



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
21年9月小米汽车成立,24年3月小米SU7发布,25年6月YU7发布。短短四年时间,小米汽车已经在新能源的红海赛道中杀出了自己的路。25年下半年,各家新势力都在卷智驾、卷性价比、卷冰箱彩电大沙发的时候,小米智驾也在悄悄迎头赶上,据说新的版本也快和大家见面了。
一个非常明显的信号便是今年小米汽车团队的论文工作颇丰,涉及VLA、世界模型、端到端等多个方面。像ORION、WorldSplat、EvaDrive、Dream4Drive等等工作业内关注都很多,小米汽车也一直在探索怎样的生成模型能在自动驾驶里面真正的落地应用。一个合理的猜测,小米新版本的量产方案会和最前沿的技术结合的比较紧密。
PS.也推荐下我们前面总结的地平线和理想智驾的工作汇总。
VLM&VLA
AdaThinkDrive
AdaThinkDrive: Adaptive Thinking via Reinforcement Learning for Autonomous Driving
论文链接:https://arxiv.org/abs/2509.13769
提出机构:清华大学, 小米汽车, 澳门大学, 南洋理工大学, 北京大学
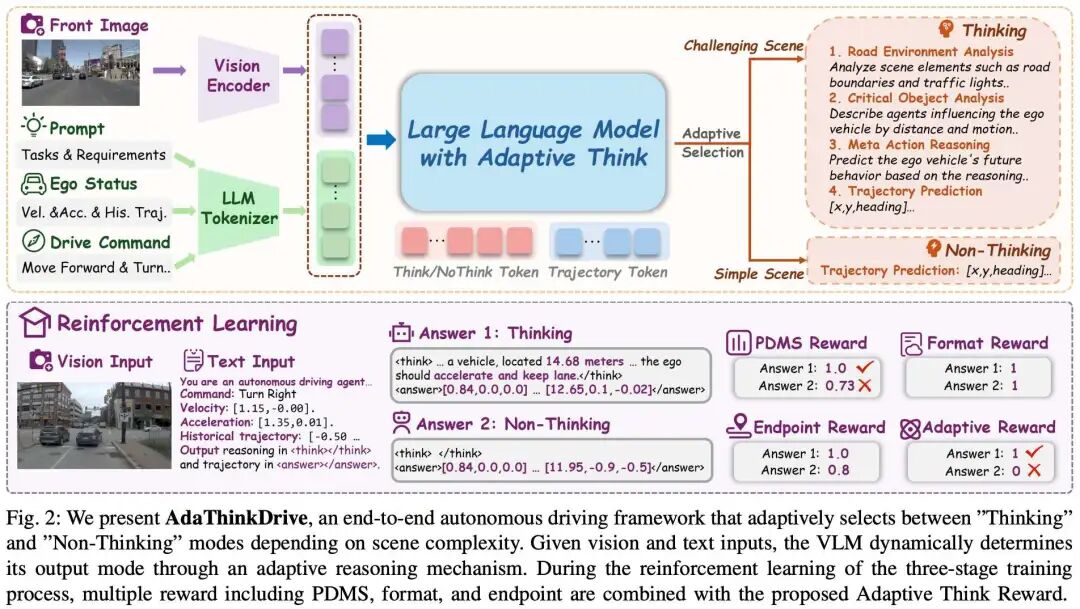
核心亮点:提出了一种名为AdaThinkDrive的自适应思维驾驶框架,首次在端到端自动驾驶中引入“快速应答/慢速思考”双模式推理机制,有效解决了传统CoT方法在简单场景中过度推理的问题,在NAVSIM基准测试中取得了90.3的PDMS,超越了当前最佳纯视觉基线,并在推理效率上提升了14%。
内容摘要:尽管思维链(CoT)推理技术已在视觉-语言-行动模型中广泛应用,并在端到端自动驾驶中展现出潜力,但现有方法在简单场景中往往引入不必要的计算开销,却未能提升决策质量。为此,论文提出AdaThinkDrive,一种具有双模式推理机制的新型VLA框架,灵感来源于人类“快思考/慢思考”认知模型。该框架首先在大规模自动驾驶场景上进行预训练,获取世界知识与驾驶常识;随后在监督微调阶段引入包含“快速应答(无CoT)”和“慢速思考(有CoT)”的双模式数据集,使模型能区分何时需要推理;进一步提出“自适应思维奖励”策略,结合GRPO,通过比较不同推理模式下的轨迹质量,奖励模型选择性使用CoT的能力。实验表明,AdaThinkDrive在NAVSIM基准测试中PDMS达到90.3,优于最佳纯视觉基线1.7分,并且在96%的复杂场景中使用CoT,在84%的简单场景中直接输出轨迹,显著提升了决策效率与准确性。该方法为自动驾驶中的自适应推理提供了新思路,并在闭环仿真中验证了其高效与可靠性。
EvaDrive
EvaDrive: Evolutionary Adversarial Policy Optimization for End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2508.09158
提出机构:新加坡国立大学, 清华大学, 小米汽车, 同济大学, 麦吉尔大学, 威斯康星大学麦迪逊分校
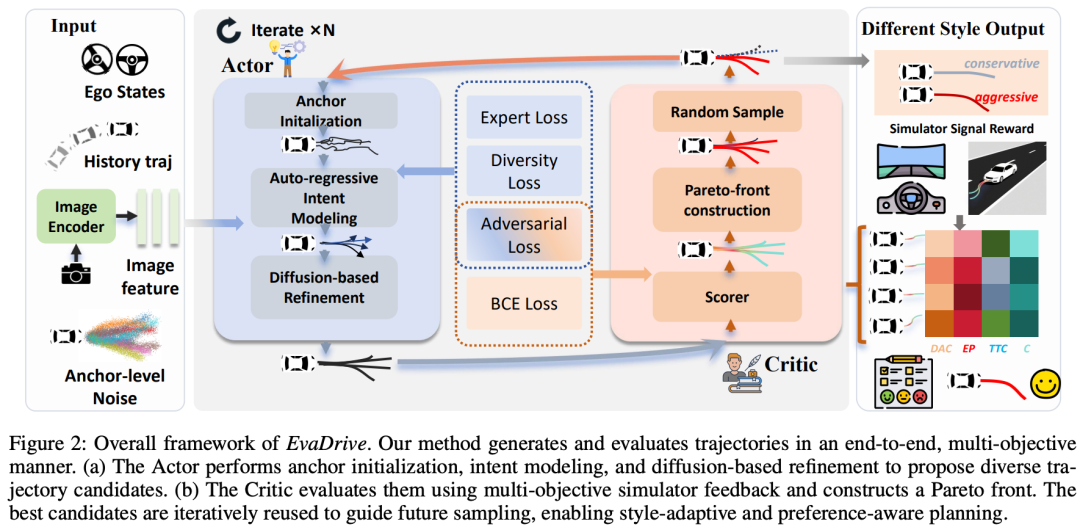
核心亮点:提出了一种名为 EvaDrive 的进化对抗策略优化框架,首次在端到端自动驾驶中实现了轨迹生成与评估的闭环共进化,通过多目标、多轮强化学习有效避免了传统方法中的标量化偏差与局部最优问题,在 NAVSIM 与 Bench2Drive 基准测试中均达到最优性能。
