



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
编辑 | 自动驾驶之心
理想汽车自去年端到端+VLM双系统量产以来,已顺利跻身国内智驾一梯队,这两年在学术工作和量产方案上也一直处于领先的地位,今年更是主推VLA量产的中坚力量。随着具身智能和大模型的又一轮技术爆发,这家“专注于智能电动车的新兴品牌”正从汽车新势力向AI企业稳步迈进。
量产方面,全新的VLA司机大模型采用创新的“VLA架构”,在端到端模仿学习的基础上进一步升级。VLA司机大模型具备空间理解能力、思维能力、沟通与记忆能力以及行为能力。技术层面使用了Diffusion、强化学习、MoE、CoT、RAG等等。柱哥前一段时间也试驾体验了理想i6,可圈可点,全程基本上没有接管,语音指令超车也很丝滑,地库漫游自动泊车,自动识别地库出口做的都很不错。在一个非结构化的道路上由于对向来车未做礼让,在已经侵占本车道后停车的情况下卡在了原地,问题也不大。
同时理想在学术上的探索也做的很深入,提出了TransDiffuser、World4Drive、ReflectDrive等多个引起业内讨论热情的方案。在这篇文章中,自动驾驶之心的原创作者团队花费了不少心思整理了理想汽车 2025 年的一些创新性工作,今天就带着读者们一起回顾一下。
PS.也推荐下从地平线自动驾驶2025年的工作,我们看到了HSD的野心
整体上来说,理想在Diffusion轨迹生成、世界模型(场景生成+3DGS重建)和VLA上探索较多,这也侧面印证了MindVLA的技术架构。
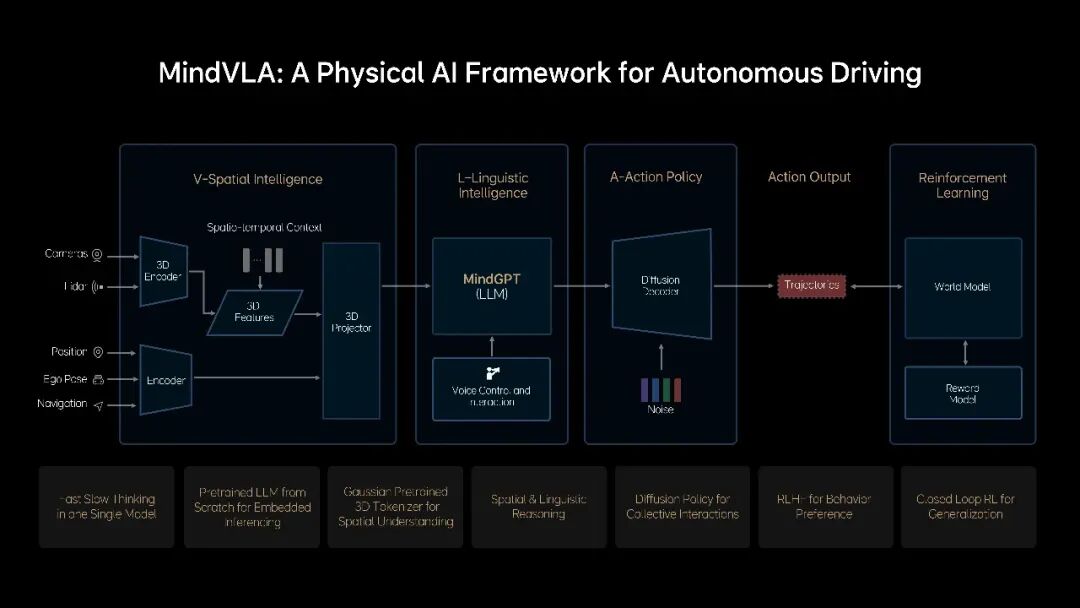
技术思路上,世界模型主要用于闭环仿真以及闭环强化学习,辅助Action的学习。我们也注意到,理想在大模型、具身智能领域也开始有工作推出。在智能驾驶的下半场,理想也在寻求新的突破,正如我们在开头所说,人工智能是理想汽车发展的新锚点。
一、VLA & VLM
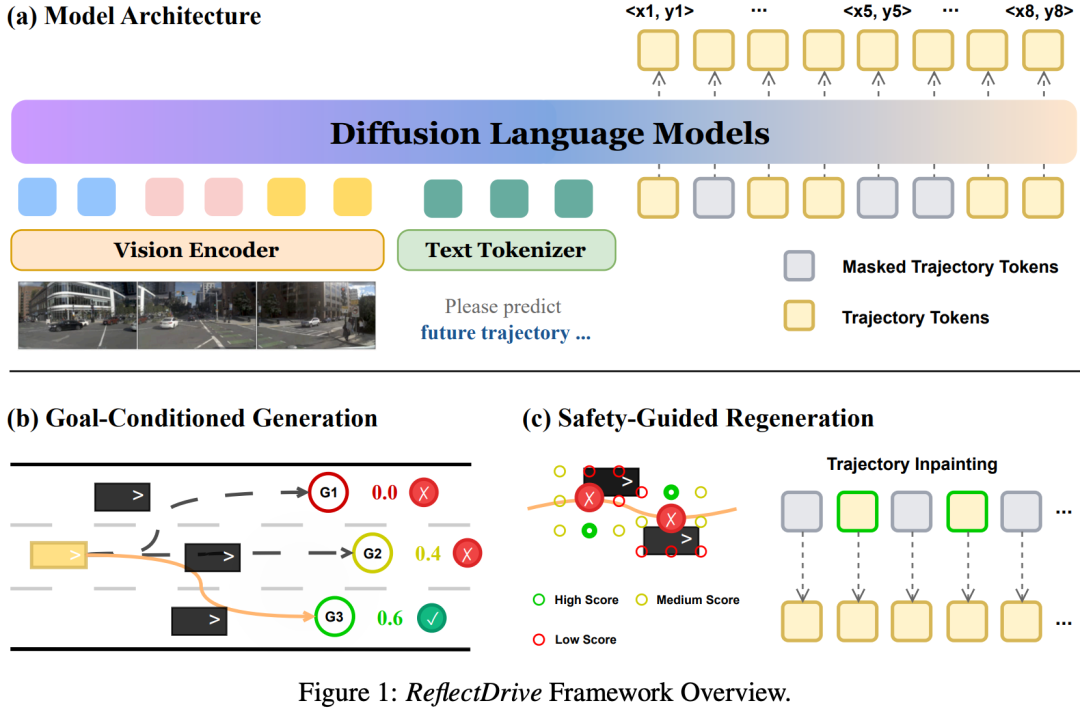
1. ReflectDrive
Discrete Diffusion for Reflective Vision-Language-Action Models in Autonomous Driving
论文链接:https://arxiv.org/abs/2509.20109
项目主页:https://github.com/pixeli99/ReflectDrive
提出机构:理想汽车, 清华大学
一句话总结:VLA目前迫切需要做到的是L模态和A模态的融合,一种更容易scaling的统一的架构,同时还要做到高效生成。为应对这些挑战,理想和清华的团队提出ReflectDrive——一种新型学习框架,通过离散扩散的反思机制实现安全轨迹生成。
核心贡献:
首次将离散扩散应用于端到端自动驾驶轨迹生成,并将其集成到VLA模型中以实现可扩展训练。
提出反思机制——一种专为离散扩散去噪过程设计的新型推理阶段引导框架,将外部安全验证与高效离散令牌优化相结合。
在真实世界驾驶基准测试集上对该方法进行评估,证明该框架能够在不影响行为连贯性的前提下,强制满足严格的安全约束。
