 KVCache原理解析与优化
KVCache原理解析与优化




转自 | 地平线开发者 来源 | 手撕大模型|KVCache 原理及代码解析
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
在大型语言模型(LLM)的推理过程中,KV Cache 是一项关键技术,它通过缓存中间计算结果显著提升了模型的运行效率。本文将深入解析 KV Cache 的工作原理、实现方式,并通过代码示例展示其在实际应用中的效果。
01 为什么需要 KV Cache?
在 Transformer 进行自回归推理(如文本生成,每次生成一个 token 的时候需要结合前面所有的 token 做 attention 操作)时,计算注意力机制时需要存储 Key(K) 和 Value(V),以便下一个时间步可以复用这些缓存,而不必重新计算整个序列。
在标准 Transformer 解码时,每次生成新 token 时:
需要 重新计算所有之前 token 的 K 和 V,并与当前 token 进行注意力计算。
计算复杂度是 O(n²)(对于长度为
n的序列)。
而 KV Cache 通过存储 K 和 V 的历史值,避免重复计算:
只需计算 新 token 的 K 和 V,然后将其与缓存的值结合使用。
计算复杂度下降到 O(n)(每个 token 只与之前缓存的 token 计算注意力)。
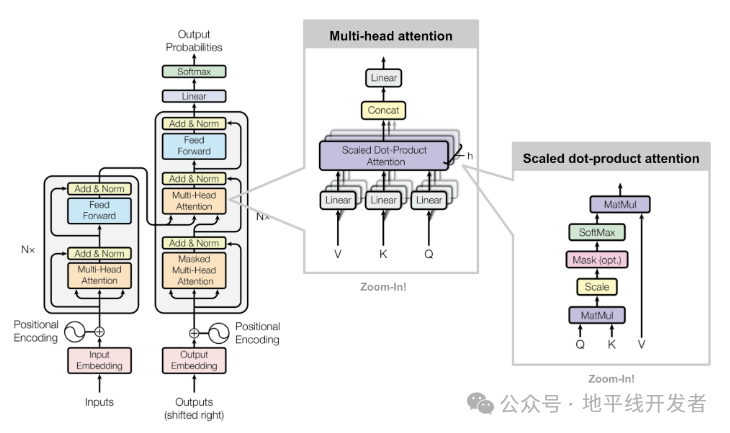
02 KV Cache 的工作原理
KV Cache 的核心思想是缓存历史计算中的键(Key)和值(Value)矩阵,避免重复计算。具体来说:
在生成第一个 token 时,模型计算并缓存所有输入 token 的 K 和 V 矩阵;
生成后续 token 时,只需要计算新 token 的查询(Query)矩阵;
将新的 Q 矩阵与缓存的 K、V 矩阵进行注意力计算,同时将新 token 的 K、V 追加到缓存中。
这个过程可以用伪代码直观展示:
初始输入: [t0, t1, t2]
首次计算: K=[K0,K1,K2], V=[V0,V1,V2] → 生成t3缓存状态: K=[K0,K1,K2], V=[V0,V1,V2]第二次计算: 新Q=Q3注意力计算: Attention(Q3, [K0,K1,K2]) → 生成t4更新缓存: K=[K0,K1,K2,K3], V=[V0,V1,V2,V3]第三次计算: 新Q=Q4注意力计算: Attention(Q4, [K0,K1,K2,K3]) → 生成t5更新缓存: K=[K0,K1,K2,K3,K4], V=[V0,V1,V2,V3,V4]...