内容摘要:端到端自动驾驶规划面临轨迹生成与评估割裂、多目标偏好难以平衡等挑战。现有生成-评估框架缺乏闭环反馈,而强化学习方法常将多维度目标压缩为单一标量奖励,导致轨迹多样性与优化鲁棒性受限。EvaDrive 提出三大创新:1)分层规划器结合自回归意图建模与扩散式轨迹优化,兼顾时序因果性与空间灵活性;2)多轮优化机制通过帕累托前沿选择引导轨迹迭代优化,有效跳出局部最优;3)对抗策略优化构建生成器与评价器的动态博弈,在不依赖外部偏好数据的情况下生成多样化驾驶风格。实验表明,EvaDrive 在 NAVSIM v1 上取得 94.9 PDMS,超越 DiffusionDrive、DriveSuprim 等方法,并在 Bench2Drive 上达到 64.96 驾驶分数,验证了其在开环与闭环场景下的优越性能。
MTRDrive
MTRDrive: Memory-Tool Synergistic Reasoning for Robust Autonomous Driving in Corner Cases
论文链接:https://arxiv.org/abs/2509.20843
提出机构:清华大学, 小米汽车, 麦吉尔大学, 威斯康星大学麦迪逊分校
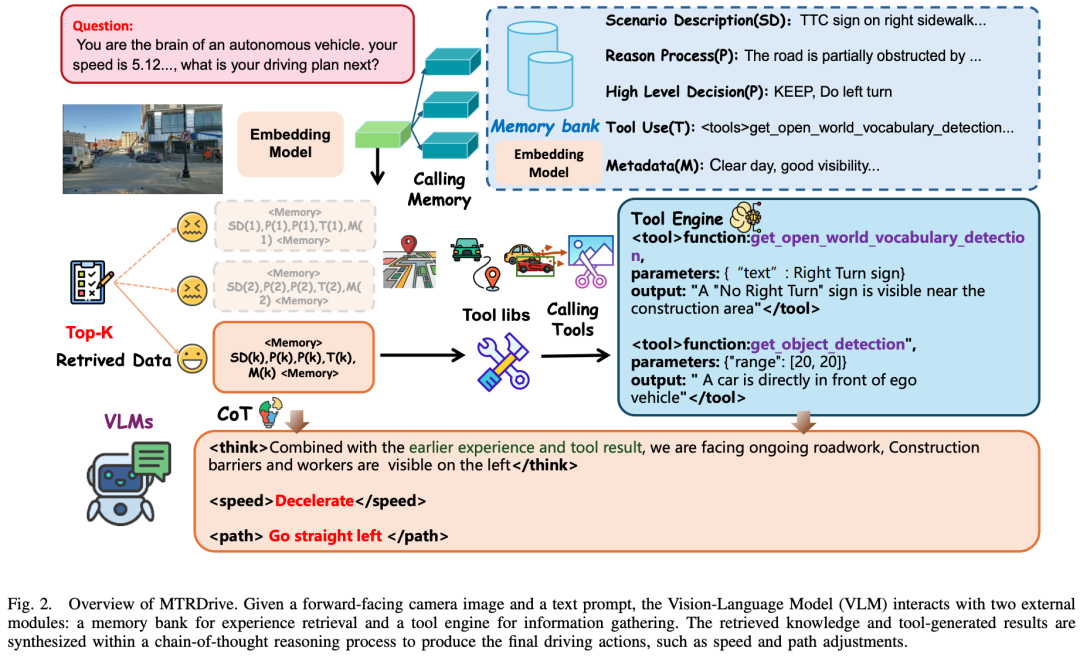
核心亮点:提出了一种名为MTRDrive的记忆-工具协同推理框架,通过引入闭环的交互式推理机制,显著提升了视觉语言模型在自动驾驶任务中的泛化能力与决策鲁棒性,有效缓解了幻觉问题,并在多个基准测试中实现了领先性能。
内容摘要:视觉语言模型在端到端自动驾驶中展现出潜力,但其在实际部署中仍存在幻觉和泛化能力不足的问题。MTRDrive提出了一种记忆-工具协同推理框架,模仿人类驾驶中的闭环认知过程。该框架包含两个核心组件:一是驾驶经验库,用于存储和检索结构化的历史驾驶场景;二是经验驱动的规划模块,通过检索相似场景的经验,引导模型调用视觉工具(如目标检测、开放词汇检测、图像裁剪)进行实时环境交互。此外,MTRDrive采用两阶段训练策略:先通过监督微调学习工具使用与记忆整合的基本语法,再通过强化学习进一步优化策略,引入格式奖励以鼓励正确使用经验。实验表明,MTRDrive在NAVSIM和自建的Roadwork-VLM基准上均表现出色,特别是在零样本泛化测试中显著优于现有方法。该方法将自动驾驶从被动感知推向主动、经验引导的推理,为实现更安全可靠的自动驾驶系统奠定了基础。
DriveMRP
DriveMRP: Enhancing Vision-Language Models with Synthetic Motion Data for Motion Risk Prediction
论文链接:https://arxiv.org/abs/2507.02948
提出机构:西湖大学, 小米汽车, 浙江大学
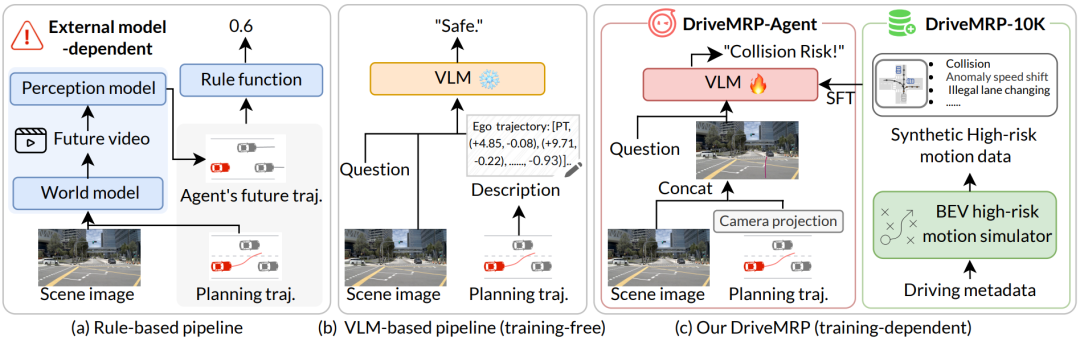
核心亮点:提出了一种创新的基于BEV的运动仿真方法,首次通过合成高风险运动数据有效增强了视觉语言模型(VLM)在自动驾驶长尾场景中的运动风险预测能力,实现了在真实世界高风险场景中的强大零样本泛化性能。
内容摘要:准确预测自动驾驶车辆在复杂动态环境中的运动风险,尤其是在数据覆盖有限的长尾场景下,是当前自动驾驶技术面临的主要挑战之一。传统基于规则的方法依赖外部模型预测其他车辆的未来位置,对感知误差敏感且缺乏可解释性;而现有基于视觉语言模型(VLM)的方法则因轨迹坐标与视觉信息之间的模态差异导致性能不佳。论文提出了两大核心贡献:1)一种BEV运动仿真方法,能够从自车、他车和环境三个维度建模风险,合成即插即用的高风险运动数据集DriveMRP-10K;2)一个VLM无关的运动风险预测框架DriveMRP-Agent,采用基于投影的视觉提示方案,将轨迹以视觉形式嵌入模型,并结合“场景理解→运动分析→风险预测”的思维链推理机制。实验表明,仅使用合成数据训练的DriveMRP-Agent在内部真实世界高风险数据集上的零样本评估准确率从基线模型的29.42%大幅提升至68.50%,展现了卓越的泛化能力。该方法为构建更安全、可解释的自动驾驶系统提供了新的技术路径。
