 UniSplat:前馈3D重建新突破
UniSplat:前馈3D重建新突破




点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Chen Shi等
编辑 | 自动驾驶之心
难得,滴滴也出了前馈GS方向的新工作,还是少帅参与 — UniSplat!
前馈式3D重建技术在自动驾驶领域发展很迅速,但现有工作在自动驾驶环视场景中的表现不佳,这是由于稀疏非重叠的相机视角以及复杂场景动态性双重buff导致。
针对这个问题,港中文(深圳)、滴滴和港大的团队提出UniSplat — 一种通用feed-forward框架,通过统一的潜在时空融合实现鲁棒的动态场景重建。该框架构建3D潜在Scaffold(一种结构化表示),利用预训练基础模型捕捉场景的几何和语义上下文。
为有效整合跨空间视角与跨时间帧的信息,引入了高效的融合机制,直接在3DScaffold内运作,实现一致的时空对齐。
为确保重建结果的完整性和细节丰富度,设计了双分支解码器,通过结合点锚定细化与体素化生成,从融合后的Scaffold中生成动态感知高斯体,并维护静态高斯体的持久化记忆,以实现超出当前相机覆盖范围的流式场景补全。
实验表明,UniSplat的新视角合成能不还不错,即使对于原始相机覆盖范围外的视角,也能提供鲁棒且高质量的渲染结果。
论文标题:UniSplat: Unified Spatio-Temporal Fusion via 3D Latent Scaffolds for Dynamic Driving Scene Reconstruction
论文链接:https://arxiv.org/abs/2511.04595
PS. 立个Flag,最近打算梳理下前馈GS方向的内容,梳理下这个方向的里程碑及自驾领域结合的工作。自动驾驶之心联合工业界算法专家开展了这门《3DGS理论与算法实战教程》!我们花了两个月的时间设计了一套3DGS的学习路线图,从原理到实战细致展开,全面吃透3DGS技术栈。添加助理咨询课程~
早鸟优惠!名额仅限「40名」

一、背景回顾
从城区驾驶场景中重建3D场景已成为自动驾驶系统的核心能力,支撑着仿真、场景理解和long-horizon规划等关键任务。近年来,3D高斯溅射技术取得显著进展,展现出令人印象深刻的渲染效率和保真度。然而,这些方法通常假设输入图像间存在大量视角重叠,且依赖逐场景优化,这限制了它们在实时驾驶场景中的适用性。
为实现更快的推理速度,前馈式重建方法应运而生,能够通过单次前向传播合成新视角。这类方法通常通过交叉注意力或构建多视图立体(MVS)cost volume,在图像域内编码视图间相关性,随后从融合后的特征中解码出高斯基元。值得注意的是,融合策略的选择至关重要,它会显著影响最终的渲染质量。EvolSplat利用3D-CNN整合前视单目序列的多帧几何信息,但忽略了语义融合且缺乏动态处理机制。与此同时,Omni-Scene采用三平面Transformer实现强大的多视图融合,但未纳入时间聚合,且受限于粗粒度的3D细节。尽管取得了这些进展,城市驾驶场景中的鲁棒重建仍面临挑战,尤其是在维持随时间平滑演化的统一潜在表示、处理部分观测、遮挡和动态运动,以及从稀疏输入中高效生成高保真高斯体等方面。