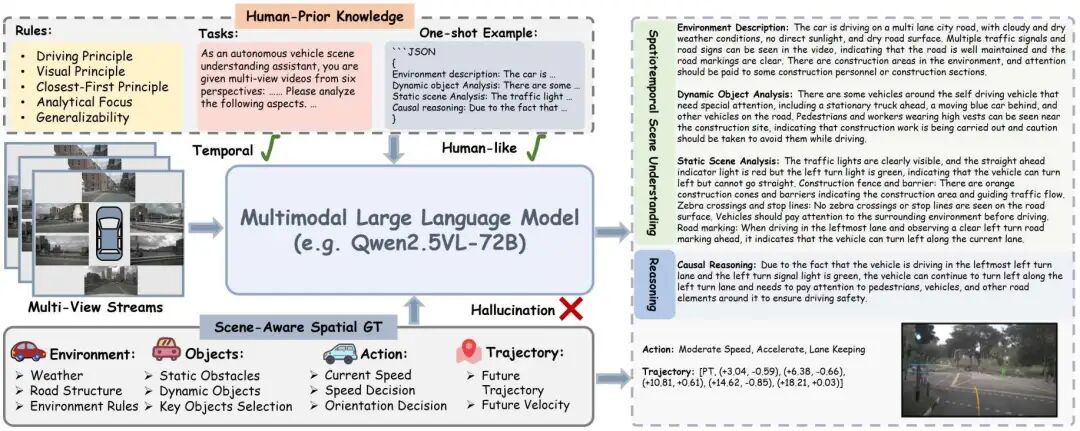
2. OmniReason
OmniReason: A Temporal-Guided Vision-Language-Action Framework for Autonomous Driving
论文链接:https://arxiv.org/abs/2509.00789
提出机构:香港科技大学(广州), 理想汽车, 香港科技大学
一句话总结:构建了用于模型训练的大规模VLA数据集OmniReason-Data,进一步提出了OmniReason-Agent架构。
核心贡献:
引入了OmniReason-nuScenes和OmniReason-Bench2Drive两个全面的VLA数据集,强调基于空间和时间上下文的因果推理,覆盖了多样且复杂的驾驶场景。通过融合人类先验知识、动态场景的分步推理以及详细的上下文感知描述,OmniReason树立了自动驾驶研究中可解释性与真实性的新标杆。
设计了基于模板的标注框架,建立在结构化场景分析之上,能够自动生成高质量、可解释的语言-动作对,适用于多样驾驶场景。该方法确保了监督的准确性,减少了幻觉现象,并提供了丰富的多模态推理信息,适合模型训练和全面评估。
提出了OmniReason-Agent,一种融合时间性三维知识和因果推理的端到端VLA架构,通过知识蒸馏将专家决策模式和自然语言推理注入模型,实现上下文感知且高度可解释的自动驾驶行为。
在开环规划和驾驶视觉问答(VQA)基准上的大量实验与消融研究表明,OmniReason-Data和OmniReason-Agent在安全、舒适和解释质量指标上均达到最先进水平。该方法显著缩小了自动驾驶车辆与人类驾驶车辆之间的差距,提升了真实场景下自动驾驶的可靠性和理解能力。
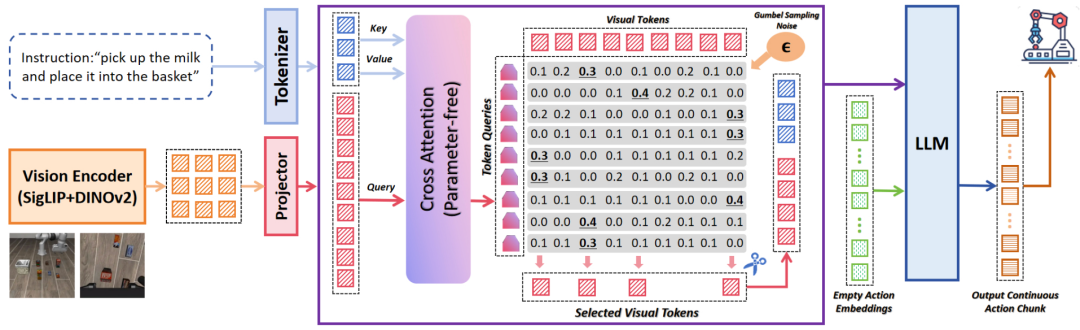
3. LightVLA
(具身智能)The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
论文链接:https://arxiv.org/abs/2509.12594
项目主页:https://liauto-research.github.io/LightVLA
提出机构:理想汽车, 清华大学, 中国科学院
一句话总结:LightVLA是一种面向视觉-语言-动作(VLA)模型的、简单而有效的可微分token剪枝框架。尽管VLA模型在执行真实世界机器人任务中展现出卓越能力,但其在资源受限平台上的部署往往受限于基于注意力机制的海量视觉token计算开销。
核心贡献:
LightVLA通过自适应、性能驱动的视觉token剪枝攻克这一难题:它生成动态查询以评估视觉token的重要性,并采用Gumbel softmax实现可微分的token选择。经过微调,LightVLA学会在执行任务时保留信息量最大的视觉token,同时剔除无关token,从而实现效率与性能的双重提升。尤为关键的是,LightVLA无需依赖启发式的“魔术数字”且不引入额外可训练参数,使其能够兼容现代推理框架。
