



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
作者 | 论文推土机
编辑 | 自动驾驶之心
约了知乎大佬@论文推土机,整理下世界模型技术栈下VQ家族的相关论文,分享给大家!
为什么要离散化:
神经网络是函数的万能拟合器,但不是概率密度的万能拟合器,这就是连续型变量做生成建模的本质困难,而图像生成的各种方案,本质上都是“各显神通”来绕过对概率密度的直接建模(除了Flow)。但离散型变量不存在这个困难,因为离散型概率的约束是求和为1,这通过Softmax就可以实现。所以肯定要搞离散化。
离散化直接应用到像素级ar:
像素级 AR 的困境:直接在像素空间做自回归步数过大(256×256 需约 20 万步),难以落地。
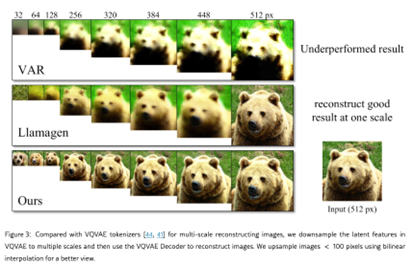
“先压缩后生成”的主流与隐患:VQ-VAE/VQ-GAN/FSQ 等“图像 tokenizer”在 32×32 或 16×16 网格上生成,再解码回像素;但这是强压缩,会引入信息损失(SEED 可视化重构示例:语义对,但细节走样)。
信息论下的下界估算:以 ImageNet-64 平均熵估算,一个长度为V的词表,信息容量是log2(V), 若想在 L=32×32 或 16×16 的长度上“无损”承载图像信息,词表规模需夸张到 甚至 ,远超现有 codebook 能力——强压缩必然有损。
然而,直接在像素空间上操作的最大问题是——序列太长,生成太慢。在多数应用场景中,图片分辨率起码要达到256以上才有实用价值(除非只是为了用于小图表情包的生成),那么就算n=256,也有3n2≈20万,也就是说为了生成一张256大小的图片,我们需要自回归解码20万步。
为此,一个很容易想到的思路是“先压缩,后生成”,即通过另外的模型压缩序列长度,然后在压缩后的空间进行生成,生成后再通过模型恢复为图像。压缩自然是靠AE(AutoEncoder),但我们想要的是套用文本生成的建模方式,所以压缩之后还要保证离散性。
所以评价一个生成方法好不好,直接看它用了什么方式防止信息损失,以及做到了什么程度的无损压缩。
VQ-VAE
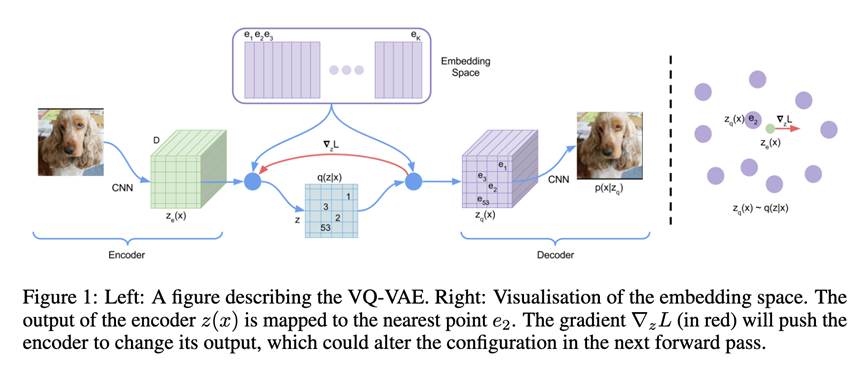
vq-vae是非常老帮菜的技术了,其核心就是将连续特征离散化表达。三个loss:
其中使用梯度直通gradient straight through解决离散化不可导的问题。这样前向用的是 ,梯度回传则传到 上。
Plain Text
z_st = z_e + (e_q - z_e).detach() # 前向用 e_q,反向对 z_e 传梯度#VQ-GAN
Esser, Patrick, Robin Rombach, and Bjorn Ommer. "Taming transformers for high-resolution image synthesis." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
