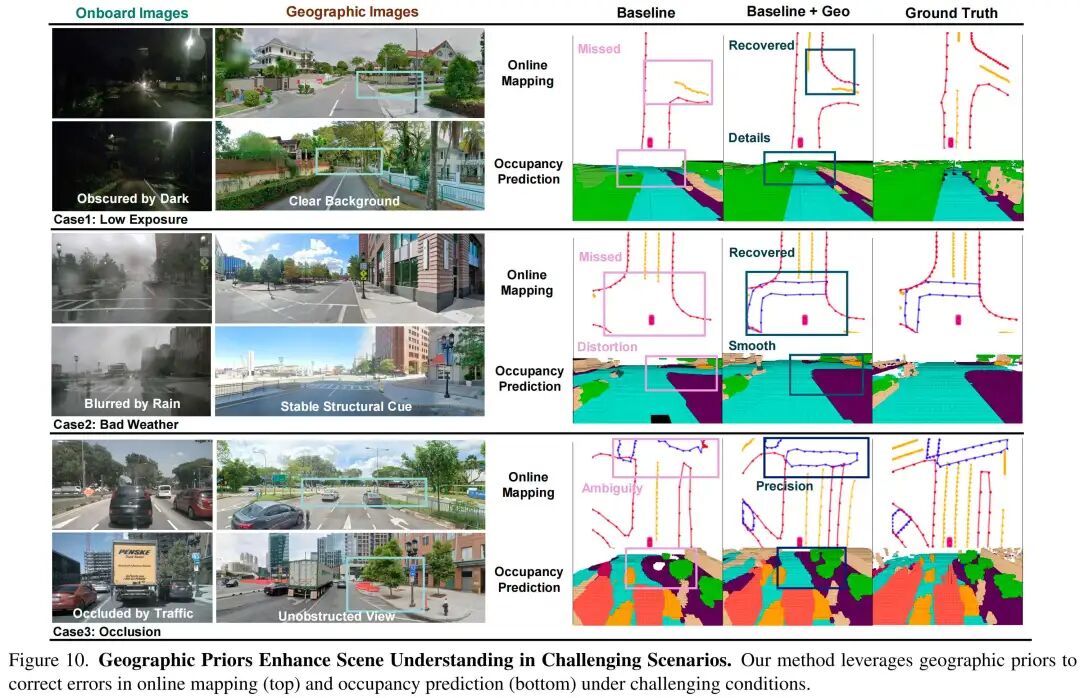
在线建图:如表2所示,将地理先验融入MapTR和MapTRv2后,在线建图性能显著提升。额外的背景信息有助于恢复被遮挡的车道(见图10)。
占用预测:如表3所示,扩展FBOCC和FlashOCC后,模型的平均交并比(mIoU)持续提升,静态类别尤为明显。该先验为背景几何结构提供了抗传感器噪声的锚定(见图10)。
目标检测:如表4所示,BEVDet和BEVFormer在融入地理数据后提升微乎其微。这一结果符合预期,因为空间检索主要提供背景信息。不过,利用地理数据区分前景与背景进而辅助目标检测,是一个值得探索的未来方向。

规划鲁棒性
我们基于VAD评估空间检索对安全规划的促进作用。地理先验提供了一致的道路布局信息,弥补了遮挡或光照不足导致的传感不稳定性。如表6所示,在保持轨迹精度相当的前提下,我们的方法提升了安全裕度。具体而言,在具有挑战性的夜间场景中,平均碰撞率从0.55%降至0.48%,证明了地理先验作为安全规划可靠指导的价值(见图9的可视化示例)。

生成式世界模型一致性
我们进一步评估地理先验对生成式世界模型的辅助作用。将UniMLVG和MagicDriveDit (针对MagicDriveDit,我们将测试集采样步长调整为13,以避免重复采样近重复片段)与地理图像进行条件关联后,模型的视频弗雷歇距离(FVD)和inception距离(FID)均降低,有效防止了场景漂移,在滚动生成过程中保持了几何一致性(如表5所示)。这证实了空间检索可作为结构化支架,支撑连贯的世界建模。
错位空间检索的可视化
新范式面临检索缺失或错位的挑战——当离线地理图像与相机图像不一致时会出现此类问题(见图7)。其原因主要包括:(1)地图过时:道路布局因施工发生变化,但缓存的地图影像未准确反映,可能误导模型;(2)GPS/定位误差:自车姿态不准确可能导致检索图像与车载传感器图像错位,谷歌地图API偶尔会出现此类情况。
消融实验
我们在占用预测任务(FlashOcc)和生成式世界模型任务(Unimlvg)上进行消融实验。如表7所示,引入地理先验始终能带来显著性能提升,而位置编码和可靠性估计门控则进一步优化了性能。

定性分析
在线建图:图10显示,当车载相机的视觉线索退化或缺失时,地理先验有助于重建地图元素。
占用预测:图10显示,地理先验提供了清晰稳定的几何参考,能够恢复被遮挡的背景结构。
规划:图9显示,地理先验提供的稳定道路几何信息,使模型在复杂路口和恶劣天气下能生成更平滑、更安全的轨迹。
生成式世界建模:图8显示,地理先验防止了长时域滚动生成过程中的生成崩溃,维持了场景一致性。


