



作者 | 张凯@知乎 编辑 | 大模型之心Tech
原文链接:https://zhuanlan.zhihu.com/p/1959223427115250831
点击下方卡片,关注“大模型之心Tech”公众号
本文只做学术分享,已获转载授权,欢迎添加小助理微信AIDriver004做进一步咨询
学校毕业以后一直从事芯片算法行业,中间经历了CNN的如日中天,ViT的异军突起,再到如今LLM/VLM的一片火热,算法层面早已发生了翻天覆地的变化。
未来端侧智能的上限究竟有多高,我们还没有见到天花板;但是可以预见的是,具身智能,手机,音箱,摄像头,各种盒子,各种端侧场景的需求是无限广阔的,这既是历史性的挑战,更是时代赋予的机遇。
目前市场上也有一些端侧的芯片,这里聊的主要是100T算力以内的芯片,例如爱芯元智、算能都相关的芯片,也能支持LLM的推理,但是不管如何,其实还是面向上一代的ViT设计的,其效率在LLM上还没有达到上限。
本文还是主要从算法的角度聊一聊,框架和部署技术对未来芯片设计的影响。
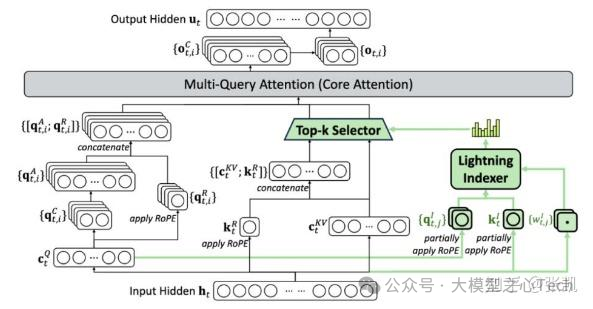
注意力机制的演进
Transformer架构长期以来主导了大模型领域,其自注意力机制的计算复杂度与序列长度呈平方关系,这对prefill阶段的算力需求和decode阶段的带宽(KVcache大幅度增加)需求都提出了巨大的挑战。早在ViT和Transformer时代,关于Transformer的结构就有了一系列的改进,Performer(ICLR'21),Reformer(ICLR'20),lnformer(AAAI'21 best paper),但是没有一个真正广泛应用的。原因只有一个,不是真正的强需求。毕竟即使是在2025年,某些场景用ResNet18(2015)和Yolov3(2018)也是足够的。但是在大模型时代,一切都不一样了。视觉大模型确实相比过去的小模型产生了巨大的性能提升,泛化性也得到了极大的加强。而语言大模型,则打开了智能的天花板。所以Transformer的支持变得势在必行。
为了应对自注意力机制的瓶颈,线性注意力(Linear Attention)机制应运而生,通过将注意力计算分解为核函数近似,将计算复杂度降低至线性水平。类似地,RWKV、Mamba,以及近期的Qwen3-next的DeltaNet等都是类似的思路。还有另一条路线是,则是以DSA为代表的稀疏注意力,如果不能解决 的瓶颈,如果将n变小也是可行的,该工作也是今年ACL(2025) 的best paper。类似地,kimi的MoBA也是类似的思路,其思想也是非常的优雅。除此以外,还有一条隐含的路线,张祥雨老师提到用多智能体协作解决上下文的问题,一个做全局理解,一个做局部感知,典型的分而治之的思想,大巧不工。那这些对端侧芯片有什么影响呢?其实影响不大,只要不出现奇奇怪怪的算子,能够在NPU上融合成一个大算子,计算效率依然会非常高。反而在这里面是通道数的大小,head数的大小影响更大,SRAM是否能够放下,可能是更关键的瓶颈。
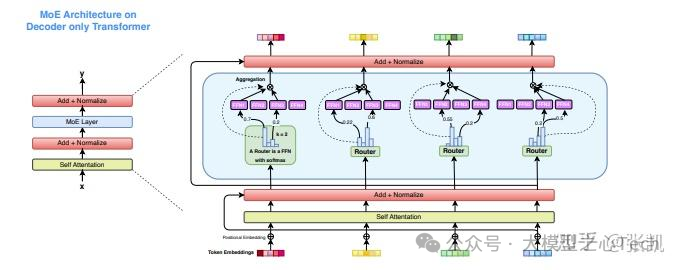
动态稀疏。
过去十年,动态机制对于网络性能的提升是非常大的,例如动态卷积(Dynamic Conv),条件卷积(CondConv),可变形卷积(DCN),动态FPN。稀疏技术,学术界一直探索的比较多,工业界却一直很难用。我们团队在CNN时代和Transformer时代一直也有在研究稀疏技术,例如NeurIPS'22的SAViT;今年尝试联合用稀疏和低秩分解做大模型的压缩,也中了今年的EMNLP,但总体来说,还是非常定制化。
