



点击下方卡片,关注“大模型之心Tech”公众号
本文只做学术分享,如有侵权,联系删文
当我们还在讨论“大模型靠堆数据变聪明”的时代,另一场无声的革命正在发生。
新加坡国立大学联合 Sea AI Lab等研究团队发现,在数据成为瓶颈的未来,扩散语言模型(Diffusion Language Models, DLM) 展现出惊人的学习潜力。
在相同规模与算力下,它们不靠更多数据,却能学得更快、更深、更“聪明”。
这篇名为《Diffusion Language Models are Super Data Learners》的最新论文揭示:DLM 在有限数据条件下,全面超越传统的自回归语言模型(AR),预示着语言模型的新范式正在崛起。
论文链接:https://arxiv.org/abs/2511.03276v1
研究背景
自回归语言模型目前是现代大规模语言模型的主流,其优点是高效的训练和推理性能,适用于大规模数据集。然而,随着计算资源的不断增加,高质量数据成了扩展模型的主要瓶颈。
在数据有限的情况下,哪种模型能够从每个独特的token中提取更多的信息?换句话说,数据(而非计算)成为了限制因素。
何为智能交叉点?
研究定义:当独特数据量有限时(即可用的高质量数据不多),DLM 模型在多轮训练后会超越同规模的 AR 模型,这种现象被称为“Crossover”。具体来说,在数据受限的情况下,DLM比AR模型具有大约3倍的数据潜力。
这一交叉点随着几个因素的变化而变化:
数据越多,交叉点出现得越晚。