实验结果表明,在LIBERO基准测试的多种任务中,LightVLA均优于不同VLA模型及现有token剪枝方法,以显著降低的计算开销实现了更高的成功率。具体而言,LightVLA在计算量(FLOPs)和延迟上分别降低59.1%与38.2%,同时任务成功率提升2.6%。此外,我们还探索了基于可学习查询的token剪枝方法LightVLA*(引入额外可训练参数),该方法同样取得了令人满意的性能。
本研究揭示:当VLA模型追求最优性能时,LightVLA能够自发地从性能驱动视角进行token剪枝。据我们所知,LightVLA是首个将自适应视觉token剪枝应用于VLA任务并同步优化效率与性能的工作,标志着向高效、强大且实用的实时机器人系统迈出关键一步。
4. DriveAgent-R1
DriveAgent-R1: Advancing VLM-based Autonomous Driving with Active Perception and Hybrid Thinking
论文链接:https://arxiv.org/abs/2507.20879
提出机构:上海期智研究院, 理想汽车, 同济大学, 清华大学
一句话总结:DriveAgent-R1 是一款为解决长距离、高层级行为决策而设计的自动驾驶Agent。当前VLM在自动驾驶领域的潜力,因其短距离的决策模式和被动的感知方式而受到限制,尤其在复杂环境中可靠性不足。
核心贡献:
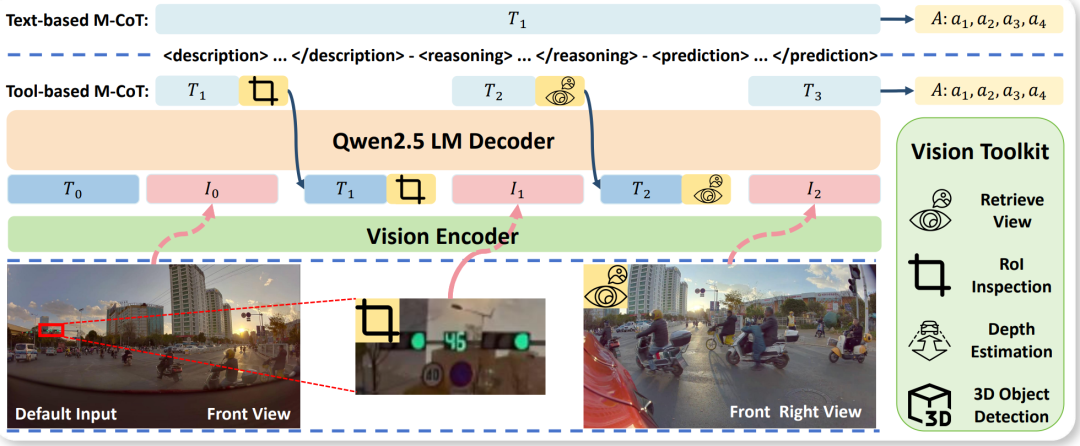
业界首个基于强化学习的智能思维架构: 我们首次在自动驾驶智能体中实现并提出了混合思维架构。DriveAgent-R1能够根据驾驶场景的复杂度,在高效的纯文本多模态思维链 Text-based M-CoT和基于视觉工具辅助多模态思维链 Tool-based M-CoT之间自适应切换,从而智能地适应不同的驾驶场景。
引入主动感知概念: 我们将“主动感知”的概念引入到基于VLM的自动驾驶中,为智能体配备了一个强大的视觉工具箱,使其能够在不确定的环境中主动探索,显著增强其感知鲁棒性。
完整的三阶段渐进式训练策略: 我们设计了一套完整的、以强化学习为核心的三阶段渐进式训练策略,并建立了一套全面的评估体系,用以评估模型的预测准确性、推理质量和自适应模式选择能力。
在挑战性数据集上取得SOTA性能: 在极具挑战性的SUP-AD数据集上,我们的方法取得了SOTA性能,甚至超越了如Claude 4 Sonnet,Gemini2.5 Flash 等前沿多模态大模型 。
5. DriveAction
DriveAction: A Benchmark for Exploring Human-like Driving Decisions in VLA Models

论文链接:https://arxiv.org/abs/2506.05667
Benchmark:https://huggingface.co/datasets/LiAuto-DriveAction/drive-action
提出机构:理想汽车
一句话总结:理想汽车开源的国内行车场景VLA数据集。
核心贡献:
广泛覆盖驾驶场景:DriveAction数据集源自量产自动驾驶车辆内部测试用户主动收集的真实世界数据,与以往依赖自收集或开源数据的基准不同,它覆盖了中国148个城市以及所有量产车型的记录。通过多轮人工筛选和质量控制,确保了驾驶场景和动作的全面性和代表性。该数据集涵盖了7大关键场景类别,包括匝道/侧路合并/分离、导航/效率驱动的变道、绕行弱势道路使用者、复杂路口等。每个场景都关联了多种细粒度动作,如变道、减速、绕行等,能够详细分析不同驾驶情况下的决策过程。
与人类驾驶偏好一致的真实标注:DriveAction的动作标签直接来源于用户的实时驾驶操作,能够准确捕捉驾驶员决策时的真实意图。为了与端到端大型模型的输出粒度匹配,这些标签被离散化为高级动作,更好地反映了人类驾驶决策的分类性质。所有标签都经过多轮人工验证,排除了错误、不合理或非法的行为,如意外的控制输入、与交通环境不符的突然停车、违反交通规则的动作等,确保了标注的可靠性和有效性。
二、端到端轨迹生成
1. World4Drive
World4Drive: End-to-End Autonomous Driving via Intention-aware Physical Latent World Model
论文链接:https://arxiv.org/abs/2507.00603
开源链接:https://github.com/ucaszyp/World4Drive
提出机构:中国科学院自动化研究所, 理想汽车, 新加坡国立大学, 清华大学
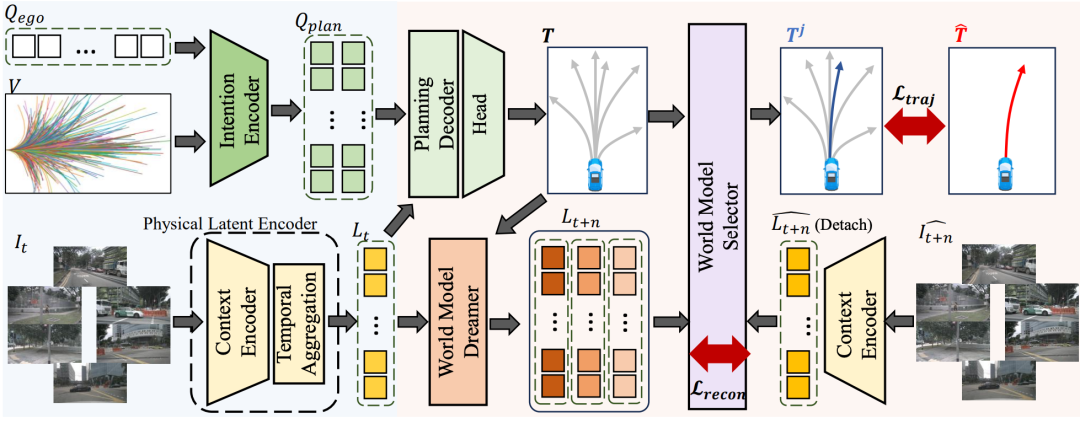
一句话总结:告别标注!中科院&理想提出一个全新的端到端框架:World4Drive,整合了多模态驾驶意图与潜在世界模型,以实现合理规划。
核心贡献:
受人类驾驶员决策过程的启发,作者提出了一个意图感知的潜在世界模型,创新性地使用世界模型在不同意图下生成和评估多模态轨迹。
为了增强世界模型对物理世界的理解而不依赖感知标注,作者设计了一个新颖的驾驶世界编码模块,该模块利用视觉基础模型的先验知识来提取驾驶环境的物理潜在表示。
作者的方法在 nuScenes 和 NavSim 基准测试中实现了无需感知标注的端到端规划性能,并显著加快了收敛速度。
2. TransDiffuser
TransDiffuser: Diverse Trajectory Generation with Decorrelated Multi-modal Representation for End-to-end Autonomous Driving
论文链接:https://arxiv.org/abs/2505.09315
提出机构:理想汽车, 中国科学院, 清华大学
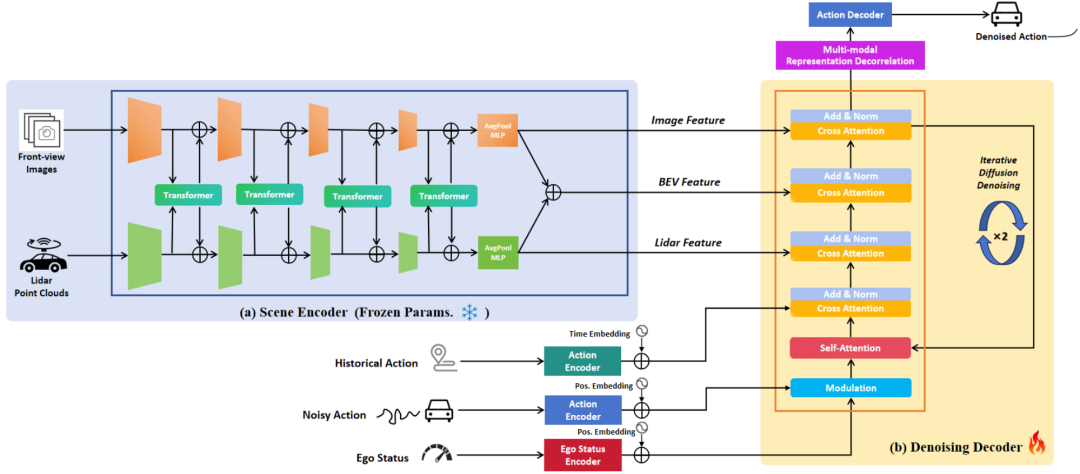
一句话总结:TransDiffuser基于TrajHF进一步改进,全新的生成式端到端自动驾驶轨迹规划模型。模型的输入为前视相机图像、激光雷达与当前车辆的运动信息,通过作者所设计的基于DDPM的Denoising Decoder架构进行多模态信息的融合,并通过多模态表示解相关策略对融合信息进行进一步优化,最后解码出规划轨迹。