真正给稀疏带来广泛应用的是MoE技术,是动态稀疏,这也是很久前一直想做的动态稀疏,奈何以前芯片一直支持的不好。MoE网络在推理阶段只激活一部分专家。从推理的角度看,MoE非常的有意思,做个对比,14B的稠密模型和30B-A3B的稀疏模型(激活3B),后者性能更好,推理时还省算力,省带宽,小模型不管是量还是价,都“超越”了大模型的性能,标准的以小胜大的典范。只有一个小缺点,内存需求更大。当然这是单batch的理想情况,多batch的时候则非常糟糕,decode阶段的时候带宽几乎等同于30B,这个时候就不如稠密模型了。(插个话,我之前面试的时候,有时会问一道数学题,对于MoE模型,计算多batch下平均激活专家的期望数。)云端推理的时候,MoE又可以非常友好,当所有专家都被选取的时候,其实是可以省算力的。
回到端侧芯片上,最主要的场景可能还是单batch的场景。当下的趋势是,MoE模型的稀疏性进一步加大,例如蚂蚁最近的MoE模型(100B-A6.1B)非常出色,其端侧的模型(16B-A1.4B)也是令人惊艳,这都进一步加到了动态稀疏的趋势,MoE的内存要求会更大。最后总结一下,未来MoE技术对于芯片的影响是巨大的,大内存,中带宽,中算力。更进一步的,工业界当下更要关注moe的压缩后面该怎么压缩,类似今年MoNE的工作(如何降低内存)。
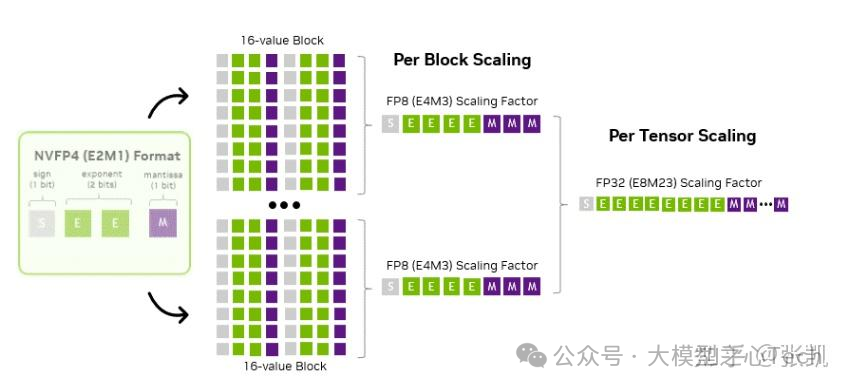
低比特量化。
Deepseek采用FP8训练,打开了低比特量化的新时代。而在推理阶段,端侧大模型对低比特量化(4bit及以下)提出了更加激进的需求,其技术也呈现出了不同的特性:
1)weight-only量化,针对decode阶段的带宽瓶颈,只对权重做压缩,计算还是保持原精度计算,例如GPTQ、AWQ等;
2)低精度浮点vs.定点数,这其实是两条路线,云端GPU从FP16/BF16往下做FP8/FP4,端侧芯片则希望是继续原来的INT8/INT4技术路线,例如后摩的RPTQ工作。在细粒度量化下,其实两者是殊途同归的;
3)细粒度量化,以往的权重是per-channel量化,激活是per-tensor量化,当下则是都拆分成更细的粒度(例如per-group)去做,量化精度显然更高;
4)动态量化vs.静态量化。这里主要是针对激活值的,由于任务的不确定性,像过去直接离线确定一个激活值的范围挑战是比较大的,但是支持动态量化,显然在芯片上有较大的成本,这个是比较头疼的trade-off。
最后,我还觉得混合量化是未来的趋势,大模型天然的层内和层间的数值不平衡就适合混合量化去处理,我们今年也有一篇做混合量化相关的工作被接收EMNLP接受。未来针对MoE模型,混合量化应该还有更大的用武之地,业界应该投入更多的力量去探索和研究。
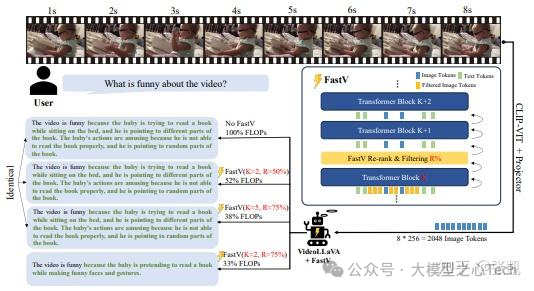
Token压缩。
这一方向的工作其是Transformer新带来的压缩方向,Token维度天然适合去进行压缩,这极大地降低了端侧大模型的应用门槛。对于标准的VLM(例如1BViT+3BLLM)的模型而言,文本token为数百个,但是视觉token为上千,显然视觉Token带来的计算量是非常庞大的,但其实冗余度非常高。从早期的Fastv(ECCV'24),PyramidDrop(CVPR'25),Holov(NeurIPS'25),LightVLM,SpecPrune-VLA等等,最近这方面的工作是井喷式的。对于芯片的影响,则是多多益善,吃到就是赚到。
以上四个变化,是我觉得这一年以来相对确定性的变化,对未来端侧芯片的设计都有着较大的影响。兵马未动,粮草先行,端侧芯片其实一直严重滞后于大模型的发展,未来希望早日见到可用的高效端侧芯片。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


















 2766
2766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









