



作者 | wangleineo 来源 | 青稞AI
原文链接:https://zhuanlan.zhihu.com/p/1972781108128155202
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
最近看了几篇关于RL学习的论文,发现这几篇研究存在着一些内在联系,综合起来看,也许有助于我们理解RL学习方法的本质。
破除迷信
Does RLVR enable LLMs to self-improve?
第一篇文章是最近备受关注的一篇论文,来自清华的LEAP实验室,在今年的NeurIPS拿下了全满分,获得最佳论文奖:
https://arxiv.org/abs/2504.13837这篇论文开宗明义提出了一个问题:RL学习真的能让LLM获得超越基础模型的推理能力吗?
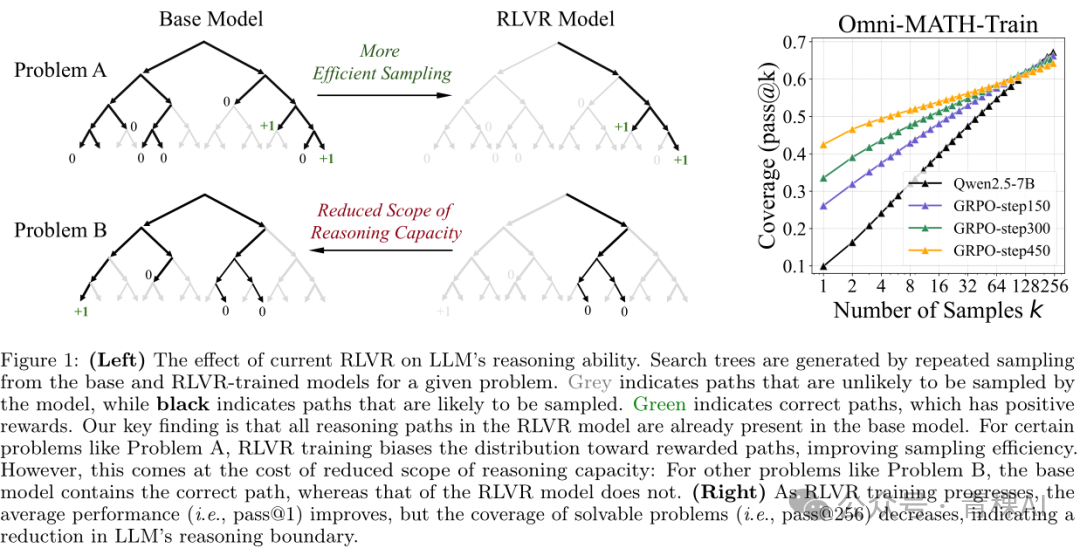
研究结论很确切,不能。论文用实验证明,RLVR后模型的能力完全在基础模型的能力范围内,只是搜索效率提高了,能更高效地找到问题的解。而基础模型不能解决的问题,RLVR的模型一样不能解决。
证明的方式就是用pass@K(生成 K次结果,只要有一次通过就算通过)的评估方式来比较RL模型和基模的表现。论文发现,在 @1的时候,RL模型的表现都会好于基模,但是随着K的增大,和基模的表现越来越接近,直到在K较大时RL被基模超越。
而且这个结论对于各种RL方法(PPO/GRPO等),在各种评估测试集(数学、代码、视觉推理),各种模型大小上面都适用。
Base VS RL on pass@k
之所以用pass@K的评估方式,是因为这个研究并不是为了测量模型的实际性能,而是为了衡量模型内在能力的边界(boundary)。事实证明,RLVR并没有真正拓展这个边界,而只是在边界内高效寻找到了解决问题的路径而已。RL同时收窄了推理路径的范围(coverage),所以在K较大时,反而没有基础模型的表现更好。
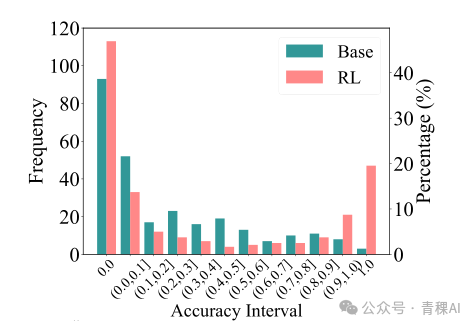
更进一步分析模型的精确度分布,我们发现RL的模型呈现两极分化的特征:在高精确度上特别集中,而在低精确度上的表现不如基模,精确度为零的概率反而较高。
RL训练后的模型就像是一个严重偏科的学生,会做的题目都能打满分,但是对于不会做的题目,猜对的概率还不如普通的学生。