为解决这些挑战,本文提出UniSplat,一种基于多相机视频的动态场景建模通用前馈框架。UniSplat的核心见解是构建统一的3D Scaffold,融合多视图空间信息与多帧时间信息。该Scaffold支持3D空间中的几何和语义上下文交互,助力高效的长期信息整合与动态建模,并实现高斯基元的有效解码。通过保留和融合关键信息,它确保了场景重建在时间上的连贯性和一致性。
具体而言,UniSplat框架遵循三阶段流程。首先,我们将多视图图像输入预训练的几何基础模型和视觉基础模型,构建以自车为中心的3D Scaffold,将几何结构和语义线索编码为稀疏3D特征体。其次,进行时空融合:在当前帧的Scaffold内整合多视图空间上下文,并通过自车运动补偿将历史Scaffold融合到当前Scaffold中,得到时间增强的场景表示。最后通过双分支策略将融合后的Scaffold解码为高斯体:一个分支在稀疏点位置预测高斯体以获取细粒度细节,另一个分支直接从体素中心生成新的高斯体,以补充点锚定预测的不足。每个高斯体都被分配动态概率分数以识别静态内容,使我们能够跨帧维护静态高斯体的记忆库,实现长期场景补全。
本文在Waymo Open数据集和NuScenes数据集上对方法进行评估,这两个数据集包含动态街道场景,具有复杂的环境条件和有限的多相机图像重叠。实验结果表明,我们的方法在输入视图重建和新视角合成任务中,在两个数据集上均达到当前最优性能。值得注意的是,借助时间记忆,我们的模型在合成原始相机覆盖范围外的视角时,展现出强大的鲁棒性和卓越的渲染质量。
综上所述,我们的主要贡献如下:
提出UniSplat,一种基于统一3D潜在Scaffold、从多相机视频中重建动态场景的新型前馈框架。
设计新型的基于Scaffold的融合机制,支持统一的时空对齐和渐进式场景记忆整合。
提出带动态感知过滤的双分支高斯生成机制,实现细粒度且完整的渲染以及基于记忆的场景补全。
在两个大规模驾驶数据集上的综合实验表明,UniSplat显著优于当前最优的前馈重建方法,对观测相机视锥外的挑战性视角具有泛化能力。
二、UniSplat详解
UniSplat 针对多相机帧的连续流进行处理,维持场景随时间演化的统一 3D 潜在表示。如原文图 1 所示,每个时间步从多视图图像的 3D scaffold构建开始,生成编码场景几何与语义的 3D 体素(潜在scaffold);随后执行统一时空融合,整合当前Scaffold内的跨视图信息与前一时间步的潜在Scaffold;最后通过双分支解码器实现动态感知高斯生成,同时维护静态高斯的时间记忆库,以解决稀疏相机输入和有限视场导致的场景覆盖不完整问题。