方法:
回顾VQ-VAE:
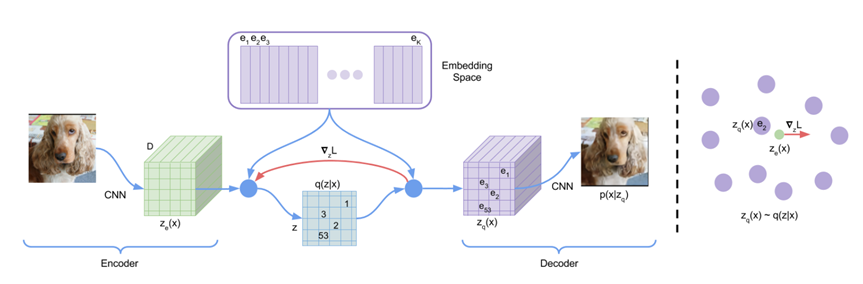
而VQ-GAN则是加强版:
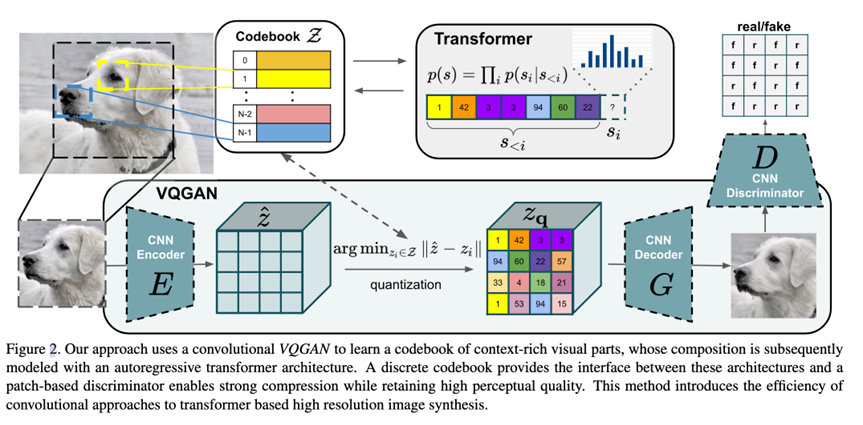
全文三件事:
把“卷积的局部归纳偏置 + Transformer 的长程建模”拼起来做高分图像生成。先用卷积式的 VQGAN 学一个“上下文丰富的离散码本”,把图像压到较短的 h×w 索引序列;再在索引序列上用自回归 Transformer 做最大似然建模(next-index prediction)。这样既保留了 Transformer 的表达力,又避免像素级序列过长带来的二次复杂度瓶颈。
提出 VQGAN 作为更强的第一阶段表征:用感知重建损失+PatchGAN 判别器替代纯 L2,使在更高压缩率下仍有较好感知质量;这一步显著缩短 Transformer 的序列长度,是能上高分辨率的关键。
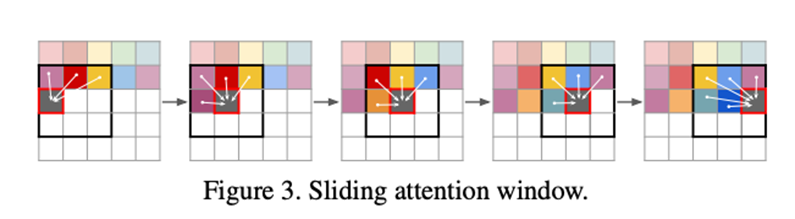
滑动注意力窗口做超大图采样:训练时裁成可承受长度的索引块;采样时沿空间滑窗自回归,前后块共享上下文,就是上面图三所谓的sliding attention window。
Loss
vq-vae的loss:
VQ-VAE 对编码器 EEE、解码器 GGG、码本 ZZZ 的联合目标:
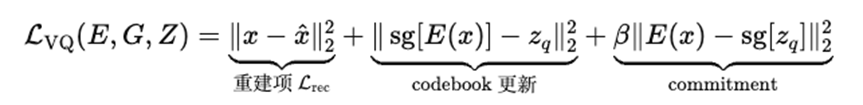
其中重建项:逼近像素;codebook/commitment:稳定码本、避免编码器漂到码本之外,β为权重。VQGAN 仍保留 的结构,但是做了三个改动:
★
把重建项换成感知重建;
并引入对抗损失(PatchGAN 判别器 D);
再用自适应权重 λ 动态平衡两者;
Perception loss
用 VGG/LPIPS 等感知度量替代像素 L2 作为 ;实证表明在高压缩比下可显著提升感知质量。
GAN loss
采用 patch-based 判别器 D,最小最大目标:
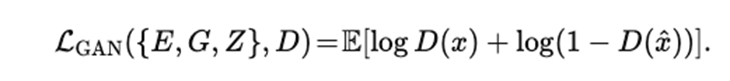
整个训练是一个 min–max 博弈,整体目标:
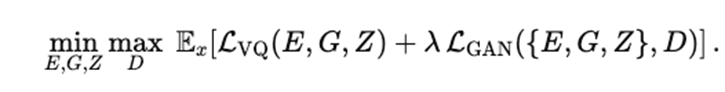
自适应权重
λ 由解码器最后一层的梯度范数比自适应调整:
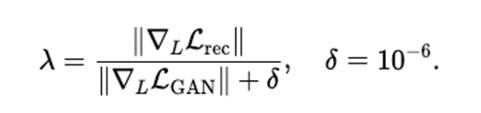
如果 LGAN 的梯度太小(GAN 学不动),λ变大,放大 GAN 项;
如果 LGAN的梯度太大(GAN 过强不稳),λ变小,抑制 GAN 项;
这样能在训练早中晚期自适应匹配两者强度,避免手调常数。
Sliding attention window