数据质量越高,交叉点也越晚。
模型越大,交叉点越早出现。
这意味着在未来高质量的数据仍然是最稀缺的资源的情况下,DLM将成为未来语言模型发展的有力竞争者。成为推动前沿能力的有力工具。
定义
1. 自回归语言模型
定义:自回归语言模型是现代大规模语言模型(LLM)中的主流方法。它通过链式法则参数化一个token序列的联合分布。
实现方式:现代的AR模型通常使用解码器-only结构,通过因果自注意力实现每个位置的上下文限制,使得每次生成都只依赖于先前的tokens,支持逐步生成文本。训练过程中使用教师强制方法,而推理阶段则通过KV缓存来提高效率。
学习目标:AR模型通过最大化对数似然(来优化参数,即最小化交叉熵。
2. 扩散语言模型
定义:采用加噪—去噪的框架,在训练过程中将序列中的tokens进行加噪处理,然后在推理时通过去噪恢复原始序列。
学习目标:DLM的学习目标是最大化对数似然的变分下界),通过最小化以下损失函数来优化。
实验结果
1. 实验设置
训练与数据:
所有训练都使用了经过显著修改的Megatron-LM代码库。
交叉实验中使用的数据集包括Nemotron-CC、c4-en和RefinedCode。
所有token预算是从这些数据集中随机抽取的。
训练参数:
批量大小:256
序列长度:2048
学习率采用预热—稳定衰减策略,初始学习率为2e-4,经过1000步预热后,10%的指数衰减至2e-5。
模型参数使用均值为0、标准差为0.02的正态分布随机初始化。
