



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Yulong Cao等
编辑 | 自动驾驶之心
英伟达许久不见自动驾驶方向的论文工作,昨天直接放了个大招,难得啊。。。
一篇长达41页的自动驾驶VLA框架 — Alpamayo-R1。Alpamayo-R1指出基于模仿学习的端到端架构,在长尾场景中的表现能力很差,这是由于监督信号稀疏并且因果推理的理解能力不足。另外现有自驾VLA的框架没办法显式约束思维链和决策行为之间的关联,一方面可能出现幻觉的问题,另一方面也没办法保证因果理解的正确性。举个错误的例子:左转是红灯,但由于直行是绿灯所以允许车辆左转。
为了解决这些问题,Alpamayo-R1将因果链(Chain of Causation)推理与轨迹规划相融合,以提升复杂驾驶场景下的决策能力。本文方法包含三大核心创新:
(1)因果链(CoC)数据集:通过“自动标注+人机协同”的混合流程构建,生成与驾驶行为对齐、以决策为核心且具备因果关联的推理轨迹;
(2)模块化VLA架构:整合为物理智能(Physical AI)应用预训练的视觉-语言模型Cosmos-Reason,以及基于扩散模型(diffusion-based)的轨迹解码器,可实时生成动态可行驶的规划方案;
(3)多阶段训练策略:采用有监督微调SFT激发模型推理能力,并结合强化学习,通过大型推理模型反馈优化推理质量,同时确保推理与动作的一致性。
结果表明,相较于仅基于轨迹的基准模型,AR1在高难度场景下的规划准确率提升高达12%;在闭环仿真中,偏离车道率降低35%,近距离碰撞率降低25%。经强化学习后训练(RL post-training),通过推理模型评估器测得模型推理质量提升45%,推理-动作一致性提升37%。模型参数从0.5B扩展至7B时,性能持续提升。实车道路测试验证了该模型的实时性能(延迟99毫秒)及成功的城市路况部署能力。通过将可解释推理与精准控制相衔接,AR1为实现L4级自动驾驶提供了一条切实可行的路径。未来,英伟达计划发布AR1模型及部分CoC数据集。
论文标题:Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
论文链接:https://arxiv.org/abs/2511.00088
开源链接:https://huggingface.co/datasets/nvidia/PhysicalAI-Autonomous-Vehicles
一、背景回顾
自动驾驶系统的发展经历了范式转变:从传统的模块化架构转向端到端自动驾驶框架,这一转变已得到业界的广泛认可。传统模块化设计通过人工设计的中间表示,将感知、预测与规划模块明确分离;而端到端方法则通过联合训练的神经网络,直接将原始传感器输入映射为车辆运动指令。这种一体化设计消除了人工设计的接口,支持大规模的联合优化与数据驱动型策略学习。近年来,基于Transformer的架构不断发展,结合大规模驾驶数据集,进一步提升了端到端驾驶范式的整体性能与泛化能力。
尽管取得了这些成果,当前端到端方法在处理长尾场景与安全关键场景时仍存在脆弱性——这些场景中,监督信号稀疏且需高阶推理能力,给模型带来了重大挑战。因此,现有端到端模型的能力与实现具备驾驶专属推理能力的稳健L4级自动驾驶需求之间,仍存在显著差距。
大语言模型的最新进展为填补这一推理差距提供了极具潜力的方向。LLMs彻底改变了人工智能领域,其缩放定律表明,随着计算资源与数据量的增加,模型性能会呈现可预测的提升。除训练阶段的缩放外,近期的前沿模型(如OpenAI的o1、DeepSeek-R1等)还引入了一种新范式:inference-time reasoning。与传统单步答案生成不同,这些模型会生成中间推理轨迹(即“思维链”),模仿人类解决问题的策略。这一转变使推理时间成为可调节资源:为审慎推理分配更多计算资源,通常能获得更准确、稳健且可验证的决策。对于自动驾驶而言,这种推理能力尤为重要——毕竟驾驶决策本质上存在不确定性,且关乎安全。基于文本的推理还能让模型在执行动作前,在语言空间中探索多种可能结果,其核心优势包括:
(1)通过显式反事实推理及运行时安全交叉校验与监控,提升安全性;
(2)通过人类可理解的决策依据,增强模型可解释性;
(3)提供更丰富的训练信号(可作为可验证奖励),以提升长尾场景下的性能。
视觉-语言模型(VLMs)与视觉-语言-动作模型(VLAs)已在自动驾驶领域得到广泛应用,但多数方法要么缺乏显式推理过程,要么采用自由形式、无结构化的推理方式。这类方法难以泛化到训练分布之外的场景,尤其在模糊或组合型长尾场景中——这些场景亟需强领域先验知识的支撑。此外,若将自动驾驶车辆的推理视为纯粹的自然语言处理(NLP)问题,会忽略驾驶任务固有的丰富结构化知识,例如车道几何、交通规则、地图先验、智能体交互及动态约束等。
本文认为,有效的自动驾驶推理必须具备因果锚定能力,且在结构上与驾驶任务对齐。推理轨迹不应是冗长的无结构化叙述,而应通过因果链将观测到的场景证据与具体驾驶决策显式关联,且这些决策需直接约束或控制低阶轨迹生成。上述设计原则确保:推理不仅是提升可解释性的附加组件,更是提升训练效率与闭环驾驶性能(尤其在安全关键型长尾事件中)的功能性核心。
本文提出Alpamayo-R1(AR1)——一种扩展自视觉-动作(VA)模型Alpamayo-VA的VLA模型,具备结构化推理能力,可衔接推理与动作预测,实现泛化性自动驾驶。该模型通过三大核心创新应对上述挑战:
构建结构化的因果链(CoC)标注框架:生成与驾驶场景对齐、以决策为核心且具备因果关联的推理轨迹;同时开发“人机协同+自动标注”的混合流程,支持大规模高质量数据生成。
采用基于flow matching的动作专家轨迹解码器:高效生成连续、多模态的轨迹规划方案,既能与语言推理输出对齐,又能满足实时推理需求。
设计多阶段训练策略:以Cosmos-Reason VLM为主干网络,注入动作模态以实现轨迹预测,通过在CoC数据集上的有监督微调激发推理能力,并采用强化学习(RL)提升推理质量、推理-动作一致性及轨迹质量。
通过大量开环与闭环(仿真及实车)评估,本文证明AR1相较于端到端基准模型实现了显著性能提升,且在罕见、安全关键场景中的收益最为显著,同时保持了实时推理性能(端到端推理耗时99毫秒)。
二、构建推理型视觉-语言-动作(VLA)架构
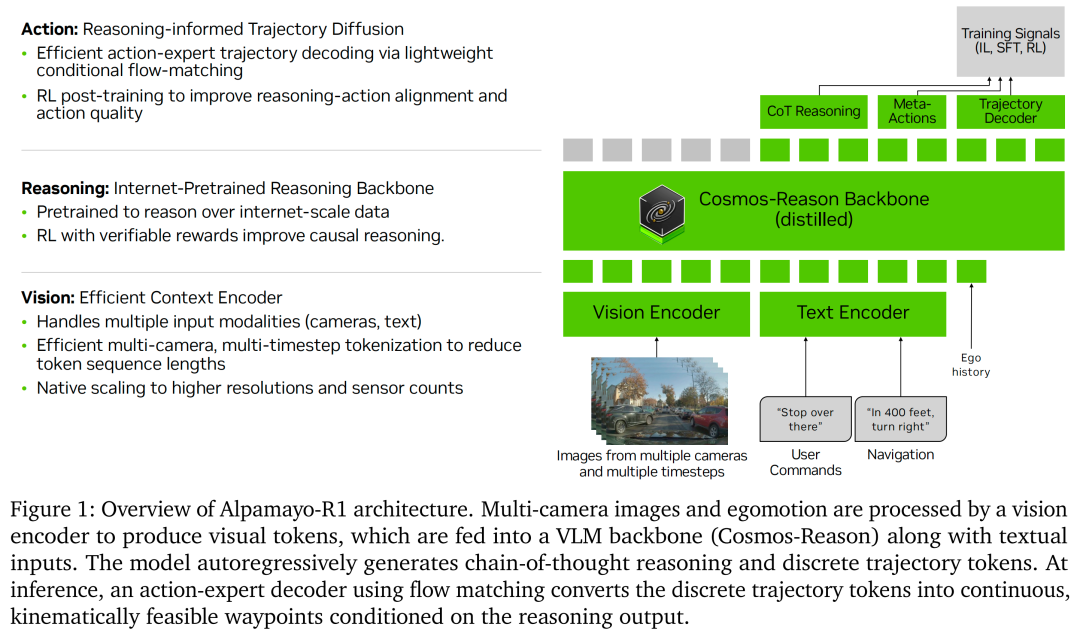
构建适用于自动驾驶的高效推理型视觉-语言-动作(VLA)模型,需具备通用视觉-语言模型目前尚不具备的多项新能力。首先,自动驾驶车辆需依赖多摄像头、多时间步观测实现360度环境感知,但标准VLMs通常独立处理图像或视频帧,缺乏显式的时序与跨视角推理能力,导致处理多摄像头输入时token数量过高,无法满足实时推理需求。其次,驾驶决策需基于结构化因果推理,而非自由形式的叙述;模型需依据历史窗口中的可观测证据,解释某项操作为何安全且合法。第三,模型需实时生成精准的多模态轨迹预测;将路径点作为文本token进行自回归解码效率低下,且缺乏安全车辆控制所需的几何与运动学约束。最后,为确保长尾场景下的安全性,推理轨迹需与执行动作保持对齐。