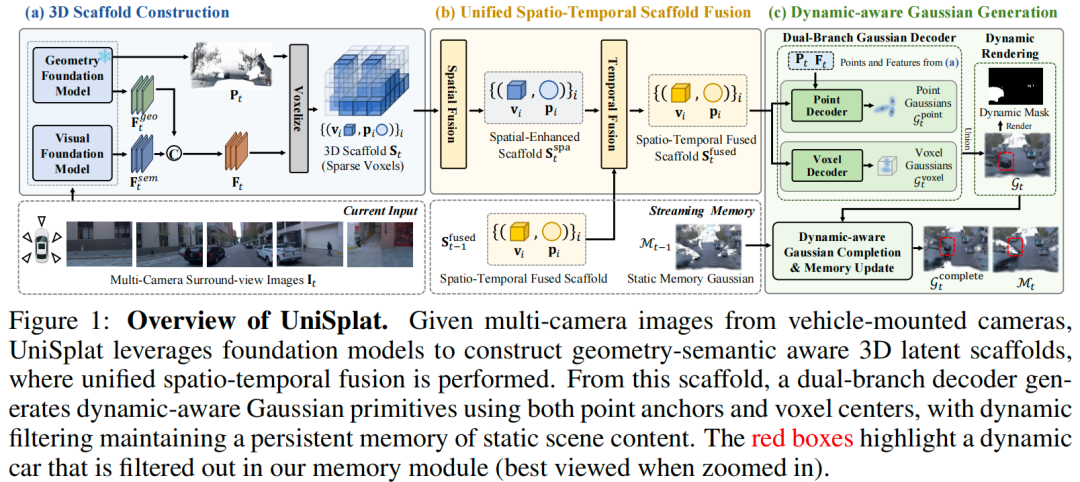
预备知识
3D 高斯溅射将场景表示为一组 3D 高斯基元集合 ,每个基元 由可学习参数元组定义,分别对应其 3D 中心位置、不透明度、协方差矩阵和颜色系数。
从目标视角渲染图像时,需将这些 3D 高斯投影到 2D 图像平面,并通过可微 alpha 合成进行融合。对于特定像素,所有投影覆盖该像素的高斯对其颜色贡献 计算如下:
其中, 是覆盖该像素的高斯集合(按深度排序), 为高斯 的颜色系数, 为其不透明度。
此外,受高斯可扩展性启发,本文为每个高斯引入可学习动态属性,以明确分离场景的动态成分。
3D Scaffold构建
从稀疏、低重叠的相机视角构建准确 3D Scaffold是驾驶场景多视图重建的核心挑战。本文通过几何基础模型推断 3D 结构,结合视觉基础模型补充语义信息,最终在自车坐标系下生成潜在Scaffold,为后续时空融合奠定基础。
度量尺度 3D 几何生成:给定多相机装置的同步多视图图像 ,首先采用最先进的前馈多视图几何基础模型(如 Wang et al., 2025a; e)直接预测密集 3D 点云 ,每个像素的 3D 坐标由所有视图联合推断(区别于单视图深度估计与后期融合,该方法通过学习多视图对应关系生成连贯的场景级点云)。
为解决几何模型预测中的尺度模糊问题,引入辅助尺度对齐分支:通过小型 MLP 从池化后的几何特征中预测每相机尺度因子,公式如下:
其中, 为几何模型的隐藏特征图, 表示对每个视图按高度和宽度维度进行平均池化。尺度预测通过最小化 与“基于 LiDAR 点参考、经 ROE 求解器计算的最优尺度向量”之间的误差实现监督。将 应用于 ,可得到度量一致的点云 ,作为Scaffold的几何基础。
含几何-语义上下文的Scaffold构建:由于 是无结构点集,需将其组织为稀疏体素网格,并融合几何与语义特征以生成 3D 潜在Scaffold:
利用视觉基础模型(Oquab et al., 2023)从输入视图提取语义感知 2D 特征 ,并与几何特征融合得到统一多视图特征图 ;
将点云体素化到覆盖周围场景的自车坐标系长方体中,体素大小为 ,仅保留含有点的有效体素;
对每个体素 ,计算其初始粗几何特征 (为体素内所有点坐标的平均值):
其中, 是体素 内所有点的索引集; 4. 将体素中心投影到输入视图,从 中采样对应特征,并与 拼接,最终场景的 3D Scaffold 定义为以下体素集合:
其中, 为特征维度, 是编码几何与语义上下文的体素特征, 是保留显式 3D 结构的体素中心。
统一时空Scaffold融合
Scaffold表示的核心优势在于其固有结构——在统一自车空间内编码显式 3D 几何,支持 3D 空间中的上下文交互,可在单一Scaffold表示内直接、高效地实现跨视图和跨时间帧的时空融合。