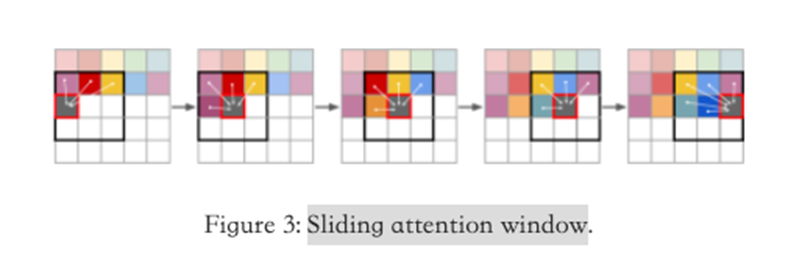
具体做法就是把整张大图在VQGAN 的潜空间网格上,分成可承受的小窗口(如 16×16 token)来做自回归预测;采样时让这个窗口在整张图上滑动,每次只让 Transformer 关注窗口内及与前一窗口的重叠上下文,从而把注意力的开销从 降到近似 (k为窗口边长)。
Sliding attention window = 用固定小序列训练 Transformer,用滑动的局部注意力窗口在采样时覆盖整图;它主要解决了注意力二次复杂度导致的高分辨率生成不可扩展的问题,并依赖 VQGAN 的上下文丰富表征与重叠上下文来保持全局一致性。让gpt举个例子:

RQ-VAE
预测residual早已有之。
首先回顾VQ-GAN,是一个两阶段学习:
第一阶段,学一个encoder,decoder用于离散化编码图像patch。
第二阶段,使用transformer生成latent code,可以是条件生成或者无条件生成,最后通过decoder生成高清图片。
同样的,rq-vae也是两阶段学习,第一阶段的区别在于学的不是vq而是vq的residual;第二部分,由于第一阶段任务的改变,每个patch的表达方式变成了多个code-book词表的残差和,所以对应的transformer的学习任务也发生了微调。整体上架构是和vq-gan相同的,具体的操作上发生了改变。文中也强调了,这个学习residual地intuition就是希望能使用不同codebook词表表达图片的不同信息,从框架到纹理。
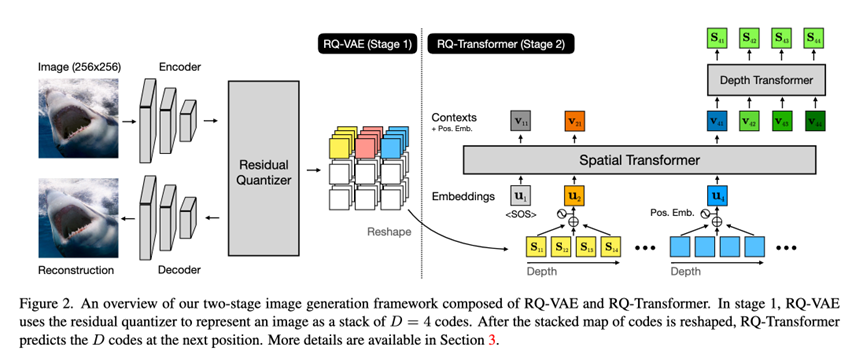
总结来说,全文三件事:

Residual quantization
和原来vq-vae不同的地方是,vq-vae一个patch对应一个码本词表,这次rq-vae采用了D个码本词表对应一个patch特征。
其中:
具体来说就是第一层patch就是直接codebook里找最近code,然后patch特征减掉这个code,获得第一个residual,这个residual就是剩余的可解释信息,然后继续相同的操作,为这个residual在codebook里找第二个code,然后再减掉residual的residual,循环操作D次,获得每个patch特征的D个code表达,这样就有: 要在Markdown中输出该公式,可使用LaTeX语法:
这里的操作思路和var类似,精确的说应该是var applies residual modeling which is inspired by rq-vae.
Loss
还是原来的vq-vae的loss:
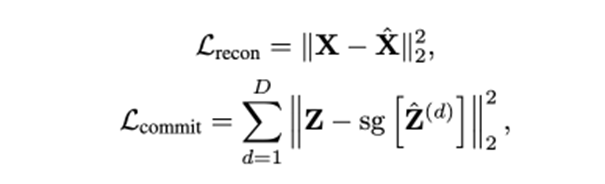
当然也可以像vq-gan,加上perception和patch gan loss。