为应对上述挑战,本文提出Alpamayo-R1(AR1)——一种模块化VLA架构,其在Alpamayo-VA模型基础上扩展了推理能力,可衔接推理与动作预测以实现自动驾驶。该架构的设计理念强调灵活性与模块化:可兼容任何现成的VLM backbone网络,同时集成面向自动驾驶领域的专用组件(用于高效视觉编码与实时动作解码)。这种模块化设计使我们能够充分利用视觉-语言预训练领域的最新进展,同时高效衔接高阶推理与低阶控制,以适配自动驾驶任务。
问题定义
给定截至时间戳 的历史观测序列 (下文省略时间戳标注),包括多摄像头图像 与自车运动历史 ,AR1模型需完成两项核心任务:生成推理内容(记为Reason),以及预测自车未来轨迹 。本文将该任务建模为序列预测问题,整个序列定义为:
其中每个组件均依赖所有前序组件进行预测。默认情况下,模型需预测未来6秒的完整轨迹序列:
式中, 表示在时间戳 时,自车坐标系下以10Hz采样的第 个未来路径点( 为偏航角)。如3.2.2节所述,本文采用基于控制的表示方式(基于单轮车动力学模型),控制输入定义为:
式中, 与 分别表示第 个时间步的加速度与曲率。关于轨迹 的编码与解码细节,将在3.2.2节与5.1节中详细说明。
图1展示了AR1的端到端架构。该系统以多摄像头、多时间步观测作为视觉输入,可选择性融入文本输入(如用户指令与高阶导航指令)。所有输入(包括历史自车运动数据)均按预设顺序被token化,形成统一的多模态token序列。这些token随后输入Cosmos-Reason主干网络,输出包含推理轨迹、元动作(meta-actions)与预测未来轨迹的token序列。模型通过多阶段训练实现优化,融合有监督微调(SFT)与强化学习(RL)。
VLM主干网络:Cosmos-Reason
本文选用Cosmos-Reason作为AR1的VLM主干网络。Cosmos-Reason是专为物理智能(Physical AI)应用设计的VLM,通过在370万视觉问答(VQA)样本上进行后训练,具备物理常识与具身推理能力。该模型包含2.47万条精心筛选的驾驶场景视频VQA样本,涵盖场景描述、驾驶难度标注,以及从DeepSeek-R1蒸馏得到的动作预测推理轨迹。
领域特定有监督微调:
为进一步增强Cosmos-Reason在自动驾驶场景中的部署能力,本文构建了覆盖多个物理智能领域的补充数据集,包括自动驾驶、机器人、医疗健康、智慧城市、制造业、零售业与物流。这种跨领域物理智能预训练使模型能够形成通用的物理常识与具身推理能力,并迁移到驾驶场景中。针对自动驾驶任务,本文额外增加了10万条训练样本,包含环境关键目标标注与动作推理内容。
驾驶导向的数据构建:
为平衡标注质量与规模,本文设计了互补的标注方法:
人工标注数据:涵盖全面的标注内容,包括运行设计域(天气、光照、路况)、交通规则(红绿灯、交通标志)、自车行为(交互性与非交互性元动作)、影响自车行为的关键目标,以及观测操作背后的因果推理。这些标注可提升模型在复杂驾驶场景中的理解与推理能力。
自动标注数据:聚焦自车行为推理与预测,通过向教师VLM(如Qwen3-VL(Qwen Team, 2025))输入驾驶专属先验知识(包含纵向、横向、车道相关元动作及速度信息)生成标注。这种可扩展的方法能增强模型的预测推理能力。
特定领域适配
尽管Cosmos-Reason提供了坚实的基础,但要实现实际自动驾驶部署,仍需解决两个关键问题:多摄像头、多时间步输入的高效视觉编码,以及实时控制所需的精准轨迹解码。以下小节将详细介绍针对这些挑战设计的领域专用组件。
视觉编码
在VLM中,视觉编码器的核心作用是将输入图像转换为token流,供后续LLM主干网络处理。然而,由于VLA需部署在实车上,其视觉编码器的关键要求是:在保留环境相关语义信息的前提下,尽可能减少生成的token数量。目前已有多种视觉token化方法,其主要差异在于每次推理步骤的信息编码量(即多少图像被压缩为多少token)及相关架构设计。
本节将讨论AR1可采用的不同视觉编码器及其权衡关系,同时探讨进一步压缩token数量的方法,以实现更大主干网络的实时车载推理。
单图像token化:
许多视觉tokenizer主要关注单图像表示,要么采用自编码架构,要么直接对像素块进行编码。VLMs主要采用后者,通过视觉Transformer将图像分割为像素块,编码后形成一维token序列。本文将这种范式称为“单图像token化”,即模型将每个输入帧编码为一组token。
AR1的默认tokenizer(后续所有实验均采用此配置)采用该范式,利用基础VLM的视觉编码器将尺寸为 像素的输入图像编码为像素块特征 ,随后通过2倍双线性下采样得到单图像特征 。例如,当输入图像尺寸为 、 时,该过程每幅图像生成160个token。
多摄像头token化:
单图像token化虽易于实现,但生成的token数量会随图像分辨率与摄像头数量线性增加。自动驾驶车辆通常需配备6-10个摄像头以实现360度环境感知,若采用基于像素块的token化方法,每个时间步会生成数千个token,无法满足实时推理需求。因此,AR1还支持一类新型高效多摄像头tokenizer——先将多摄像头图像编码为中间表示,再对该中间表示进行token化。
具体而言,AR1可集成高效多摄像头tokenizer,该方法利用三平面(triplane)作为3D归纳偏置,可高效地同时表示多摄像头图像。关键在于,由于三平面尺寸固定,输入摄像头数量及其分辨率与最终生成的token数量完全解耦。形式上,对于网格尺寸为 、 、 的三平面,以及下游像素块划分参数 、 、 ,该tokenizer生成的token数量计算公式为:
例如,当 、 且 时,仅需288个token即可表示一个时间步的观测,与摄像头数量或分辨率无关。对于7摄像头车辆配置,这相当于每幅图像约41.1个token(比单图像token化减少3.9倍)。如6.6节所示,这种高效性的实现并未显著牺牲端到端驾驶指标。
多摄像头视频token化:
尽管上述方法已大幅减少传感器观测所需的token数量,但仍有两个核心方向可进一步提升效率:
(1)时序信息利用:帧间信息存在冗余,可通过时序建模减少token数量;
(2)突破结构化特征表示的性能上限。
因此,AR1还支持多摄像头视频tokenizer,可直接对多时间步的多摄像头观测序列进行编码。例如,Flex通过全自注意力层与固定查询向量集,对多摄像头、多时间步的图像token进行压缩,提供了控制信息瓶颈规模的显式机制。该方法相较于单图像token化,token压缩率最高可达20倍,同时仍能保持甚至提升下游驾驶指标。
token压缩的其他方向:
除上述token化策略外,还有多种补充方法可进一步减少token数量。例如,SparseVILA提出的训练后token剪枝技术,可在推理时动态识别并移除冗余token,无需重新训练,为已训练模型降低计算成本提供了实用路径。这些方法为AR1向更大主干网络扩展、同时保持实时性能提供了潜在方向。
轨迹解码
要使VLM能够在物理世界中有效运行,需将物理动作(在自动驾驶场景中即未来驾驶轨迹)融入VLA的训练过程。然而,具身化在动作解码中带来了独特挑战:
(1)动作表示需精准,同时保留保真度与多模态特性;
(2)解码过程需足够快速,以支持实时推理;
(3)解码机制需与VLA训练流程无缝集成。