核心贡献:本文的核心创新在于所引入的多模态表示解相关化的优化策略。TransDiffuser在 NAVSIM 基准测试中取得了最新的SOTA,在当时Leaderboard上提交的结果也取得了榜首,并且相较于GoalFlow与DiffusionDrive这两个相关工作,该模型无需依赖任何锚点轨迹或预定义轨迹词汇表,而是直接从高斯噪声解码潜在轨迹。这表明该模型在复杂交通场景中具有出色的泛化能力和适应性,能够生成高质量且多样化的轨迹规划方案。另外值得注意的是,本文沿着DiffusionDrive,进一步强调了生成轨迹多样性的重要性,并汇报了对应量化指标。
3. TrajHF
Learning Personalized Driving Styles via Reinforcement Learning from Human Feedback
论文链接:https://arxiv.org/abs/2503.10434
提出机构:上海交通大学, 上海期智研究院, 北京大学, 理想汽车, 清华大学
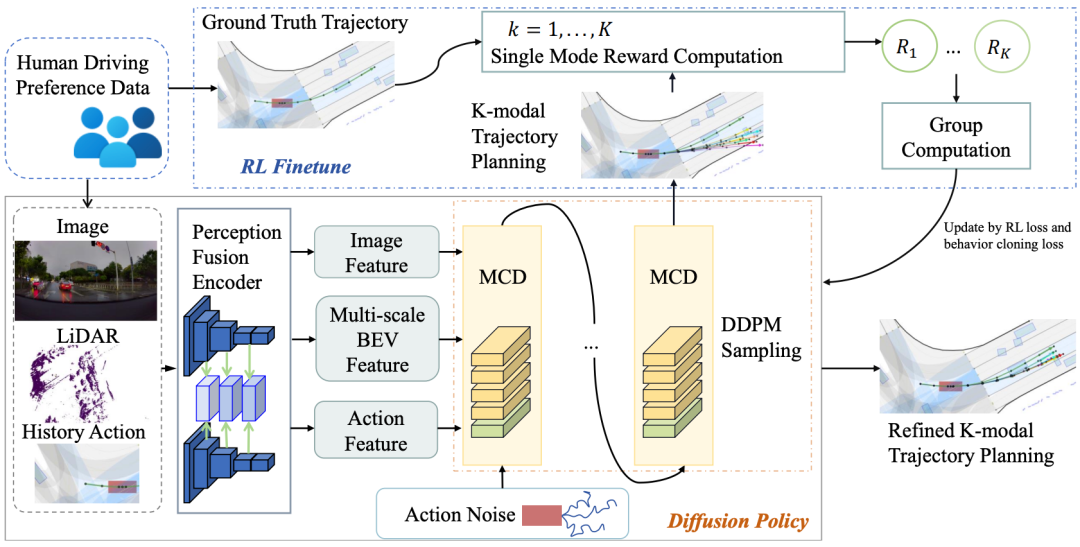
一句话总结:TrajHF 提出了一个基于人类反馈的微调框架,用于生成式轨迹模型,使模型能够与多样化的人类驾驶偏好对齐。
核心贡献:
系统地研究了平均行为和个性化驾驶风格之间的轨迹分布偏移问题;
提出了一种用于生成轨迹模型的人类反馈驱动微调框架,使其能够与不同的人类驾驶偏好保持一致。
综合实验评估证明了TrajHF在不同场景下生成与人类对齐的自动驾驶轨迹的有效性。
三、世界模型
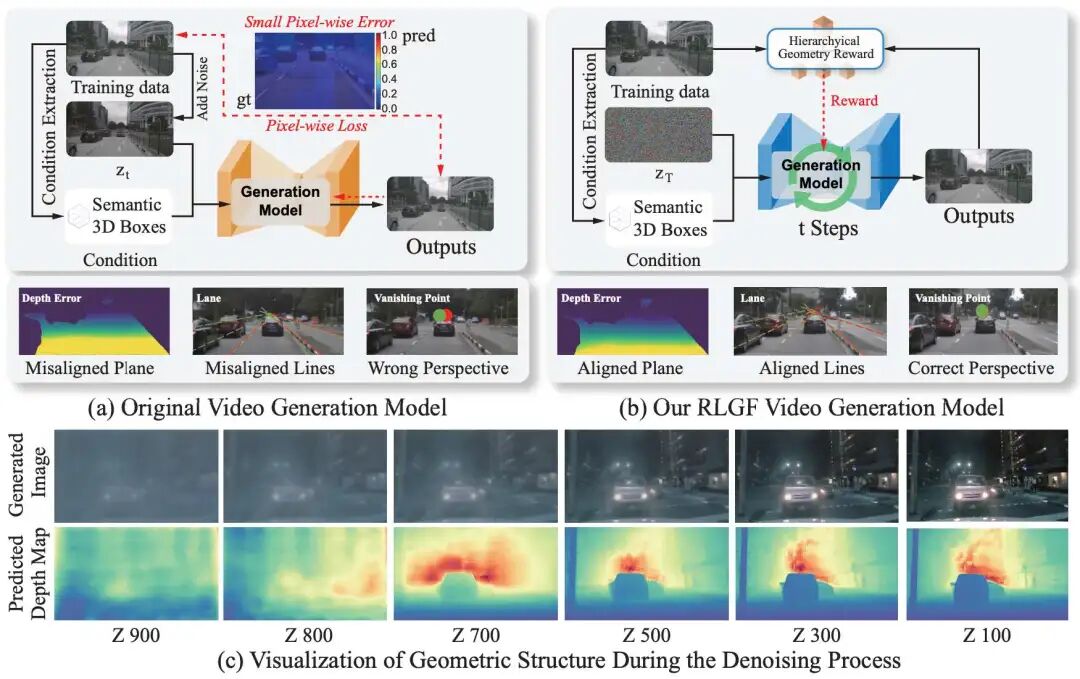
1. RLGF
(NeurIPS 2025)RLGF: Reinforcement Learning with Geometric Feedback for Autonomous Driving Video Generation
论文链接:https://arxiv.org/abs/2509.16500
提出机构:澳门大学, 理想汽车
一句话总结:理想汽车在自动驾驶场景视频生成方面的探索,提出了几何反馈强化学习RLGF,RLGF通过结合来自专门的潜在空间自动驾驶感知模型的奖励改进视频扩散模型。
核心贡献:
首次系统地量化了自动驾驶视频生成中的几何失真问题,并提出了用于评测的GeoScores度量。
介绍了RLGF,这是一种新的范式,它使用强化学习,在潜在空间的滑动窗口内有效地应用基于感知的奖励,实现了即插即用的几何校正。
设计了HGR,通过结合从潜在表示中导出的点线平面和场景级占用多级几何反馈来解决几何失真问题。
在nuScenes上进行的广泛实验证明了RLGF在两条基线上的即插即用有效性,将3D检测mAP绝对值提高了12.7%,同时减少了相对于真实数据的几何差距(通过GeoScores)。这项工作为自动驾驶系统中几何忠实的合成数据生成建立了一个新的范式。
2. HiNeuS
(ICCV 2025)HiNeuS: High-fidelity Neural Surface Mitigating Low-texture and Reflective Ambiguity