RQ-transformer
细节比较多,看下原文吧。这里说一下推理,由于前面的vq方式发生了改变,这里多了一个深度D维度,所以transformer分成两个构型,一个是空间的spatial transformer,然后还有一个depth transformer:
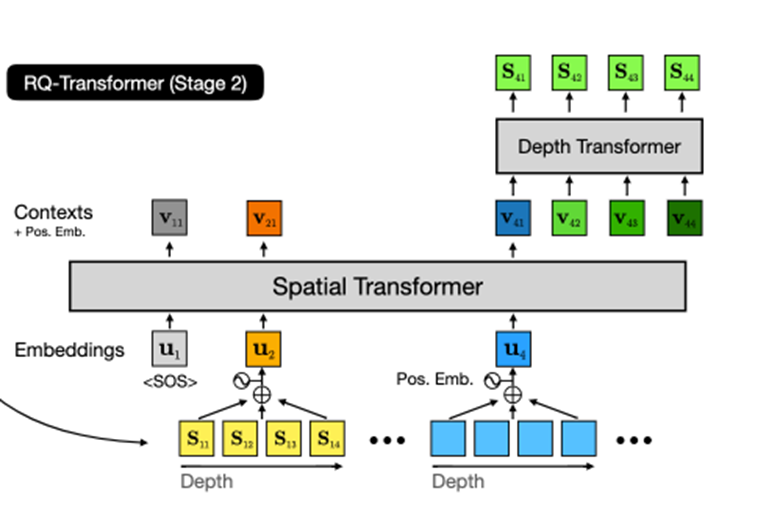
上图画的很清楚,ar过程有两个,一个是空间上的ar,然后每个空间位置上还有一次depth上的ar。
小小的对比
与 VQ-VAE / VQ-GAN 路线
★
VQ-VAE 首次把离散潜变量与学习先验结合,避免后验坍缩,成为离散生成的基础;但单层量化在强压缩下重建退化明显。
VQ-GAN 把对抗与感知损失引入第一阶段,提高重建与感知质量,并提出滑窗注意力以缓解长序列问题。
RQ-VAE 的位置:在不扩大码本的情况下,以多层残差量化获得更强近似能力与更短序列(更小 T),这正对 VQ-GAN 的“长度瓶颈”给出另一条通路。
与“并行/掩码式”AR(如 MaskGIT)
★
近年的意见认为顺序 AR 太慢,MaskGIT 以“随机掩码+迭代并行填充”的范式在速度与质量上取得强竞争力,弱化严格的自左到右生成。
对比:RQ-Transformer 依旧是自回归,但通过 T×D的结构与短序列维持了可接受速度;MaskGIT 走的是“并行 refinement”的另一条路。
不同层的residual预测结果


文章给出了不同层的预测结果,一开始我还没有特别理解残差预测为什么可以每一层都重建图片,然后问了一下gpt“图中显示使用不同depth的embedding进行重建得出的不同结果,但是网络预测的是残差,每一层的残差本身应该是没有直接重建图片能力的,而只有所有残差加起来到最后一层的结果才有重建图片的能力,为什么图中每一层残差都有重建图片的能力,只是细节越来越完善的区别?”,其实我的理解有误差,每一层的decoder输入是累积到该层的所有残差,所以其实最开始的第一层就可以重建基本轮廓了:

★这让我想起了flexvar中的图片,如上面右图所示,说使用residual不能重建出任何东西,这样的对比其实没意义,应该使用累积和进行重建,所以使用residual 预测照样可以在每层重建出语义信息。所以flex-var文章强调的重点“连续语义:不以“上一层累计重建”作为必须条件,而是直接对齐“真值”,从统计学习角度更像一致的似然因子分解,强调相邻尺度的语义连续(作者认为更利于建模扩展的概率分布)。”其实站不住脚。var没有类似rq-vae的图是因为它根本没想到有人会用residual去decode图片。
Soft VQ-VAE
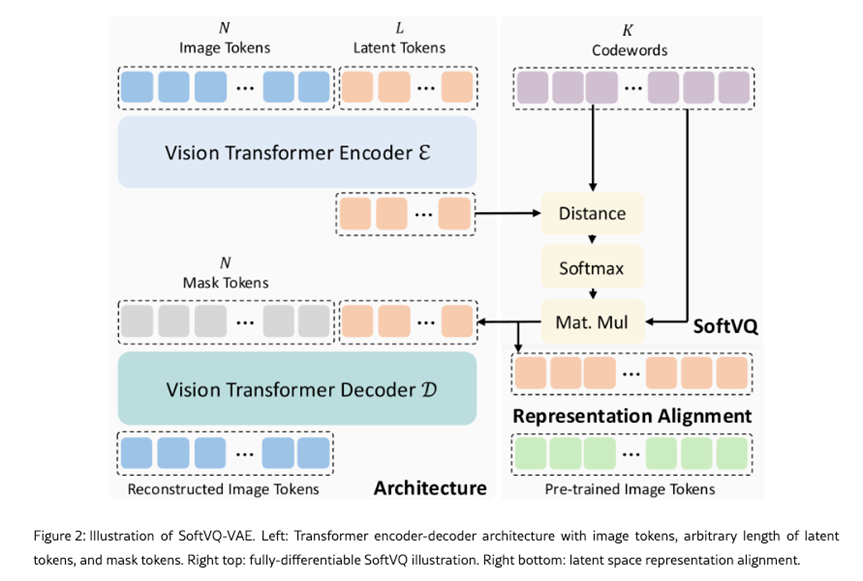
MaskGIT
方法
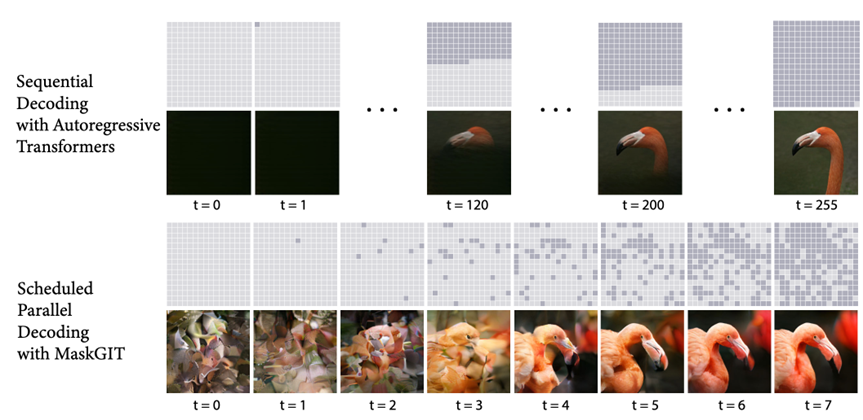