本文研究发现,直接在原始位置(即 )路径点空间训练模型易受传感器噪声影响,导致模型收敛性能下降。此外,下游低阶车辆控制器通常需对轨迹输出进行平滑处理,以确保实车执行的一致性与稳定性。因此,本文未直接在原始位置路径点空间学习轨迹 ,而是采用基于单轮车动力学模型的动作表示,以提升闭环性能。具体而言,本文采用以下单轮车动力学模型:
式中,本文设置 秒; 表示鸟瞰图(BEV)平面中的位置路径点; 为偏航角; 为速度; 为曲率; 为加速度。训练阶段,通过带Tikhonov正则化的最小二乘方法,从轨迹 中推导得到真实控制序列 ,以抑制高频噪声。模型训练目标为预测控制序列 ;推理阶段,通过式(5)将 映射为轨迹 。
此外,为使AR1能够理解并生成轨迹,本文将 编码为离散token或连续嵌入。在离散表示中,将控制序列 中每个连续值在预设范围内均匀量化为等间隔区间,将得到的索引表示为专用token。在连续表示中,通过正弦位置编码将 映射到AR1的嵌入空间,随后通过MLP投影进一步处理。具体而言,本文采用受 -KI启发的策略:将VLM中学习的离散轨迹token,与通过流匹配框架将同一轨迹解码为连续表示的动作专家相结合。该框架不仅简化了VLM训练,加速了轨迹解码,还提升了闭环性能。
小结
本节详细阐述了将VLMs系统适配为自动驾驶策略VLA的两个核心设计维度(视觉编码与动作解码)。在后续章节中,本文将详细介绍数据流程构建与训练策略设计——这两部分共同赋予模型更强的推理与对齐能力,从而提升其在长尾事件中的稳健性。
三、因果链数据集:学习基于因果推理的VLA
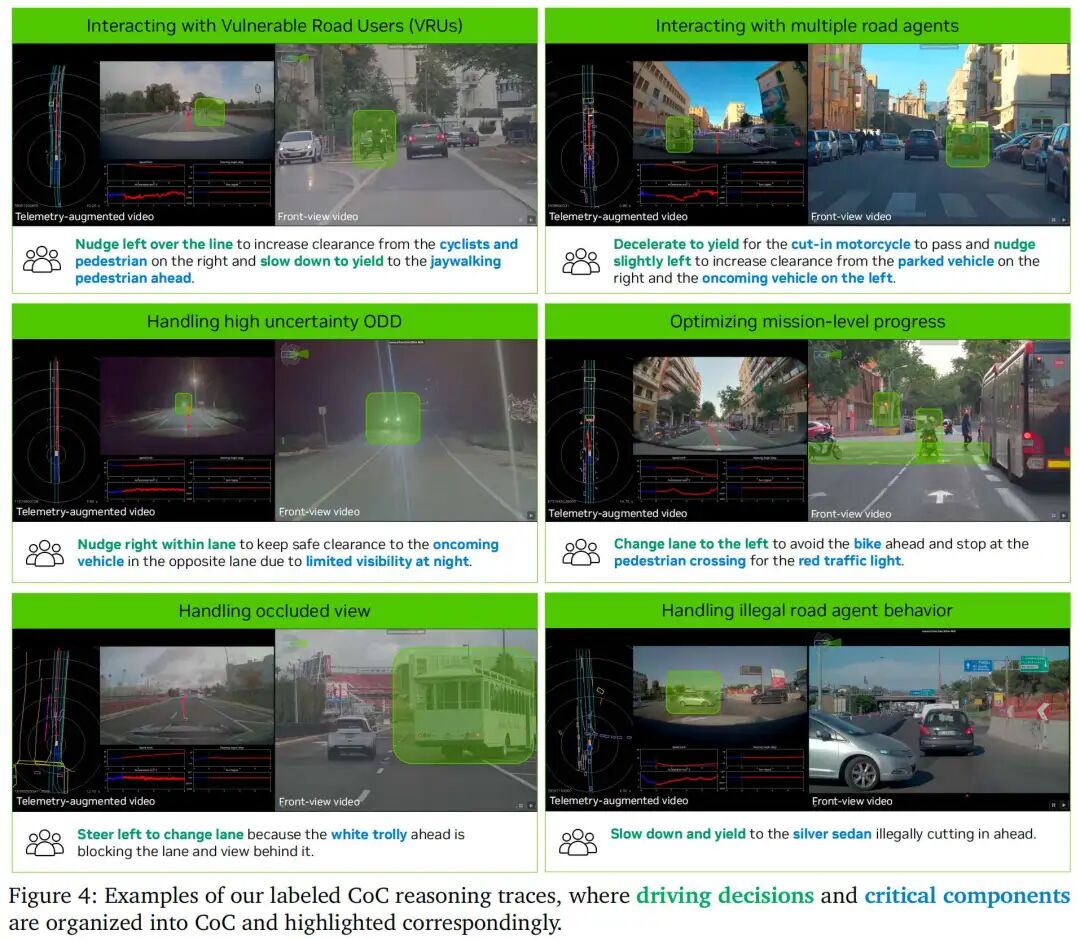
要使推理型VLA模型能够解释驾驶动作的原因并提升轨迹级性能,推理数据需与自车轨迹紧密关联。然而,自动驾驶领域现有的思维链(CoT)推理数据集普遍存在若干局限(如图2所示):
(1)行为描述模糊:自由形式的CoT标注可能无法明确指定具体驾驶动作,或选用与自车轨迹关联性较弱的表述;
(2)推理流于表面:部分推理轨迹仅描述场景观测或假设性因素,与自车行为缺乏直接因果关联,对提升训练后驾驶性能的帮助有限;
(3)因果混淆:推理轨迹可能包含未来时间窗口中的因果因素,而这些因素在模型训练时并不可观测。这一问题源于标注过程常暴露完整视频,未区分历史与未来片段。

为解决上述问题,本文提出一种标注框架,可在推理轨迹中强制加入显式因果结构。首先,本文定义了一套全面的高阶驾驶决策集合,这些决策与低阶自车轨迹直接对应;每个推理轨迹均关联一个显式驾驶决策,并仅包含驱动该决策的因果因素。通过精心选择关键帧以分割视频的历史与未来片段,确保所有因果因素均来自可观测的历史窗口,从而避免因果混淆。该设计确保每个推理轨迹均以决策为核心且具备因果关联,捕捉简洁可解释的因果关系,而非冗长的描述性叙述。由此构建的数据集称为“因果链(Chain of Causation, CoC)数据集”,可为学习决策因果性提供清晰监督,使推理型VLA在车载推理时能高效推理特定驾驶动作的原因。图3展示了该标注流程的整体框架。
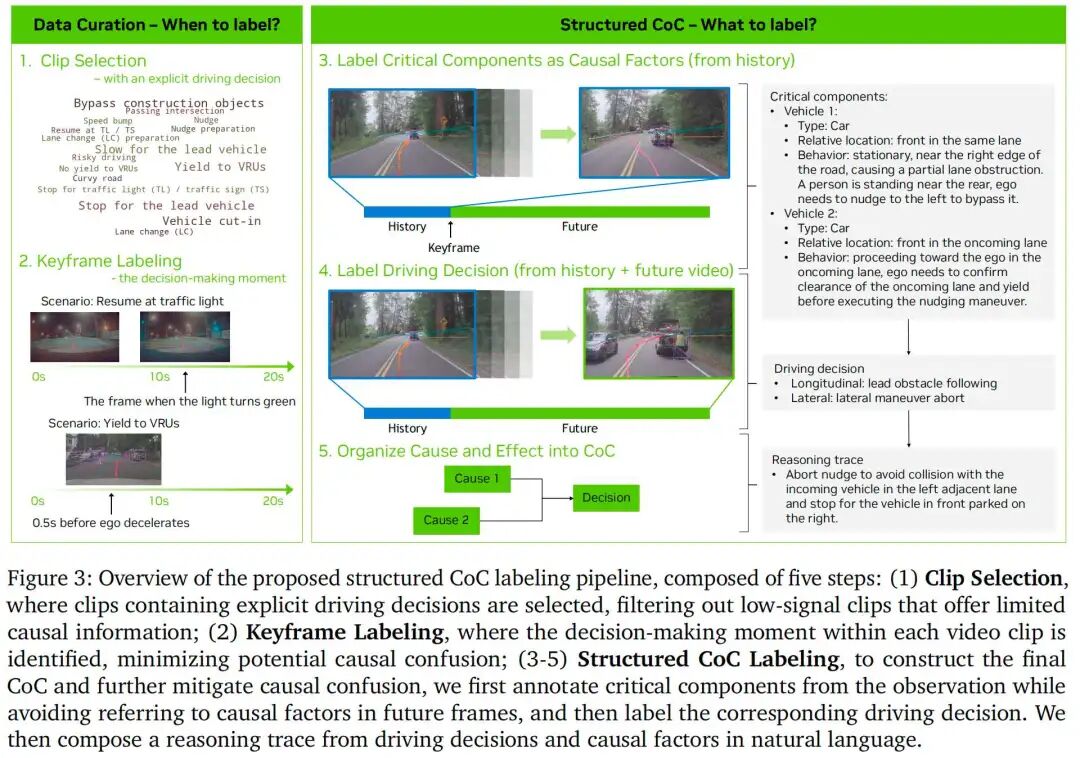
结构化因果链
为提高标注效率,本文提出的标注框架将每个数据样本分解为三个结构化组件:驾驶决策、因果因素(关键组件)与组合CoC轨迹。因此,每个数据实例均构成包含这三个组件的结构化CoC样本。
驾驶决策:
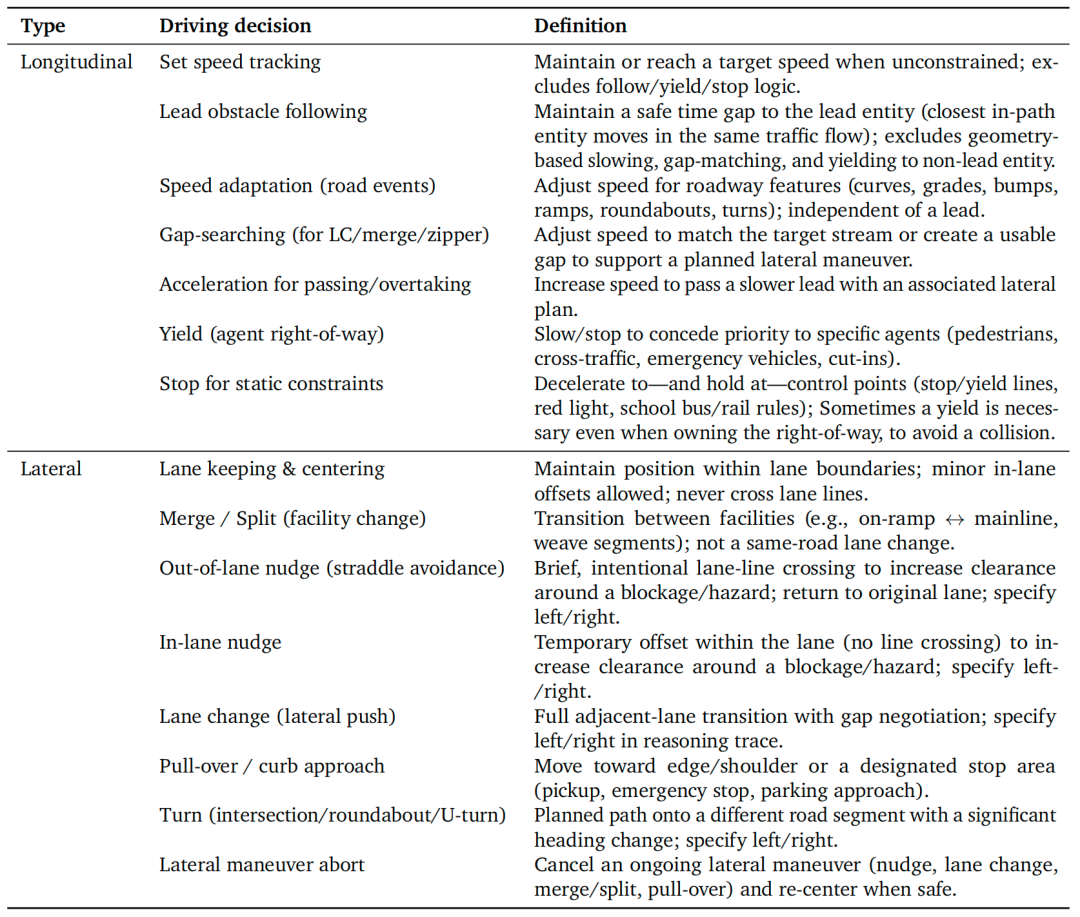
为确保CoC数据以决策为核心,本文定义了一套封闭的高阶驾驶决策集合(如表1所示)。每个视频片段最多标注一个纵向决策与一个横向决策(或某一维度为“无”),对应关键推理时刻后自车执行的首个动作。这套标准化决策集合与低阶轨迹直接对齐,消除了对驾驶行为的自由形式模糊描述,确保每个推理轨迹均能明确指定所执行的决策。为保证语言一致性与多样性,最终CoC推理轨迹采用与这些驾驶决策对齐的简洁动词集合构建。
表1 用于将推理轨迹锚定到显式控制意图的封闭集驾驶决策(纵向与横向)
关键组件:
与闭集驾驶决策不同,因果因素定义为开放集,其类别与示例属性如表2所示。这种设计允许人工标注者或自动标注流程灵活指定仅影响驾驶决策的关键元素,同时保持输出结构化。
表2 可能作为驾驶决策因果因素的关键组件类别与示例属性

组合CoC轨迹:
确定驾驶决策与关键组件后,需将其以自然语言组织为连贯的CoC推理轨迹,捕捉所选决策背后的因果逻辑。由此,结构化CoC协议可确保:
(1)决策锚定:每个推理轨迹均锚定于关键时刻的单一显式决策;
(2)因果局部性:所有证据均来自观测历史窗口;
(3)标注经济性:仅包含与决策相关的因素。
数据筛选
在定义了CoC的结构化组件(驾驶决策、关键组件、组合CoC轨迹)后,下一步需确定何时对这些推理数据进行标注。并非所有视频片段都需标注,仅在可明确建立观测因素与自车后续决策间因果关联的时刻触发标注。因此,本文数据标注框架的核心环节是数据筛选——即识别这些关键推理时刻。
片段选择:
本文选择包含显式驾驶决策的片段用于CoC数据集标注,避免选择因果信息有限的低信号片段。这些片段分为两类场景:
(1)反应型场景:自车需针对特定事件立即调整行为,例如为前方车辆或红灯停车、调整横向位置以与附近障碍物/危险保持间距;
(2)主动型场景:自车无需立即反应,但需主动评估并预判潜在操作调整需求(因前方道路事件或障碍物)。例如,自车收到变道导航指令,但目标车道无足够空间,需持续寻隙与评估空间以准备变道操作。
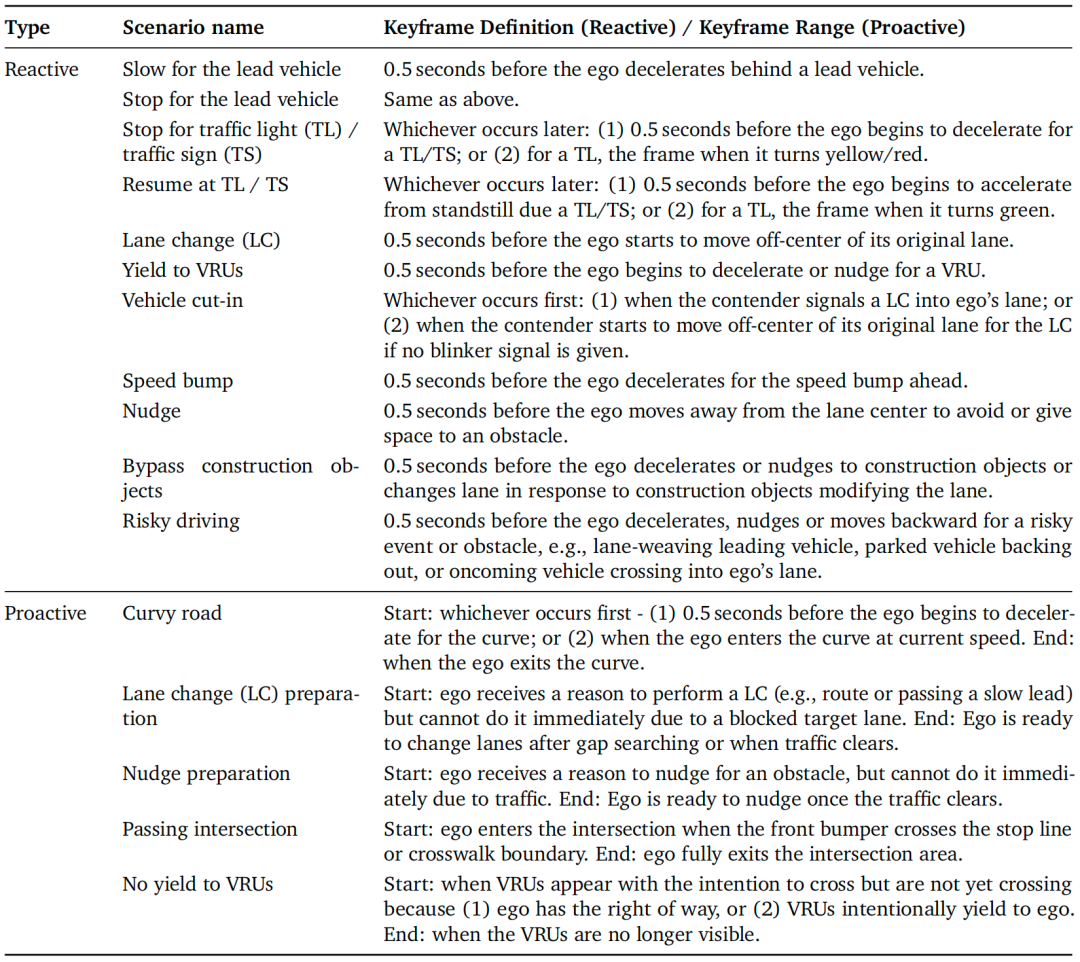
本文采用基于规则的方法识别各类场景对应的片段,并平衡各类场景的片段数量以确保数据集多样性。表3提供了场景的详细定义。
关键帧标注:
每个原始片段包含20秒数据,在训练与评估均采用“2秒历史预测6秒未来”的配置下,可生成多个训练样本。因此,为CoC标注选择关键帧对最大化决策因果清晰度至关重要。
对于反应型场景,关键帧通常选择在自车启动与驾驶决策对应的行为变化前约0.5秒(短时间缓冲)。在该关键帧处,自车已在之前2秒历史窗口中积累了足够观测证据,可支撑即将执行的动作,有效避免因果混淆。由于关键帧位于决策时刻直前,可确保每个数据样本均关联具体驾驶决策,从而实现以决策为核心的CoC轨迹标注。
对于主动型场景,本文标注关键帧区间——即自车主动评估或准备潜在操作调整的时间窗口。表3提供了反应型与主动型场景的关键帧或关键帧区间的详细定义。仅对关键帧时间戳或关键帧区间内采样的关键帧样本标注CoC推理轨迹。
表3 CoC标注所用的片段选择场景及关键帧/关键帧区间定义
混合标注流程
为同时确保标注质量与规模,本文提出融合人工标注与自动标注的混合标注流程。尽管自动标注足以生成大规模推理型VLA训练数据,但约占总量10%的高质量人工验证数据对进一步有监督微调、自动标注评估与模型评估至关重要。该混合标注方法可平衡效率与准确性,同时支持大规模训练与可靠模型评估。
人工标注
两阶段标注流程:
根据前文所述的结构化CoC定义,人工标注者需完成两阶段流程,以生成简洁且因果锚定的CoC文本:
第一阶段(0-2秒):在观测历史窗口(关键帧前2秒内)从表2中识别关键组件。此步骤可确保仅考虑决策时刻前可获取的证据,避免因果混淆;这些关键组件可能影响下一阶段标注的驾驶决策。