架构配置采用了GPT-2 tokenizer、RoPE(旋转位置编码)、SwiGLU激活函数、预层RMSNorm等技术。
所有混合专家模型使用token选择路由,并附带1e-2辅助损失和1e-3 z损失。
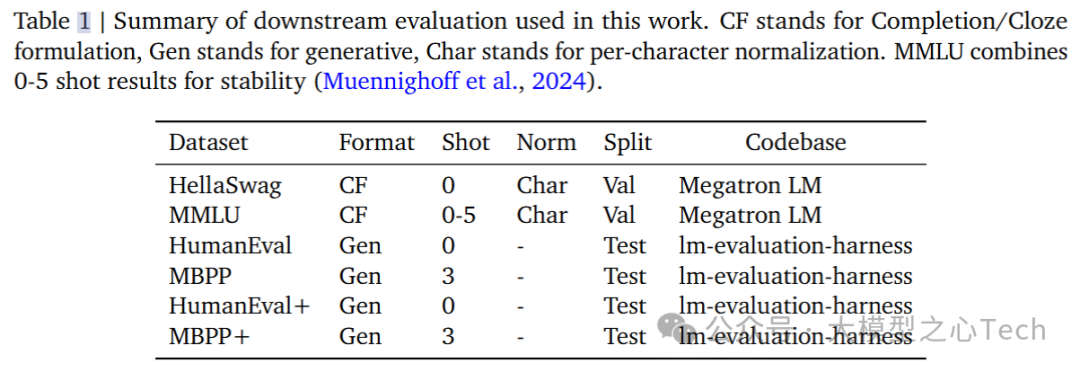
2. 数据预算决定交叉点的时机
研究探讨了在数据受限的情况下,独特数据的预算对DLM和AR模型性能差异的影响。实验中,总训练token数量固定为96B,但独特token的数量从 0.5B 到 96B 不等,同时保持模型规模为 1B。 研究发现:
在较低的数据预算下,DLM显著超越AR模型,表现出比AR模型高三倍的数据效率。
例如,一个训练了0.5B独特token的DLM(还未完全收敛)能够达到与训练了1.5B独特token的AR模型相当的性能。
在计算资源充足、数据丰富的情况下,AR模型更有效地拟合数据,而DLM则在数据受限时表现出更强的能力。
随着独特数据量的增加,交叉点出现得越来越晚,这表明数据量越大,AR模型越能表现出优势。
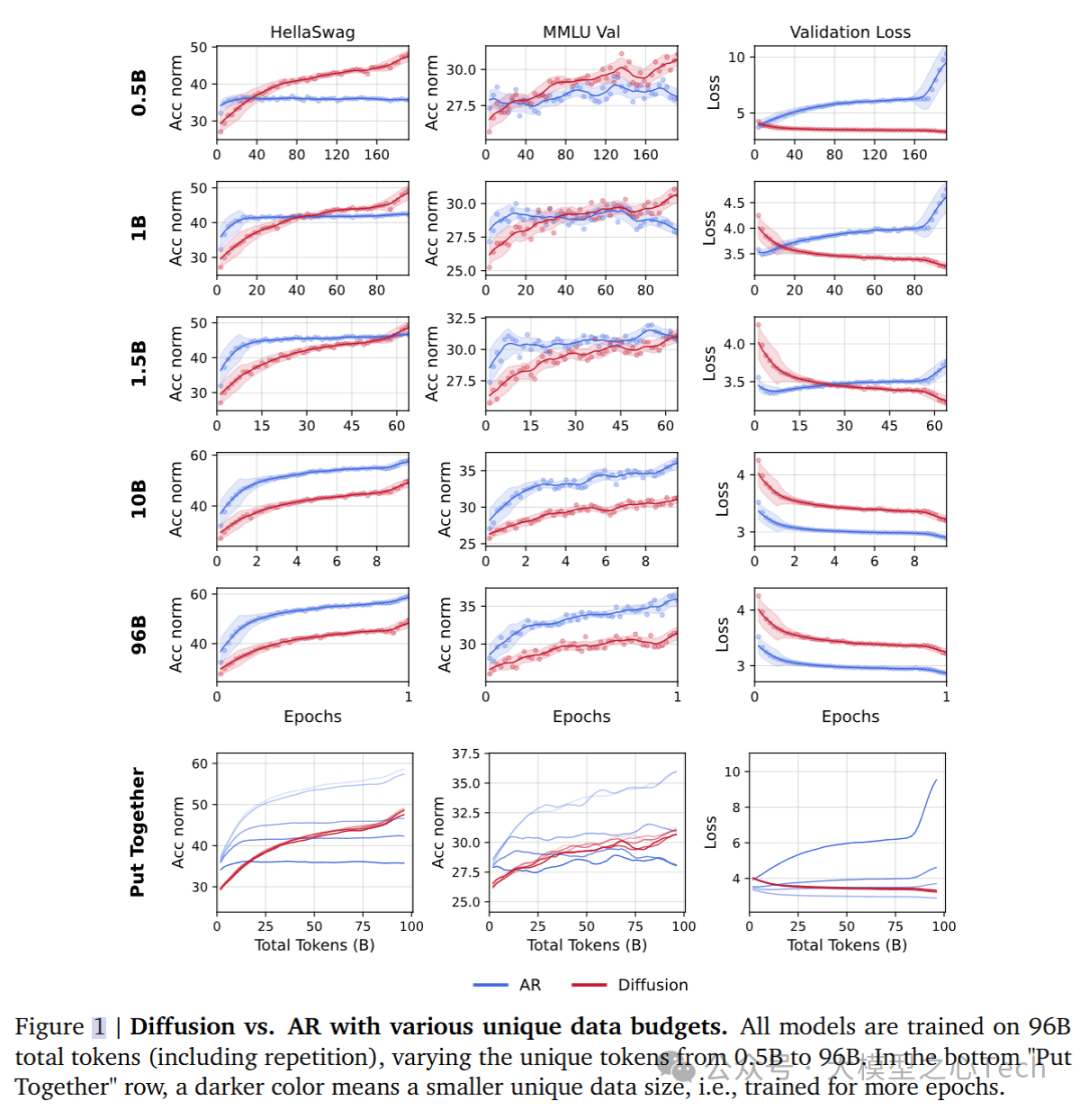
3. 数据质量的变化
数据的质量也是影响模型性能的关键因素。实验中,研究团队使用了三种质量等级的数据(低、中、高质量),并对1B参数的AR和DLM模型进行了训练,使用1B独特token进行训练,共训练96个epoch。研究发现:
数据质量的提高使得AR模型对数据质量的变化更为敏感,并且随着数据质量的提高,DLM的交叉点出现得稍微推迟。