ReCogDrive
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
原文链接:https://arxiv.org/abs/2506.08052
Code:https://github.com/xiaomi-research/recogdrive
Model & Data:https://huggingface.co/collections/owl10/recogdrive-68bafa143de172bab8de5752
提出机构:华中科技大学、小米汽车
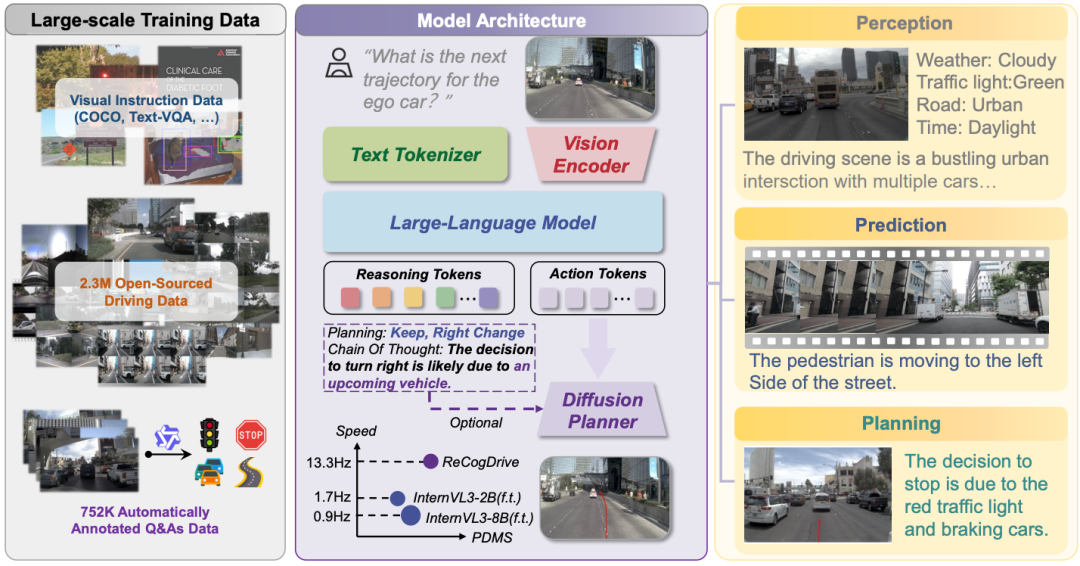
核心亮点:提出名为 ReCogDrive 的端到端自动驾驶强化认知框架,首次将视觉 - 语言模型(VLM)的认知推理与强化学习增强的扩散规划器结合,通过分层数据管道解决 VLM 领域差距问题,利用认知引导扩散规划器消除语言 - 动作模态不匹配,设计 Diffusion Group Relative Policy Optimization(DiffGRPO)提升驾驶安全性与舒适性;在 NAVSIM 基准实现 90.8 的 PDMS,仅用视觉输入超越多传感器基线,推理速度较纯文本 VLM 方法提升 7.8 倍。
内容摘要:尽管视觉 - 语言模型(VLMs)凭借世界知识与认知能力为端到端自动驾驶长尾问题提供解决方案,但现有方法常将轨迹规划转化为语言建模任务,导致输出格式违规、动作不可行及推理缓慢等问题。为此,论文提出 ReCogDrive 框架,通过融合自回归模型与扩散规划器,统一驾驶场景理解与轨迹规划。首先,设计分层数据管道(生成 - 精炼 - 质控)模仿人类驾驶认知过程,构建大规模视觉问答(VQA)数据集,为 VLM 注入驾驶先验以弥合领域差距;其次,提出认知引导扩散规划器,将 VLM 的潜在认知表征转化为连续稳定的轨迹,解决模态不匹配问题;最后,引入 DiffGRPO 强化学习阶段,基于仿真反馈优化规划器,突破模仿学习局限。实验表明,ReCogDrive 在 NAVSIM 闭环测试中 PDMS 达 90.8,Bench2Drive 场景成功率 45.45%,且在 DriveVQA 基准超越 GPT-4o 等模型,验证了其高效性与可靠性。
AgentThink
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
原文链接:https://arxiv.org/abs/2505.15298
github链接:https://github.com/curryqka/AgentThink
项目主页:https://curryqka.github.io/AgentThink.github.io/
提出机构:清华大学, 麦吉尔大学, 小米汽车, 威斯康星大学麦迪逊分校
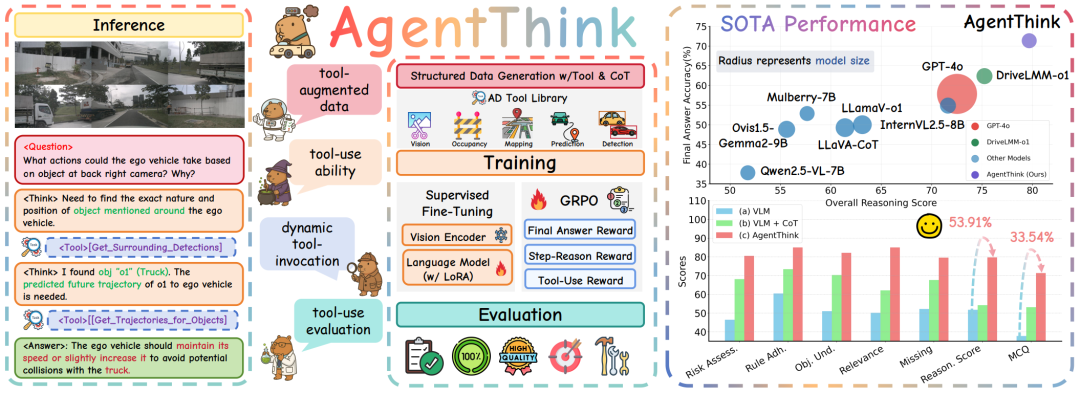
核心亮点:提出了一种名为 AgentThink 的统一框架,首次将动态、代理式工具调用与思维链推理相结合,显著提升了视觉语言模型在自动驾驶任务中的推理一致性与答案准确性,并在多个基准测试中超越了现有最先进模型,展现出强大的泛化能力与工具感知推理能力。