第二阶段(0-8秒):(a)应用安全排除过滤器,移除包含非法或不安全驾驶行为的无效数据;(b)为每个维度(纵向/横向)选择关键帧后的首个驾驶决策(或“无”);(c)撰写CoC推理轨迹,仅参考第一阶段识别的、导致该驾驶决策的因果因素,并在适用时包含导航或规则信号。
为明确区分第一阶段与第二阶段、最大限度减少因果泄露,本文设计了一款标注工具,可显式区分历史视频片段(0-2秒)与未来片段(2-8秒)。该工具还提供可视化辅助功能,包括自车动力学图表(速度、加速度、转向角、转向灯)、叠加车道拓扑的鸟瞰图可视化,以及障碍物边界框,帮助标注者更准确地理解驾驶场景。
质量保证(QA):
为最大化标注质量并减少潜在偏差,本文实施了严格的QA流程。每个标注实例首先由另一名标注者进行质量检查;此外,根据标注者表现,随机抽取10%-20%的标注实例,由专业审核团队进行额外审核。质量检查与审核流程均遵循相同QA指南,核心规则总结于表4。该QA流程确保CoC的核心要求(决策锚定、因果局部性、标注经济性)得到严格执行,同时保留自然语言表达的灵活性。最终,本文在各类驾驶场景中生成了高质量CoC推理轨迹,代表性示例如图4所示。
表4 质量检查与审核流程的质量保证(QA)清单

自动标注
自动标注的关键帧选择:
为高效扩展训练数据并提升模型泛化能力,本文开发了CoC标注的自动标注流程。为识别自动标注的关键帧,首先定义一套低阶元动作,并实现相应的基于规则的检测器,以在帧级别推断这些元动作;随后,将元动作发生转换的帧视为决策时刻,从而在大规模数据中自动高效地确定关键帧。
元动作:
表5列出了完整的元动作集合。这些低阶元动作具有原子性,代表自车轨迹的瞬时运动学变化,因此与高阶驾驶决策存在显著差异。视频片段中的一个高阶驾驶决策通常由纵向与横向两个维度的一系列原子元动作构成。例如,“左变道”决策可能包含“左转向”、短暂“右转向”(以稳定车头方向)、随后“直行”的序列,通常还伴随轻微“加速”与“维持速度”。对于每个8秒数据样本,本文最多标注一个纵向与一个横向高阶驾驶决策,而原子元动作则以10Hz的频率自动标注。
表5 纵向与横向原子元动作列表

标注流程:
随后,本文采用GPT-5(OpenAI, 2025)等最先进VLM,通过多步推理流程执行离线自动标注。该方法可将大型模型的世界知识提炼为结构化CoC标注,同时平衡效率与成本。与人工标注流程类似,VLM生成的结构化推理轨迹包含识别的驾驶决策、关键组件,以及将驾驶决策与其因果因素关联的简洁推理轨迹。
为支持推理过程,自动标注流程向模型提供原始视频与辅助信号(包括自车轨迹、动态状态与元动作)。视频以2Hz采样,在平衡信息密度的同时,确保不超出自动标注模型上下文窗口的token预算。
为缓解因果混淆,通过提示引导VLM在识别关键组件时仅使用2秒历史视频;随后利用6秒未来视频、自车轨迹与元动作解决多模态歧义,并确定相应驾驶决策。在此过程中,模型会对识别的因果因素进行重要性排序,仅保留直接影响驾驶决策的因素纳入最终推理轨迹。
评估
对开放式文本(尤其是推理轨迹)的评估仍是自动驾驶研究领域的开放挑战,而评估CoC中的因果关系则进一步增加了复杂性。现有数据集通常采用以下评估方法之一:
(1)对小样本子集进行人工评估:在标注者指导充分时有效,但无法扩展到大规模评估或标注流程的快速迭代;
(2)基于启发式的指标(如BLEU、METEOR、CIDEr):仅捕捉表层文本相似性,无法反映底层因果推理,因此不适用于评估本文CoC数据集;
(3)基于LLM的自动评估:利用LLM对因果关系的推理能力,可扩展到大规模评估集,但LLM在评估复杂多步因果链时易产生幻觉。
由于这些挑战,现有研究往往缺乏可靠的推理数据集评估方法。
CoC评估流程:
为应对上述挑战,本文采用融合人工验证与LLM自动评估的混合评估策略。具体而言,选用GPT-5作为LLM评估器,并构建包含2000个样本的精选评估集,覆盖表3列出的代表性场景。为减少LLM评估中的幻觉,避免直接使用自由形式文本与评分结果,而是将评估过程分解为三个结构化子任务,分别覆盖驾驶决策、因果因素存在性与因果关系有效性。通过将这些评估维度重构为一系列“真/假”问题,使评估过程更具可解释性,且与人工判断更一致。
为验证可靠性,将基于LLM的自动评估与人工评估在同一版自动标注数据集上进行对比,发现两者对齐率达92%,证实了本文LLM自动评估方法的稳健性。通过该评估方法,本文发现所提出的结构化CoC推理轨迹相较于不强制显式驾驶决策与关键组件的自由形式推理轨迹,因果关系得分相对提升132.8%。
不完美自动标注的有效性:
需注意的是,即使可能,在因果效应评估中获得完美(100%)分数也并非自动标注数据有用性的必要条件。由于复杂驾驶场景中因果推理固有的模糊性,以及人工标注真值与评估指标中的噪声,100%一致性是否为合理或明确定义的目标尚不明确。相反,CoC自动标注的主要价值在于支持大规模有监督微调,以提升AR1在各类驾驶场景中的泛化能力。
实证结果(如第6节所示)表明,在自动标注CoC轨迹上训练的模型已比无推理监督的基准模型实现显著性能提升。此外,如第5节所述,本文训练流程还包含后续基于强化学习的后训练步骤,可进一步增强推理能力与因果一致性。同时,随着人工标注规模扩大,本文计划引入更多轮基于人工标注CoC推理轨迹的有监督微调,逐步提升因果锚定能力与可解释性。
四、训练策略
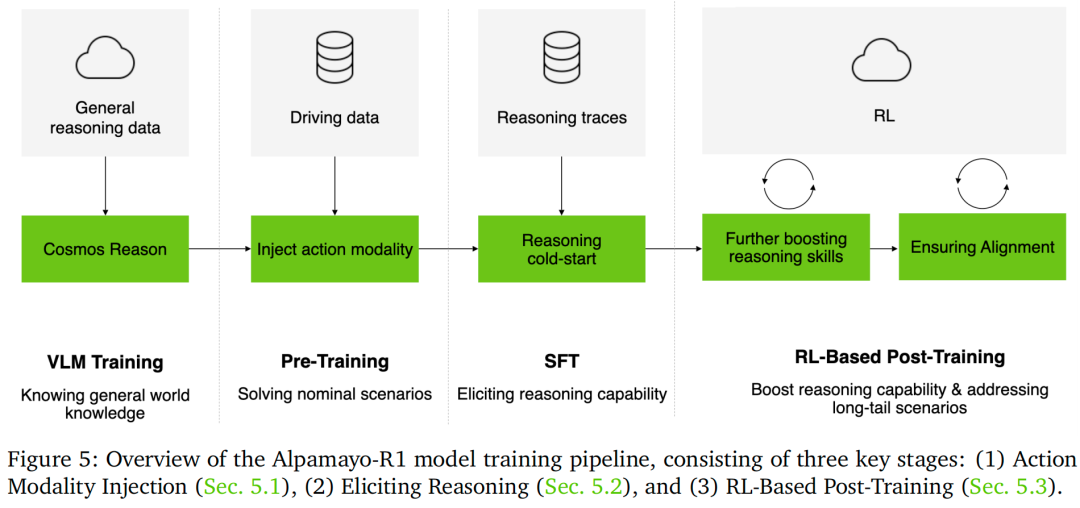
本文以Cosmos-Reason视觉-语言模型(VLM)为主干网络——该网络通过领域特定有监督微调(SFT)已具备基础物理推理能力,在此基础上,我们设计了三阶段训练策略,将其转化为具备推理能力的自动驾驶策略模型。如图5所示,每个阶段逐步增强模型在稳健且可解释驾驶中必需的核心能力:离散轨迹token训练并添加基于流匹配的动作专家,向VLM注入动作模态,使模型能够预测车辆控制输出;因果链(CoC)数据集进行有监督微调,教会模型生成因果锚定的解释,以优化驾驶决策;最后采用结合大型推理模型反馈的强化学习(RL),优化推理质量、使推理轨迹与执行动作对齐,并提升轨迹质量,最终实现可解释且安全的驾驶行为。
动作模态注入
训练阶段,我们通过离散token向VLM注入动作模态,并基于式(1)定义的训练token序列,通过交叉熵损失对VLM进行训练。根据式(3)中的控制型表示,每条轨迹包含64个路径点,每个路径点对应2个量化值(加速度 与曲率 ),因此每条轨迹对应128个离散token。这些token通过一组专用于动作表示的特殊token进行编码。但需注意,推理阶段我们不使用离散轨迹token,具体原因如下。
双表示的设计动机:
训练阶段采用离散token与推理阶段采用连续流匹配解码器的双表示方式,具备以下核心优势:
离散token化支持统一自回归训练:推理与轨迹共享同一token空间,使VLM能通过标准的下一个token预测任务,将因果解释与车辆行为紧密关联;
离散表示便于强化学习优化:后训练阶段(见5.3节)可实现直接梯度传递,使GRPO(Shao et al., 2024)等策略梯度方法能联合优化推理质量与推理-动作一致性;
离散表示为学习车辆动力学提供强监督,而流匹配专家则确保输出满足物理可行性与多模态特性;
流匹配解码具备计算效率优势:生成连续轨迹的速度远快于自回归采样128个离散token,可满足实时推理需求。