无论是DLM还是AR模型,在高质量数据上表现都显著改善,但DLM依然在数据受限的情况下占有优势。
在验证集上,中等质量的数据表现出了最低的验证损失,这表明验证损失并不总是衡量模型性能的可靠指标。
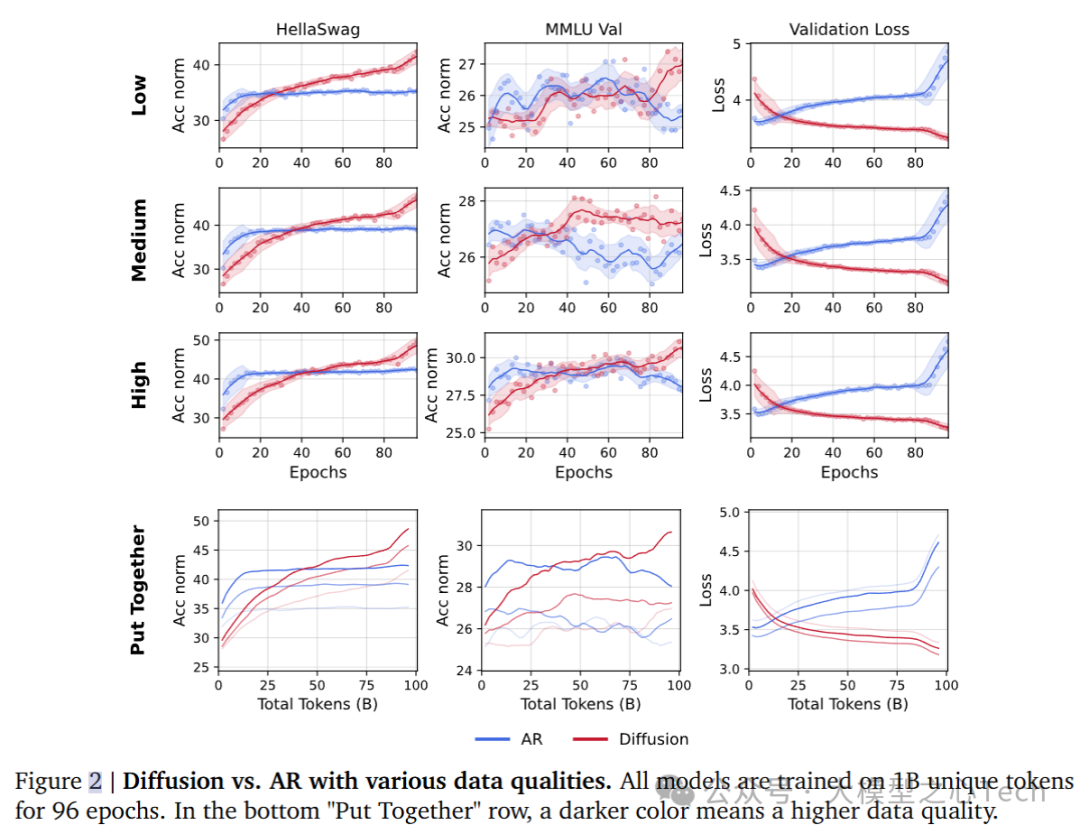
4. 模型规模对数据受限训练的影响
依据计算和数据受限的规模法则,实验探讨了随着模型规模的扩大,交叉点的变化。实验中,DLM和AR模型的规模从1B到8B参数不等,训练仍然在1B独特token上进行,训练周期为96个epoch。
较大的模型规模使交叉点提前出现。原因是AR模型在数据受限时很快会饱和,进一步扩展模型规模不会带来显著提升,反而可能导致过拟合。
与之相反,DLM模型可以充分利用更大的模型规模,即使在数据受限的情况下,随着模型规模的增加,DLM的表现持续提高。
DLM的学习空间比AR模型更大,因为DLM能够进行任意顺序建模,输入序列的每个token都可以生成多个变体,而AR模型只能生成有限的因果关系映射。
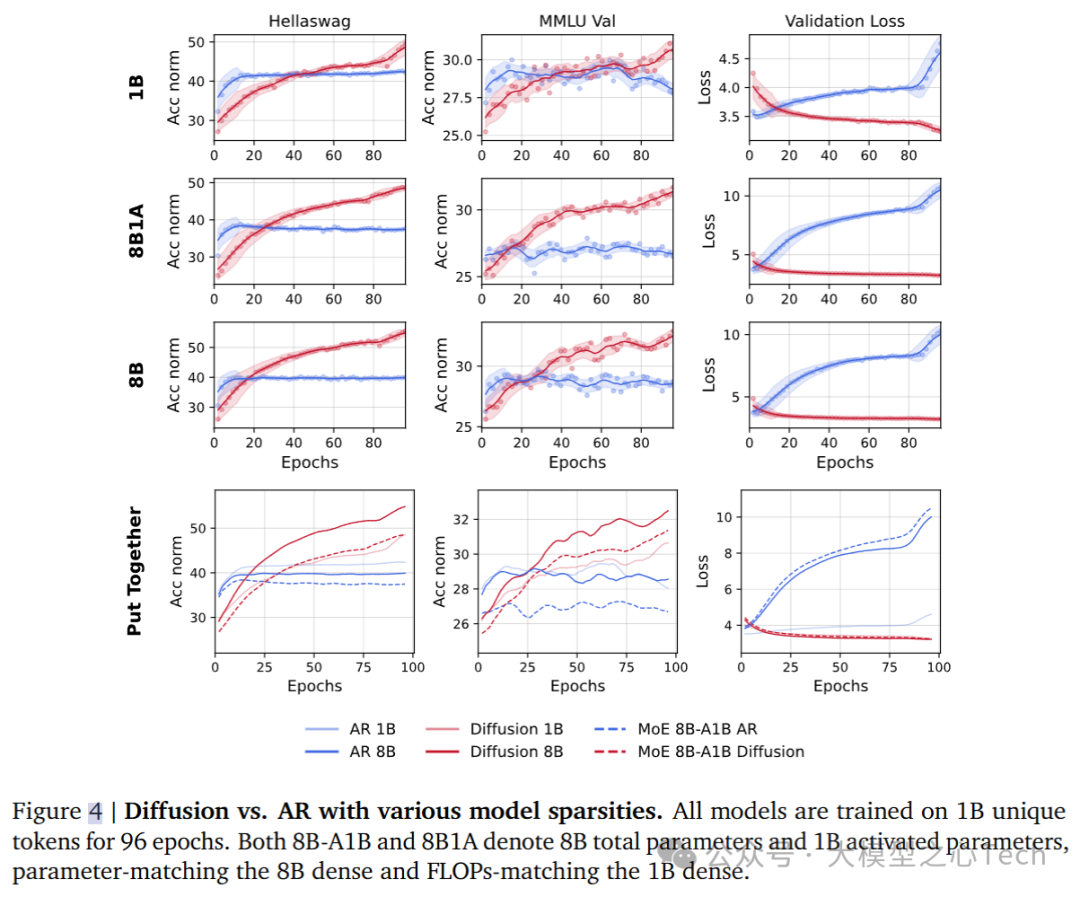
5. 稀疏、密集与超密集架构的对比
在计算效率方面,DLM与AR模型的区别尤为明显。DLM在训练时需要更多的FLOPs,而推理时需要更高的并行FLOPs,以实现更高效的计算。在本节实验中,研究使用了MoE架构,在该架构下,不同的稀疏和密集模型分别被训练。