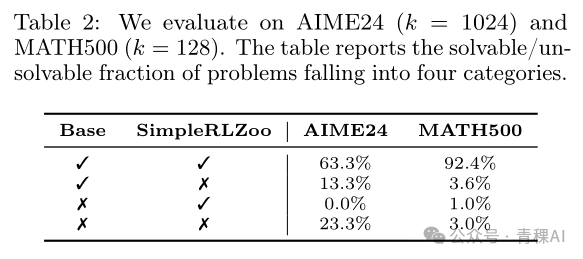
对于两种模型表现的比对可以进一步证明上面的结论:有很多题目RL没有解决,但是基模能解决;但是反过来,基模不能解决,RL能解决的题目几乎不存在(下表中第三行,百分比接近于零)。
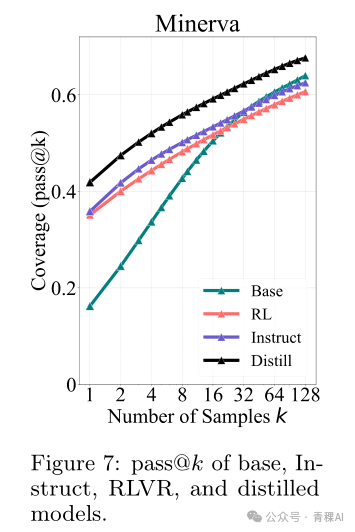
与RL学习不同,Distillation学习(SFT)方式可以拓展模型的能力,让模型学会解决原来不能解决的问题:
RL学习这种限制的主要原因被认为是在语言广阔的探索空间中,预训练先验(prior)存在“双刃剑”效应。虽然先验使强化学习训练变得可行,但它也限制了探索,因为任何偏离都可能导致低奖励输出。因此,强化学习算法会强化先验内的解决方案,而不是发现其外的创新路径。
这篇文章只是验证了一个假设,并没有否定RL学习方法本身的价值。基础模型和RL模型的对比,就像是通才(generalist)和专才(specialist)的对比,在解决具体领域问题的时候,往往还是专才能堪大用,我们也会容忍专才的偏执和狭窄的视野。
当然,文章最后也提出,也许我们能找到一种训练方法,平衡模型的exploration和exploitation,让模型在提高效果的同时,不收窄探索的范围。
更新:经评论区小伙伴提醒,有其他论文提出了貌似完全相反的结论:
https://arxiv.org/pdf/2509.25123
看来这个课题还远远没有定论。用一个capability来概括LLM能学习的能力也许过于泛化,可能我们需要一个细化的capability taxonomy,做更加科学的Ablation研究和分类实验。
探究原因 - The Path Not Taken
为什么RL训练会有这样的效果呢?另一篇来自Meta的论文也许给出了解释:
https://arxiv.org/abs/2511.08567z z研究者认为,RL训练有一个特征,参数更新高度局部化。文章把它称为model-conditioned optimization bias:
For a fixed pretrained model, updates consistently localize to model-preferred parameter regions, remain highly consistent across runs, and are largely invariant to datasets and RL recipes.