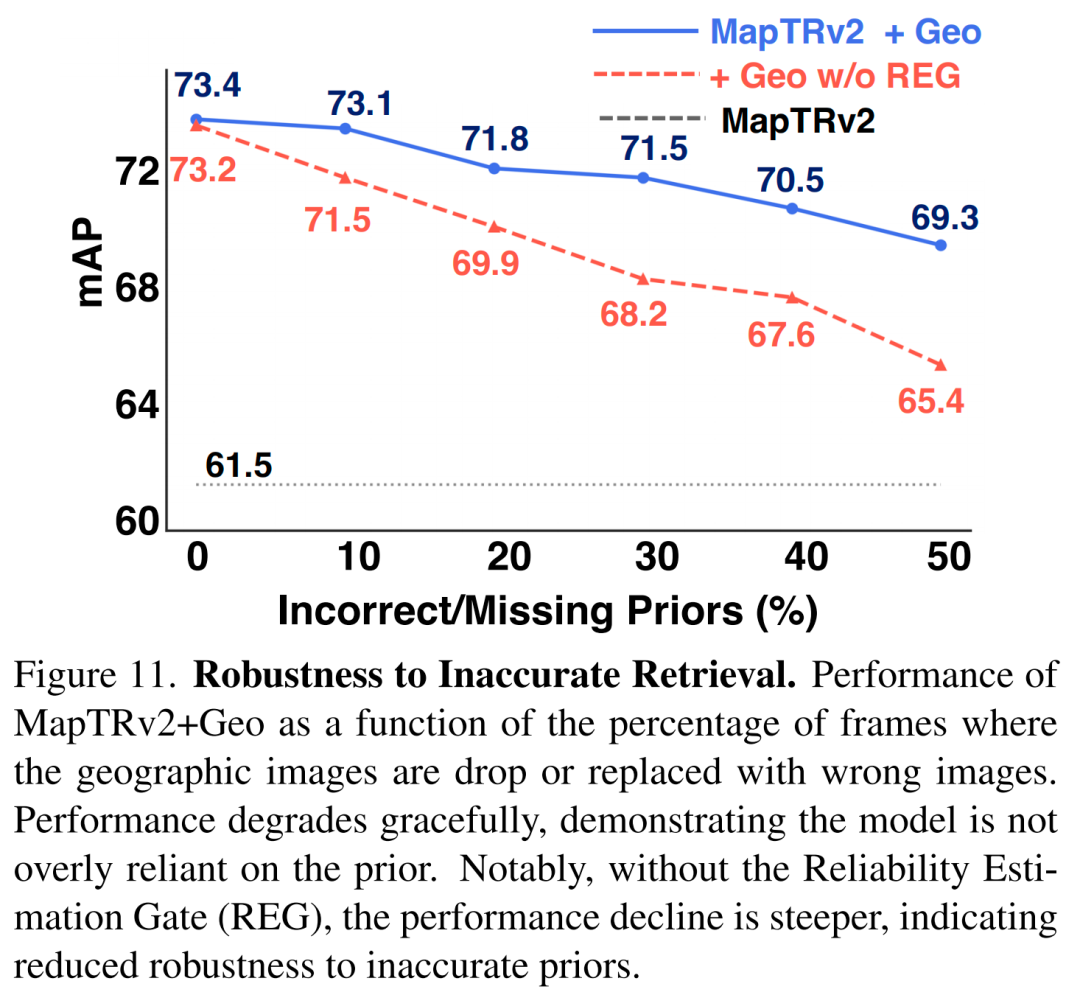
对不准确检索的鲁棒性
为进一步评估所提出的可靠性估计门控的有效性,我们测试了在线建图方法MapTRv2在不准确检索下的鲁棒性。我们随机丢弃地理图像,或在一定比例的帧中用随机错误图像替换它们。图11显示,随着先验可用性的降低,模型性能平稳下降。即使50%的先验缺失或错位,模型仍保留了相对于基准的大部分性能提升。这表明,所提出的可靠性估计门控使模型能够在有可用先验时加以利用,而在无先验时不会出现灾难性失效,体现了良好的实际应用鲁棒性。
五、结论
本研究提出了自动驾驶空间检索范式,将地理数据作为额外输入引入系统。我们通过谷歌地图API获取地理数据,扩展了nuScenes数据集,并在扩展后的nuScenes-Geography数据集上对五个关键自动驾驶任务进行了评估。我们设计了通用的即插即用型空间检索适配器,作为融入地理数据的直观基准;同时提出可靠性估计机制,基于检索数据的可靠性自适应融合地理信息。大量实验表明,所提出的范式能够提升多个自动驾驶任务的性能,彰显了这一新范式的巨大潜力。
自动驾驶之心
3DGS理论与算法实战课程!

知识星球交流社区


















 5493
5493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