内容摘要:视觉语言模型在自动驾驶中展现出潜力,但仍面临幻觉、推理效率低和缺乏真实世界验证等问题。为此,研究者提出了 AgentThink,一个开创性的统一框架,首次将思维链推理与动态代理式工具调用相结合。其核心创新包括:1)结构化数据生成,构建了一个自动驾驶工具库,自动生成包含工具使用的自验证推理数据;2)两阶段训练流程,采用监督微调与分组相对策略优化,使模型具备自主调用工具的能力;3)代理式工具使用评估,引入新的多工具评估协议,系统评估模型在工具调用与使用方面的表现。实验表明,AgentThink 在 DriveLMM-o1 基准测试中将整体推理分数提升了 53.91%,答案准确率提升了 33.54%,并在零样本/少样本泛化测试中表现出强大鲁棒性,为构建可信赖、工具感知的自动驾驶模型开辟了新路径。
ORION
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
论文链接:https://arxiv.org/pdf/2503.19755
项目主页:https://xiaomi-mlab.github.io/Orion/
提出机构:华中科技大学, 小米汽车
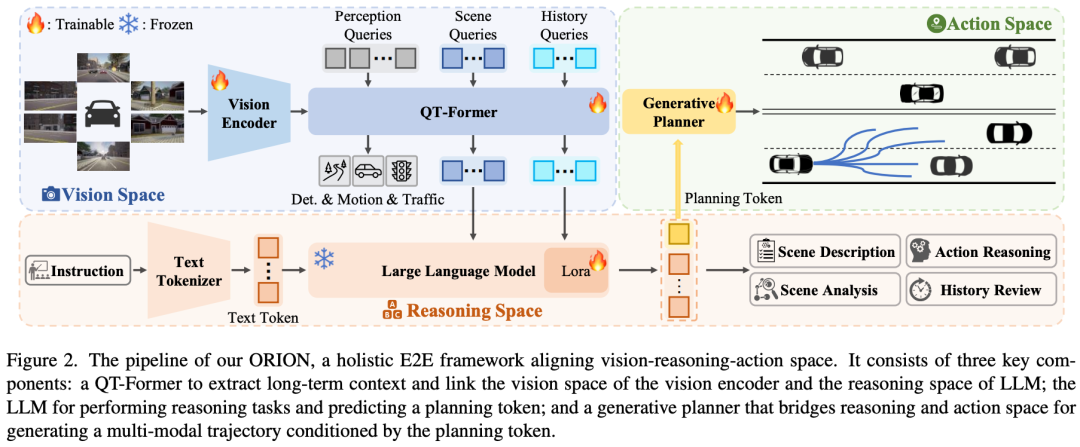
核心亮点:提出了一种名为ORION的端到端自动驾驶框架,创新性地通过视觉语言模型指导动作生成,有效解决了现有方法在语义推理空间与数值动作空间之间的对齐难题,在Bench2Drive闭环评测中显著超越现有最优方法,展现出强大的场景理解与决策能力。
内容摘要:端到端自动驾驶方法在闭循环评测中由于缺乏因果推理能力而表现不佳。尽管已有研究尝试引入视觉语言模型的强大理解与推理能力,但由于语义推理空间与轨迹动作空间之间存在差异,现有VLM方法在闭循环评测中仍表现有限。ORION提出了一种全面的端到端自动驾驶框架,通过三个核心组件实现突破:1)QT-Former,用于聚合长期历史上下文并压缩视觉特征;2)大语言模型,负责场景理解与推理,并生成规划指令;3)生成式规划器,通过变分自编码器对齐推理空间与动作空间,实现多模态轨迹预测。ORION在Bench2Drive数据集上实现了77.74的驾驶分数和54.62%的成功率,相比之前最优方法分别提升了14.28分和19.61%,展现出卓越的闭环驾驶性能。
世界模型
Dream4Drive
Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
原文链接:https://arxiv.org/abs/2510.19195
项目主页:https://wm-research.github.io/Dream4Drive/
提出机构:北京大学,小米汽车,华中科技大学
核心亮点:
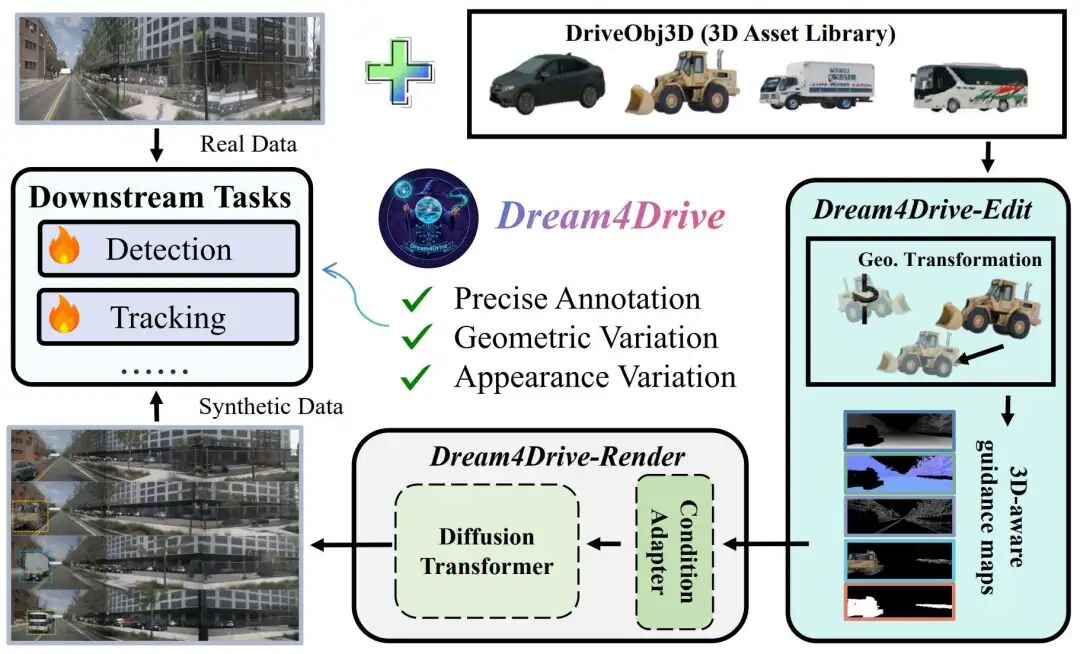
提出Dream4Drive,首个以3D感知引导图为驱动的自动驾驶合成数据生成框架,突破传统布局生成限制
引入大规模3D资产数据集DriveObj3D,覆盖典型驾驶场景类别,支持多样化视频编辑
在公平实验设定下(同等训练轮数),仅用不到2%的合成样本即显著提升感知任务性能
提出多条件融合适配器与3D感知渲染机制,实现几何一致的多视角视频生成