空间Scaffold融合:区别于传统方法在 2D 空间通过图像级交叉注意力融合跨视图空间信息(易受视图重叠有限影响),本文直接在 3D Scaffold空间执行空间融合:3D 表示中,不同视图的空间对应信息天然在 3D 空间对齐。具体采用稀疏 3D U-Net 整合多视图特征,生成空间增强Scaffold表示 :
。
时间Scaffold融合:不同于现有方法处理历史原始图像,本文以流式方式直接在Scaffold表示内整合时间线索:
从流式记忆中获取前一帧的融合潜在Scaffold特征 ;
利用已知自车姿态 ,将 的体素中心 warp 到当前帧坐标系,并为其特征添加时间步嵌入以区分当前观测;
通过稀疏张量加法合并“变换后的前一帧Scaffold ”与“当前空间增强Scaffold ”:重叠体素位置通过元素加法聚合特征,非重叠区域直接保留双方特征,公式表示为:
其中, 表示稀疏张量加法操作; 4. 采用轻量级稀疏卷积网络进一步细化 ,以捕捉复杂时间依赖,并将其缓存回流式记忆,维持长期时间信息。
动态感知高斯生成
基于时空融合后的Scaffold ,通过双分支解码策略生成 3D 高斯基元集合,显式分离场景的静态与动态成分,实现随时间的渐进式场景补全。
双分支高斯解码器:解码器的两个分支互补,共同提升重建保真度与完整性:
点解码器分支
聚焦于保留细粒度几何细节:利用度量尺度点云 中的点级锚点,对每个点 ,定位其在Scaffold中的体素坐标,并从 中检索对应潜在特征:
其中, 表示体素索引操作;若点落在Scaffold空间范围外,则采用零填充。由于每个点 与源像素一一对应,额外从多视图特征图 中为每个点采样 2D 图像特征 ,将 与 拼接后通过 MLP 预测高斯基元:
其中, 是高斯相对于点锚点的偏移量, 是学习到的动态分数(表示运动可能性),该分支生成细节丰富的高斯基元集合 。
体素解码器分支
通过直接从体素级Scaffold特征预测新高斯基元,补充点解码分支,填补稀疏覆盖区域并提升场景完整性:对 中的每个体素,采用紧凑 MLP 每体素生成 组高斯参数(同公式 8),每个高斯的中心由“体素中心 + 预测偏移量”得到,形成高斯基元集合 。
最终,时间 的完整重建结果为两分支高斯集合的并集:
动态感知高斯补全:为提升时间一致性并缓解遮挡导致的稀疏性,引入记忆机制以随时间累积静态高斯:
每个高斯基元关联动态属性 ,支持运动感知过滤;
对前一帧的静态记忆,先将其变换到当前自车坐标系,再执行视图过滤以移除当前视场内可见的高斯,得到过滤后记忆 ;
将 与当前重建结果 融合,得到填补当前帧重建盲区的完整场景表示;
更新记忆:保留当前帧中动态分数低于阈值 的静态高斯:
其中, 是当前帧高斯基元总数。该流式机制实现时间持久化重建,同时抑制动态伪影。
训练目标
模型通过复合损失函数优化,损失定义在 的渲染输出上,包含以下项:
:视图 的渲染图像与真值图像的 MSE 重建损失;