通过这种方式,每次新生成 token 时,只需计算新的 Q 矩阵并与历史 KV 矩阵进行注意力计算,将时间复杂度从 O (n²) 降低到 O (n),极大提升了长序列生成的效率。
下面,我们结合示意图进一步剖析一下 KV Cache 部分的逻辑。
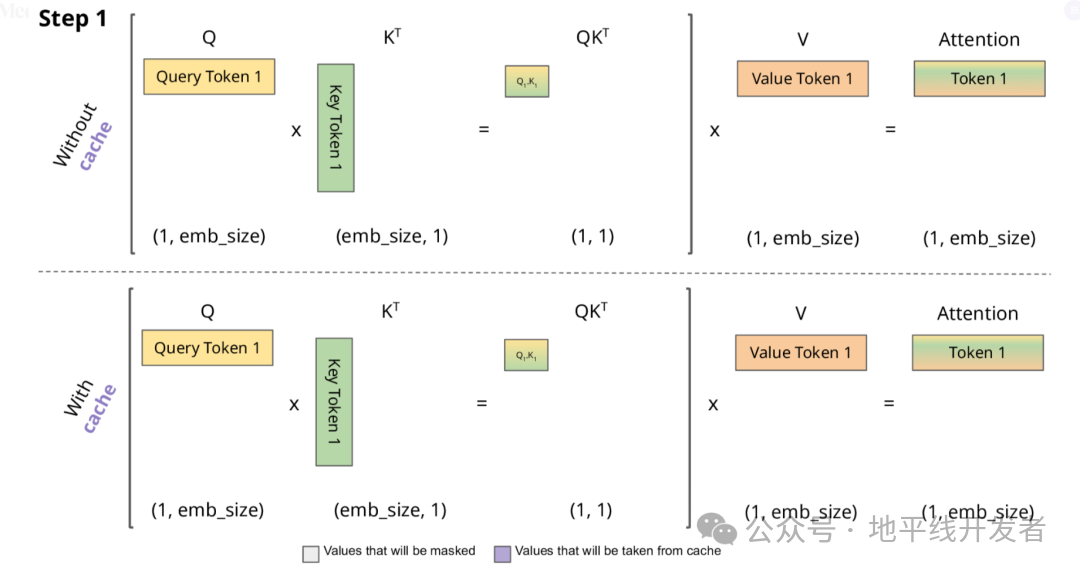
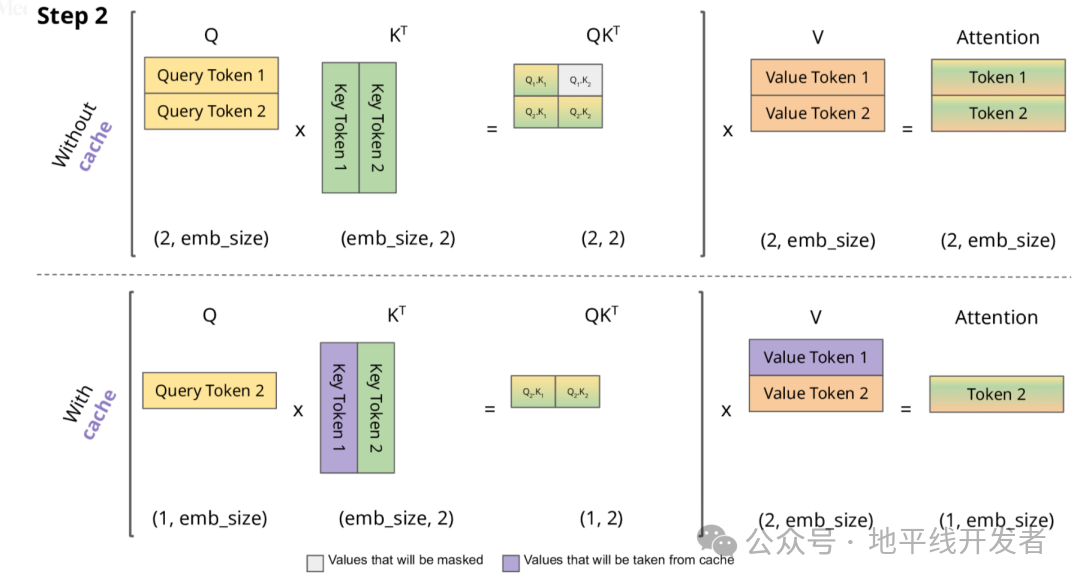
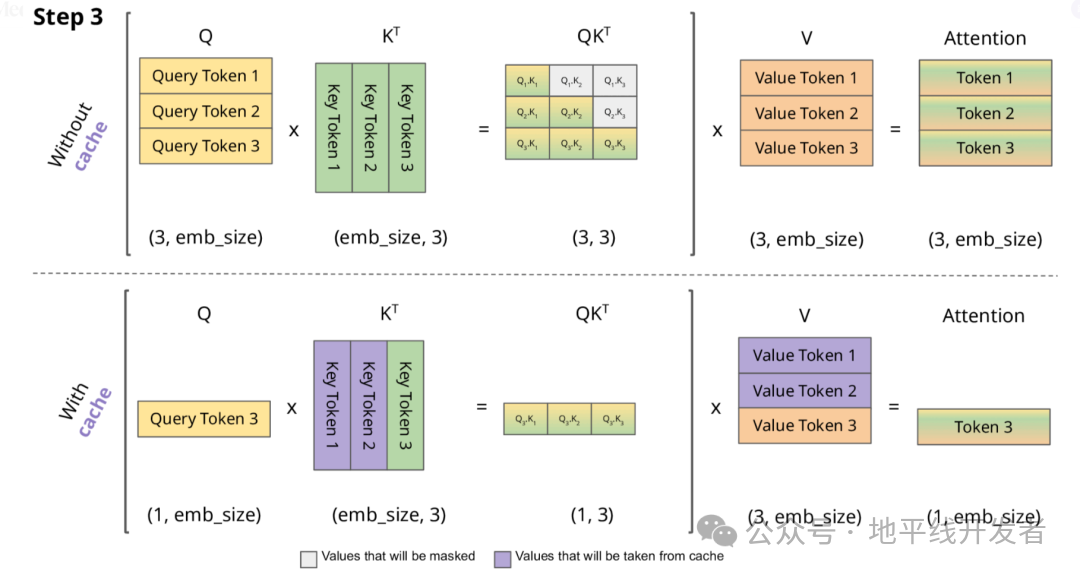
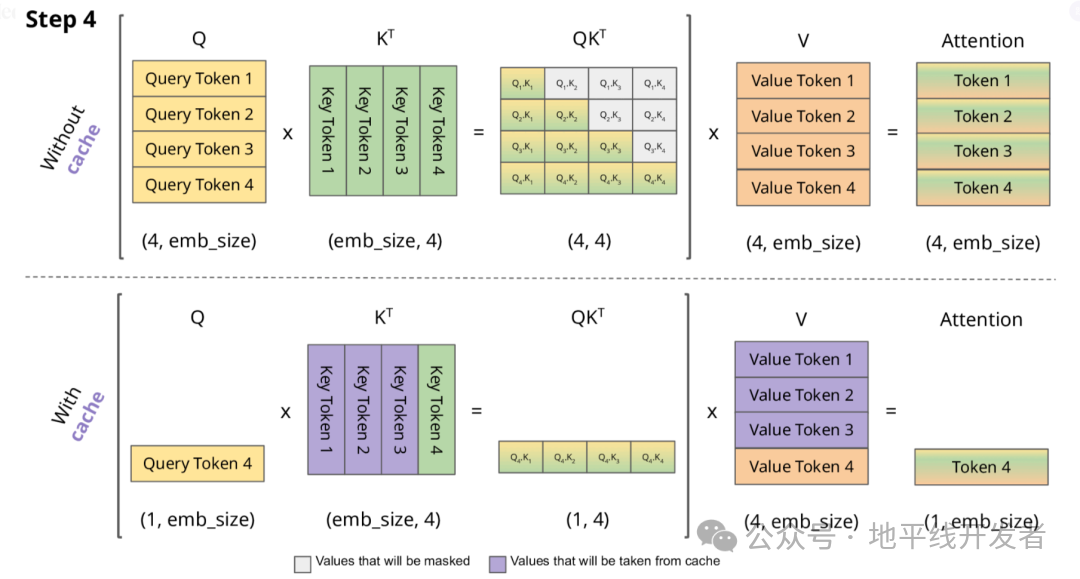
KV Cache 核心节约的时间有三大块:
前面 n-1 次的 Q 的计算,当然这块对于一次一个 token 的输出本来也没有用;
同理还有 Attention 计算时对角矩阵变为最后一行,和 b 是同理的,这样 mask 矩阵也就没有什么用了;
前面 n-1 次的 K 和 V 的计算,也就是上图紫色部分,这部分是实打实被 Cache 过不需要再重新计算的部分。
这里还有个 softmax 的问题,softmax 原本就是针对同一个 query 的所有 key 的计算,所以并不受影响。
2.1 KV Cache 的技术细节
2.1.1 缓存结构
KV Cache 通常为每个注意力头维护独立的缓存,结构如下:
Key 缓存:形状为 [batch_size, num_heads, seq_len, head_dim];
Value 缓存:形状为 [batch_size, num_heads, seq_len, head_dim]。
其中,seq_len 会随着生成过程动态增长,直到达到模型最大序列长度限制。
2.1.2 内存与速度的权衡
KV Cache 虽然提升了速度,但需要额外的内存存储缓存数据。以 GPT-3 175B 模型为例,每个 token 的 KV 缓存约占用 20KB 内存,当生成 1000 个 token 时,单个样本就需要约 20MB 内存。在批量处理时,内存消耗会线性增加。
实际应用中需要根据硬件条件在以下方面进行权衡:
最大缓存长度(影响能处理的序列长度);
批量大小(影响并发处理能力);
精度选择(FP16 比 FP32 节省一半内存)。
2.1.3 滑动窗口机制
当处理超长序列时,一些模型(如 Llama 2)采用滑动窗口机制,只保留最近的 N 个 token 的 KV 缓存,以控制内存占用。这种机制在牺牲少量上下文信息的情况下,保证了模型能处理更长的对话。
04 代码实现解析
下面以 PyTorch 为例,展示 KV Cache 在自注意力计算中的实现方式。
1. 基础自注意力实现(无缓存)
首先看一下标准的自注意力计算,没有缓存机制:
import torchimport torch.nn as nnimport torch.nn.functional as Fclass SelfAttention(nn.Module): def __init__(self, embed_dim, num_heads): super().__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim // num_heads