内容摘要:针对现有自动驾驶世界模型在合成数据生成中存在的控制粒度不足与评估不公平问题,本论文提出Dream4Drive——一种面向感知任务优化的3D感知合成数据生成框架。该框架首先将输入视频分解为深度、法线、边缘等多类3D感知引导图,进而将来自DriveObj3D的高质量3D资产渲染至引导图中,并通过微调的扩散Transformer生成具有几何一致性与视觉真实感的多视角视频。与传统方法依赖BEV布局或3D边界框不同,Dream4Drive通过密集引导图实现实例级、跨视角一致的视频编辑,有效增强合成数据的多样性与真实性。在实验设计上,论文强调公平比较:所有方法均在相同训练轮数(1×, 2×, 3×)下评估。研究显示,现有方法如Panacea、SubjectDrive在双倍训练轮数下虽优于仅使用真实数据的基线,但在对齐轮数后优势消失;而Dream4Drive仅需插入420个样本(不足真实数据2%),即可在检测与跟踪任务中稳定提升性能。例如在1×轮数下,mAP从34.5提升至36.1,NDS从46.9提升至47.8;在2×轮数下,mAP进一步提升至39.7,超越所有对比方法。此外,论文还系统分析了插入位置、距离与资产来源对性能的影响,揭示了合成数据增强中的关键因素。
ViSE
ViSE: A Systematic Approach to Vision-Only Street-View Extrapolation
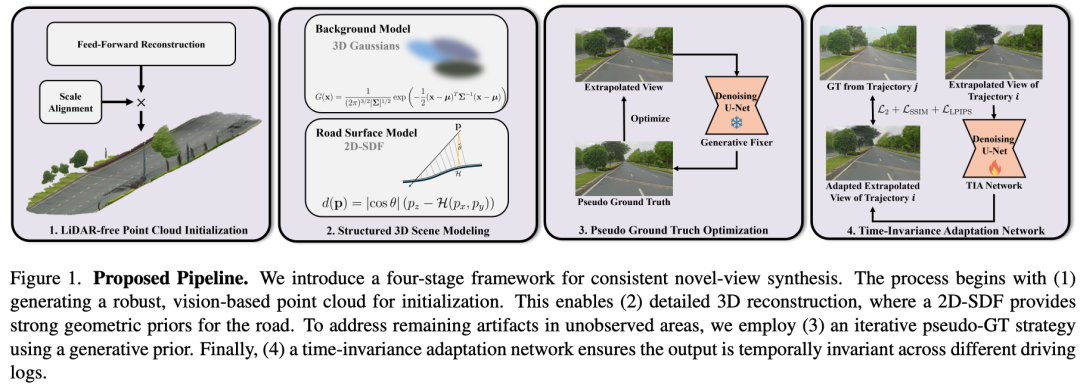
原文链接:https://arxiv.org/abs/2510.18341
提出机构:小米汽车
核心亮点:提出了一套完整的四阶段视觉街景外推框架,首次在无LiDAR条件下实现了高精度、几何一致的外推视图合成,在ICCV 2025 RealADSim-NVS挑战赛中取得第一,综合得分0.441。
内容摘要:针对自动驾驶仿真中视图外推的几何失真与纹理退化问题,ViSE构建了一个系统化的视觉重建流程。首先,通过视觉生成的伪LiDAR点云实现场景初始化,避免局部最优;其次,提出二维符号距离函数(2D-SDF)对道路表面进行降维建模,增强几何一致性;随后,引入生成式伪真值监督机制,通过扩散模型修复外推区域的视觉伪影;最后,设计时序无关适应网络(TIA-Net),消除不同记录时段带来的光照、阴影等瞬时干扰。整个流程仅依赖视觉输入,无需激光雷达或人工标注。从实验数据来看,ViSE在RealADSim-NVS基准测试中PSNR达到18.228,SSIM为0.514,LPIPS降至0.288,显著优于其他参赛方案。消融实验进一步验证了各模块的有效性,特别是2D-SDF与伪真值生成分别将LPIPS改善了2.6%与20%,而TIA网络最终将综合性能提升至领先水平,证明了该方法在复杂外推场景中的鲁棒性与实用性。
WorldSplat
WorldSplat: Gaussian-Centric Feed-Forward 4D Scene Generation for Autonomous Driving
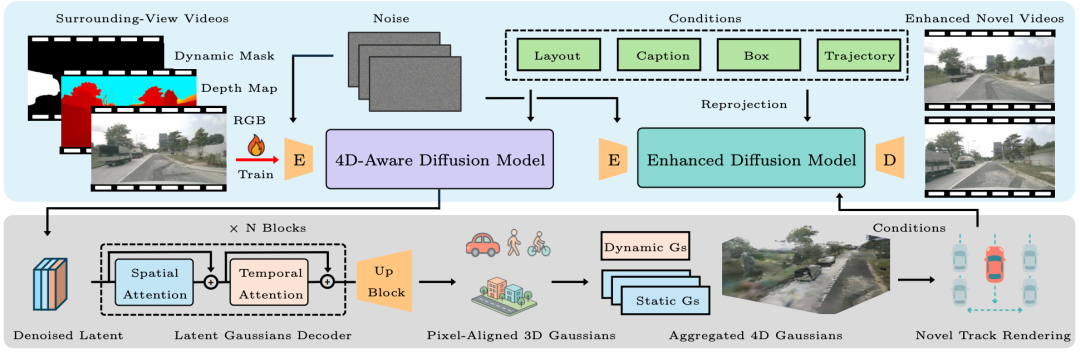
论文链接:https://arxiv.org/abs/2509.23402
项目主页:https://wm-research.github.io/worldsplat/
提出机构:南开大学, 小米汽车, 南京大学(苏州校区)
核心亮点:提出了一种名为 WorldSplat 的高斯中心化前馈式4D场景生成框架,首次将生成式扩散模型与显式动态场景重建相结合,有效解决了自动驾驶场景生成与重建之间的困境,能够生成高质量、时空一致的多视角驾驶视频,在nuScenes基准测试中表现优异,优于多种现有生成与重建方法。