在所有稀疏性水平下,DLM模型始终超越AR模型,并且交叉点的时机依次排列为:8B密集模型 < 8B1A MoE < 1B密集模型。
稀疏化的DLM比AR在相同的稀疏程度下表现更好,而稀疏AR模型在数据受限的情况下表现最差。
对比不同密度的架构,结果表明,增加FLOPs能显著改善性能,尤其是在数据受限时,DLM模型的密集架构始终表现优于稀疏架构。
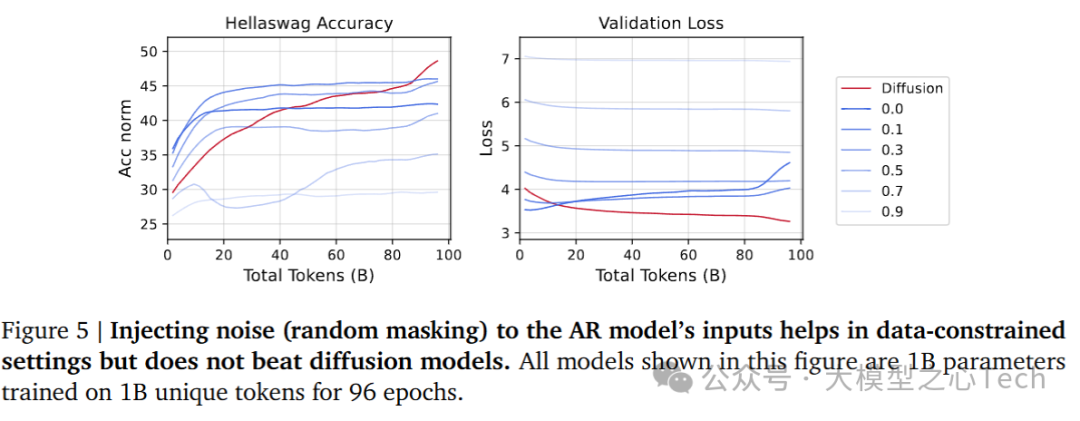
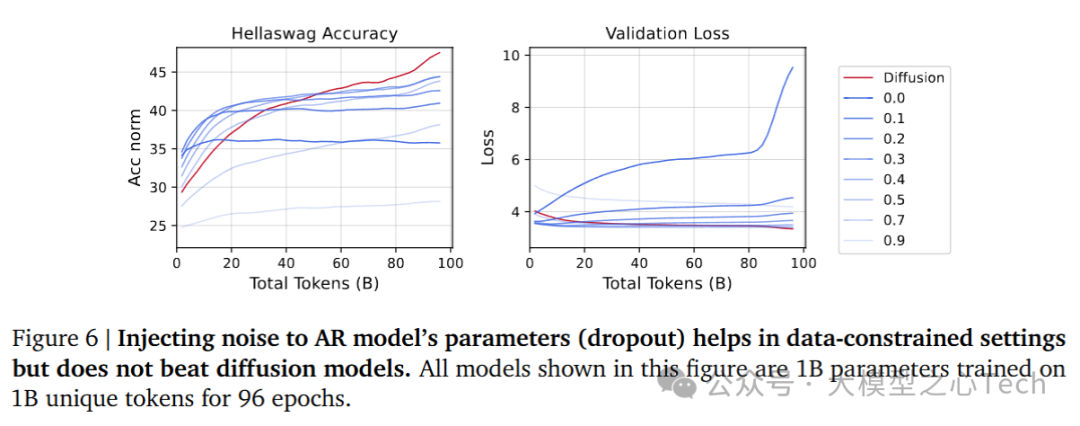
6. 噪声在模型中的作用
实验进一步分析了噪声注入对DLM和AR模型表现的影响。通过向AR模型输入数据中注入噪声,模拟DLM的加噪-去噪过程,研究其对模型性能的影响。
噪声注入对AR模型有一定提升作用,但即使在较低噪声水平下,AR模型的表现也无法超越DLM。
对AR输入数据进行噪声注入(如随机掩码或dropout)可以在数据受限的情况下改善性能,但在噪声水平过高时,AR模型的性能会迅速下降。
DLM通过丰富的蒙特卡洛采样和噪声增强,能够在数据受限的环境中表现出更加稳定的优势。
将交叉扩展到万亿级Tokens
研究进一步验证了在大规模独特token数据集上的交叉点现象,尤其是在生成任务中,训练的总计算预算约为1.5T tokens。
在训练初期,DLM模型在下游基准任务上表现出了非常明显的超越AR模型的现象,进一步证明了扩散模型与自回归模型交叉点的普遍性。
尽管训练达到1.5T token的计算量,但DLM在训练结束时仍未完全收敛,这意味着如果继续训练,DLM还具有大量未开发的潜力。