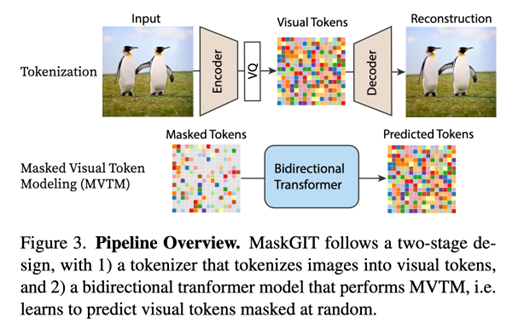
本文核心两个部分,一个是VQ-GAN学一个tokenizer,然后是一个bidirectional transformer,网络需要预测是被mask部分的概率,所以loss就稍作修改:
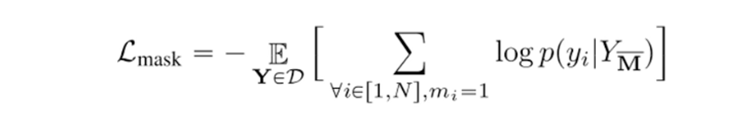
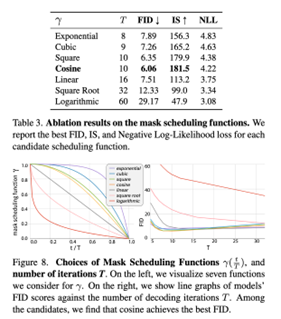
整体的采样decoding策略是:“并行预测 + 基于置信度的重掩 + 多步 refinement”策略,关于masking比例调度有一个对比,这里最后采用的是cosine scheduling。解释是“Concave function captures the intuition that image generation follows a less-to-more information flow. In the beginning, most tokens are masked so the model only needs to make a few correct predictions for which the model feel confident. Towards the end, the mask ratio sharply drops, forcing the model to make a lot more correct predictions. The effective information is increasing in this process. The concave family includes cosine, square, cubic, and exponential.”对于预测早期,不确定性大,所以不需要准确预测太多token,随预测次数增加,可以快速增加准确预测tokens的数量。下面左图是算法结构,右图是不同调度方式。只要是起点为1,终点为0的任何调度方式都可以,y轴表示的mask比例。
实验结果
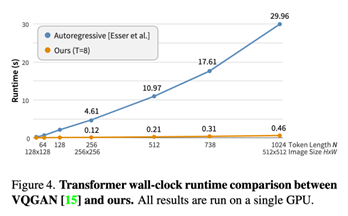
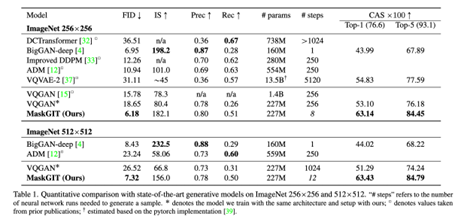
实验结果上,首先推理速度蹭蹭快,毕竟是做了并行decoding的,并且推理步数也非常少:
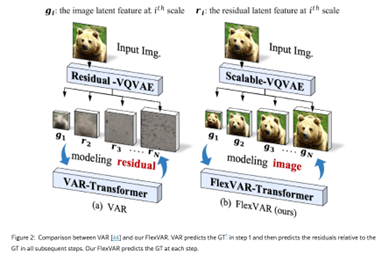
VAR
Tian, Keyu, et al. "Visual autoregressive modeling: Scalable image generation via next-scale prediction." Advances in neural information processing systems 37 (2024): 84839-84865.