文章用两个很形象的图来表示了这个特征:SFT训练的过程就像是越野,走的路径百无禁忌,可以爬山下谷;而RL训练的过程像是带着一个指南针,按照这个指南针的指引,在相对平坦的地面上谨小慎微地前行。

这个指南针,或者说这个optimization bias是从哪里来的呢?作者提出了一个“三重门”的理论:
Gate I: On-Policy RL Imposes a One-Step KL Leash
RL学习会限制每一步更新的KL分布,让它接近模型的原有分布。就像给探索戴了一个狗链(leash),每一步都不会走太远,向着更高奖励的方向小步前进。
Gate II: Model Geometry Determines Where a KL-Bounded Step Goes
一个经过预训练的模型,它的参数空间会有一些结构化的几何特征,会有一些高曲度的方向。可以直观地把它理解为探索空间的主山脉、深峡谷的走向。
而RL训练的更新,会尽量避开这些高曲度方向的更新,采用尽量沿principal angle的方向更新。从参数矩阵的角度说,矩阵的主向量和特征值都会大体保持原样。
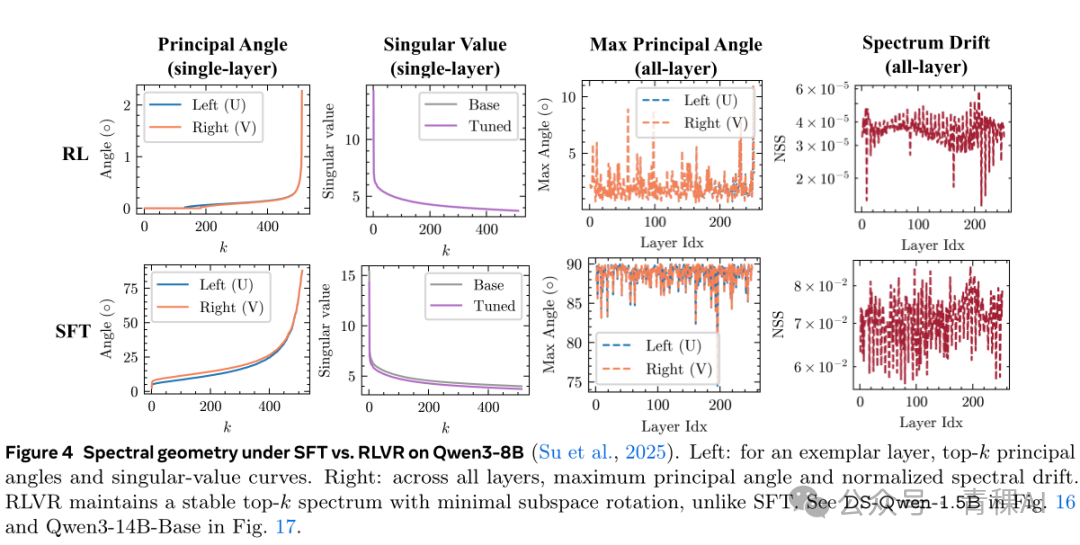
Gate III: Precision Acts as a Lens Revealing the Compass
这重门的意思是,在偏离主向量的方向上并不是没有更新,但是更新的幅度很小。这就导致低精度的参数表示,比如bfloat16,就会起到一个过滤器的作用,把这些幅度很小的更新直接归零。
作者也在这里澄清了一个广为流传的误解:RL产生的更新非常稀疏(sparse)。实际上RL更新的参数并不少,只是一些小更新被参数的表示精度抹平了:
RLVR exhibits a persistent, model-conditioned optimization bias in where updates land—highly consistent across runs and largely invariant to datasets and RL recipes. The observed sparsity is a superficial readout of this bias, amplified by bf16 precision.
关于这三重门的数学解释,请参见论文,这里不展开了。
通过观察训练后参数空间的变化,作者得出了以下结论:
• RLVR Preserves Spectral Geometry, While SFT Distorts It
• RLVR Avoids Principal Weights, While SFT Targets Them
• RLVR Relies on Model Geometry, Disrupting Geometry Destroys the Bias
• RLVR signatures persist in agentic tasks and RLHF
作者认为,现有的一些RL训练方法,比如PiSSA,没有考虑到RL存在这种参数更新的特征,所以效果不好。我们应该可以设计一些适用于RL的参数更新方法,比如冻结主要权重,而更新“非主要、低幅度的权重。”我们可能需要研究一些"RL-native, geometry-aware" 的算法,来适配RL学习的这种特征。
这项研究使我们从‘黑箱’视角转向对RL如何学习的‘白箱’理解。RL这种“循规蹈矩”的特点,就大体上解释了第一篇论文中“RL为什么没有真正提高模型能力”的问题。
灾难性遗忘 - 没有免费的午餐?