# 定义Q、K、V投影矩阵 self.q_proj = nn.Linear(embed_dim, embed_dim) self.k_proj = nn.Linear(embed_dim, embed_dim) self.v_proj = nn.Linear(embed_dim, embed_dim) self.out_proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x): batch_size, seq_len, embed_dim = x.shape
# 计算Q、K、V q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力分数 attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) attn_probs = F.softmax(attn_scores, dim=-1)
# 应用注意力权重 output = attn_probs @ v output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)
return self.out_proj(output)2. 带 KV Cache 的自注意力实现
下面修改代码,加入 KV Cache 机制:
class CachedSelfAttention(nn.Module): def __init__(self, embed_dim, num_heads): super().__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim // num_heads
# 定义投影矩阵 self.q_proj = nn.Linear(embed_dim, embed_dim) self.k_proj = nn.Linear(embed_dim, embed_dim) self.v_proj = nn.Linear(embed_dim, embed_dim) self.out_proj = nn.Linear(embed_dim, embed_dim)
# 初始化缓存 self.cache_k = None self.cache_v = None
def forward(self, x, use_cache=False): batch_size, seq_len, embed_dim = x.shape
# 计算Q、K、V q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 如果使用缓存且缓存存在,则拼接历史KV if use_cache and self.cache_k is not None: k = torch.cat([self.cache_k, k], dim=-2) v = torch.cat([self.cache_v, v], dim=-2)
# 如果使用缓存,更新缓存 if use_cache: self.cache_k = k self.cache_v = v
# 计算注意力分数(注意这里的k是包含历史缓存的) attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) attn_probs = F.softmax(attn_scores, dim=-1)
# 应用注意力权重 output = attn_probs @ v output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)
return self.out_proj(output)