论文链接:https://arxiv.org/abs/2506.23854
提出机构:理想汽车
一句话总结:理想汽车ICCV2025中稿的神经表面重建工作,主要解决三个问题:多视图辐射不一致、无纹理区域中的关键点缺失,以及联合优化过程中过度执行Eikonal约束导致的结构退化。
核心贡献:
SDF引导的多视图一致性:利用连续SDF评估,计算可见度因子Vj来解决反射模糊问题,而不会产生网格离散化伪影。
局部几何约束正则化:光线对齐平面约束自适应地正则化无纹理区域,同时通过特征感知加权保留边缘。
渲染优先Eikonal松弛:自适应加权方案动态平衡几何保真度和渲染精度,在高误差区域保持细节。
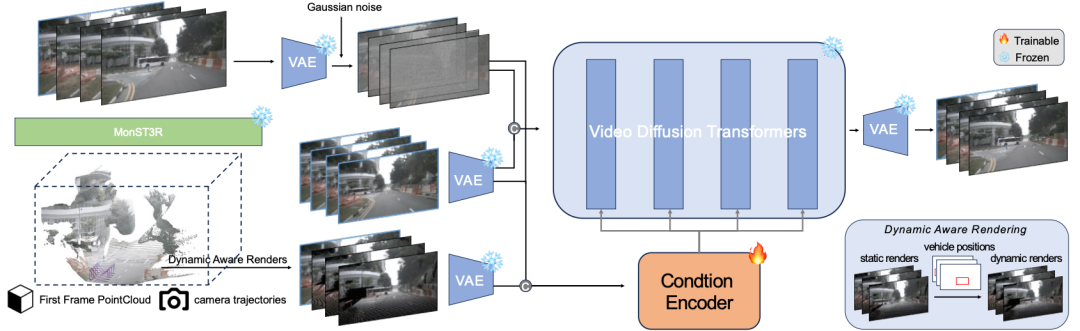
3. GeoDrive
GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control
论文链接:https://arxiv.org/abs/2505.22421
项目主页:https://github.com/antonioo-c/GeoDrive
提出机构:北京大学, 理想汽车, 加州大学伯克利分校
一句话总结: GeoDrive 首创性地将三维点云渲染过程纳入生成范式,在每一帧生成中显式注入空间结构信息,显著提升了模型的空间一致性与可控性。
核心贡献:
几何驱动的时序条件生成 系统以单帧 RGB 图像为输入,借助 MonST3R 网络精准估计点云和相机位姿; 结合用户提供的轨迹信息,逐帧进行投影生成,构建具有三维一致性的条件序列,确保场景结构连贯真实。
动态编辑模块:突破静态渲染局限 通过融合 2D 边界框注释,GeoDrive 支持对可移动物体的灵活位置调整,解决传统渲染中“场景冻结”的假设; 在训练阶段显著提升多车交互场景的动态合理性和模拟真实度。
结构增强的视频扩散生成架构 将渲染生成的条件序列与噪声特征拼接输入冻结的 Video Diffusion Transformer(DiT), 在保持光学生成质量的同时,引入结构上下文以增强三维几何保真度,实现内容与物理一致性的统一。
4. StyledStreets
StyledStreets: Multi-style Street Simulator with Spatial and Temporal Consistency

论文链接:https://arxiv.org/abs/2503.21104
提出机构:理想汽车
一句话总结:基于3DGS的自动驾驶场景重建算法,可以实现跨季节、天气和相机的真实风格转换。
核心贡献:
提出了一种基于不确定性感知的街景新风格重建流程,它通过学习可靠性掩膜来减少来自2D diffusion prior的监督噪声;
提出的混合嵌入架构将采集场景的几何结构与瞬态风格属性分离,在保持结构完整性的同时进行逼真的环境编辑;
统一的参数模型通过正则化约束几何漂移,维持了在多个车载相机下的多视图一致性。
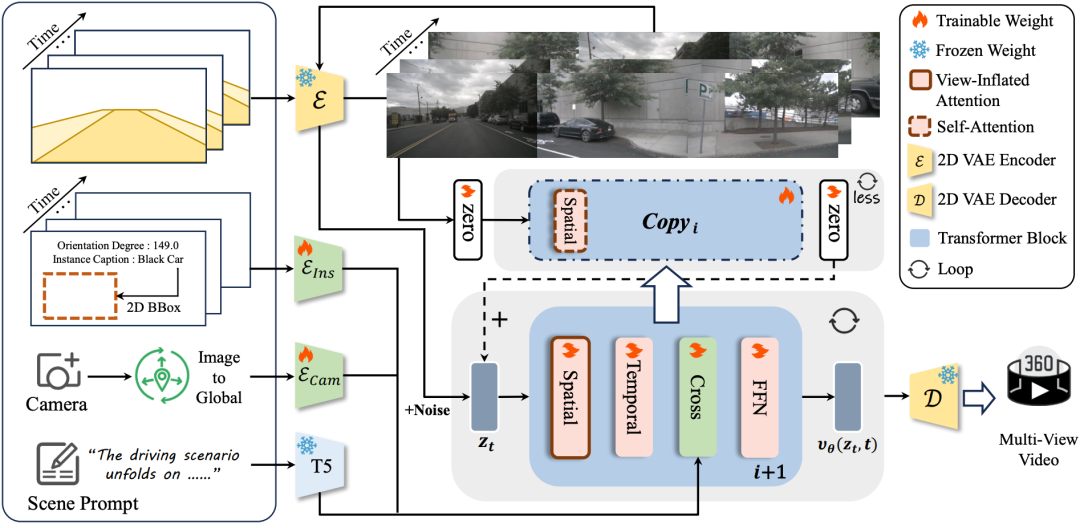
5. DiVE