:视图 的 LPIPS 感知损失(Zhang et al., 2018);
:视图 的渲染动态分数与真值动态分割掩码的交叉熵损失;
:尺度监督的 Smooth-L1 损失;
其中, 是时间 的输入相机视图集合, 是时间 的新视角集合; 表示元素乘法,背景掩码 用于排除动态区域,避免优化不稳定。
实验结果分析
主要结果
Waymo 数据集结果:我们将 UniSplat 与当前主流的稀疏视角重建方法进行对比,包括 MVSplat、DepthSplat、EvolSplat和 DriveRecon。对于通用方法 MVSplat 和 DepthSplat,本文基于其官方代码库在 Waymo Open 数据集上重新训练;对于面向驾驶场景的方法 EvolSplat 和 DriveRecon,我们在验证场景上评估,并调整其输出分辨率以确保对比公平性。定量结果汇总于表 1,UniSplat 在输入视图重建和新视角合成两项任务的所有指标上,均持续优于所有基线方法。定性对比结果如图 2所示:MVSplat 和 DepthSplat 难以重建精细几何细节,且在相邻相机重叠区域存在明显伪影,而我们的方法能生成视觉连贯、质量更高的结果。此外,我们还报告了一个优化变体(标记为†)——该变体采用基于 LiDAR 点云计算的最优单相机尺度,进一步提升了性能。
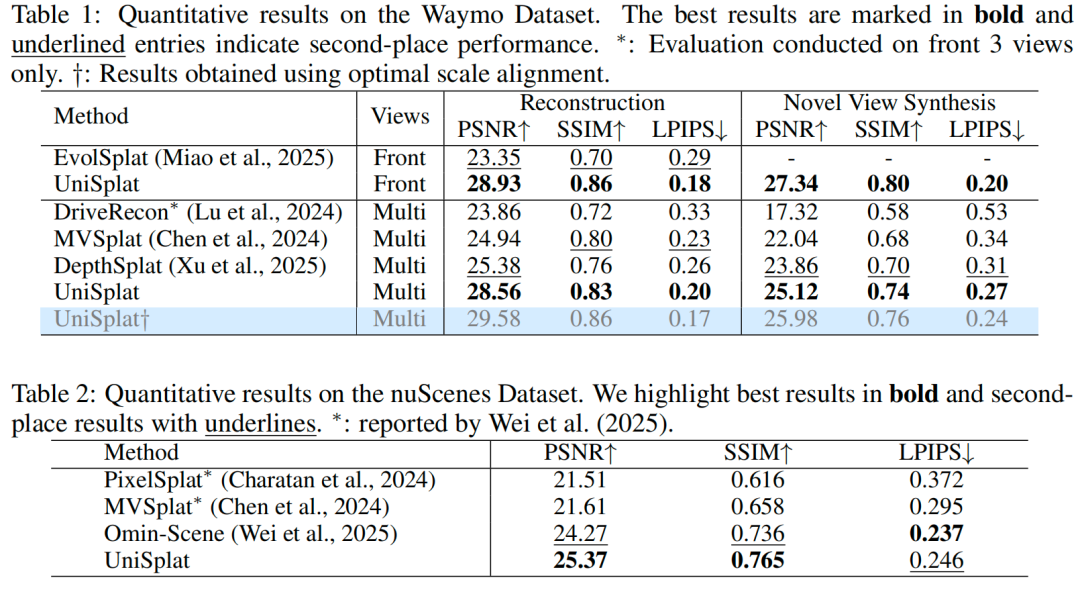

nuScenes 数据集结果:我们在 nuScenes 基准测试上评估 UniSplat。如表 2所示,UniSplat 性能超过此前的最优方法 Omni-Scene,PSNR达到 25.37 dB,较后者提升 1.10 dB。
动态感知高斯补全结果:UniSplat 可预测每个高斯基元的动态属性,无需人工标注即可在推理阶段实现场景的渐进式构建。如图 3所示:上方为无动态过滤的基线方法结果,由于动态目标的累积,出现了“重影伪影”;而我们的方法在补全缺失区域的同时,有效抑制了此类伪影。下方结果表明,UniSplat 成功补全了两种典型场景下的未观测区域:一是 Waymo 5 相机系统无法覆盖 360° 视场的区域,二是跨相机的视野盲区。此外,模型能清晰区分动态行驶车辆与静止停放车辆,证明其可有效利用时间上下文信息。

消融实验
为验证框架各组件的有效性,我们在 Waymo Open 数据集上开展消融实验,重点分析新视角合成任务的性能。为提升效率,我们对每个序列的前 20% 帧进行采样,并对 point map 采用最优尺度对齐以加速模型收敛。所有模型均在 16 块 GPU 上训练 20 个 epoch,批次大小为 32。
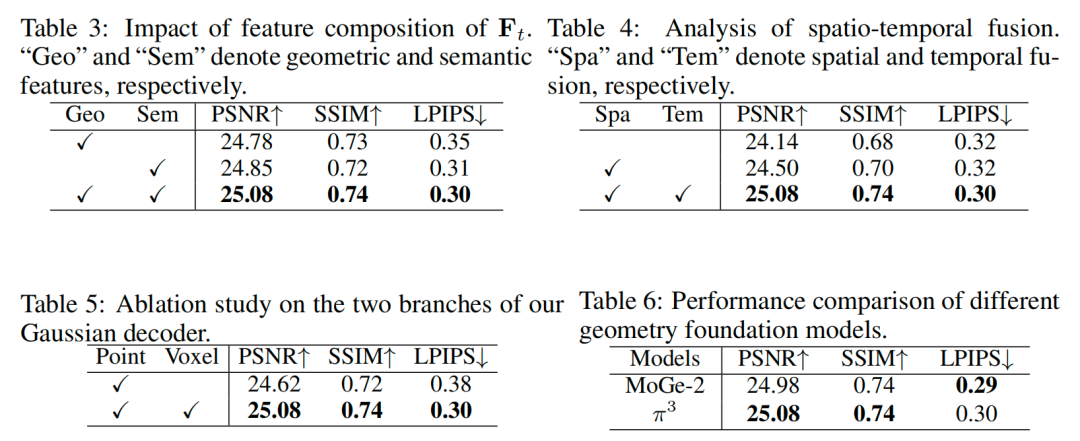