与 -KI(Driess et al., 2025)类似,我们采用独立的动作专家,通过流匹配实现动作解码。该动作专家与VLM采用相同的Transformer架构,注意力头数与注意力维度一致,但隐藏层嵌入维度与MLP维度更小,以提升效率。
在扩散调度的每个时间步 ,动作专家的输入包含两部分:VLM中序列 生成的KV缓存,以及带噪声控制信号 的嵌入表示(扩散时间 也会被嵌入并添加到特征中)。随后,专家通过MLP头对最终层特征进行投影,预测向量场 ,其中 表示可学习参数。我们采用标准条件流匹配损失训练动作专家:
实际训练中,我们采用高斯条件最优传输(OT)路径,采样 (其中 ),此时目标向量场存在闭式解:
推理阶段,从 开始,通过欧拉积分实现去噪:
默认设置下,推理阶段 ,训练阶段扩散调度 采用Physical Intelligence et al. (2025)提出的偏移Beta分布。此外,训练时我们对VLM生成的KV缓存施加梯度停止(stop-gradient)操作,避免专家的梯度反向传播至VLM权重。
激发推理能力
前文已构建具备动作生成能力的视觉-语言-动作(VLA)模型,接下来需解决的核心挑战是:使模型能够执行结构化、因果锚定的推理,以解释为何选择特定驾驶决策。在模仿学习仅依赖模式匹配可能失效的复杂安全关键场景中,这种推理能力至关重要。
为实现这一目标,我们利用前文提出的结构化CoC数据集——该数据集包含与专家轨迹配对的、以决策为核心且具备因果关联的推理轨迹。我们在CoC数据集上进行有监督微调,通过模仿学习教会模型生成推理轨迹,且每个推理轨迹均锚定于显式驾驶决策(表1)并基于场景关键组件(表2)。尽管有监督微调能使模型掌握基础推理能力,但我们将通过强化学习进一步优化推理质量,并确保推理-动作一致性。
形式上,每个训练样本包含:多摄像头驾驶场景观测 、解释自车决策因果因素的结构化CoC推理轨迹 ,以及式(3)定义的真值控制型轨迹表示 。根据式(1)的序列定义,有监督微调的目标是最大化推理-动作序列的条件对数似然:
其中 表示由 参数化的VLA策略,包含视觉编码器、语言主干网络及相应的嵌入适配器。实际训练中,我们对推理token与离散轨迹token(前文提到的每条轨迹128个token)均施加交叉熵损失,使模型能在统一自回归框架中学习基于语言的推理与动作预测的联合分布。
仅依赖有监督微调的局限性:
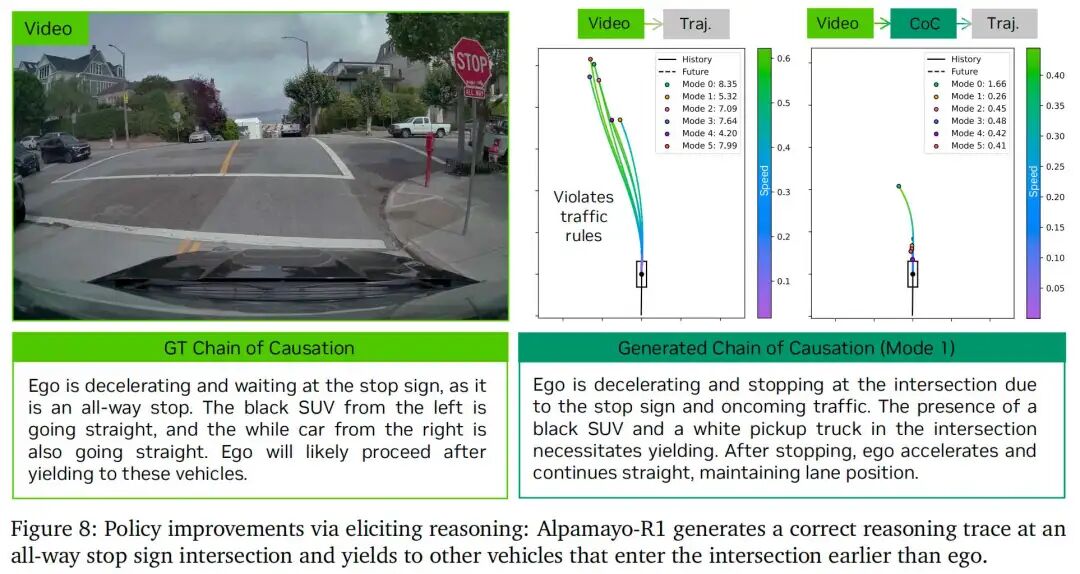
这一模仿学习阶段使模型能内化类人推理模式:不仅学习“执行何种动作”,还能理解“为何在特定视觉与场景线索下该动作适用”。如图8所示,在CoC数据上进行有监督微调的模型,其轨迹预测准确率已显著优于无显式推理监督的模型。然而,尽管有监督微调能让VLA模型生成推理轨迹,其性能仍受以下因素局限:
数据偏差与标注噪声:自动标注数据可能包含不完美的因果关系,导致模型过拟合于标注伪特征,而非学习稳健的因果推理;
泛化能力有限:模型可能仅记忆常见推理模式,缺乏深层因果理解,无法泛化到新颖场景;
视觉锚定薄弱:下一个token预测无法确保视觉一致性,模型可能虚构场景中不存在的因果因素(图10);
推理-动作不一致:联合优化未显式确保推理表述与预测轨迹的对齐,可能导致解释与行为矛盾(图11)。


基于强化学习的后训练
为解决有监督微调局限性,我们提出如图6所示的基于强化学习的后训练框架,优化三个互补奖励信号:推理质量(通过大型推理模型反馈)、推理-动作一致性,以及轨迹质量。与有监督微调不同——后者在教师强制(teacher forcing)下优化专家演示的似然,未考虑推理时的误差反馈——强化学习能对模型自身采样的轨迹提供显式推理反馈,使优化目标与系统实际部署方式对齐。该方法通过针对性反馈评估推理的因果正确性及其与执行动作的对齐性,在相同计算预算下显著提升模型稳健性与泛化能力。

后训练算法
大规模基础模型后训练已成为提升模型推理能力与生成质量的核心策略。近年来,这类技术已扩展到具身智能领域,促使VLA模型生成更符合人类意图的动作,适用于自动驾驶(Tian and Goel, 2025)与通用机器人智能体等场景。在推理型VLA场景中,对齐阶段不仅需优化动作生成,还需显式提升具身场景下的推理质量,并确保推理-动作一致性——这两者都是实现可解释、可信自动驾驶的关键属性。
我们采用GRPO(Group Relative Policy Optimization) 作为对齐算法。GRPO对标准策略梯度方法进行扩展,通过在一组采样模型轨迹中优化相对优势,而非依赖绝对奖励信号。具体而言,给定从当前模型 采样的一组轨迹 (每个轨迹对应一个标量奖励 ),GRPO的目标函数定义为:
其中 表示每条轨迹在组内的相对优势( 为组平均奖励), 控制权重分布的尖锐度。含系数 的KL正则化项惩罚模型偏离参考策略 (通常为有监督微调模型)的程度,避免模型对噪声或有偏奖励信号过度优化,并保留预训练阶段学习的语言与行为先验。
奖励模型
我们的奖励模型整合三个互补信号,共同评估模型的“推理内容”与“动作表现”。具体而言,每条轨迹的总奖励 由以下三部分组成:推理质量奖励、推理-动作一致性奖励,以及低阶轨迹质量奖励。
利用大型推理模型评估推理质量:
为避免推理轨迹出现“看似合理但不安全或因果不一致”的虚构内容(幻觉),我们采用大型推理模型(LRMs) 作为自动评估器,为推理质量提供可扩展的高质量反馈。受LLM对齐领域最新进展的启发——专家模型可作为评判者提供可扩展反馈——我们选用最先进的大型推理模型(如DeepSeek-R1、Cosmos-Reason作为推理评估器,对VLA生成的推理轨迹质量进行评分。选择大型推理模型作为评估器的原因在于:尽管这类模型可能因缺乏具身先验而难以生成驾驶专属推理,但它们在验证与评估方面能力极强——即便是在该领域生成能力有限,其评估逻辑合理性、因果对齐性与场景一致性的能力仍高度可靠(这一现象被称为“生成-验证差距”)。最终得到的奖励信号为推理质量提供连续度量,使强化学习能迭代优化模型生成锚定且逻辑一致推理的能力。
推理评估器设计:
对于每个训练样本,大型推理模型评估器的输入包括:2秒历史窗口最后一帧的多摄像头视觉观测 、数据集中的真值CoC推理轨迹 ,以及当前策略 生成的推理轨迹 。评估器从两个维度评估 与 的对齐程度:
行为一致性:预测推理描述的驾驶决策是否与真值一致;
因果推理质量:预测推理是否依据CoC原则,正确识别场景历史中可观测的因果因素。
评估器根据聚焦“行为一致性”与“因果推理一致性”的结构化评分标准,对预测推理进行评分,具体提示与评分规则如下:
提示:LLM推理评分规则
你是自动驾驶推理轨迹的专家评估者。推理轨迹需描述自车应执行的行为,以及导致该行为的原因与因素。你的任务是从“行为一致性”与“因果推理”两个维度,评分预测推理轨迹(PRED)与真值推理轨迹(GT)的对齐程度。评分范围为0-5分,具体规则如下:
5分:行为与因果推理完全一致;
4分:行为正确,因果推理基本一致;
3分:行为大致正确,但推理不完整或存在轻微错误;
2分:行为部分错误,或推理严重不一致;
1分:行为错误,或与真值矛盾;
0分:与真值完全无关或相反。
最终得到的标量分数 作为推理奖励。该信号促使模型生成的推理轨迹不仅能描述正确驾驶行为,还能保持因果真实性——基于视觉场景与交通线索,准确解释“为何执行该动作”。