DiVE: Efficient Multi-View Driving Scenes Generation Based on Video Diffusion Transformer
论文链接:https://arxiv.org/abs/2504.19614
提出机构:哈尔滨工业大学(深圳), 理想汽车, 清华大学(深圳)
一句话总结:基于Diffusion Transformer的生成框架,可以生成真实、时序连贯和跨视图一致的环视自动驾驶场景视频,相比基线速度提升2.6倍且性能掉点可控。
核心贡献:
提出了DiVE,这是一种基于DiT的环视驾驶场景视频生成新框架,在nuScenes数据集上取得了SOTA性能,FVD降低了36.7。此外DiVE生成的数据显著提高了下游感知模型的性能。
DiVE提出了两种协同方法:多控制辅助分支蒸馏(MAD),通过特定条件的辅助分支减轻多条件CFG的复杂性,并通过混合控制指导训练的跨条件知识蒸馏加以增强;以及分辨率渐进采样(RPS),一种无需训练的加速策略,分辨率逐渐增加的推理方式减少了推理耗时。单独来看,MAD和RPS分别提供1.71倍和1.62倍的加速。最终实现了2.62倍的加速,并且性能掉点可控。
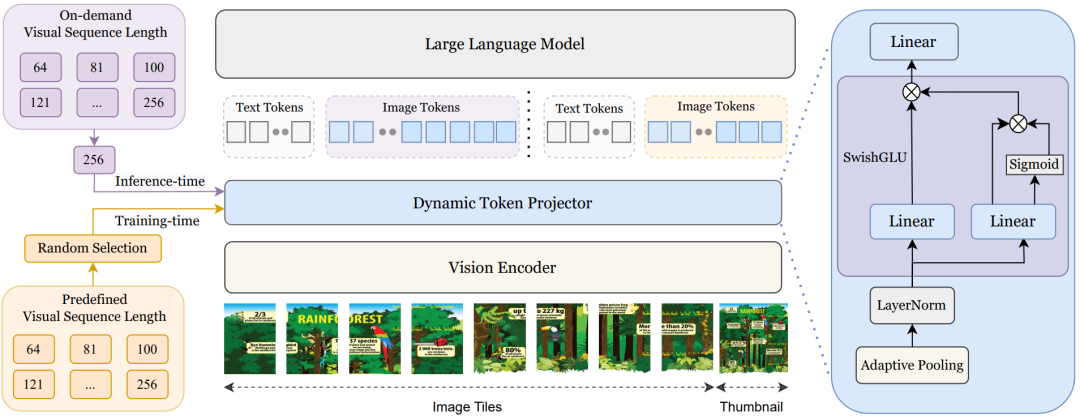
6. TokenFLEX
TokenFLEX: Unified VLM Training for Flexible Visual Tokens Inference
论文链接:https://arxiv.org/abs/2504.03154
提出机构:理想汽车
一句话总结:动态视觉Token推理的统一VLM训练框架。
核心贡献:
动态token机制。为了解决训练中的固定token约束,TokenFLEX开发了一种随机训练方法,从每个样本的预定义集合中随机选择视觉token的数量。强迫模型在不同的token编号之间学习鲁棒的跨模型对齐一致性,有效地减轻了推理过程中OOD性能的下降。这种训练范式支持使用任意token数的灵活推理,同时保持与固定token基线一样的性能。
轻量级token自适应Projector。这个Projector结合了自适应平均池化层和SwiGLU。自适应平均池化层允许灵活修改视觉token的数量,而SwiGLU利用其门机制动态地为视觉特征分配权重,在不同的token配置下优先考虑突出信息,同时抑制冗余细节。这种自适应加权确保了即使在减少token数量的情况下,也能保留关键的视觉语义。
四、其他
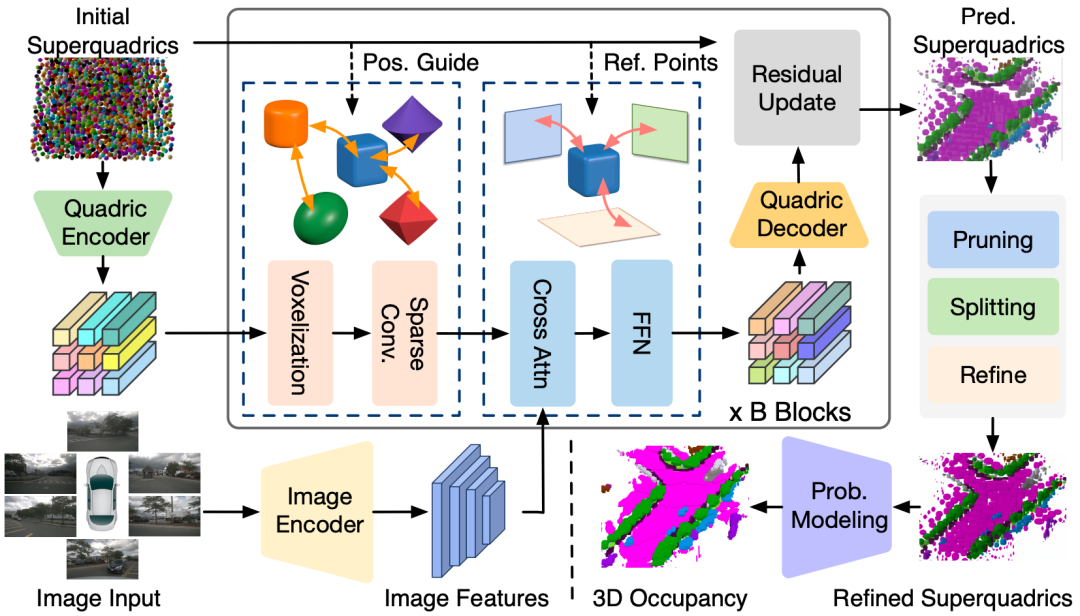
1. QuadricFormer
QuadricFormer: Scene as Superquadrics for 3D Semantic Occupancy Prediction
论文链接:https://arxiv.org/abs/2506.10977
项目主页:https://zuosc19.github.io/QuadricFormer/
代码链接:https://github.com/zuosc19/QuadricFormer
提出机构:清华大学, 理想汽车
