



转自 | 量子位 小米最新大模型成果!罗福莉现身了
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
小米的最新大模型科研成果,对外曝光了。
就在最近,小米AI团队携手北京大学联合发布了一篇聚焦MoE与强化学习的论文。

而其中,因为更早之前在DeepSeek R1爆火前转会小米的罗福莉,也赫然在列,还是通讯作者。
罗福莉硕士毕业于北京大学,这次也算是因AI串联起了小米和北大。
有意思的是,就在今年9月DeepSeek登上《Nature》的时候,罗福莉也出现在了作者名单,不过是以“北京独立研究者”的身份。

当时还有过风言风语,说当初“雷军千万年薪挖来AI天才少女”,当事人可能离职了。
但这篇小米最新AI论文披露后,一切似乎有了答案…
小米最新AI成果:找到RL中稳定和效率的平衡
这篇论文大道至简,提出了一种在MoE架构中提高大模型强化学习的思路。
相对已经共识的是,当前强化学习已成为在预训练遇到瓶颈后,推动LLM突破能力边界的关键工具。
不过在MoE架构中,情况就没那么简单了,由于需要根据问题分配不同的专家,路由机制会让训练过程变得不稳定,严重时甚至会直接把模型“整崩”。
为了解决这个问题,研究团队提出了一种全新的思路,让MoE也能平稳且高效地推进大规模强化学习。
强化学习的灾难性崩溃
自从预训练时代告一段落,后训练成了巨头们拿起Scaling Law瞄准的的下一个战场。
靠着大规模强化学习,大模型开始学会更长链路的推理,也能搞定那些需要调用工具的复杂Agent任务。
不过,强化学习在扩展规模的过程中,总会不可避免地撞上一道铁幕:效率和稳定性的权衡。
想要高效率,就得训练得更“猛”——更高的学习率、更大的并行度、更频繁的样本更新。可这样一来,稳定性也更容易出现问题。
但一味追求稳定也不行,效率会被拖住,模型训练慢得像蜗牛。
想要解决这个问题,得先回到强化学习的底层一探究竟。
LLM的强化学习,通常分两步:
第一步是推理,模型自己生成内容、和环境互动、拿到反馈分数;
第二步是训练,根据这些分数去微调自己,并想办法在下次拿更高分。
不过,这两步通常不是在同一套系统里跑的。
比如,现在主流方案是SGLang负责生成内容,追求速度快;而Megatron负责训练更新,追求算得准。
虽然两边用的是同一套模型参数,但底层实现有细微差别,比如像随机性、精度、并行方式、缓存策略,这些看似微不足道的细节波动,都会让结果出现偏差。
于是就出现了一个尴尬现象:
一模一样的Prompt,两套模式下最终生成的结果都能不一样。
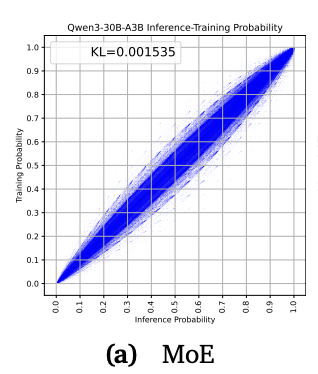
这种「概率漂移」积累多了,模型就会越学越偏,最后学着学着,训练目标和实际表现彻底牛头不对马嘴。
这就是业内常说,强化学习灾难性崩溃。
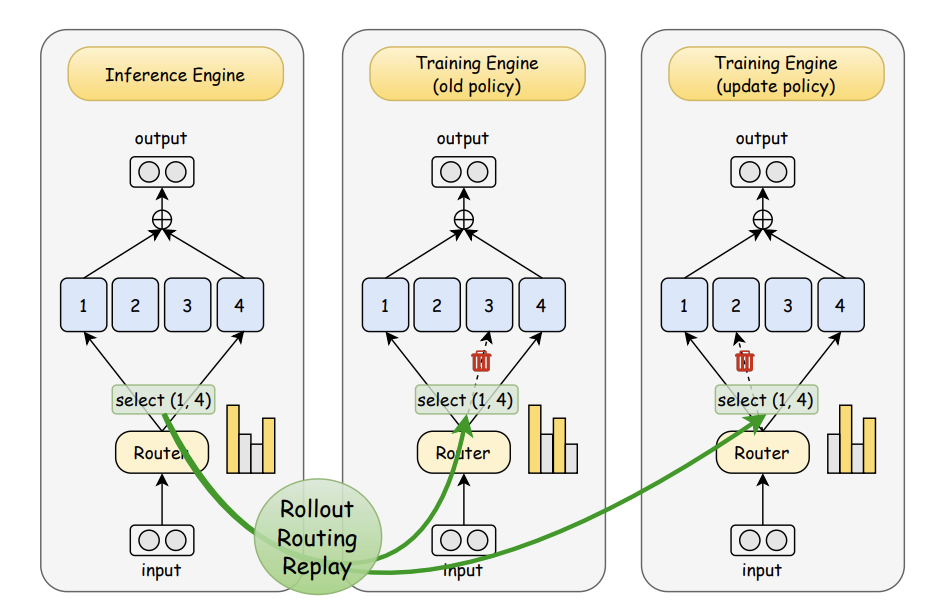
路由重放机制
研究团队指出,导致MoE在强化学习中容易崩掉的罪魁祸首,在于路由分布。
在MoE模型中,路由器不会把所有参数都用上,而是会根据每个输入token的特征,挑几位在该领域更擅长的“专家”出来干活,从而可以节省不少资源。
但副作用也很明显,这种动态模式会让模型在训练阶段和推理阶段得出的最佳策略大相径庭,比传统的稠密模型要“飘忽”得多。
对此,这篇论文给出了一种新颖的解决方案。
既然问题出在路由随机,那为何不直接把路由锁住呢?
他们的做法是:在推理时把路由分布记录下来,等到训练时再把这些分布原封不动地“重放”进去。
这样,训练和推理就走同一条路线,不再各干各的。
根据这种“重放”的特定,研究将这种方法命名为——Rollout Routing Replay(R3)。
解决了稳定性的问题,再来看看如何把效率也稳稳拿下。
在强化学习中,模型会不断重复“生成→获得奖励→更新→再生成”的飞轮,一个完整过程下来,可能要跑上几十万、甚至上百万次推理。
要是每次生成都要从头计算上下文,算力与时间成本将呈几何式增长。
为应对这种情况,主流推理引擎普遍采用KVCache前缀缓存策略:把之前算好的上下文保存下来,下次直接“接着算”。
不过,除了上下文不一致,MoE架构还涉及到路由选择不一致的问题——按照传统的解决方案,即便是重复的上下文,每一次计算,模型还是要重新选专家、激活专家。
因此,研究团队在KVCache的基础上又加了一招——路由掩码(routing mask)。
他们的想法是,既然对于对相同的上下文,MoE的路由结果应该一样,那干脆,把推理阶段的路由掩码和前缀KVCache一起缓存起来。
这样当相同上下文再次出现时,模型就能直接用上次的掩码,不必重算。
这样,R3就能够与现有的前缀缓存系统无缝衔接,在大规模强化学习及复杂的Agent任务中,也依然能保持出色的计算效率。
实验结果
为评估R3的实际效果,研究团队基于Qwen3-30B-A3B模型进行了一系列实验。
总体性能:

结果发现,不管在哪种场景下,R3的整体成绩都更好。
在多mini-step设置下,GRPO+R3的表现比GSPO高出1.29分。
若将R3与GSPO结合,性能还可以进一步提升0.95分。
训练稳定性:
崩溃情况也少了很多。
不难看出,随着训练时间的延长,即便到了第150步,R3依然能保持相对平缓的曲线。
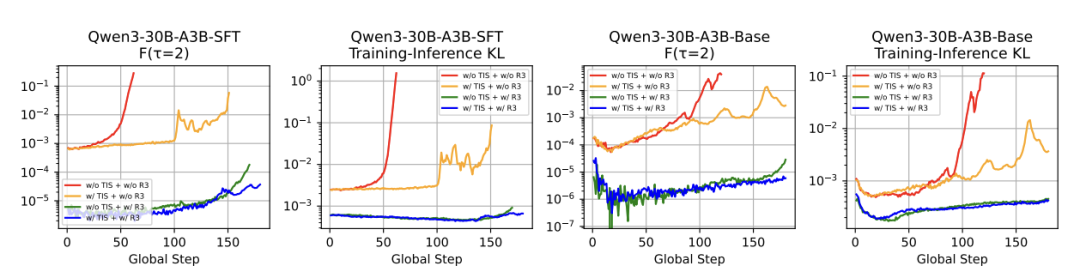
相比之下,如果是用GRPO训练,到第60步时就已经严重跑偏。
优化与生成行为:
而且,R3不光让模型更稳,也让它更聪明。
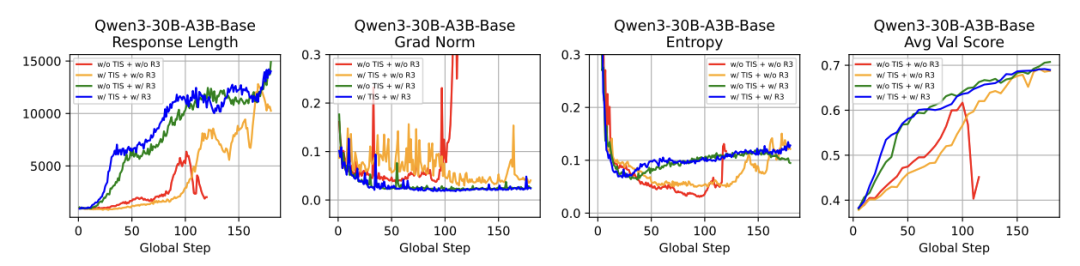
实验结果结果表明,R3能更快找到正确方向、优化过程更丝滑,还能更早开始探索更优策略。
一句话总结,研究团队在这篇论文提出了一种叫R3的方法,通过在训练中复用推理阶段的路由分布,能够让MoE模型的强化学习更稳定、更高效。
论文作者
说完论文,再让我们看看这支由小米系和北京大学携手牵起的研究团队。
论文的第一作者叫Wenhan Ma。
资料不多,只知道Wenhan是小米LLM-Core团队的研究员,而且还是实习生。
此前,他还曾参与过小米MiMo模型与多模态MiMo-VL的研发。