内容摘要:自动驾驶场景的生成与重建是提升自动驾驶系统可扩展性和可控性的关键。现有方法存在生成视角稀疏、3D一致性不足或缺乏生成能力等问题。WorldSplat 提出一种前馈式框架,通过三个核心模块实现高质量4D场景生成:1)4D感知潜在扩散模型,融合多模态控制信号(如道路草图、目标框、文本描述和自车轨迹),生成包含RGB、深度和语义信息的潜在表示;2)潜在高斯解码器,将潜在表示转换为像素对齐的3D高斯,并通过静态-动态分解构建统一的4D高斯场景表示,支持任意视角的实时渲染;3)增强扩散细化模型,对渲染视频进行细节修复与质量提升,增强时空一致性。该方法在nuScenes数据集上取得最优的FVD与FID指标,并在下游任务(如3D检测与BEV分割)中显著缩小领域差距,展现出强大的实用价值。
ExtraGS
ExtraGS: Geometric-Aware Trajectory Extrapolation with Uncertainty-Guided Generative Priors
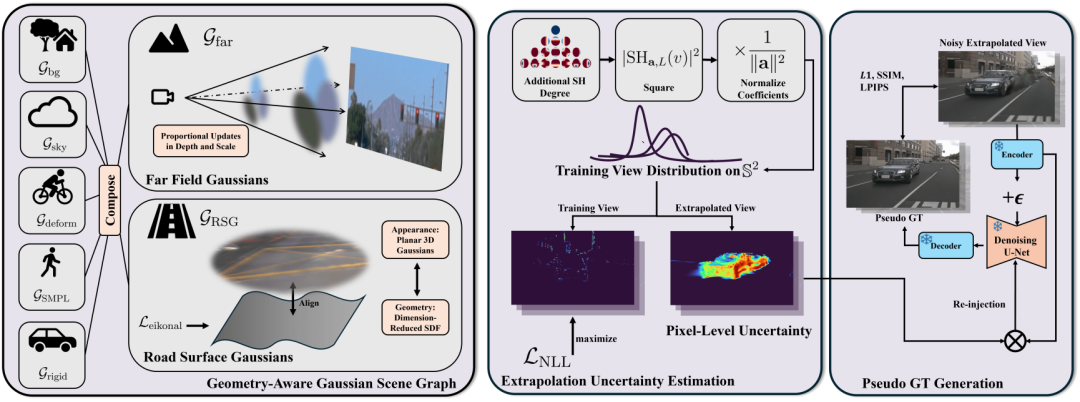
原文链接:https://arxiv.org/abs/2508.15529
项目主页:https://wm-research.github.io/extrags
提出机构:伊利诺伊大学厄巴纳 - 香槟分校, 小米汽车
核心亮点:提出了一种融合几何先验与生成先验的轨迹外推框架,通过新型场景表示设计与不确定性引导机制,显著提升外推视图的几何一致性与视觉真实感,在多种多相机配置与生成先验下均表现优异。
内容摘要:针对驾驶场景中外推视图合成中几何失真与生成噪声的挑战,ExtraGS在神经场景图(NSG)框架中引入了两种新的高斯节点:Road Surface Gaussians(RSG)结合降维符号距离函数(SDF)与3D高斯,强化道路表面的局部平面约束;Far Field Gaussians(FFG)通过可学习缩放因子联合调制位置与尺度,提升远处物体的优化效率。此外,提出基于球谐函数的自监督不确定性估计方法,能够区分外推噪声与场景固有特征,实现生成先验的精准选择性融合。框架支持即插即用多种生成模型,并在训练中引入伪颜色编码层以缓解生成图像的颜色偏移问题。实验表明,ExtraGS在Waymo与nuScenes数据集上均达到领先水平,在无需额外条件输入的情况下,Waymo上的NTA-IoU与NTL-IoU分别达到0.592与58.49,nuScenes上的外推FID@3m降至77.19,同时保持原始轨迹的高保真渲染质量,验证了其在外推任务中的有效性与泛化能力。
Genesis
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
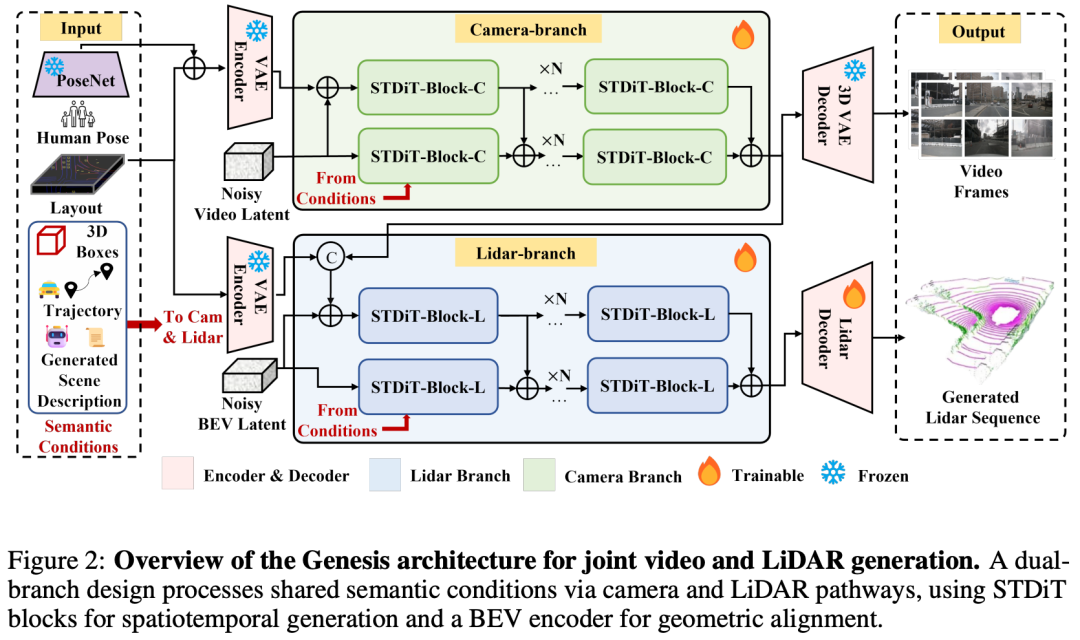
论文链接:https://arxiv.org/abs/2506.07497
github链接:https://github.com/xiaomi-research/genesis
提出机构:华中科技大学, 小米汽车
核心亮点:提出了一种名为Genesis的统一多模态生成框架,首次实现了多视角驾驶视频与LiDAR点云序列的联合生成,并在时空一致性与跨模态对齐方面取得突破,显著提升了自动驾驶仿真数据的真实性与实用性。
内容摘要:生成多样化、真实的驾驶场景对于提升自动驾驶系统的鲁棒性与安全性至关重要。然而,现有方法多局限于单一模态(视频或LiDAR)的生成,缺乏跨模态的一致性,且语义控制能力有限。Genesis提出了一种统一的双分支架构,通过共享条件输入联合生成多视角视频与LiDAR序列。其核心创新包括:1)统一的多模态生成架构,利用共享的BEV特征与条件输入实现视频与LiDAR的紧密对齐;2)DataCrafter结构化语义描述模块,基于视觉语言模型生成场景级与实例级描述,增强生成内容的可控性与语义一致性;3)在nuScenes基准测试中,Genesis在视频生成(FVD 16.95,FID 4.24)与LiDAR生成(Chamfer距离 0.611)方面均达到最优性能,并能有效提升下游任务(如BEV分割与3D检测)的准确率。