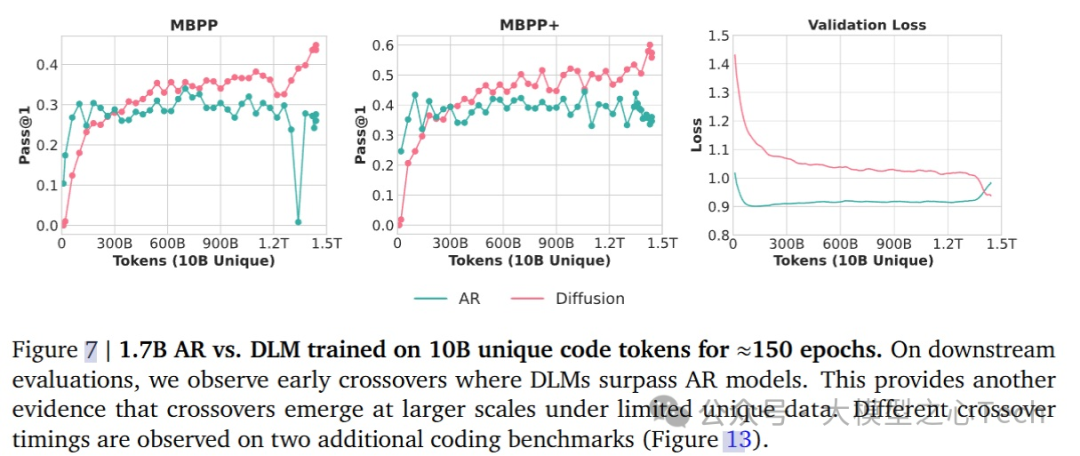
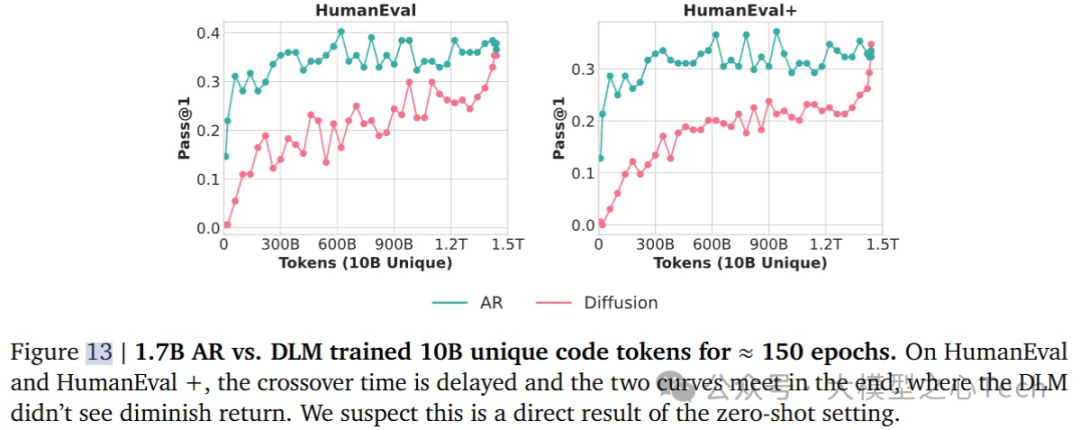
在标准基准之外,研究团队还使用了HumanEval和HumanEval+等代码生成任务来评估DLM和AR模型。
发现交叉点在HumanEval和HumanEval+中的表现时间有所不同,具体来说,交叉点出现在退火阶段的末尾,没有出现性能下降。
MBPP与HumanEval之间的差异可能源自于评估协议:MBPP和MBPP+使用了3-shot设置,而HumanEval和HumanEval+使用了0-shot设置。这种评估配置的不同可能会在不同的训练阶段放大或抑制模型的能力,从而导致交叉点的时机发生变化。
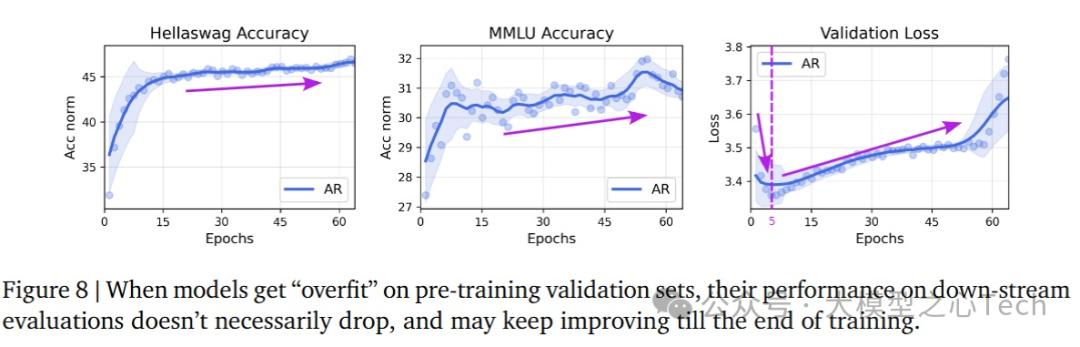
高验证损失≠降级智能
在自回归(AR)模型中,验证集损失上升并不一定意味着模型的智能或性能下降,尤其是在过拟合的情况下。研究观察到:
在AR模型中,尽管验证损失(NLL)增加,表明模型可能开始过拟合,但模型在下游任务中的表现仍然在持续改进。
这种现象的原因在于,验证损失是通过计算绝对交叉熵损失来衡量的,而在多选题型的基准测试中,准确率是基于不同选项之间的相对交叉熵损失来比较的。
绝对NLL的变化并不一定意味着相对排序的变化,即模型的验证损失增加,并不必然导致其区分能力下降。