CoC-动作一致性奖励:
为确保模型动作生成忠实遵循其推理表述,我们引入CoC-动作一致性奖励,度量生成推理轨迹与对应自车预测轨迹的行为对齐程度。具体而言,对于每条推理-动作轨迹,我们先将预测运动轨迹转换为元动作序列(可解释的运动基元)——这些元动作编码自车在纵向(加速/制动)与横向(转向)两个维度的控制行为;随后,解析生成的推理轨迹以推断自车的意图行为,并通过基于规则的匹配,将其与从预测轨迹中提取的元动作进行对比。若推理轨迹中描述的行为与元动作在两个维度均一致,则赋值 ;否则赋值 。若推理轨迹无法解析为有效驾驶决策(即无法在自动标注所用的封闭决策集中识别意图),则保守赋值 。
尽管基于简单规则逻辑,该二元奖励对提升模型推理-动作关联的可信度至关重要:通过显式惩罚不一致性、仅奖励正确匹配,促使模型生成的推理不仅“表述合理”,还能转化为连贯、物理一致的行为。
低阶轨迹质量奖励:
为确保生成的运动轨迹具备物理可行性、舒适性与执行安全性,我们引入低阶轨迹质量奖励,在连续空间中评估模型的运动输出。该组件补充上述推理级与一致性级奖励,直接对轨迹的物理属性进行正则化。奖励由三部分组成:
其中:
与 分别表示预测轨迹与专家轨迹;
为二元指示器,若预测运动导致与周围障碍物碰撞则为1,否则为0;
表示加加速度(jerk)大小,用于惩罚突发或不舒适的运动;
、 、 为各奖励项的权重系数。
L2模仿项促使轨迹接近专家演示,提升学习稳定性与驾驶平滑性;碰撞惩罚确保安全性;加加速度正则化提升舒适性与控制平滑度。三者共同作用,使模型学习类人、安全且舒适的运动,增强对齐阶段生成轨迹的物理合理性。
面向成本高效训练的后训练数据筛选
基于强化学习的后训练计算成本高昂,原因在于其迭代特性:每次策略更新需对大量推理与轨迹样本进行多次模型采样、奖励评估与梯度更新。此外,与有监督微调直接基于标注数据计算损失不同,后训练涉及在线策略采样与基于大型推理模型的奖励计算,进一步增加计算与数据成本。因此,若将强化学习扩展到完整预训练数据,将面临训练时间与计算资源的双重瓶颈。
为解决这一问题,我们为强化学习后训练筛选高信息增益数据集。核心思路是:优先选择模型隐含奖励信号(由logits编码)与显式奖励模型存在分歧的样本。具体而言,对于模型采样的每条轨迹 ,我们计算两部分概率分布:
由模型logits推导的预测概率分布;
由奖励转换得到的玻尔兹曼分布 ( 为温度参数)。
若两分布差异较大,表明模型的内在偏好(隐含奖励)与外部定义的奖励信号存在冲突。这类样本揭示模型所学奖励的不准确之处,对对齐训练极具价值。因此,我们优先选择这些高分歧样本构建后训练数据集,同时混入一定比例的随机采样数据,以保持分布多样性并稳定训练。通过在该混合数据集上聚焦强化学习更新,我们实现了高对齐效率与稳健学习动态,性能优于基于均匀采样数据的训练。
后训练基础设施
为开展强化学习实验,我们基于Cosmos-RL框架开发了定制版本,专门适配自动驾驶推理任务。该系统为大规模多模态强化学习提供可扩展、模块化的基础设施,与Alpamayo-R1系统的其他组件无缝兼容。其支持分布式数据加载、混合并行训练、基于vLLM的轨迹生成,以及跨多GPU节点的奖励计算,可实现高效、高吞吐量的策略优化。
实验结果
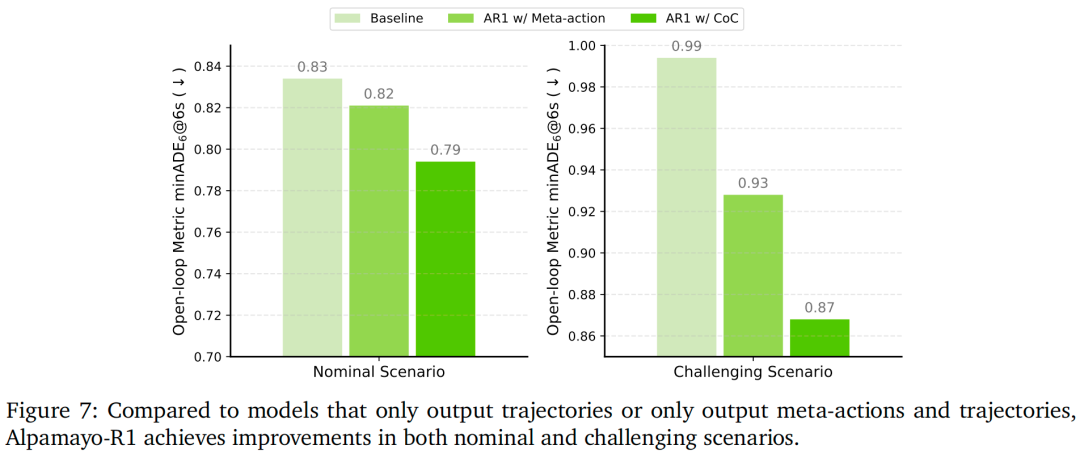
我们从多个维度对Alpamayo-R1(AR1)进行全面评估,包括推理能力、轨迹预测准确率与闭环驾驶性能。首先,图7显示:与仅输出轨迹的基准模型相比,本文提出的Alpamayo-R1在高难度场景(需复杂推理以优化驾驶决策)中表现显著更优。
评估协议
我们的评估策略包含四个互补组件:
开环轨迹预测:在常规与长尾驾驶场景中评估规划准确率;
闭环仿真:利用AlpaSim评估模型在真实场景中控制车辆时的安全性与稳健性;
消融实验:分析关键架构选择的影响,包括视觉-语言模型缩放、视觉编码策略、推理集成与动作解码策略;
实车道路测试:验证模型在自动驾驶场景中的真实世界部署能力。
数据集:
模型训练与评估基于在美国与欧盟多个地理区域收集的内部驾驶数据,所有评估数据均严格进行地理围栏(geo-fenced),且与训练区域完全隔离,避免信息泄露。评估覆盖数据集 中的常规驾驶场景,以及 中的高难度长尾场景,以全面测试模型处理罕见安全关键事件的能力。
具体而言,完整训练与评估数据集包含8万小时驾驶数据,由多辆自车在25个国家的1700多个城市采集,涵盖高速公路、城市道路等多种场景,以及不同天气、时段与交通密度条件。原始传感器输入包括7摄像头环视系统的视频记录,辅以精确的摄像头标定参数与自车运动数据。本文重点使用两个前视摄像头输入:水平视场角120°的前视广角摄像头,与水平视场角30°的前视长焦摄像头,分别用于近场与远场场景理解,形成互补视角。
除通用驾驶数据集 外,我们还构建了第4章所述的CoC数据集,包含70万个带结构化因果链标注的视频片段。该数据集用于微调模型以激发推理能力,以及基于强化学习的后训练对齐。
开环评估:
开环轨迹预测评估的预测时域为6秒(对应自车规划路径点),采用minADE(最小平均位移误差)与ADE(平均位移误差)作为评估指标:
minADE:对6个预测轨迹样本计算,定义为真值未来轨迹与模型生成的6个预测轨迹中“最佳匹配轨迹”的最小距离;
ADE:定义为预测轨迹与真值轨迹在所有未来时间步的平均距离。
闭环评估:
已有研究表明,优异的开环结果并不一定转化为可靠的闭环驾驶性能。为填补这一差距,我们在AlpaSim 中进一步评估模型——这是一款基于最先进神经重建技术的开源端到端闭环模拟器。AlpaSim利用真实驾驶日志构建时序3D高斯溅射表示,在闭环评估中,当自车偏离记录轨迹时,可通过该表示合成新视角。评估过程中,预测轨迹由模型预测控制器(MPC)跟踪,车辆动力学遵循动态扩展自行车模型;交通智能体(车辆、行人)则遵循其记录轨迹行驶。
我们在75个高难度20秒场景中评估模型,这些场景的选择标准是“自车-智能体”与“智能体-智能体”交互密集。尽管场景数量看似有限,但它们均为精心筛选的“需复杂推理与交互决策”的安全关键场景。我们报告以下AlpaSim指标:
偏离车道率:自车驶出可行驶区域的场景占比;
近距离碰撞率:自车与其他交通智能体发生近距离碰撞的场景占比;
AlpaSim评分:事件(偏离车道或近距离碰撞)之间的平均行驶距离(单位:km);
责任方AlpaSim评分:与AlpaSim评分定义相同,但仅统计自车为责任方的近距离碰撞(排除追尾类近距离碰撞)。
仿真在首次发生近距离碰撞或偏离车道事件时终止。为减少渲染伪影,自车与原始记录轨迹偏差超过4米的事件,均不纳入任何指标计算。
推理对驾驶策略的优化作用
本文的核心贡献之一是利用提出的CoC数据优化驾驶策略。为评估推理对驾驶性能的影响,我们以在 上预训练且注入动作模态的模型(5.1节)为基础,在CoC数据集上通过不同推理模态进行微调:元动作描述、完整因果链推理轨迹。推理阶段,基于CoC推理训练的模型在输出轨迹预测的同时,还会生成显式推理内容,使其能更好地处理需多步决策的高难度场景。我们对比三种微调策略:(1)仅轨迹预测;(2)元动作+轨迹预测;(3)因果链推理+轨迹预测(即Alpamayo-R1)。所有模型均在CoC预留测试集上评估,分为“提供路线信息”与“不提供路线信息”两种设置。
开环性能提升:
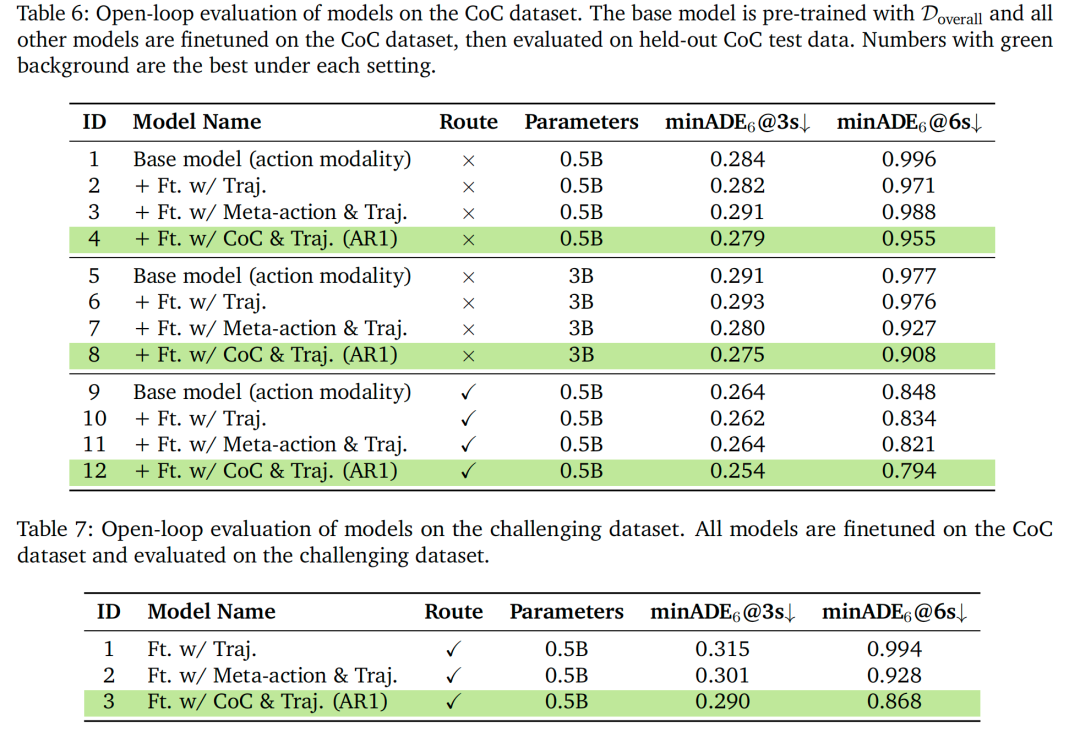
如表6(常规场景)与表7(高难度场景)所示,集成CoC推理在两种设置下均显著提升开环轨迹预测性能:
无路线信息时:AR1在6秒时域的minADE为0.955米,较基础模型提升4.1%,且优于仅轨迹预测(0.971米)与元动作(0.988米)基准;
有路线信息时:性能提升更显著——AR1的minADE达0.794米,较仅轨迹预测基准(0.834米)提升4.8%;
模型缩放增益:将参数扩展至3B时,性能进一步提升,AR1-3B(无路线信息)的minADE达0.908米,证明模型容量对复杂推理任务的重要性;
高难度场景优势:在高难度场景中,AR1的性能提升更为突出——minADE达0.868米,较仅轨迹预测基准(0.994米)提升12%。
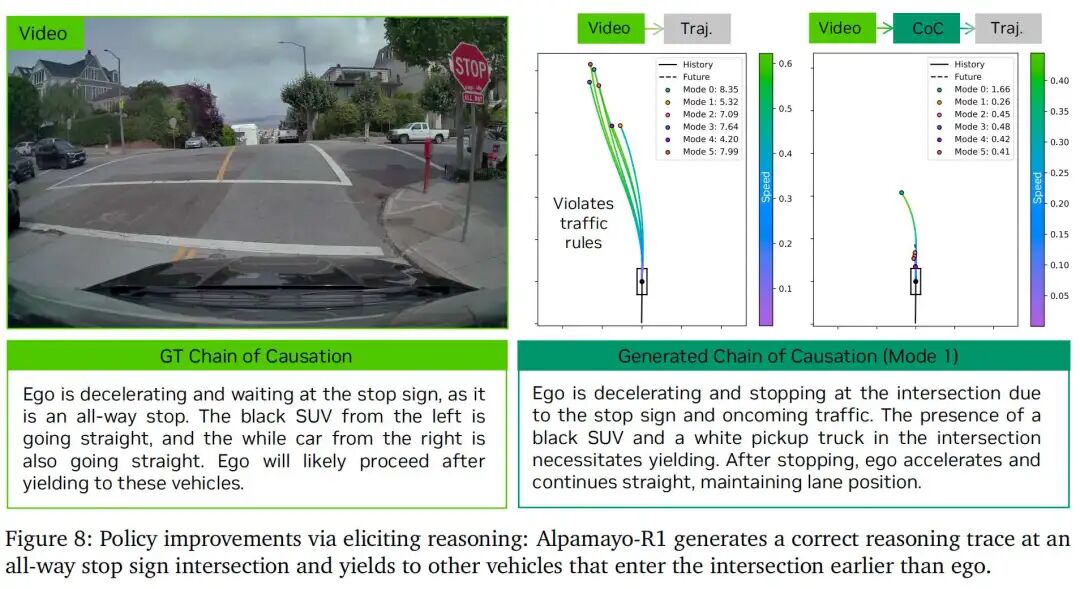
这些结果表明,显式推理能力使模型能更有效利用路线引导等场景信息,并更好地处理需预判未来交互的复杂驾驶场景。图8通过定性示例展示:基于CoC的模型能成功生成正确推理轨迹,并在高难度场景中为其他车辆让行,而基准模型则无法预判此类交互。
闭环性能提升:
如表8所示,AR1的闭环性能同样显著优于基准模型:与仅轨迹预测基准相比,AR1的偏离车道率降低35%(从17%降至11%),近距离碰撞率降低25%(从4%降至3%);整体AlpaSim评分从0.38提升至0.50,证明基于推理的决策能提升动态闭环场景中的安全性。图9展示两个定性示例,验证AR1在AlpaSim中高难度场景的闭环驾驶能力。

基于强化学习后训练的推理、一致性与安全性提升
尽管在CoC数据上进行有监督微调能使模型联合生成推理轨迹与动作,但无法保证推理具备因果锚定特性,也无法确保动作忠实遵循推理或符合人类驾驶规范。为解决这一问题,我们通过基于强化学习的后训练,同时提升推理质量、推理-动作一致性与轨迹质量。本节以在CoC数据上微调的0.5B AR1模型为基础,评估不同奖励组件对模型行为的影响。
利用大型推理模型反馈的价值:
为确保推理轨迹不仅流畅,还具备因果锚定与场景准确性,我们引入基于大型推理模型反馈的推理奖励。该奖励为每条生成推理轨迹的逻辑一致性与因果正确性提供连续评估信号。具体而言,在6个生成轨迹中,“最可能轨迹”的平均推理评分在应用推理奖励后提升约45%(从3.1分提升至4.5分)。
图10展示两个定性示例,对比后训练前后模型行为差异:
左图(施工场景):有监督微调预训练模型忽略施工障碍,将场景描述为常规驾驶情境,未识别到需规避动作;后训练模型的推理则正确关注施工区域,解释“自车应向右微调以避开障碍物”;
右图(行人场景):两名行人即将离开车道,有监督微调预训练模型忽略这一场景线索,未预判自车需准备加速;后训练模型则正确识别“行人已离开可行驶区域”,推理“自车可安全恢复行驶”。

强化推理-动作一致性的价值:
有趣的是,若后训练阶段仅优化推理奖励,虽能提升推理评分,但ADE指标与推理-动作一致性均会较基础模型下降。这表明:仅优化推理质量可能导致推理“脱离实际”或“过度自信”——模型生成流畅但因果脱节的解释,无法转化为连贯动作。因此,一致性奖励对将推理锚定到物理可行行为至关重要,可确保可解释性提升不以控制精度为代价。
具体而言,当联合优化推理奖励与一致性奖励时,后训练模型的性能表现为:
最可能轨迹的ADE降低9.4%(从2.12米降至1.92米);
推理评分提升45%(从3.1分升至4.5分);
推理-动作一致性提升37%(从0.62升至0.85)。
这些结果证明两种奖励组件的互补性:推理奖励提升可解释性与因果锚定,一致性奖励确保生成推理能转化为忠实且更准确的运动行为。图11通过两个定性示例展示后训练对运动精度的提升:当模型推理“在停车标志处减速、停车后加速”时,对齐模型能忠实执行这一因果序列(平滑减速、完全停车、确认路口安全后加速),而有监督微调预训练模型则倾向于“中途停车且无法恢复行驶”。
引入安全奖励的价值:
尽管推理奖励与一致性奖励能提升可解释性与因果锚定,但它们未显式约束模型生成安全运动轨迹。为确保物理安全性,我们在后训练中引入安全奖励,惩罚不安全或物理不可行的轨迹。实证结果表明,添加安全奖励可进一步降低近距离碰撞率,稳定轨迹生成,且不损害推理质量。如表9所示,完整奖励配置(推理+一致性+安全)实现最低近距离碰撞率,同时保持ADE与推理-动作一致性的提升。
消融实验:视觉-语言模型主干网络选择
视觉-语言模型主干网络的选择对Alpamayo-R1的性能至关重要。本节从两个互补维度展开研究:模型规模的影响,以及物理智能(Physical AI)导向预训练的价值。这些消融实验共同证明:模型容量与领域专用预训练均为实现优异驾驶性能的关键。
模型规模消融
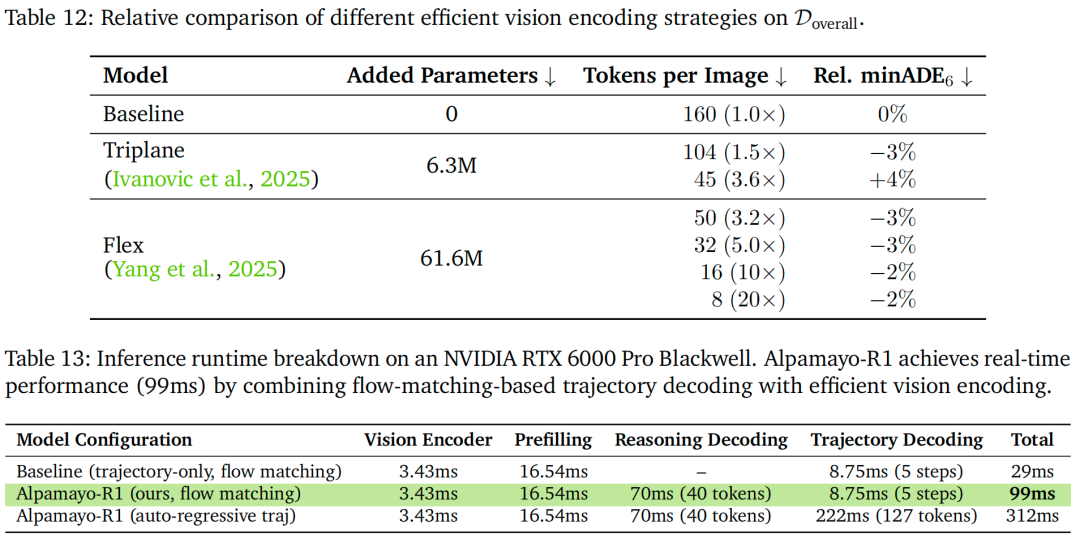
为研究模型容量对驾驶性能的影响,我们首先采用通用视觉-语言模型进行基准缩放实验。具体评估三种不同主干网络规模的架构:0.5B、3B与7B参数。其中,0.5B模型采用DINOv2视觉编码器与Qwen2.5-0.5B语言模型;3B与7B模型则分别采用Qwen2.5-VL-3B与Qwen2.5-VL-7B。为保证消融实验的公平性,所有变体均在相同数据上训练(训练预算低于主模型),并在 预留测试集(无路线信息)上评估,采用6秒时长的minADE指标。
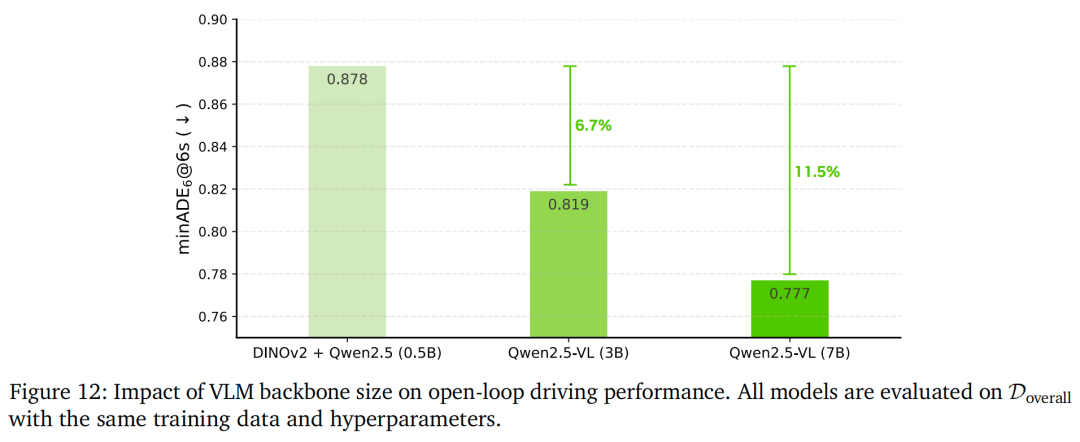
如图12所示,随着模型规模增大,开环性能持续提升:7B模型的minADE较0.5B基准降低11%(从0.901米降至0.819米),证明视觉-语言主干网络的缩放能提升场景理解与轨迹预测能力。尽管这些结果证实模型容量的重要性,但它们基于“无领域专用预训练的通用视觉-语言模型”;结合物理智能导向预训练(即Cosmos-Reason)能实现更显著的性能提升——这也是我们最终选择Cosmos-Reason作为Alpamayo-R1主干网络的原因。
数据规模消融
与模型缩放互补,我们研究在架构与训练预算固定时,训练数据规模对驾驶性能的影响。我们在0.5B模型上训练不同数据量:10万、20万、50万、100万与200万个视频片段,所有实验的总训练步数固定。
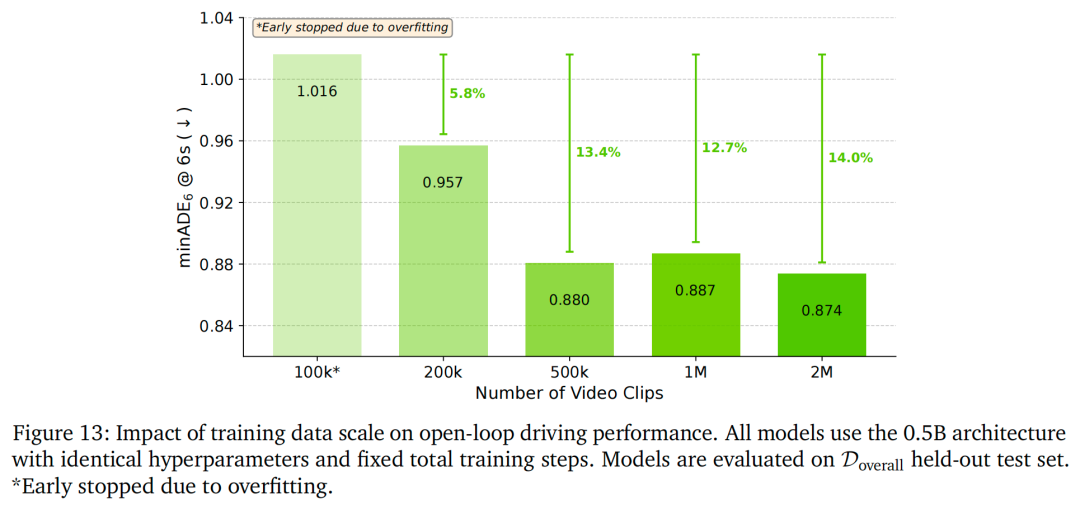
如图13所示,性能随数据规模增大而持续提升,证明数据多样性对自动驾驶的价值:
10万样本模型存在明显过拟合(无早停时1.111米,早停后1.016米);
扩展至50万样本时,minADE达0.880米,较10万样本提升13.4%;
200万样本模型实现最佳性能(0.874米),较10万样本提升14.0%。
这些结果与模型规模消融共同证明:模型容量与数据规模均为提升驾驶性能的有效维度,二者在实现稳健自动驾驶系统中具有互补作用。
Cosmos-Reason的物理智能能力
上述缩放实验虽证实模型容量的重要性,但未回答一个关键问题:在模型规模固定时,领域专用预训练是否有价值?如前文所述,Alpamayo-R1采用Cosmos-Reason作为视觉-语言模型主干网络——该模型通过物理智能数据(含驾驶场景)进行后训练。为验证这一架构选择的合理性,并证明物理智能导向预训练能在“仅缩放”基础上进一步提升驾驶专属理解能力,我们将Cosmos-Reason与同规模(7B)通用视觉-语言模型在公开驾驶基准上进行对比。