Uni-Gaussians
Uni-Gaussians: Unifying Camera and Lidar Simulation with Gaussians for Dynamic Driving Scenarios
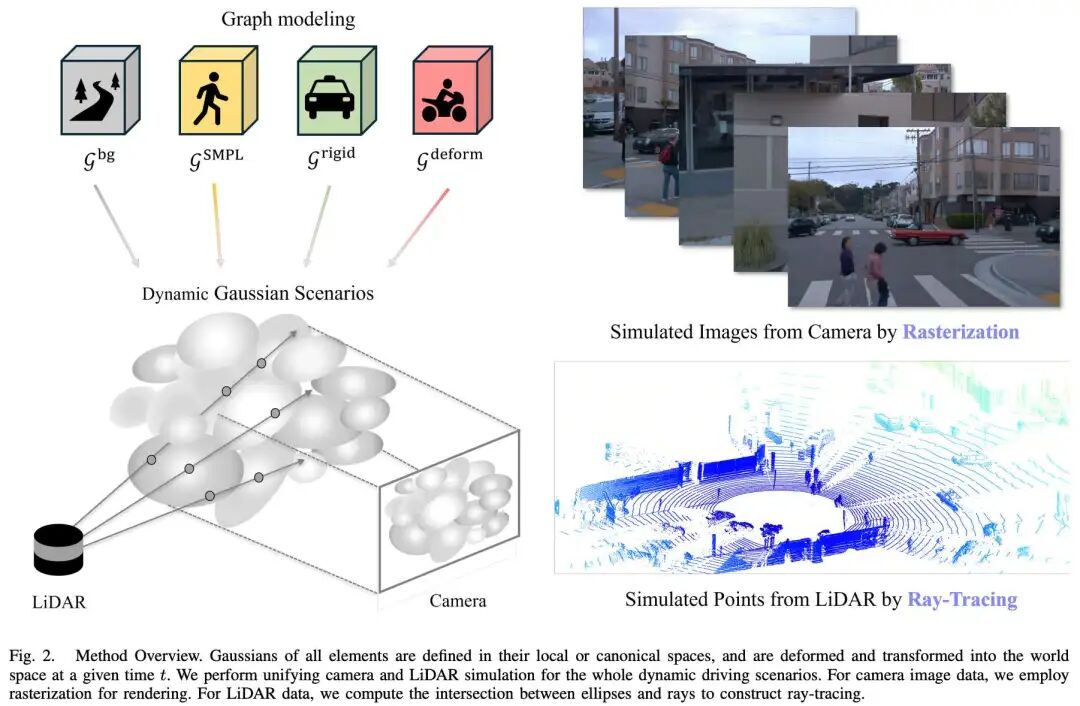
论文链接:https://arxiv.org/abs/2503.08317
提出机构:InnoHK Centers, 小米汽车
核心亮点:提出了一种名为 Uni-Gaussians 的统一高斯表示方法,首次通过结合光栅化与光线追踪的混合渲染策略,实现了动态驾驶场景中相机与LiDAR数据的高效、高保真仿真,显著优于现有方法,并在公开数据集上验证了其优越性。
内容摘要:在自动驾驶仿真中,如何统一表示并高效渲染多传感器数据(如相机图像与LiDAR点云)是一个关键挑战。传统NeRF方法虽能统一表示,但渲染速度慢;而基于高斯泼溅的方法虽快,却难以准确模拟LiDAR等非线性传感器。本文提出 Uni-Gaussians,采用统一的2D高斯原语表示动态场景,并针对不同传感器特性采用差异化渲染策略:对图像数据使用光栅化以保持高效,对LiDAR数据则采用高斯光线追踪以匹配其主动感知机制。此外,方法引入场景图建模,将场景分解为静态背景、刚性车辆与非刚性行人等动态实体,进一步提升仿真真实感。实验在Waymo数据集上进行,结果表明该方法在LiDAR点云和相机图像的仿真质量上均优于当前最优方法,并在新视角合成中展现出更好的泛化能力。
CoGen
CoGen: 3D Consistent Video Generation via Adaptive Conditioning for Autonomous Driving
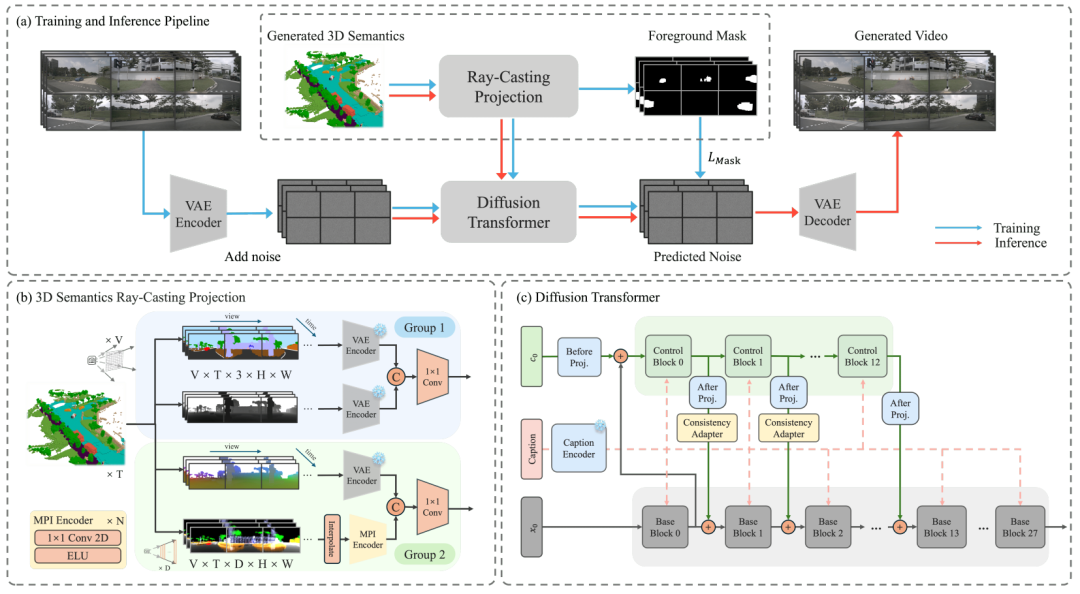
论文链接:https://arxiv.org/pdf/2503.22231
提出机构:南京大学, 小米汽车, 南开大学, 北京大学
核心亮点:提出了一种名为CoGen的空间自适应生成框架,通过引入高质量的3D语义条件与一致性适配模块,显著提升了自动驾驶场景视频生成的3D一致性与视觉真实感,为自动驾驶仿真提供了可靠且可控的高质量视频生成方案。
内容摘要:自动驾驶系统的训练依赖于大量多样化数据,而真实数据的采集与标注成本高昂。为此,基于生成模型的高质量驾驶场景合成方法逐渐成为研究热点。然而,现有方法多依赖2D布局条件(如HD地图与边界框),在多视角视频生成中难以保持严格的3D一致性。CoGen框架从两个方面进行改进:1)提出一种时序3D语义条件生成器,通过体素化语义表示与射线投影生成四种细粒度3D条件(语义图、深度图、坐标图、多平面图像),替代传统的2D布局,显著增强空间一致性;2)设计轻量级一致性适配器,融合空间与时序卷积及注意力机制,提升模型对多条件输入的鲁棒性与帧间运动连贯性。此外,还引入基于前景掩码的损失函数,增强前景物体(如车辆、行人)的细节生成质量。实验在nuScenes数据集上进行,CoGen在FVD等指标上达到最优,生成视频在下游任务(如3D检测与BEV分割)中也表现出优越的实用性。
MiLA
MiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving
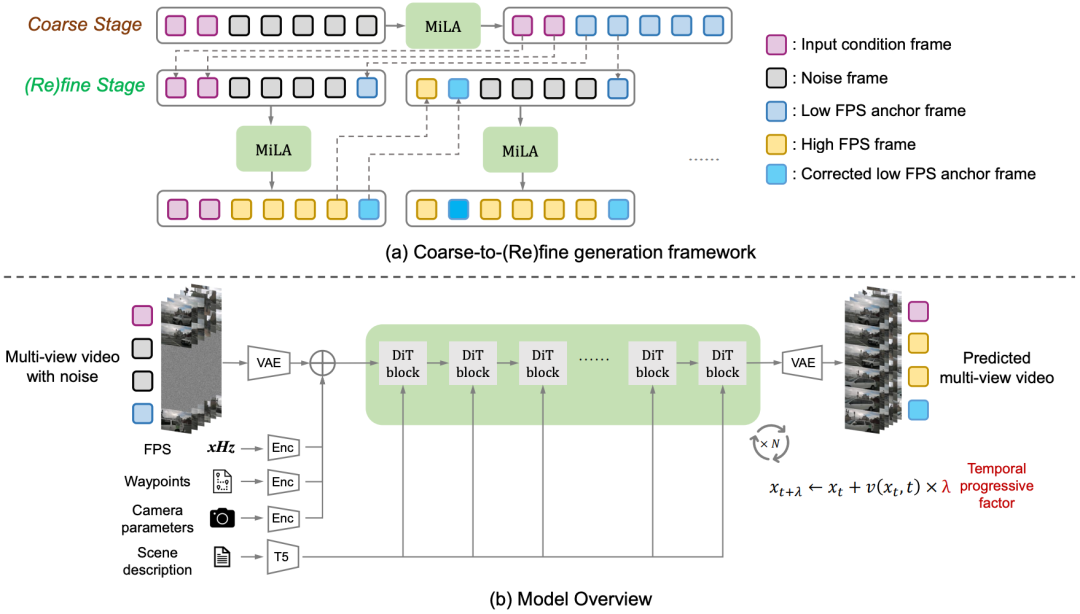