读到这你可能会问,既然RL不能真正提高模型的能力,而SFT可以,那我们为什么不用SFT方式来做所有的训练呢?这就不得不提到灾难性遗忘的问题。
RL's razor这篇论文指出,SFT训练会导致严重的灾难性遗忘,而RL训练却不会。
https://arxiv.org/abs/2509.04259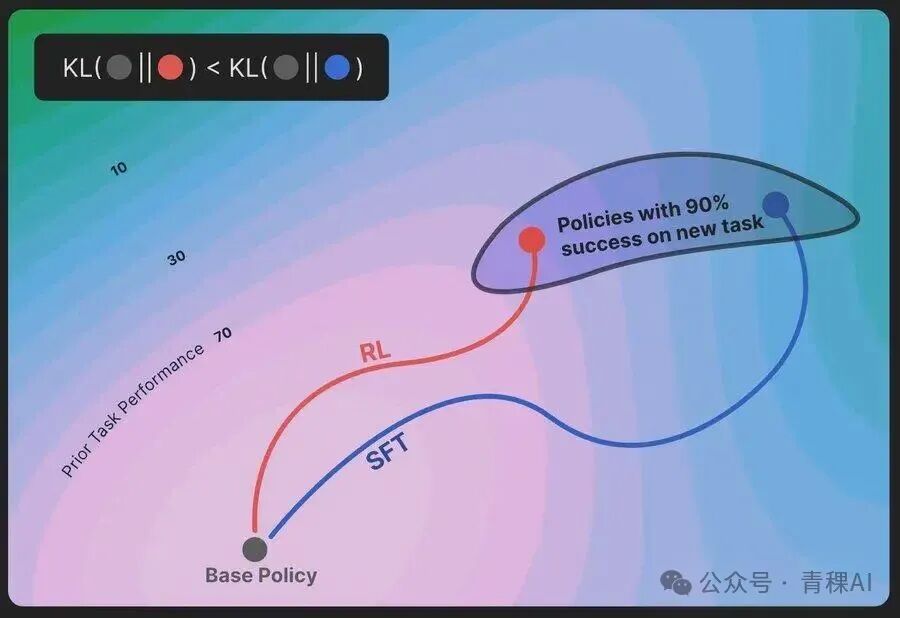
关于这一篇论文,我在另一篇文章中已经有解读,在此不再赘述:持续学习和灾难性遗忘[1]
把这几篇论文的研究结论联系起来看,我脑中想到了一个问题:学习新技能和避免灾难性遗忘会不会是鱼与熊掌,不可兼得?我们看这个表格:

也许学习新能力和避免遗忘之间,存在表中所展现的互斥性。如果是这样,只能说天下没有免费的午餐,只能在两者之间做权衡(tradeoff),看具体场景选择训练方案了。
但也许原理上并不存在这样的互斥性,也许我们可以二者兼得。最近Thinking Machines的一篇文章就是这个方向的一个探索。
他们的方法叫做On-policy Distillation,可理解为RL方法和SFT的一种“杂交”,原理上是一种RL训练,但过程又类似于SFT的蒸馏训练:Thinking Machines新文章:On-Policy Distillation[2]
真希望第一篇论文的研究者能用他们的实验方法来测试一下TML的On-policy Distillation,看看结果如何。如果OPD方法能:
• 通过蒸馏扩展模型的能力边界
• 高效寻找推理路径
• 避免灾难性遗忘
那恐怕我们就找到了LLM模型训练的一个灵丹妙药,能治百病,又没有副作用。说不定,就此开启了模型进化的新纪元呢。
引用链接
[1] 持续学习和灾难性遗忘: https://zhuanlan.zhihu.com/p/1969174968651736270[2] Thinking Machines新文章:On-Policy Distillation: https://www.zhihu.com/pin/1968462515513062544
自动驾驶之心
端到端与VLA自动驾驶小班课!

添加助理咨询课程!

知识星球交流社区


















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