def reset_cache(self): """重置缓存,用于新序列的生成""" self.cache_k = None self.cache_v = None3. 生成过程中的缓存使用
在文本生成时,我们可以这样使用带缓存的注意力机制:
def generate_text(model, input_ids, max_length=50): # 初始化模型缓存 model.reset_cache()
# 处理初始输入 output = model(input_ids, use_cache=True) next_token = torch.argmax(output[:, -1, :], dim=-1, keepdim=True) generated = [next_token]
# 生成后续token for _ in range(max_length - 1): # 只输入新生成的token output = model(next_token, use_cache=True) next_token = torch.argmax(output[:, -1, :], dim=-1, keepdim=True) generated.append(next_token)
# 如果生成结束符则停止 if next_token.item() == 102: # 假设102是[SEP]的id break
return torch.cat(generated, dim=1)05 KV Cache 的优化策略
在实际部署中,为了进一步提升 KV Cache 的效率,还会采用以下优化策略:
- 分页 KV Cache(Paged KV Cache):借鉴内存分页机制,将连续的 KV 缓存分割成固定大小的块,提高内存利用率,代表实现有 vLLM。
- 动态缓存管理:根据输入序列长度动态调整缓存大小,在批量处理时优化内存分配。
- 量化缓存:使用 INT8 或 INT4 等低精度格式存储 KV 缓存,在牺牲少量精度的情况下大幅减少内存占用。
- 选择性缓存:对于一些不重要的层或注意力头,选择性地不进行缓存,平衡速度和内存。
06 总结
KV Cache 通过缓存中间计算结果,有效解决了 Transformer 模型在生成式任务中的效率问题,是大模型能够实现实时交互的关键技术之一。理解 KV Cache 的工作原理和实现方式,对于优化大模型推理性能、解决实际部署中的挑战具有重要意义。
07 参考链接
1. https://zhuanlan.zhihu.com/p/670515231
2. https://zhuanlan.zhihu.com/p/714288577
3. https://zhuanlan.zhihu.com/p/715921106https://zhuanlan.zhihu.com/p/19489285169
4. https://medium.com/@joaolages/kv-caching-explained-276520203249
自动驾驶之心
论文辅导来啦


自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 3925
3925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