论文链接:https://arxiv.org/abs/2503.15875
项目主页:https://github.com/xiaomi-mlab/mila.github.io
提出机构:南京大学, 小米汽车, 西湖大学
核心亮点:提出了一种名为MILA的多视角高保真长期视频生成世界模型,首次在自动驾驶场景中实现了长达一分钟的高质量、多视角、时序一致的视频生成,显著缓解了长视频生成中的误差累积与场景退化问题,并在nuScenes数据集上取得了最先进的生成效果。
内容摘要:自动驾驶系统的数据驱动方法虽已取得显著进展,但稀有场景数据的收集仍面临高成本挑战。世界模型通过合成标注视频数据为训练提供了可行路径,然而现有方法在生成长时间视频时难以避免误差累积和场景一致性问题。MILA提出了一种“粗到精”的生成框架,首先生成低帧率的关键帧,再通过插值模型生成高帧率视频,并通过联合去噪与校正模块(JDC)和时间渐进去噪调度器(TPD)提升视频质量与一致性。该方法在nuScenes数据集上显著优于现有方法,在FID与FVD指标上达到最优,并展示了与商业求解器相当的生成控制能力。
深度估计
Pixel-Perfect Depth
(NeurIPS 2025)Pixel-Perfect Depth with Semantics-Prompted Diffusion Transformers
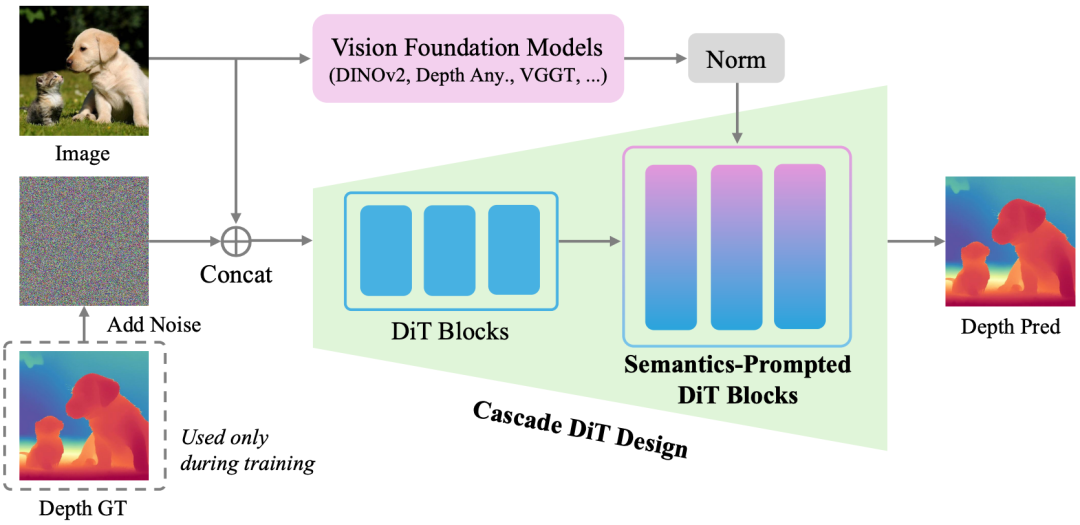
原文链接:https://arxiv.org/abs/2510.07316
主页链接:https://pixel-perfect-depth.github.io/
github链接:https://github.com/gangweix/pixel-perfect-depth
提出机构:华中科技大学、小米汽车、浙江大学
核心亮点:提出了一种基于像素空间扩散生成的单目深度估计模型,通过语义提示扩散Transformer(SP-DiT)与级联DiT设计,有效规避了VAE压缩引入的飞行像素问题,在边缘细节重建和点云质量上实现显著提升,并在五个主流基准测试中超越所有已发布的生成式方法。
内容摘要:当前基于生成模型的单目深度估计方法(如Marigold)通常依赖Stable Diffusion的潜在空间扩散,需通过VAE压缩深度图,导致边缘模糊和飞行像素。Pixel-Perfect Depth创新地在像素空间直接执行扩散生成,避免VAE带来的几何失真。为解决像素空间生成的高复杂度,论文引入SP-DiT,将预训练视觉基础模型(如DINOv2、Depth Anything v2)的语义表征融入扩散过程,增强全局结构一致性;同时设计级联DiT,通过动态调整令牌数量,以粗到细的方式优化计算效率与细节生成。模型在Hypersim等高精度合成数据集上训练,并采用流匹配(Flow Matching)作为生成核心,支持零样本泛化至真实场景。实验数据表明,Pixel-Perfect Depth在NYUv2、KITTI等五个基准测试中,绝对相对误差(AbsRel)最低达4.1%,δ1准确率最高至97.7%,显著优于Marigold等现有生成模型;在边缘感知点云评估中,其Chamfer距离仅为0.08,远低于其他方法,验证了其在复杂场景中生成无飞行像素点云的卓越能力。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频学习官网:www.zdjszx.com

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