代码地址:https://github.com/FoundationVision/VAR/tree/main
与之前的ar方案的图片生成策略不同,var首次使用了next scale prediction的方式,通过预测层与层的残差方式,从粗粒度开始基于上一scale的信息预测下一个更细粒度的scale。并在指标上打败当时的DiT图片生成方案。
之前的MaskGIT相比于AR生成,采用了parallel decoding策略,通过cosine 调度方式先填补high confidence,然后再继续填补剩余部分,逐步补全全图。相当于是bert的图片生成版本。
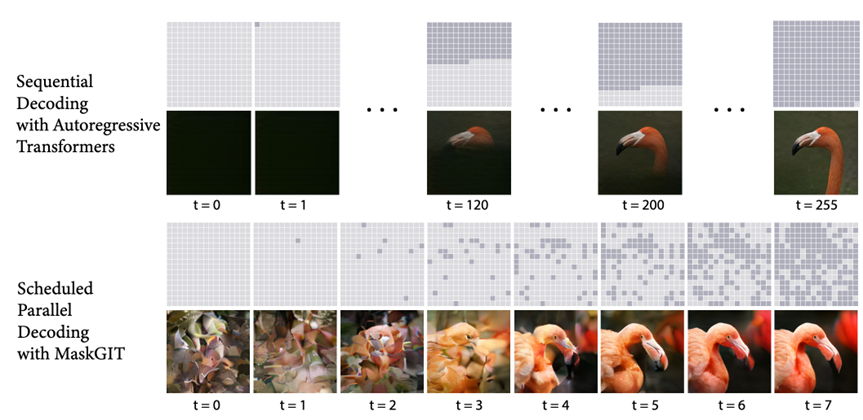
而之前的VQ-GAN是加强版VQ-VAE,在做attention的时候,有一个sliding attention window的做法:
有一点考虑图片与文本序列的一大区别是图片在空间上有关联性,所以虽然做ar生成,但是每次都会和当前patch附近的空间区域做attention。但是VQ-GAN,或者MaskGIT方法,没有scale的概念,和语言序列的最大区别之一,就是图片的邻近空间相关性,从这个角度上讲,上面两个方法都没有很好处理图片生成的这个特点,所以文章首先列举了图片生成的痛点问题:

然后陈述自己的方案如何解决这些问题:

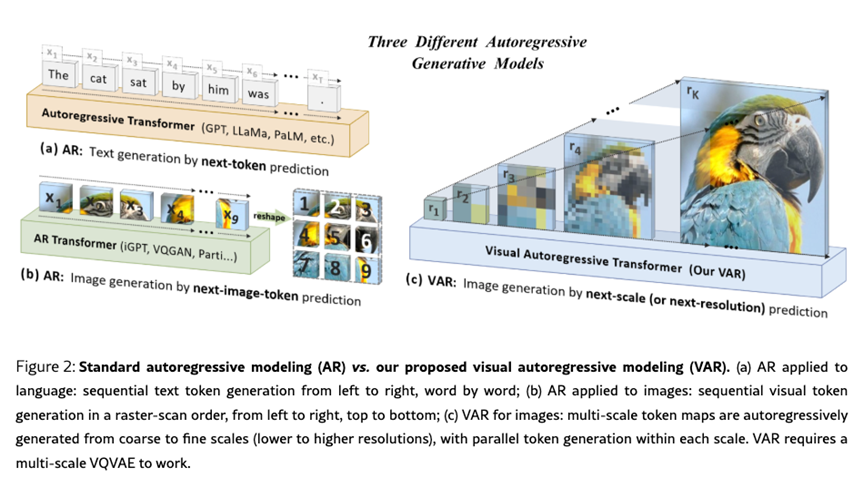
本文的方案是使用next scale residual prediction,虽然也是condition on之前的信息,预测下一步信息,但是ar是预测next token,var预测next scale:
这里的r是token maps,next scale的预测可以condition on之前scale的信息。这点思想,有点类似于RQ-transformer的思路,也是利用到了residual prediction的策略。

算法流程如上面所示,一个是不断计算当前scale的离散表达,然后用f减掉,计算残差,然后不断迭代。推理过程中,则是不断重建出残差,在f上加进去,最后恢复图片。
残差预测在flexVAR中被批为:“我们考察了视觉自回归建模中残差预测的必要性。我们的直觉是,在尺度自回归建模中,当前尺度的真实值可以从先前的尺度序列中可靠地估计出来,这使得残差预测(即预测当前尺度和前一个尺度之间的偏差)变得不必要。值得注意的是,预测真实值确保了相邻尺度之间的语义连贯性,使其更有利于建模尺度的概率分布。此外,这种结构可以在任何步骤输出合理的结果,打破了残差预测的刚性步骤设计,赋予自回归建模极大的灵活性。”
总而言之,就是两个好处“this non-residual modeling approach ensures continuous semantic representation between adjacent scales. Simultaneously, it avoids the rigid step design inherent in residual prediction, significantly expanding the flexibility of image generation.”一个是不再依赖刚性步长, 第二个是有连续的语义表达。
首先第一点,刚性步长确实是residual预测的问题:
在 VAR 的实现里,步长(每个 scale 的 token 数)基本被结构固定:
patch_nums预先定义了每一层的网格,例如(1,2,3,4,6,8,10,13,16),模型里据此计算L、begin_ends、位置/层级嵌入与跨尺度因果 mask。这意味着每一步要产出恰当数量的 token,才能进入下一步(见 VAR 论文与官方代码)。自回归推理也把“第 层的输出”用于构造“第 层的输入”(
get_next_autoregressive_input做上采样+卷积,再下采样给下一层),因此某层没完备,下一层就没条件。这是残差链式设计的直接后果(上一层给出“粗解”,下一层只学“剩余”)。
FlexVAR 的思路:让每一步都直接预测“真值”(而不是剩余),从而任何步数都能单独产出合理结果。这正是 FlexVAR 宣称的优势之一。但是redisual预测我觉得不至于一无是处。至少从语义连续性角度来讲,RQ-VAE证明residual预测也有语义连续性,相关结论在RQ-VAE中已经提到:
★“使用residual不能重建出任何东西,这样的对比其实没意义,应该使用累积和进行重建,所以使用residual 预测照样可以在每层重建出语义信息。所以flex-var文章强调的重点“连续语义:不以“上一层累计重建”作为必须条件,而是直接对齐“真值”,从统计学习角度更像一致的似然因子分解,强调相邻尺度的语义连续(作者认为更利于建模扩展的概率分布)。”其实站不住脚。”
loss
loss采用了vq-gan的loss:
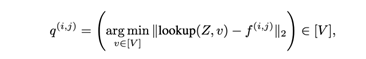
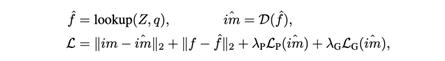
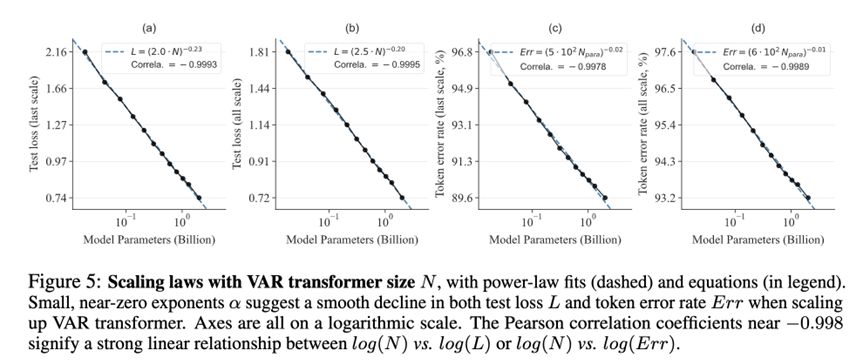
实验结果
实验结果强调两点是,一个是scaling law,通过不断增大参数量,可以看到test loss and token error rate在不断降低,其次同样的模型,增加traning compute,也存在scaling:
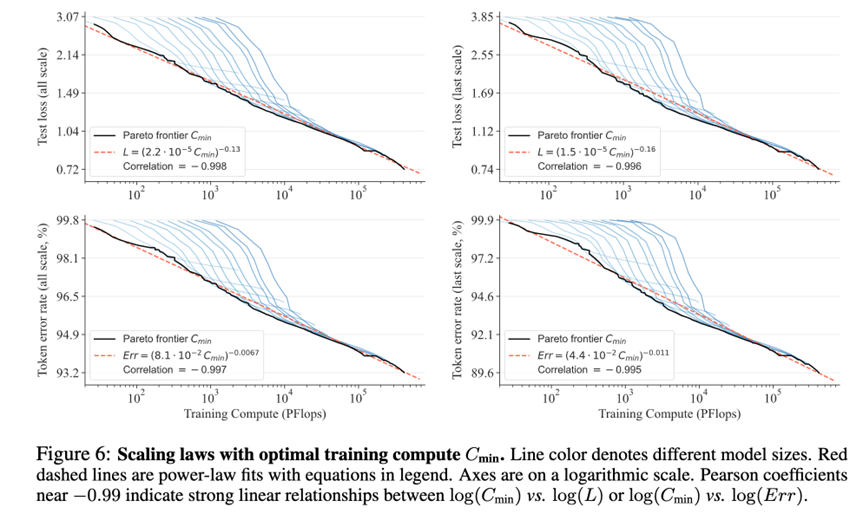
FlexVAR
方法
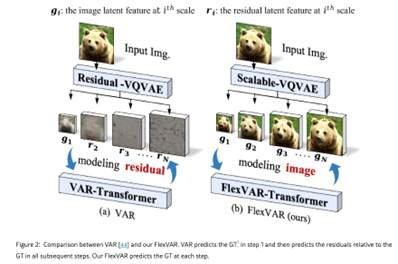
问题设定:视觉AR常见三类路径——逐token(raster-scan)、掩码并行(random-scan / MaskGIT)、以及尺度自回归(scale-wise)。VAR提出“下一尺度预测”,一步并行出整张token map,但采用残差(当前尺度 − 上一尺度上采样),因此推理步设计刚性、可伸缩性有限。
FlexVAR的核心变更:把“下一尺度残差预测”改为“下一尺度GT预测”,每一步都能直接给出一幅可用图像;并提供可缩放2D位置编码与随机步采样,从而打破固定步/固定分辨率限制。
总结来说和VAR的核心区别是:每一步直接预测该尺度的 ground-truth(GT)latent token map,而不是像 VAR 那样预测“残差”。这样每一步都能独立生成一幅可用图像,并且步数、分辨率与宽高比在推理时都可以灵活切换。
对比VAR and FlexVAR
残差预测(VAR)的优点
★
优化更分解:把高频细节留给细尺度学,“粗到细”像正交分解;对大模型训练很友好,论文与代码报告了强指标。
码本效率:多尺度/残差量化提高逼近能力,类似 RQ-VAE/RQ-Transformer 的“叠残差码栈”思想,早在 RQ-VAE 路线已验证有效。
先粗后细的归纳偏置:第一层一个 token 信息少,但它确实承担全局基色/构图这种超低频信息;随后层级逐步细化,误差更小、学习更稳。
残差预测(VAR)的代价 / 局限
★
特征无法对齐:从表示学习的视角,就是像素patch级别的残差和像素patch不共享特征空间. 这就导致了高频特征无法和 语义,实例,这种抽象信息对齐。
流程刚性:步数、每步 token 数基本写死;中断或少步会让下一层缺条件,输出容易退化。
接口复杂:
f_rest/f_hat、跨尺度掩码、teacher-forcing 的拼接,训练/推理的结构耦合强,不太“随心所欲”。每步可视化不一定优雅:早期粗层的可视图常较糙;要“任何步都像样”,并非设计目标。
非残差(FlexVAR)的优点
★
灵活:每一步都直接预测“真值分布”的一部分,使任意步数、分辨率、纵横比都能工作(作者展示了单模多任务/分辨率/步数的适配与迁移)。
连续语义:不以“上一层累计重建”作为必须条件,而是直接对齐“真值”,从统计学习角度更像一致的似然因子分解,强调相邻尺度的语义连续(作者认为更利于建模扩展的概率分布)。
实证:作者报告在 ImageNet 256 上,1B 参数的 FlexVAR 优于同规模 VAR,并在 13 步 zero-shot 迁移时 FID=2.08,优于 AiM/VAR 与一些扩散基线;在 512 上(zero-shot)对 2.3B VAR 也具竞争力。需注意对比条件与实现细节。
非残差(FlexVAR)的代价 / 潜在风险
★
难度可能上升:不借助“残差分解”,每步都要能“自圆其说”,需要强大的上采样/解码器与训练技巧,防止模式坍缩/漂移。
理论/经验尚在沉淀:FlexVAR 是 2025 年的新工作(arXiv),虽然有 GitHub,但生态与“各种数据域”的稳健性还待更多复现与比较。
Img generation without VQ
Li, Tianhong, et al. "Autoregressive image generation without vector quantization." Advances in Neural Information Processing Systems 37 (2024): 56424-56445.