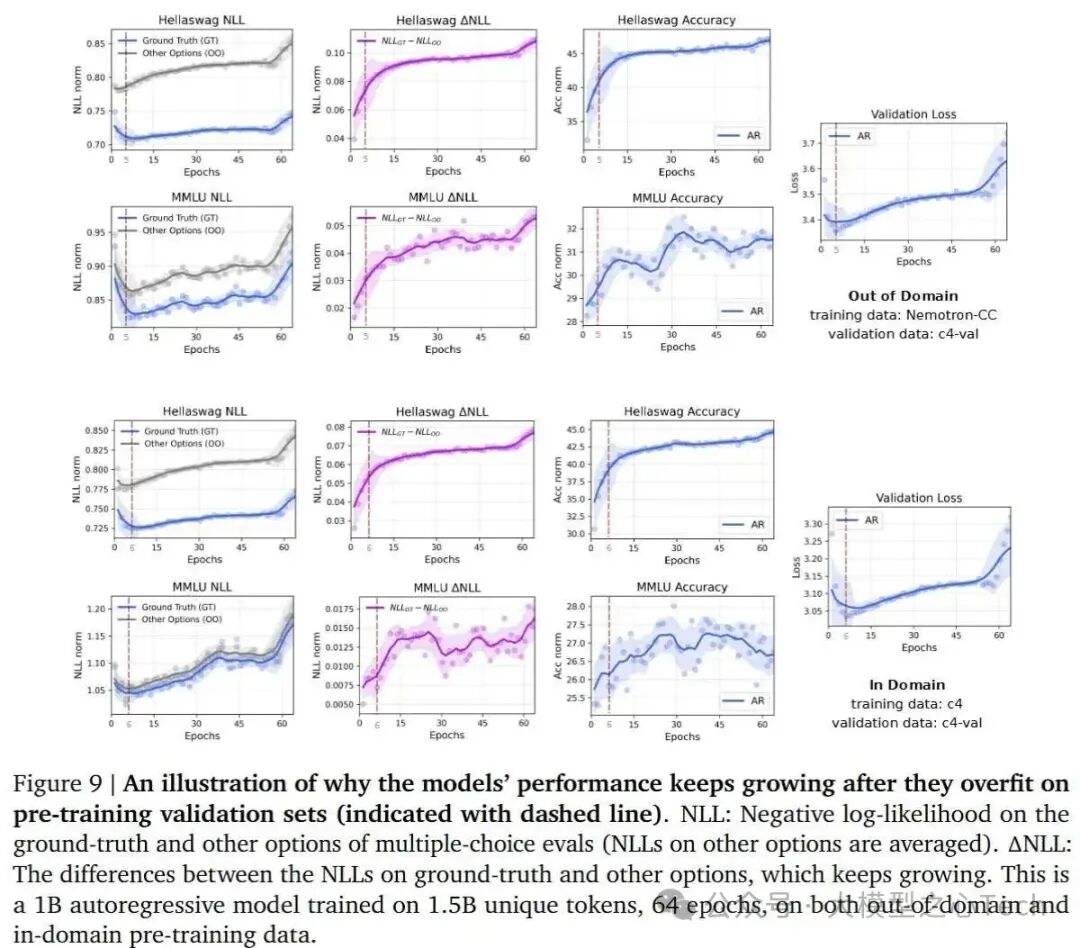
NLL差异与模型判别能力的结果表明:
即使验证损失上升,正确答案与错误答案之间的NLL差距持续增加,显示出模型的判别能力持续改善。
即使在验证损失上升的情况下,AR模型在区分正确答案和错误答案之间的能力仍在持续增强。
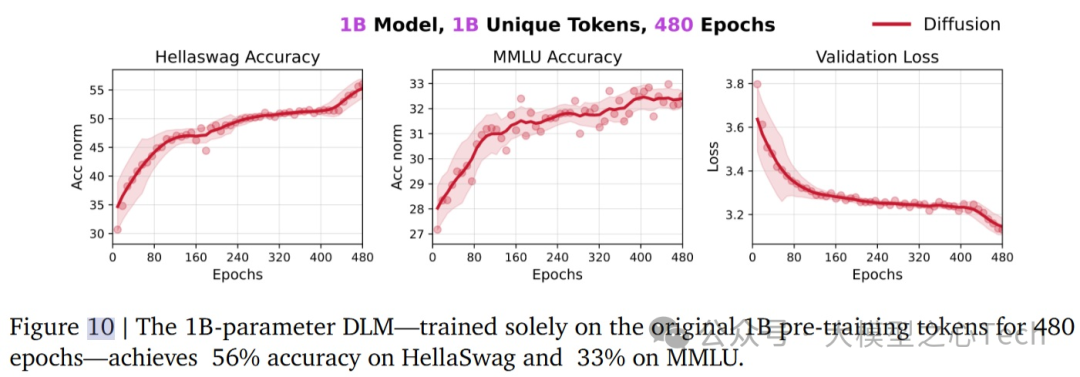
扩散语言模型是否会过拟合?
为了探索DLM在训练中的数据潜力,研究团队进行了额外的实验,将1B-token数据集重复使用了480个epoch,总共训练了480B tokens。结果发现:
即使在极端的数据重复情况下,DLM仍在HellaSwag和MMLU这两个基准任务上表现出色,分别达到了**56%和33%的准确率,显著超过AR模型的41%和29%**。
尽管进行了大量的数据重复训练,DLM的性能并未达到饱和,表明DLM能够从固定的1B-token语料中提取出更多的信息。
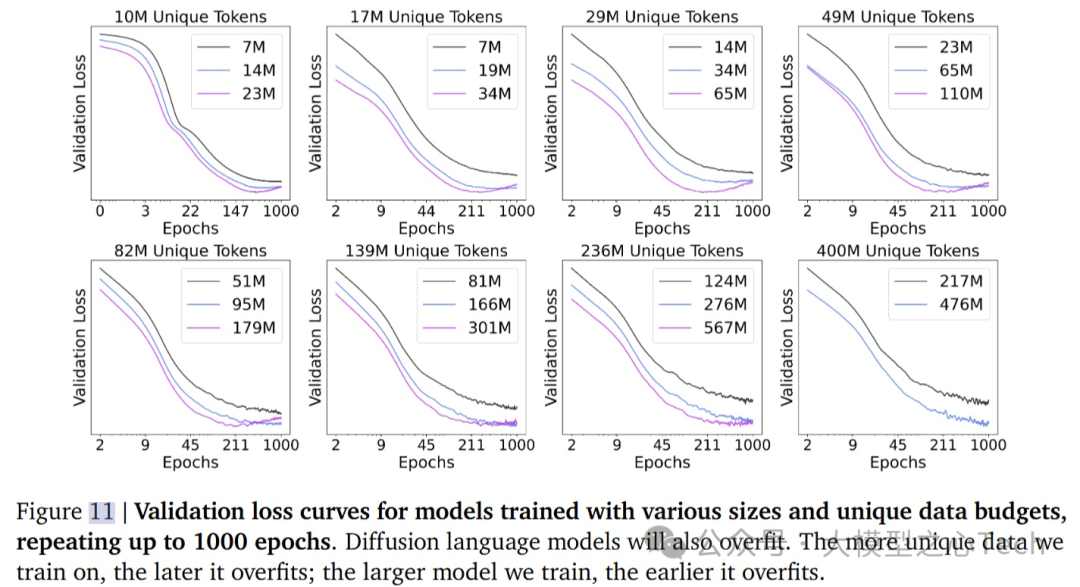
研究进一步探讨了DLM是否会在长时间训练后出现过拟合,特别是当训练周期延长至1000个epoch时。结果表明:
当独特数据量较小时,并且模型规模较大时,过拟合最终会在训练后期出现。
更大数据量推迟了过拟合的出现,而更大模型则容易较早出现过拟合。
尽管模型在某些情况下可能会过拟合(验证损失上升),但性能退化通常发生得比较晚。例如,在实验中,尽管0.5B tokens和192个epoch的训练中模型已经过拟合,性能并没有立即下降。