相比起来,这篇论文的两名通讯作者,大家可能更耳熟能详一点。
一位是罗福莉。

罗福莉本科毕业于北京师范大学计算机专业,硕士阶段进入北京大学计算语言学深造。期间,她在不少NLP顶级会议上都发表过论文。
硕士毕业后,罗福莉加入阿里巴巴达摩院,担任机器智能实验室研究员,负责开发多语言预训练模型VECO,并推动AliceMind项目的开源工作。
2022年,罗福莉加入DeepSeek母公司幻方量化从事深度学习相关工作,后又担任DeepSeek的深度学习研究员,参与研发DeepSeek-V2等模型。
截至目前,罗福莉的学术论文总引用次数已超过1.1万次,仅在今年一年内就新增了约八千次引用。
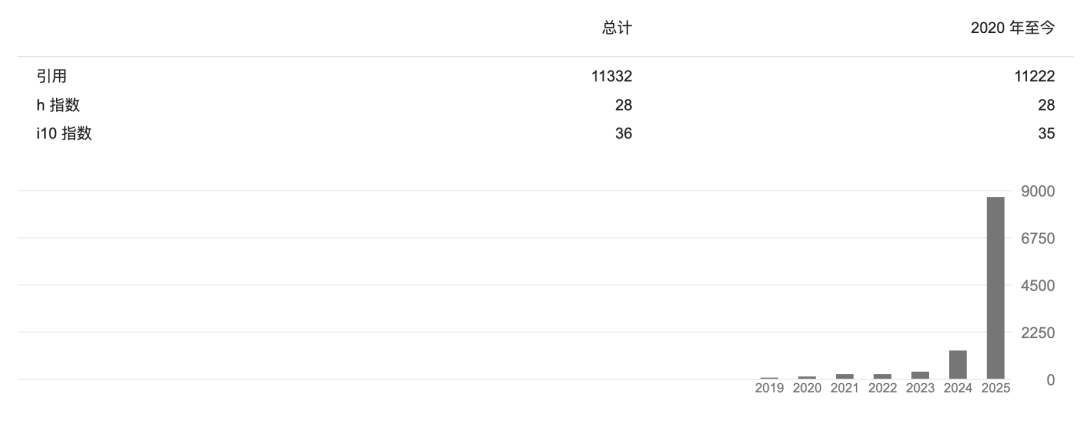
而另一名通讯作者,正是罗福莉的北大硕士导师——穗志方。

穗教授是北京大学信息科学技术学院的教授、博士生导师,长期从事计算语言学、文本挖掘与知识工程研究,在NLP与AI领域发表了大量高水平论文。
但稍有有个新问题,在这篇论文成果的单位注释中,罗福莉的单位没有被明确,她既不是北大的,也没有被归入小米。

咦……依然是独立研究者?
论文:
https://arxiv.org/abs/2510.11370
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