本文的核心思路就是maskGIT+连续特征表达diffusion生成,具体来说两件事:
不用离散化/码本也能做自回归图像生成:作者提出将每个token 的条件分布p(x∣z)p(x|z)p(x∣z) 用一个扩散过程来表示,于是 token 可以是连续值而非 VQ 离散索引;训练时用“Diffusion Loss”取代传统交叉熵,从而摆脱 VQ(向量量化)的依赖。
统一 AR 与 Masked AR(MAR):作者把“随机顺序 + 双向注意力 + 一步预测多个 token”的 MaskGIT/MAGE 类方法形式化为广义自回归(“下一组 token 预测”),并论证双向注意力也能做自回归。
方法
diffusion


原来的各种vq-vae方法下,生成next token的方式是condition on之前的信息,或者之前scale的信息,做next token预测。这里也是一样,但是第一个区别是,不在有vq了,完全latent空间的连续表达,第二个,不是直接condition on之前的信息,而是利用一个轻量级的diffusion head,先聚合之前信息,作为condition z,然后把这个z给进diffusion head,预测出next token,这里的diffusion loss定义为:
Mask预测

借鉴maskGIT的思路:

diffusion毕竟非常耗时,本文的一个加速方式就是进行next some tokens prediction:
并且采用maskGIT的思路,并不是rasterized方式,一个个按顺序预测,而是采用随机mask随机预测的方式,逐渐补全整张图片。
双向attention
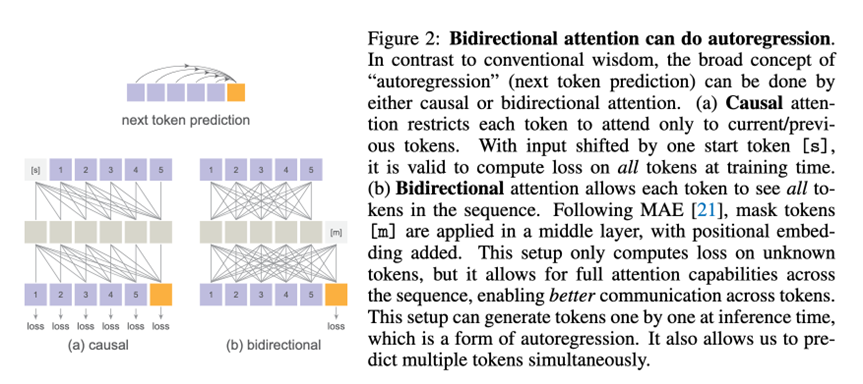

这个是MAE风格的操作,自回归的本质是条件化(只用“已知”去预测“未知”),与“用因果注意力还是双向注意力”无直接冲突,说白了只是不同的实现方式。论文明确指出“自回归可以用因果或双向注意力实现”,目标只是“给定之前的 token 去预测下一个/下一组 token”。
具体操作如下:
编码已知:先用一个 bidirectional encoder 只处理 已知 token(加位置信息),已知 token 之间相互可见。
解码未知:把编码后的已知序列与若干 [MASK] token(带位置嵌入,表示哪些位置要预测)拼接,再送入 bidirectional decoder。
只在未知处计损:训练时只对未知位置计算 Diffusion Loss/重建损失;已知位置不计损。这保证网络不会窥视目标值(未知处只有[MASK]向量而非GT)。
推理时的自回归:一次生成一个或一批未知 token,把它们的预测值并入“已知集合”,再进入下一步,直至全图填满。这样的“下一(组)token 预测”就是自回归,只是体系结构用的是双向注意力也就是mask和非mask之间的因果,而非前后因果掩码而已。
Future work
下一篇整理各种神奇的非vq-vae家族的tokenizer。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 4133
4133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