Scaffold中几何与语义特征的消融:表 3 分析了基础模型提供的几何特征(Geo)和语义特征(Sem)对Scaffold表示的贡献:缺失语义特征会导致 LPIPS 指标显著下降(误差增加 0.05),这是因为 LPIPS 依赖深度语义表示衡量感知相似度;而第 2 行与第 3 行结果显示,仅使用 DINO 语义特征时性能差距较小,说明当前大规模预训练 2D 基础模型可能已隐式捕捉了一定的几何先验。
时空融合的影响分析:我们对空间融合(Spa)和时间融合(Tem)的作用进行消融,结果如表 4 所示:第 1 行与第 2 行对比表明,在 3D 空间聚合信息的“空间Scaffold融合”,较仅依赖图像域融合的基线方法,PSNR 提升 0.36 dB,SSIM 提升 0.02;进一步加入“时间Scaffold融合”(通过自车运动 warp 和潜在Scaffold域融合引入历史上下文)后,PSNR 再提升 0.58 dB,SSIM 再提升 0.04(第 3 行)。我们还对比了“直接使用连续两帧而不进行潜在空间时间传播”的变体,该变体 PSNR 仅为 24.72 dB(性能更低),原因是其难以建模动态目标且时间上下文受限。这些结果证明,在 3D Scaffold表示内直接进行统一时空建模,对处理稀疏、低重叠相机视角和复杂动态驾驶场景具有重要意义。
双分支高斯解码器的消融:表 5 验证了双分支解码器的设计合理性:仅使用点锚定高斯(Point 分支)时,性能显著下降——PSNR 降低 0.46 dB,SSIM 降低 0.02,LPIPS 误差增加 0.08,这表明体素生成高斯(Voxel 分支)在填补稀疏覆盖区域、提升场景完整性方面至关重要。由于仅体素分支在长距离渲染任务中性能极差,所有指标均表现糟糕,因此未将其纳入对比。
几何基础模型的消融:表 6 分析了几何基础模型对框架性能的影响:将默认的 模型替换为最新的开放域几何估计方法 MoGe-2后,性能保持稳定,说明我们的方法对底层几何基础模型的选择具有鲁棒性。值得注意的是,我们未纳入代表性模型 VGGT——实证观察表明,该模型在户外驾驶场景中的泛化能力弱于 。
结论
本文提出 UniSplat——一种用于动态驾驶场景重建与新视角合成的统一前馈框架。其核心贡献在于引入“3D 潜在Scaffold”,可无缝整合多相机视频的时空融合信息。该Scaffold通过利用基础模型,编码鲁棒的几何与语义先验,支持在 3D 空间内直接进行高效融合。我们进一步设计了双分支高斯解码器,从Scaffold中生成动态感知基元,并结合流式记忆机制随时间累积静态场景内容,实现长期场景补全。
在 Waymo 和 nuScenes 数据集上的大量实验表明:UniSplat 不仅在标准设置下达到当前最优性能,还对原始相机覆盖范围外的挑战性视角具有出色的泛化能力。我们认为,该框架为未来动态场景理解、交互式 4D 内容创建及终身世界建模等研究方向,提供了极具潜力的基础。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