讨论和未来方向
通过对扩散语言模型与自回归语言模型之间的比较,特别是它们在计算效率和数据效率上的差异、DLM的优势与限制,以及它们在实际应用中的潜力。不难发现:
自回归模型依赖严格的因果偏置,即每个token的生成仅依赖于之前的token。然而,很多数据(如源代码、数据库、符号表示等)并不具有明显的因果关系。DLM通过去除这种因果偏置,允许任意顺序建模,从而能更好地捕捉数据中的复杂模式。
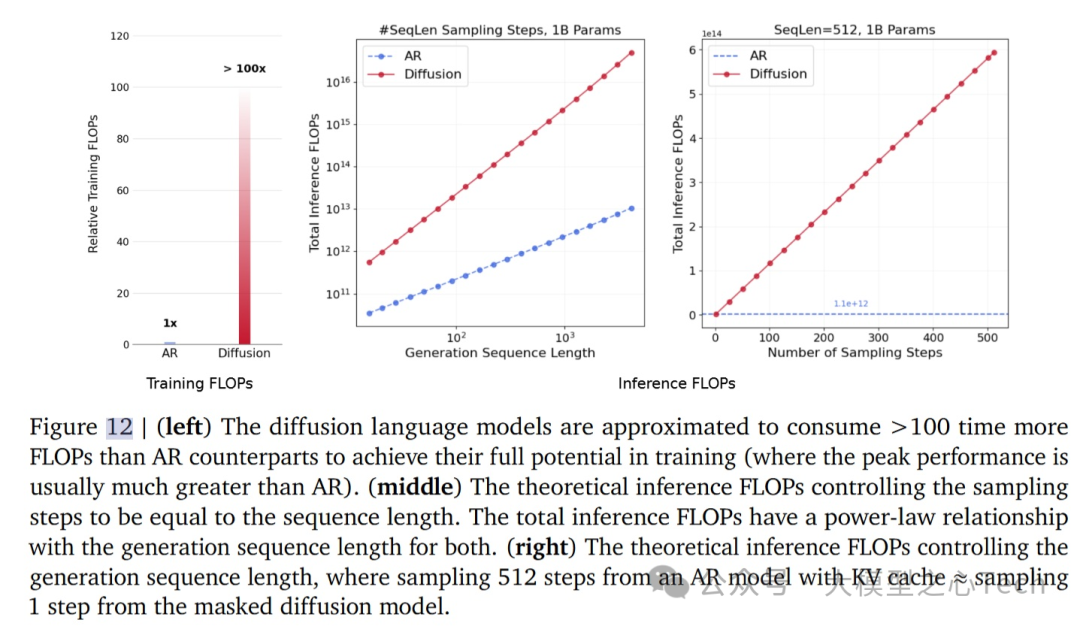
DLM通过在训练过程中反复处理数据,造成了每次任务计算量的剧增。这使得在训练时,DLM需要比AR多约100倍的FLOPs,推理时,DLM的FLOPs消耗也比AR多得多。尤其是在生成长序列时,DLM的计算消耗呈线性增长。
通过蒙特卡洛采样,DLM对数据进行增强,在训练过程中将每个数据点转换为多个不同的噪声版本。这种方法让DLM能够在数据稀缺的情况下更有效地学习,增加了其从有限数据中提取信息的能力。
然而,数据的重复使用可能会导致污染和记忆化风险,如果去重和审计机制不完善,可能会影响DLM模型的安全性和隐私性,尤其是在超密集训练中。另外,DLM在实际部署时的系统架构仍不如AR模型成熟,目前的实验主要集中在英语数据上,多语言、跨模态和长上下文的应用仍需要进一步的研究。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