一句话总结:把场景作为超二次曲面的3D语义占用预测方案。
核心贡献:
提出了一种概率超二次曲面混合模型,用于自动驾驶场景中的高效3D占用预测;
与先前基于稠密体素或者椭球高斯的方法不同,本文利用了具有几何表现力的超二次曲面进行高效的场景表示,这可以使用更少的基元来有效地捕获现实世界目标的多样化结构;
在nuScenes数据集上的实验表明,与现有方法相比,QuadricFormer实现了最先进的准确性和更高的效率。
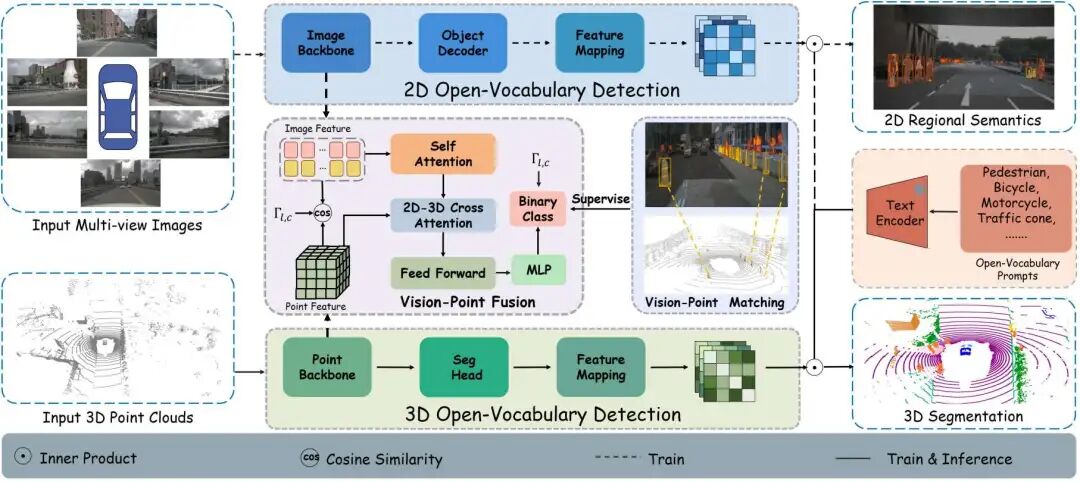
2. UniPLV
UniPLV: Towards Label-Efficient Open-World 3D Scene Understanding by Regional Visual Language Supervision
论文链接:https://arxiv.org/abs/2412.18131
提出机构:理想汽车, 中国香港科技大学(广州)
一句话总结:该工作提出了一个多模态开集框架UniPLV,将点云、图像和文本统一到一个范式中,利用图像模态作为桥梁,不需要制作对齐的点云和文本数据,实现开放世界的3D场景理解。
核心贡献:
提出了一种无需构建点云-文本对齐数据的开放世界三维场景理解框架;
设计提出了VPM匹配模块,双蒸馏以及两阶段优化策略以实现点云、图像和文本的有效对齐;
在多个数据集上的开放场景理解达到了SOTA性能,包括nuScenes,ScanNet、Waymo和SemanticKITTI。
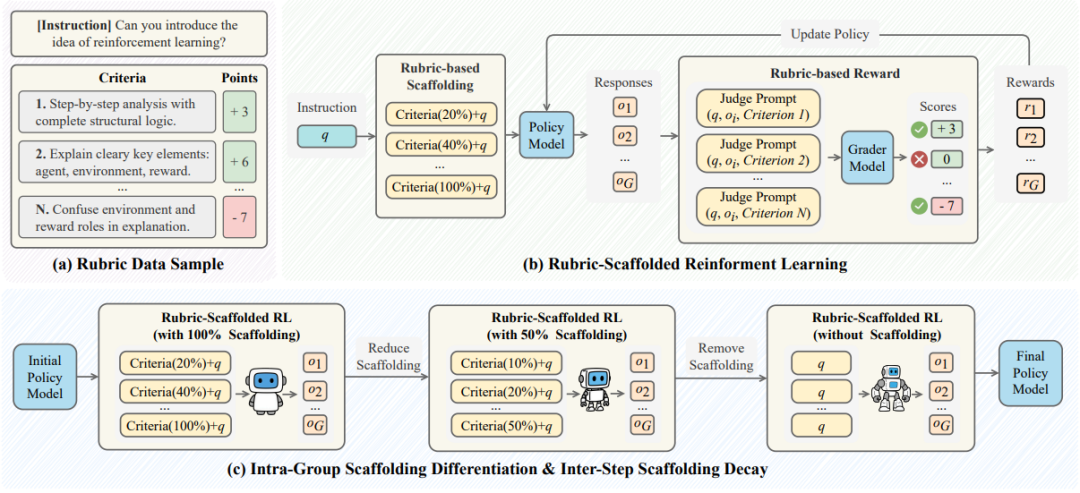
3. RuscaR
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
论文链接:https://arxiv.org/abs/2508.16949
提出机构:浙江大学, 理想汽车, 南洋理工大学, 香港中文大学(深圳)
一句话总结:RuscaRL是理想面对大语言模型强化学习探索瓶颈恶性循环,无法探索的内容便无法被有效学习给出的一套解决方案。
核心贡献:摘自理想TOP2公众号文章『理想基座模型负责人近期很满意的工作: RuscaRL』
核心思路是将教育心理学的脚手架理论AI化,脚手架的核心思想是学习者的能力不足时,通过结构化的外部支持(例如逐步引导)帮助其逐步掌握新技能,并随着能力的提升逐渐减少支持,从而促进独立学习。
无论是MindGPT还是MindVLA,一个面向数字世界,一个面向物理世界,未来的强化学习路线都有机会因RuscaRL而获益,基于此理想基座模型负责人陈伟觉得这是最近他自己很满意的一个工作。
理想团队看到的是面向未来实现模型自我进化的一个很好的路线,智能体强化学习目前看关键问题已经不是解决单点的算法问题,更多是算法和infra融合的体系性问题解决,创新往往来自于体系能力的建设,因为人的计划都不是看个体发展的,也要看他所处的环境,以及接受训练的方法,这些在ruscaRL都能看到。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