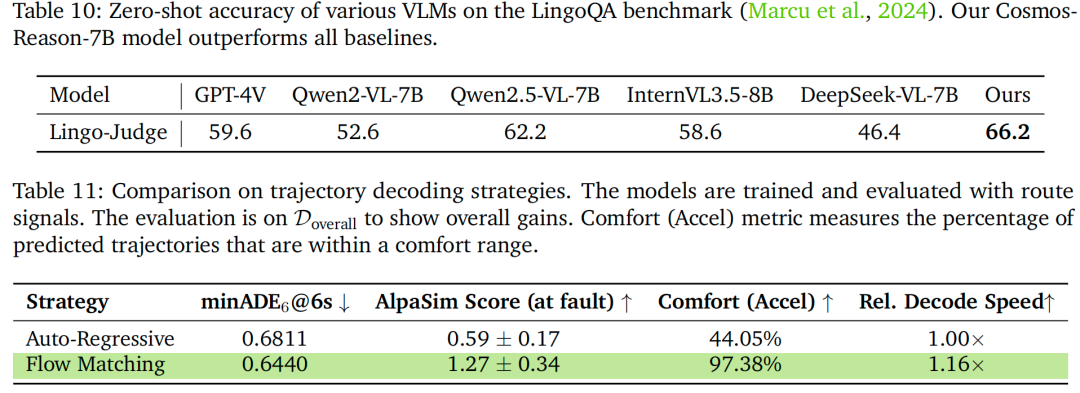
LingoQA基准评估:
表10展示在LingoQA基准上的零样本评估结果——该基准用于评估视觉-语言模型的驾驶场景理解能力。我们的Cosmos-Reason-7B模型准确率达66.2%,优于所有对比基准,包括GPT-4V(59.6%)、Qwen2-VL-7B(52.6%)、Qwen2.5-VL-7B(62.2%)、InternVL3.5-8B(58.6%)与DeepSeek-VL-7B(46.4%)。这一提升证明:物理智能导向有监督微调能显著增强模型在自动驾驶场景中的理解能力,补充图12所示的模型缩放收益。
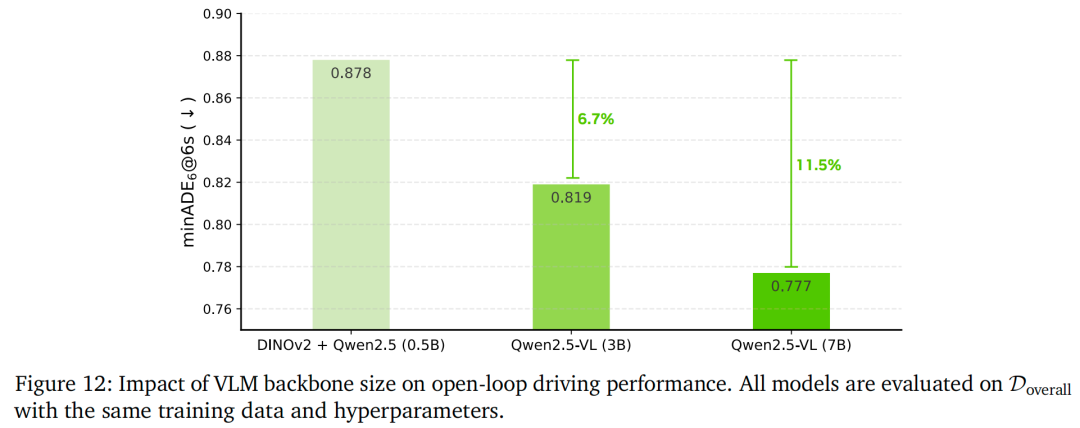
轨迹解码策略对比:
表11进一步验证采用“单轮车动力学控制+流匹配”的连续动作表示的有效性。我们对比两种模型:基准模型(训练预测6个离散轨迹token)与同规模、同训练数据的流匹配解码模型(离散轨迹tokenizer通过VQGAN预训练,以最小化输出离散token数量,降低自回归解码延迟,同时保持低重建误差)。推理阶段,流匹配设置 (即5步解码),在降低延迟的同时确保性能损失可忽略。
如表11所示,通过流匹配实现的“动力学约束连续动作空间”在开环与闭环指标上均显著优于基准:
6秒时域minADE从0.6811降至0.6440;
责任方AlpaSim评分从0.59提升至1.27;
舒适性(加速度)指标从44.05%提升至97.38%;
解码速度提升16%(相对解码速度从1.00×提升至1.16×)。
这些结果证实:模型容量与领域专用预训练均为实现优异驾驶性能的关键,也进一步验证我们选择Cosmos-Reason作为Alpamayo-R1主干网络的合理性——其为模型提供了通用视觉-语言模型所不具备的物理智能基础能力。
消融实验:动作模态注入
表11已验证采用“单轮车动力学控制+流匹配”的连续动作表示的有效性。具体而言,我们对比“自回归预测离散轨迹token”的基准模型与“通过流匹配解码轨迹”的同规模模型(训练数据相同)。离散轨迹tokenizer通过VQGAN预训练,以最小化输出离散token数量,降低自回归解码延迟,同时保持低重建误差。推理阶段,流匹配设置 (即5步解码),在降低延迟的同时确保性能损失可忽略。
结果显示,基于流匹配的动态连续动作空间在开环、闭环指标、舒适性与推理速度上均实现显著提升,进一步证明动作模态注入设计的有效性。
消融实验:高效视觉编码
除默认单图像tokenizer外,还存在多种更高效的视觉编码方法,可减少多摄像头视频输入所需的token数量。为对比不同方法,我们采用4摄像头设置,改变视觉编码器,并通过 上的minADE指标,对比端到端模型的开环驾驶质量(相对基准模型)。
如表12所示:
三平面多摄像头tokenizer(Ivanovic et al., 2025):仅增加6.3M参数,token数量减少3.6倍(从160个/图像降至45个/图像),且minADE与基准基本持平;
Flex(Yang et al., 2025):实现更显著的token压缩——最高达20倍(从160个/图像降至8个/图像),仅增加61.6M参数,且驾驶质量与基准持平。
Alpamayo-R1默认采用单图像tokenization,原因在于最优编码策略需根据摄像头数量、时序帧数与摄像头分辨率动态调整:例如,摄像头数量少、历史短时域场景更适合单图像tokenization;摄像头数量多、历史短时域场景更适合三平面;摄像头数量多、历史长时域场景则更适合Flex。
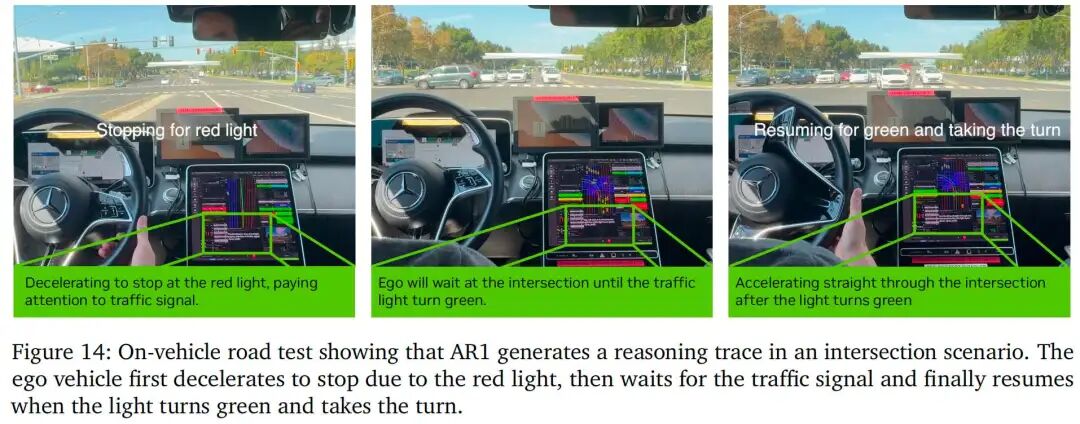
实车道路测试
为验证AR1的真实世界部署能力,我们将模型部署于测试车辆,在城市驾驶环境中开展道路测试。车辆成功完成复杂城市场景的无人工干预导航,证明模型能处理仿真之外的真实驾驶条件。图14展示一个路口场景:AR1准确识别交通状况,生成清晰简洁的推理轨迹,并执行相应驾驶动作。这些测试证实:仿真中的性能提升能成功迁移到真实世界自动驾驶场景。
实时推理性能:
实车部署的关键要求是实时推理能力。我们在NVIDIA RTX 6000 Pro Blackwell平台上对AR1进行基准测试,端到端推理延迟达99毫秒,满足自动驾驶的实时需求(通常要求100毫秒以内)。表13详细拆解推理流水线耗时,并与其他设计选择对比:预填充(prefilling)阶段通过Transformer层处理视觉token与路线信息,生成KV缓存,供后续推理与轨迹解码使用。
六、结论
在本研究中,我们提出了Alpamayo-R1(简称AR1)——一种视觉-语言-动作(VLA)模型,该模型将结构化思维链推理能力与轨迹预测相融合,旨在提升自动驾驶系统的性能,尤其针对长尾、安全关键型场景。为使模型能够生成具备因果锚定特性的推理内容,我们构建了因果链(Chain of Causation, CoC)数据集:通过“大规模自动标注+人机协同”的混合标注流程生成,确保推理数据的高质量与规模化。此外,我们通过强化学习(RL)实现推理与动作的对齐,确保模型生成的推理轨迹与实际执行的驾驶行为保持一致。
通过开环指标、闭环仿真及消融实验的全面评估,我们证实:AR1相较于端到端基准模型实现了持续性性能提升,尤其在涉及复杂智能体交互的高难度场景中,性能增益更为显著。
未来工作:
尽管当前评估聚焦于内部数据集与LingoQA基准,但我们计划将评估范围扩展至更多自动驾驶规划与决策领域的公开基准。这将有助于更全面地展现Alpamayo-R1在不同评估协议下的能力,同时实现与领域内其他最先进方法的直接对比。
从更广泛的研究视角来看,仍有多个极具潜力的方向值得探索:
策略结构化:目前我们基于流匹配的轨迹解码器已能输出满足运动学约束的轨迹,但未来可探索分层策略架构——将高阶元动作分解为结构化运动基元,进一步提升模型的可解释性与效率;
按需推理:当前架构会为每个输入生成推理轨迹,未来可研究自适应推理机制:仅在安全关键或场景模糊的情况下触发推理过程,类似于近期在推理时缩放(test-time scaling)领域的进展(Yao et al., 2023;OpenAI, 2024),实现推理时计算资源的更高效分配;
辅助任务集成:AR1目前聚焦于轨迹预测与因果推理,未来可融入互补的自监督目标(如深度估计、场景流预测或3D高斯溅射表示学习),以提升视觉骨干网络的语义理解能力;
世界模型集成:当前方法基于观测状态直接预测动作,未来可引入学习型世界模型,实现前向仿真与反事实推理,进一步提升模型在动态场景中的稳健性。
开源发布:
我们计划在Hugging Face平台上发布Alpamayo-R1模型,同时开放部分CoC数据集。该发布将补充NVIDIA Hugging Face页面已有的传感器数据与标注资源,旨在推动“基于语言的推理”与“自动驾驶”交叉领域的研究进展。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1777
1777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









